【APUE】Chapter4 File and Directories
4.1 Introduction
unix的文件、目录都被当成文件来看待(vi也可以编辑目录);我猜这样把一起内容都当成文件的原因是便于统一管理权限这类的内容
4.2 stat, fstat, fstatat and lstat Functions & 4.3 File Types
1. 介绍一个系统提供的结构体 struct stat,里面包含了与文件相关的各种信息。

书上还介绍,unix系统命令ls -l就是用了上面的数据结构。
2. File Types
书上一共介绍如下几种文件类型:
(1)Regualr file
(2)Directory file:包含目录文件名和指向这些文件的信息
(3)Block special file:a type of file providing buffered I/O access...
(4)Character special file:a type of file providing unbuffered I/O access.. 另外,所有的system device要么是block size file,要么是character special file(虽然暂时不知道这两种文件都干什么的,先记下来)
(5)FIFO:a type of file used for communication between process
(6)Socket:a type of file used for network communication between process
(7)Symbolic link:a type of file that points to another file
有关文件类型的信息,可以由上面提到的几个函数结合struct stat结构体中的st_mode属性获得。
例子如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h> int main(int argc, char *argv[])
{
int i;
struct stat buf;
char *ptr; for ( i=; i<argc; i++)
{
printf("%s: ",argv[i]);
lstat(argv[i], &buf);
if (S_ISREG(buf.st_mode))
ptr = "regular";
else if (S_ISDIR(buf.st_mode))
ptr = "directory";
else if (S_ISCHR(buf.st_mode))
ptr = "character special";
else if (S_ISBLK(buf.st_mode))
ptr = "block special";
else if (S_ISFIFO(buf.st_mode))
ptr = "fifo";
else if (S_ISLNK(buf.st_mode))
ptr = "symbolic link";
else if (S_ISSOCK(buf.st_mode))
ptr = "socket";
else
ptr = "** unkown mode **";
printf("%s\n",ptr);
}
exit();
}
编译运行结果如下:

如果代码中不用lstat函数,而改用stat函数,则结果如下:

可以看到,如果用了stat函数,就不会识别出来symbolic link类型的文件了。
4.4 Set-User-ID and Set-Group-ID
这部分内容参考了这篇blog(http://blog.csdn.net/jiqiren007/article/details/6142502)
书上敲碎了说一遍,blog提起来说一遍,稍微有些理顺了。
unix系统中,每个process有至少三类(总共六个)与之相关的ID(注意,这里是针对process来说的):
1. real user ID and real group ID:
实际调用进程的user ID或这个process是由哪个父进程发起的也就把user ID继承过来了。
这个项目一般不需要修改。
2. effective user ID and effective group ID:
与权限的user ID,即判断一个进程是否对某个文件有操作权限的依据。
这个内容比较拗口,左一个文件,右一个文件的,非常容易混乱,需要通过一个具体例子来说明。
以transFei用户的身份创建一个文件如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h> int main()
{
printf("real uid = %d\n", getuid());
printf("effective uid = %d\n", geteuid());
exit();
}
编译后结果如下:

(1)编译后的程序文件是a.out,owner自然是transFei
(2)-rwxrwxr-x 开头的'-'表示是文件,不是文件夹也不是link;rwx表示owner具有读写和执行的权限;rwx表示同组的user具有读写和执行的权限;r-x表示other用户具有读和执行的权限,没有写权限。
执行代码,结果如下:

getuid()获得进程的real user id;geteuid获得进程的effective user id;
通过上述结果可以知道:real user id就是程序的调用用户transFei,而effective user也是程序的real user即transFei。
下面执行如下操作:

上面的操作就是进入了root权限,并且改变了该a.out的owner为root。
返回到transFei账户下,执行代码,发现real uid和effective uid依然没有变化。
可以看到:在上述情况下,即使改变了a.out的owner,回到transFei用户状态下,依然不会改变real user与effective user。
我们再执行如下的操作:

我先试图在transFei的账户下修改user的读写执行权限,无权限(因为现在a.out的owner已经是root了,当然无权限了)
切换到root账户下,修改a.out的user相关的bit:“u+s”表示a.out在执行的时候,是可以获得a.out的root权限的,即使调用a.out的user并不是root。这一点,可以通过a.out的执行结果得知虽然real uid还是transFei,但是effective uid已经变成了root了。
上面的这种模式就叫set-user-id,'+s'就赋予了程序文件这样的特性(可以是u+x, g+x, o+x)。这种模式提供了一种折中的权限解决方案:你可以不是程序的创建者,甚至连读和写的权限都没有;但是允许你在调用程序的时候,获得程序owner一样的权利。这里有一个具体的例子:unix系统允许一个登陆用户改变自己的登陆密码(可以写/etc/passwd文件,但是却不需要root权限),就是因为passwd(1)这个程序具有这样的特性,见下图:

可以看到passwd这个程序,权限都是root的;但是就是因为有了rws这个s,才让用户可以修改自己的密码。以上。
3. saved set-user ID and saved set-group ID:当程序执行的时候,保存effective user ID和effective group ID
4.5 File Access Permissions
精要总结一下:
1. process属性:process的effective user id 和 effective group id说的是这个process是什么身份
2. file属性:file status mode bit表明了不同身份的访问者有什么权限
3. kernel负责匹配process权限属性与file权限属性,判断某个process的身份能有什么样的file权限;具体来说,kernel按照如下步骤检查一个process是否具备操作某个file的权限:
(1) 如果effective user ID为0(root权限),则一路畅通无阻
(2) effective user ID = owner ID of file,process就是user身份,权限就是user权限
(3) effective group ID = group ID of the file,process就是同group身份,权限就是同group的权限
(4) 如果既不是user身份,也不是同group身份,那么就归到other身份中了,权限就是other的权限
简单说,就是按照红框中的bit来检查的(从左往右):

4.6 Ownership of New Files and Directories
4.7 access and faccessat Functions
针对real user id来判断是否有操作文件的权限。
之前不是说,一般来说process的effective user id就是real user id么?为什么还要针对real user id来判断?
就像之前4.4中说的那样,如果-rws这种的情况:执行某个文件的时候,effective user id变成了文件的owner,就不再是real user id了;如果这个时候要对real user进程访问权限控制,就需要下面这个函数了。
int access(const char *pathname, int mode);
判断real user的是否有权限。
例子如下:
#include "apue.h"
#include <fcntl.h> int main(int argc, char *argv[])
{
if (argc != ) {
err_quit("usage: a.out <pathname>");
}
if (access(argv[], R_OK)<) {
err_ret("access error for %s", argv[]);
}
else
printf("read access OK\n"); if (open(argv[],O_RDONLY)<) {
err_ret("open error for %s", argv[]);
}
else
printf("open for reading OK\n");
exit();
}
编译执行结果如下:
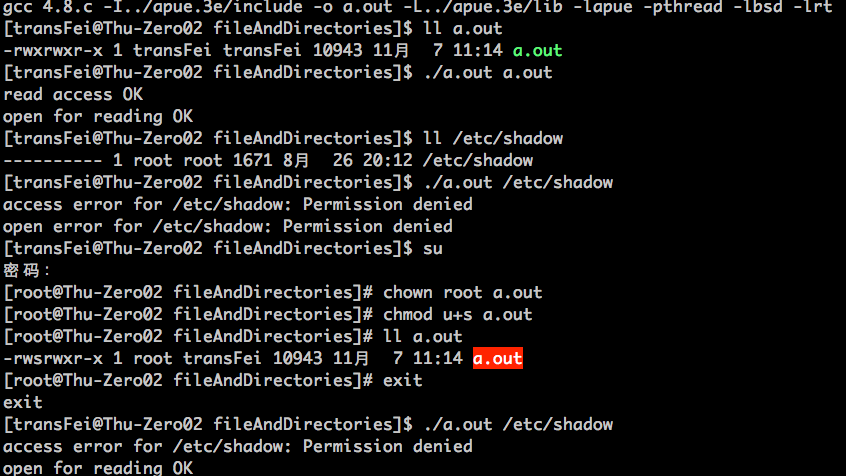
分析如下:
(1)以常规用户的身份编译程序,则程序对/etc/shadow即不能access也不能open
(2)用chown命令改变a.out的文件owner为root
(3)set-user-id bit位设为s
(3)返回常规用户身份,则程序对/etc/shadow可以open
具体的原理跟4.4中阐述的例子一样,不再赘述了。
4.8 umask Function
参考这篇blog的补充(http://blog.csdn.net/lmh12506/article/details/7281910)
umask函数的作用是给process中新生成的文件设定默认权限,是做权限减法的函数。
函数原型:mode_t umask(mode_t cmask)
其中cmask参数可以用bitwise OR的形式来组织,哪个在里面,就把哪个权限屏蔽掉了。
看一个例子(与apue书上的4.9的例子有所不同,因为我用的系统上没有create函数,所以改造了一下用open函数代替):
#include "apue.h"
#include <fcntl.h> #define RWRWRW (S_IRUSR|S_IWUSR|S_IRGRP|S_IWGRP|S_IROTH|S_IWOTH) int main()
{
mode_t old;
old = umask();
printf("old umask: %o\n", old);
if (open("foo",O_CREAT,RWRWRW)<) {
err_sys("create error for foo");
}
umask(S_IRGRP|S_IWGRP|S_IROTH|S_IWOTH);
if (open("bar",O_CREAT, RWRWRW)<) {
err_sys("create error for bar");
}
exit();
}
运行结果如下:

上述结果说明了两个事情:
(1)umask函数是做减法。生成foo文件的上下文背景的umask参数是0,而生成bar文件的上下文背景的umask参数是四个symbolic(可以直接望文生义:比如,S_IRGRP表示同组用户的读权限;其余的可以类推)
(2)umask函数的范围是调用它的process,不会影响到其父进程(比如shell的umask设置)。可以看到执行a.out之前,umask是0002;执行完a.out后,umask的设置还是0002。这就标明umask函数的作用是有范围限制的。
如果想要改变登录用户创建文件的各种默认权限,可以通过设置.bash_profile来调整。
再补充一点,这种mask bit是按照八进制的方法来表示;一共九个bit,1表示屏蔽了,0表示没屏蔽,每个单bit的屏蔽参数如下:
0400 屏蔽user-read
0200 屏蔽user-write
0100 屏蔽user-exectue
0040 屏蔽group-read
0020 屏蔽group-write
0010 屏蔽group-execute
0004 屏蔽other-read
0002 屏蔽other-write
0001 屏蔽other-execute
4.9 chmod, fchmod, and fchmodat Functions
chmod系列命令是针对existing file进行权限设置操作,可以做加减法。
继续上代码:
#include "apue.h" int main()
{
struct stat statbuf;
/*turn on set-group-id and turn off group-execute*/
if (stat("foo",&statbuf)<) {
err_sys("stat error for foo");
}
if (chmod("foo",(statbuf.st_mode & ~S_IXGRP)| S_ISGID)<) {
err_sys("chmod error for foo");
}
/*set absolute mode to "rw-r--r--"*/
if (chmod("bar",S_IRUSR|S_IRGRP)) {
err_sys("chmod error for bar");
}
exit();
}
编译执行后结果如下:

这里需要注意的是chmod设定的是absolute value;如果想根据current value设置,就需要先或st_mode属性,再做位运算。
4.10 Sticky Bit
4.11 chown, fchown, fchownat, and lchown Functions
1. 如果是symbolic link的需要注意,lchown改变的是owners of the symbolic link itself 而并不是link指向的file
2. BSD-based systems要求必须只有superuser能够改变file的ownership
4.12 File Size
1. 只有regualr files, directories 和 symbolic links是有意义的
2. 对于symbolic links来说,fize size就是pathname的长度,如下:

3. file hole的情况,file size会比真实的大;实际使用的size少。
4.13 File Truncation
int truncate(const char *pathname, off_t length)
int ftruncate(int fd, off_t length)
从指定的长度截断给定文件。
(1)如果length没有实际文件的长度大,那么文件大于length长度的都no longer accessible了
(2)如果length比实际文件的长度大,那么实际文件的size扩大了,并且可能产生了file hole
4.14 File System
这部分内容主要讲的是File System的某部分结构,围绕i-node展开的。
按照file和directory两个内容,看两个图:
图一:
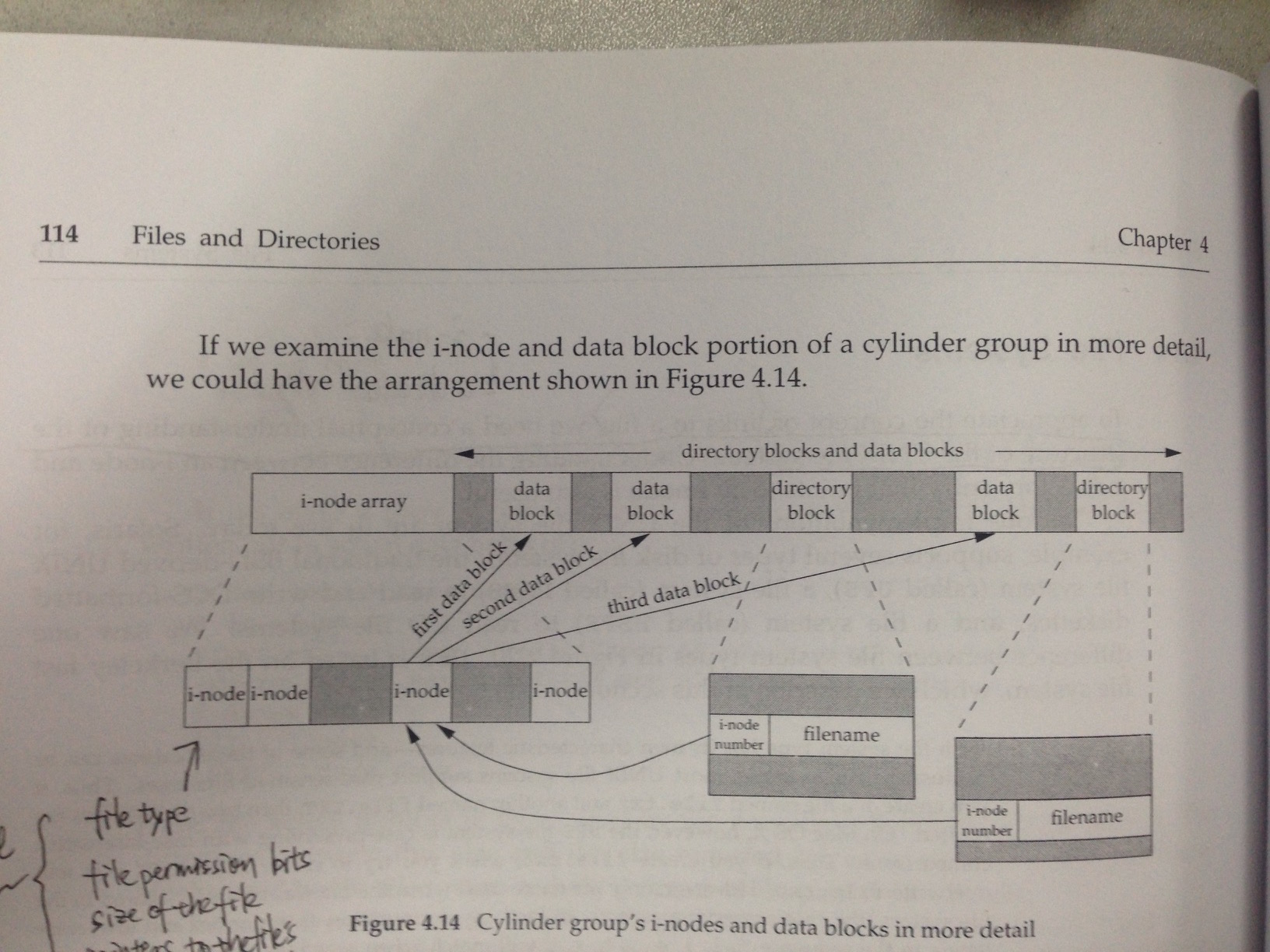
1. 图中有两个directory entries指向了同一个i-node entry,每个i-node都有一个link count来记录有多少directory entries指向它,这种叫硬链接。
2. 还有一种类型的link叫symbolic link,意思就是实际data block中存放的并不是数据,而是这个symbolic link所指向的文件名。这种link叫soft link。
3. i-node里面包含了如下的内容:
(1)file type
(2)file permission bits
(3)size of the file
(4)pointers to the field's data blocks
4. 另外与file相关的filename和i-node number存放在directory block中
图二:

上面的图解释了如果是link count field for a directory的情况:
1. 如果是directory是leaf directory(没有子目录了):如testdir这个目录,编号是2549;首先存在一个编号为2549的i-node;directory entry中有一个'.'指向2549这个i-node,还有'testdir'这个指向2549这个i-node。
2. 如果directory下面还有subdirectory:如编号为1267这个directory,至少有三个directory entry指向这个i-node。'.' '..' 以及编号伟1267这个文件夹的名。
i-node这种设计思路,其实并没有严格区分file和directory,directory是目录文件。
书上的原理有些简练,搜了下面的blog
http://www.ruanyifeng.com/blog/2011/12/inode.html (可以作为outline迅速了解一下)
http://roclinux.cn/?p=754 (这个原理更详细一些)
http://blog.csdn.net/lmh12506/article/details/7446315 (从一些文件实操的例子对inode的影响来解释)
http://www.cnblogs.com/itech/archive/2009/04/10/1433052.html (根据实操的例子对ln的硬软链接理解)
进行一下实操,加深下理解:

