shell常用语法
一、for、if条件:
https://blog.51cto.com/qiufengsong/1252889
1、for循环:
for i in $(seq );do
echo $i
done ###第一行:seq是指1到10,第二行:echo是打印的意思,打印1到10
2、if条件:
案例:给定一个用户,如果其ID号大于499,就说明其是普通用户,否则,就说明其是管理员或系统用户;
#!/bin/bash # UserName=daemon Uid=`id -u $UserName` if [ $Uid -gt ]; then echo "A common user: $UserName." else echo "admin user or system user: $UserName." fi
与逻辑和if
a_DATA=$
b_TID=$
###注意:写成一下的形式会保存,-a前面如果a_DATA为空的话会出错。
#if [ ! $a_DATA -a $b_TID ] ; then
# -a为and逻辑,如果是或的逻辑,用-o
#注意:[ 前后需要空格 ]
if [ $b_TID -a ! $a_DATA ] ; then
echo "No exit"
echo $b_TID
else
echo $a_DATA
fi

三、一些常用的符号:
https://www.cnblogs.com/yueminghai/p/6382897.html
1、$的一些常用命令:
https://www.cnblogs.com/fhefh/archive/2011/04/15/2017613.html
linux中shell变量$#,$@,$,$,$2的含义解释:
变量说明:
$$
Shell本身的PID(ProcessID)
$!
Shell最后运行的后台Process的PID
$?
最后运行的命令的结束代码(返回值)
$-
使用Set命令设定的Flag一览
$*
所有参数列表。如"$*"用「"」括起来的情况、以"$ $ … $n"的形式输出所有参数。
$@
所有参数列表。如"$@"用「"」括起来的情况、以"$" "$" … "$n" 的形式输出所有参数。
$#
添加到Shell的参数个数
$
Shell本身的文件名
$~$n
添加到Shell的各参数值。$1是第1参数、$2是第2参数…。
示例:
#!/bin/bash
#
printf "The complete list is %s\n" "$$"
printf "The complete list is %s\n" "$!"
printf "The complete list is %s\n" "$?"
printf "The complete list is %s\n" "$*"
printf "The complete list is %s\n" "$@"
printf "The complete list is %s\n" "$#"
printf "The complete list is %s\n" "$0"
printf "The complete list is %s\n" "$1"
printf "The complete list is %s\n" "$2 结果:
[Aric@localhost ~]$ bash params.sh QQ
The complete list is
The complete list is
The complete list is
The complete list is QQ
The complete list is
The complete list is QQ
The complete list is
The complete list is params.sh
The complete list is
The complete list is QQ
2、冒号:
示例
: ${JOB_USER:=hadoop}
: ${VAR:=DEFAULT}
当变量VAR没有声明或者为NULL时,将VAR设置为默认值DEFAULT。如果不在前面加上:命令,那么就会把${VAR:=DEFAULT}本身当做一个命令来执行,报错是肯定的。
3、倒引号`、双引号“”、单引号‘’
https://blog.csdn.net/jackyechina/article/details/52813007
比如 `dirname $0`, 就表示需要执行 dirname $0 这个命令
【“”】 , 被双引号括起来的内容, 里面 出现 $ (美元号: 表示取变量名) `(倒引号: 表示执行命令) \(转义号: 表示转义), 其余的才表示字符串。
【’‘】, 被单引号括起来的内容, 里面所有的都表示串, 包括上面所说的 三个特殊字符。
在命令行状态下单纯执行 $ cd `dirname $0` 是毫无意义的。因为他返回当前路径的"."。
这个命令写在脚本文件里才有作用,他返回这个脚本文件放置的目录,并可以根据这个目录来定位所要运行程序的相对位置(绝对位置除外)。
$0:当前Shell程序的文件名
dirname $0,获取当前Shell程序的路径
cd `dirname $0`,进入当前Shell程序的目录
在/home/admin/test/下新建test.sh内容如下:
- cd `dirname $0`
- echo `pwd`
然后返回到/home/admin/执行
- sh test/test.sh
运行结果:
- /home/admin/test
这样就可以知道一些和脚本一起部署的文件的位置了,只要知道相对位置就可以根据这个目录来定位,而可以不用关心绝对位置。这样脚本的可移植性就提高了,扔到任何一台服务器,(如果是部署脚本)都可以执行。
4、.(点命令):
读取并且在当前的shell中执行文件中的命令,点命令是source命令的简写。
三、常用的函数工具
1、export
用来设置环境变量
2、cut
cut 命令从文件的每一行剪切字节、字符和字段并将这些字节、字符和字段输出。
1.基本用法
cut [选项参数] filename
说明:默认分隔符是制表符
2、选项参数说明

3、案例实操



3、sed
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
1、sed文本处理工具的用法:
- 用法1:前置命令 | sed [选项] '条件指令'
- 用法2:sed [选项] '条件指令' 文件