通过上面的实操例子,可以体会硬连接(ln)和软链接(ln -s)的区别。
总结一下:
(1)硬链接就是一个文件有多个名,软链接就是一个新的文件,只不过文件的内容是另一个文件的位置(类似windows的快捷方式)
(2)硬链接不能夸不同的file system;而软链接可以跨不同的file system
4.15 link, linkat, unlink, unlinkat, and remove Functions
具体用到的例子再回来看,原理在上一小节已经搞清楚了。
2015.11.12补充,看到了第5章的tmpname函数,回来把这一块补上了。
int unlink(const char *pathname);
这个unlink是干什么用的?书上说的是"remove an existing directory entry"。
通俗或者不严谨的理解可以是:就是原来用ls能看到一个文件,执行unlink从目录中看不到了。回顾一下4.14的图,如果把entry去掉了,就意味着用户无法访问了。但是文件真的就从file system中删除了么?不是的。
可以看P117的内容,unlink只是减少了一个directory entry。kernel判断是否要完全从file system中删除一个文件取决于两点:
(1)link count是0
(2)没有任何process正打开这个file
如果以上两点都满足了,则kernel认为这个file可以从system中删除了。
看如下程序:
#include "apue.h"
#include <fcntl.h> int main()
{
open("log", O_RDWR);
unlink("log");
printf("file unlinked\n");
sleep();
printf("done\n");
exit();
}
为了执行程序,需要准备一个文件(我准备的是log文件,大概500M),执行结果如下:

在a.out这个进程中打开log这个文件,随后马上unlink了:
(1)unlink之后,发现在当前目录中找不到log这个文件了,但是这个文件还在file sytem中(因为disk使用量没有变化)
(2)等待sleep结束之后,exit(0)退出a.out这个process(exit把各种file descriptor都给关闭了),释放了a.out对log这个文件的占用,因此在这个时候kernel正式把log这个文件从system中删除了
以上这种open+unlink的方式,正是tmpfile()的实现原理的核心部分。
4.16 rename and renameat Function
int rename(const char *oldname, const char *newname);
如果newname是之前不存在的,就可以顺利完成重命名。
如果newname是已经存在的,则完成目标需要注意以下几点:
(1)如果oldname就是file或者symbolic,newname不能是directory;执行rename的结果就是,newname的文件内容被删除了,取而代之的是oldname的内容。
(2)如果oldname是directory,newname也是directory,则要求newname的directory必须是空的,并且newname的路径不能包包含在oldname中。比如 oldname是/usr/foo,newname是/usr/foo/testdir,这样的rename就是非法的。
(3)...
总之,如果不能顺利执行rename的操作:一是检查oldname和newname的类型;二是检查各种权限
4.17 Symbolic Links
俗称软链接,为了突破硬链接的两个limitations:
(1)硬链接要求link和file都在同一个file system中
(2)只有superuser具有创建directory硬链接的权限
还有一点要注意,凡是涉及到处理文件相关的函数,都需要考虑symbolic links的影响:有的函数只处理link本身,有的就处理link后面实际所指的文件。书上提供了一张表如下:

关于ln -s命令的格式:
ln -s A B
执行的结果是:B是一个symbolic link,指向A
ln -s命令有可能会造成loop的情况。书上的例子如下:

foo是个文件夹;下面有一个testdir是一个symbolic link,并且指向它的上一层目录foo,就构成了一个loop。
如果要解除这个软链接,需要用unlink testdir即可。
这里还需要注意的是,unlink只管解除软链接,并不会follow链接后面跟着的内容。但是如果是open cat这样的命令,是会follow symbolic link后面具体的内容的。见下面的例子:

看到我们让myfile链接到不存在的一个path;虽然ll命令可以正常检索到myfile,但cat命令显然follow了myfile后面link指向的内容,所以报错了。这里有个地方容易让人confuse,虽然myfile是存在的,不存在的/no/such/file,但是报错却报的是myfile不存在;因此,这种情况要提醒自己不要陷进去了。
4.18 Creating and Reading Symbolic Links
int symlink(const char *actualpath, const char *sympath);
int symlinkat(const char *actualpath, int fd, const char *sympath);
上面这俩函数管生成symbolic link的
ssize_t readlink(const char *restrict pathname, char * restrict buf, size_t bufsize);
ssize_t readlinkat(int fd, const char* restrict pathname, char * restrict buf, size_t bufsize);
前面说了open直接打开symbolic link后面跟着的实际文件,如果要打开symbolic link本身,就用上面这俩函数即可。
4.19 File Time & 4.20 futimes, utimensat, and utimes Functions
1. 时间粒度有seconds也有nanoseconds。
2. 记录file和directory的修改时间:
(1)st_atime 访问文件数据的最后时间 可能由read引起
(2)st_mtime 修改文件数据的最后时间 可能由write引起
(3)st_ctime 修改i-node的最后时间 可能由chmod chown引起
系统没有对访问i-node的时间做记录,只对修改i-node的信息做记录
3. 系统提供了几个函数可以修改上述几个针对file的时间
4.21 mkdir, mkdirat, and rmdir Functions
这是创建、删除文件夹的函数:
1. 创建时候注意设置文件夹的权限(尤其是execuate permission)
2. 删之前保证没有其他的资源在使用某个文件夹;指向这个文件夹的link的数目是0
4.22 Reading Directories
这里给出了几个函数,专注处理directroy本身。
1. 这几个函数之间有约定速成的一个结构体DIR 便于数据交换
2. opendir fopendir这里函数负责由一个给定的pathname传回DIR指针
3. 其余的5个函数根据DIR来执行各种操作(比如,迭代directory下面的每个元素)
这部分比较有价值的是给出了一个递归统计某个目录下各个类型的file的数量的代码,实现了简易版的ftw(3)函数。代码虽然比较长,但是值得仔细过一遍,可以学习很多细节。需要具体注意的点,都写在代码注释中了。
#include "apue.h"
#include <dirent.h>
#include <limits.h>
#include <errno.h> /* If PATH_MAX is indeterminate, no guarantee this is adequate */
#define PATH_MAX_GUESS 1024 /*因为path不同于一般的变量 分配的长度是有讲究的 因此单拎出来一个函数
* 1. 返回分配好内存的首地址 也就是指针
* 2. 同时在sizep地址存放被分配的地址的长度*/
char *path_alloc(size_t *sizep) /* also return allocated size, if nonnull */
{
#ifdef PATH_MAX
long pathmax = PATH_MAX;
#else
long pathmax = ;
#endif
char *ptr;
size_t size;
long posix_version = ;
long xsi_version = ; /*系统配置相关*/
posix_version = sysconf(_SC_VERSION);
xsi_version = sysconf(_SC_XOPEN_VERSION); /*这部分代码保证了pathmax在使用前是一个靠谱的非零值*/
if (pathmax == ) { /* first time through */
errno = ;
if ((pathmax = pathconf("/", _PC_PATH_MAX)) < ) {
if (errno == )
pathmax = PATH_MAX_GUESS; /* it's indeterminate */
else
err_sys("pathconf error for _PC_PATH_MAX");
} else {
pathmax++; /* add one since it's relative to root */
}
} /*
* Before POSIX.1-2001, we aren't guaranteed that PATH_MAX includes
* the terminating null byte. Same goes for XPG3.
*/
/*这部分代码处理不同系统带来的size的差异性,最后一个结束字符到底是否计算入pathmax中*/
if ((posix_version < 200112L) && (xsi_version < ))
size = pathmax + ;
else
size = pathmax; if ((ptr = malloc(size)) == NULL)
err_sys("malloc error for pathname"); if (sizep != NULL)
*sizep = size;
return(ptr);
} typedef int Myfunc(const char *, const struct stat *, int); static Myfunc myfunc;
static int myftw(char *, Myfunc *);
static int dopath(Myfunc *); static long nreg, ndir, nblk, nchr, nfifo, nslink, nsock, ntot; #define FTW_F 1 /* file other than directory */
#define FTW_D 2 /* directory */
#define FTW_DNR 3 /* directory that can't be read */
#define FTW_NS 4 /* file that we can't stat */ static char *fullpath; /* contains full pathname for every file */
static size_t pathlen; static int myftw(char *pathname, Myfunc *func)
{
/* 1. 给fullpath分配内存 不能随意的malloc是因为文件路径的长度是有讲究的*/
fullpath = path_alloc(&pathlen);