命令功能描述:
a:新增,a的后面可以接字串,在下一行出现
d:删除
s:查找并替换,s/旧/新/g,加g代表替换一行的所有(global)
p:打印过滤,前面常加行数号。
i:插入
c:整行替换
r:sed 'r b.txt' a.txt 读取b.txt到a.txt
w:sed 'w b.txt' a.txt 把a.txt另存为b.txt
h(覆盖复制) g(覆盖粘贴)
H (追加复制) G (追加粘贴)
选项参数:
-e:直接在指令列表模式上进行sed的动作编辑。
-n(屏蔽默认输出,默认sed会输出读取文档的全部内容)
-r(让sed支持扩展正则)
-i(sed直接修改源文件,默认sed只是通过内存临时修改文件,源文件无影响)
2、案例实操(摘自 并详看:https://blog.csdn.net/qq_36441027/article/details/80161570)
1)sed命令的 -n 选项和p指令
打印第3行: sed -n '3p' /etc/passwd
打印第3到5行: sed -n '3,5p' /etc/passwd
打印第3和5行: sed -n '3p;5p' /etc/passwd
打印第3以及后面的10行: sed -n '3,+10p' /etc/passwd
打印奇数行: sed -n '1~2p' /etc/passwd
打印偶数行: sed -n '2~2p' /etc/passwd
打印以bin开头的行:sed -n '/^bin/p' /etc/passwd
输出文件的行数:sed -n '$=' /etc/passwd
打印包含root的行:sed -n '/root/p' /etc/passwd 【正则表达式】
打印bash结尾的行: sed -n '/bash$/p' /etc/passwd 【正则表达式】
执行p打印等过滤操作时,希望看到的是符合条件的文本。但不使用任何选项时,默认会将原始文本一并输出,从而干扰过滤效果。比如,尝试用sed输出/etc/hosts的第1行:
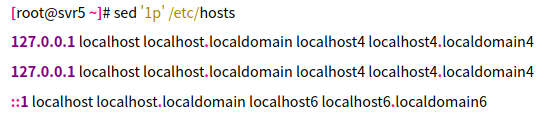
可以发现所有的行都被显示出来了(第1行重复2次)。—— 正确的用法应该添加 -n 选项,这样就可以只显示第1行了:
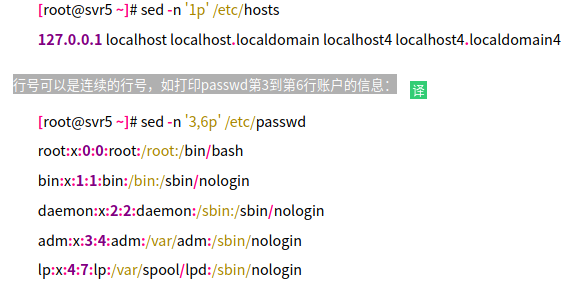
2)sed命令的 -i 选项

3)sed命令的d、s指令
d指令:删除
删除第3~5行:sed '3,5d' a.txt
删除所有包含xml的行:sed '/xml/d' a.txt
删除不包含xml的行:sed '/xml/!d' a.txt
删除以install开头的行:sed '/^install/d' a.txt
删除文件的最后一行:sed '/$d' a.txt
删除所有空行:sed '^$' a.txt
s指令:替换
替换操作的分隔“/”可改用其他字符,如#、&等,便于修改文件路径
test.txt内容:
2017 2011 2018
2017 2017 2024
2017 2017 2017
sed 's/2017/XXXX/' test.txt
#将每一行第一个2017换成XXXX
结果:
XXXX 2011 2018
XXXX 2017 2024
XXXX 2017 2017 sed -n 's/2017/XXXX/p' test.txt
结果:
XXXX 2011 2018
XXXX 2017 2024
XXXX 2017 2017 sed 's/2017/AAAAA/g' test.txt
#将所有的2017换成AAAAA
结果:
AAAAA 2011 2018
AAAAA AAAAA 2024
AAAAA AAAAA AAAAA sed 's/2017/XXXXX/2' test.txt
#把每一行第2个2017换成XXXXX
结果:
2017 2011 2018
2017 XXXXX 2024
2017 XXXXX 2017 sed 's/2017//2' test.txt
# 将每一行第2个2017都替换成空串,即删除,如果是所有则把2换成g
结果:
2017 2011 2018
2017 2024
2017 2017 sed 's#/bin/bash#/sbin/sh#' test.txt #将/bin/bash替换为/sbin/sh
sed '4,7s/^/#/' test.txt #/将第4~7行注释掉(行首加#号)
sed 's/^#an/an/' test.txt #//解除以#an开头的行的注释(去除行首的#号)
4)sed命令的a指令:增加
- 在第二行后面,追加XX:sed '2a XX' test.txt
- 在第二行前面,插入XX:sed '2i XX' test.txt
- 将第二行替换为XX(c整行替换):sed '2c XX' a.txt
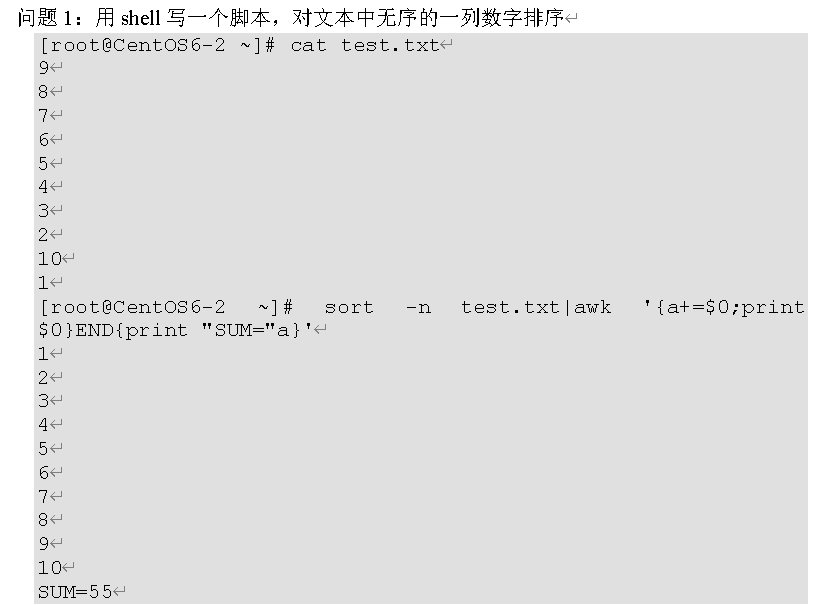
问题1:
本案例要求熟悉sed命令的p、d、s等常见操作,并结合正则表达式,完成以下任务:
- 删除文件中每行的第二个、最后一个字符 : sed 's/.//2 ; s/.$//' nssw.txt
- 将文件中每行的第一个、倒数第1个字符互换 :sed -r 's/^(.)(.*)(.)$/\3\2\1/' nssw.txt
【每行文本拆分为“第1个字符”、“中间的所有字符”、“倒数第1个字符”三个部分,然后通过替换操作重排顺序为“3-2-1”】
- 删除文件中所有的数字和行首空格:sed -r 's/[0-9]//g;s/^( )+//' nssw.txt
- 为文件中每个大写字母添加括号:sed 's/([A-Z])/[\1]/g' nssw.txt