/* 2. 由于某些原因给fullpath分配长度pathlen不足 小于pathname的长度 因此就需要重新给fullpath分配内存*/
if (pathlen <= strlen(pathname)) {
pathlen = strlen(pathname)*; /*为什么是2倍 因为既要把pathname包含进去 又要把原来的pathlen包含进去 而pathlen是小于pathname的 所以2*pathname是最小代价的内存*/
if ((fullpath=realloc(fullpath, pathlen))==NULL) {
err_sys("realloc failed");
}
}
/* 3. 把pathname复制到fullpath中*/
strcpy(fullpath, pathname);
/* 4. 此时fullpath已经包含了目标原始pathname 则递归遍历*/
return(dopath(func));
} /* 总的来说, 这是一个典型的深度优先搜索的代码路子
* 这里只传递了一个函数指针 其实还有一个参数就完全路径 只不过这个参数以全局变量的形式出现了
* 终止条件:
* 1. 如果无法获取fullpath对应的struct stat 则经过func函数处理后退出
* 2. 如果fullpath对应的不是目录 则经过func函数处理后退出
* 迭代fullpath路径下的各个元素 fullpath+各个元素 形成新的完整路径 再递归处理
*
* 需要注意的是 fullpaht是一个全局变量 保证返回到上一层递归的时候fullpath是干净的*/
static int dopath(Myfunc* func)
{
struct stat statbuf;
struct dirent *dirp;
DIR *dp;
int ret, n;
if (lstat(fullpath, &statbuf)<) { /*stat error*/
return(func(fullpath, &statbuf, FTW_NS));
}
if (S_ISDIR(statbuf.st_mode)==) { /*not a directory*/
return(func(fullpath, &statbuf, FTW_F));
}
/*it's a directory.
* 1. first call func() for the directory,
* 2. then address each filename in the directory
* */
if ((ret=func(fullpath, &statbuf, FTW_D))!=) {
/*让'目录数量'这个全局变量累加*/
return(ret);
}
n = strlen(fullpath);
/*如果初始分配的长度不够 要重新分配fullpath的占用内存大小*/
if (n+NAME_MAX+>pathlen){
pathlen *= ;
if ((fullpath = realloc(fullpath, pathlen)) == NULL) {
err_sys("realloc failed");
}
}
fullpath[n++] = '/';
printf("%s\n",fullpath);
fullpath[n] = ; /*本质的原因是malloc方法分配的内存is not cleared的 可以看man手册查询*/ /*opendir的作用是迭代遍历fullpath下的各个元素*/
if ((dp=opendir(fullpath))==NULL) { /*can't read directory*/
return(func(fullpath, &statbuf, FTW_DNR));
}
/*readdir不断迭代DIR类型指针dp 直到迭代到头*/
while ((dirp=readdir(dp))!=NULL){
if(strcmp(dirp->d_name, ".")== || strcmp(dirp->d_name, "..")==)
continue; /*ignore dot and dot-dot*/
strcpy(&fullpath[n], dirp->d_name); /*补上d_name就形成了完整的路径信息*/
if((ret = dopath(func))!=) /*recursive*/
break; /*这里的策略是一旦有一个子目录无法recursive了 整体就退出了*/
} fullpath[n-] = ; /*这样做是保证了回到上一层之前fullpath是干净的*/
if (closedir(dp)<) err_ret("can't close directory %s", fullpath);
return(ret);
}
/*统计各种类型的文件的数量*/
static int myfunc(const char *pathname, const struct stat *statptr, int type)
{
switch(type)
{
case FTW_F:
switch (statptr->st_mode & S_IFMT)
{
case S_IFREG: nreg++; break;
case S_IFBLK: nblk++; break;
case S_IFCHR: nchr++; break;
case S_IFIFO: nfifo++; break;
case S_IFLNK: nslink++; break;
case S_IFSOCK: nsock++; break;
case S_IFDIR:
err_dump("for S_IFDIR for %s", pathname);
}
break;
ndir++;
break;
case FTW_D:
ndir++;
break;
case FTW_DNR:
err_ret("can't read directory %s", pathname);
break;
case FTW_NS:
err_ret("stat error for %s", pathname);
break;
default:
err_dump("unkown type %d for pathname %s", type, pathname);
}
return();
} int main(int argc, char *argv[])
{
int ret;
if (argc != )
err_quit("usage: ftw <starting-pathname>"); ret = myftw(argv[], myfunc); /* does it all */ ntot = nreg + ndir + nblk + nchr + nfifo + nslink + nsock;
if (ntot == )
ntot = ; /* avoid divide by 0; print 0 for all counts */
printf("regular files = %7ld, %5.2f %%\n", nreg, nreg*100.0/ntot);
printf("directories = %7ld, %5.2f %%\n", ndir, ndir*100.0/ntot);
printf("block special = %7ld, %5.2f %%\n", nblk, nblk*100.0/ntot);
printf("char special = %7ld, %5.2f %%\n", nchr, nchr*100.0/ntot);
printf("FIFOs = %7ld, %5.2f %%\n", nfifo, nfifo*100.0/ntot);
printf("symbolic links = %7ld, %5.2f %%\n", nslink, nslink*100.0/ntot);
printf("sockets = %7ld, %5.2f %%\n", nsock, nsock*100.0/ntot);
exit(ret);
}
再贴一个运行结果:
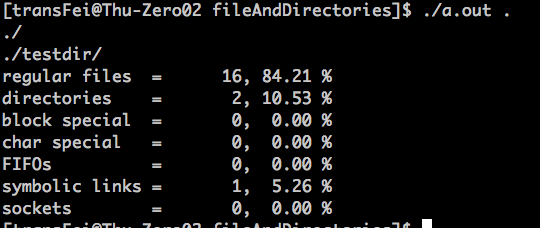
这里注意,输入给函数的参数是'.',在dopath中由lstat函数处理这个'.',间接证明了lstat是可以处理相对路径和绝对路径的。
还有需要注意是path_alloc函数是在APUE的第二张中提到的,我到原书第二章提供的源代码中找到了这个函数的实现,并加以修改。
4.23 chdir, fchdir, and getcwd Functions
1. chdir变换的是当前process的working directory,并不能改变父进程的working directory
2. chidir是会跟着symbolic link往下走的;但是不会逆向往上走:
比如 A->B:如果chidir(A)则会走到B,但是chdir(B)不会跟着走到A
Summary
这一章的核心是stat function,这个函数获得的结构体中包含了文件的各种信息。
【APUE】Chapter4 File and Directories的更多相关文章
- 【APUE】Chapter3 File I/O
这章主要讲了几类unbuffered I/O函数的用法和设计思路. 3.2 File Descriptors fd本质上是非负整数,当我们执行open或create的时候,kernel向进程返回一个f ...
- 【APUE】Chapter10 Signals
Signal主要分两大部分: A. 什么是Signal,有哪些Signal,都是干什么使的. B. 列举了非常多不正确(不可靠)的处理Signal的方式,以及怎么样设计来避免这些错误出现. 10.2 ...
- 【python】类file文件处理
[flush方法] 通常由于缓冲,write不将数据写入文件,而是写入内存的缓冲区,需要使用flush写入文件,并清空缓冲区 文件的flush方法的作用是强制清空缓存写入文件.默认每行flush一下? ...
- 【APUE】Chapter16 Network IPC: Sockets & makefile写法学习
16.1 Introduction Chapter15讲的是同一个machine之间不同进程的通信,这一章内容是不同machine之间通过network通信,切入点是socket. 16.2 Sock ...
- 【APUE】Chapter1 UNIX System Overview
这章内容就是“provides a whirlwind tour of the UNIX System from a programmer's perspective”. 其实在看这章内容的时候,已经 ...
- 【APUE】Chapter17 Advanced IPC & sign extension & 结构体内存对齐
17.1 Introduction 这一章主要讲了UNIX Domain Sockets这样的进程间通讯方式,并列举了具体的几个例子. 17.2 UNIX Domain Sockets 这是一种特殊s ...
- 【APUE】Chapter15 Interprocess Communication
15.1 Introduction 这部分太多概念我不了解.只看懂了最后一段,进程间通信(IPC)内容被组织成了三个部分: (1)classical IPC : pipes, FIFOs, messa ...
- 【APUE】Chapter14 Advanced I/O
14.1 Introduction 这一章介绍的内容主要有nonblocking I/O, record locking, I/O multiplexing, asynchronous I/O, th ...
- 【APUE】Chapter5 Standard I/O Library
5.1 Introduction 这章介绍的standard I/O都是ISOC标准的.用这些standard I/O可以不用考虑一些buffer allocation.I/O optimal-siz ...
随机推荐
- 【洛谷P1100】高低位交换
高低位交换 题目链接 这道题非常水,我是用位运算做的 a=n>>16 二进制的“高位”b=n-(a<<16) 二进制的“低位”ans=(b<<16)+a 转换 #i ...
- 简述 private、 protected、 public、 internal 修饰符的访问权限
简述 private. protected. public. internal 修饰符的访问权限. private : 私有成员, 在该类的内部才可以访问. protected : 保护成员,该类内部 ...
- html基础用法(下)
设计表格: <html> <head> <title>表格</title> <meta charset="utf-8" /&g ...
- docker官方文档翻译3
转载请标明出处: https://blog.csdn.net/forezp/article/details/80171723 本文出自方志朋的博客 第三部分: 服务 准备工作 安装Docker 1.1 ...
- Python基础—10-常用模块:time,calendar,datetime
#常用模块 time sleep:休眠指定的秒数(可以是小数) time:获取时间戳(从1970-01-01 00:00:00到此刻的秒数) localtime:将一个时间戳转换为一个对象,对象中包含 ...
- mysql存储过程和函数(一)
存储过程和函数是事先经过编译并存储在数据库的一段sql语句集合,调用存储过程和函数可以简化应用程序开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对提高数据运行效率是有好处的. 存储过程和 ...
- BigDecimal运算(加、减、乘、除)
public class BigDecimalOperation { private BigDecimalOperation(){ } public static BigDecimal add(dou ...
- c# 本地完整缓存组件
用了一段时间java,java实现服务端程序很简单,有很多公共开源的组件或者软件.但是c#的很少. 现在准备自己写点东西,学习下新的东西,总结下c#的内容以及我们经常用的内容,抽离成类,组件,模型.方 ...
- chromium之pickle
pickle谷歌翻译成泡菜 醉了,看一下头文件的说明 // This class provides facilities for basic binary value packing and unpa ...
- spring boot 搭建基本套路《1》
1. Spring复习 Spring主要是创建对象和管理对象的框架. Spring通过DI实现了IoC. Spring能很大程度的实现解耦. 需要掌握SET方式注入属性的值. 需要理解自动装配. 需要 ...