4、awk
一个强大的文本分析处理工具,把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行分析处理。
【1】基本操作方法:格式:awk [选项] '[条件]{指令}' 文件
其中,print 是最常用的编辑指令;若有多条编辑指令,可用分号分隔。
Awk过滤数据时支持仅打印某一列,如第2列、第5列等。
处理文本时,若未指定分隔符,则默认将空格、制表符等作为分隔符。
【2】awk处理的时机:
awk会逐行处理文本,支持在处理第一行之前做一些准备工作,以及在处理完最后一行之后做一些总结性质的工作。在命令格式上分别体现如下:
awk [选项] ' BEGIN{指令} {指令} END{指令}' 文件
- BEGIN{ } 行前处理,读取文件内容前执行,指令执行1次
- { } 逐行处理,读取文件过程中执行,指令执行n次
- END{ } 行后处理,读取文件结束后执行,指令执行1次
【3】选项参数:
-F:制定输入文件分割符
-v:赋值一个用户定义变量
【4】内置变量:
$1 文本的第1列
$2 文件的第2列,以此类推
FILENAME:文件名
NR:文件当前行的行号
NF:文件当前行的列数(有几列)
【4】案例实操
print直接过滤文件内容:
- awk '{print $1,$3}' test.txt //打印文档第1列和第3列
- df -h | awk '{print $4}' //打印磁盘的剩余空间,即df -h显示的第四列,(结合管道过滤命令)
- awk -F: '{print $1,"的解释器:",$7}' /etc/passwd //awk的print指令不仅可以打印变量,还可以打印常量

选项 -F 可指定分隔符:
awk -F"[01]" '{}' 这种形式指定的分隔符是或的关系,即0或1作为分隔符;
awk -F"[0][1]" '{}' 这种形式指定的分隔符是合并的关系,即以“01”作为一个字符为分隔符。
- awk -F: '{print $1,$7}' /etc/passwd //输出passwd文件中以冒号分隔的第1、7个字段,显示的不同字段之间以逗号隔开
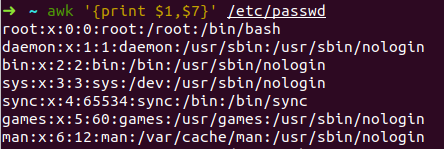
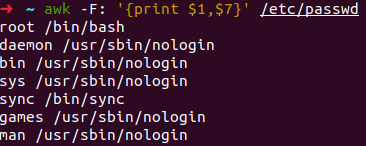
- awk -F "[:/]" '{print $1,$10}' /etc/passwd //awk还识别多种单个的字符,比如以“:”或“/”分隔,输出第1、10个字段:

- awk -F: '/bash$/{print}' /etc/passwd //输出其中以bash结尾的完整记录
- awk -F: '/root/' /etc/passwd //输出包含root的行数据: (因为awk最主要的功能打印,指令不写也能把那一行打印出来)
- awk -F: '/^(root|adm)/{print $1,$3}' /etc/passwd //输出root或adm账户的用户名和UID信息
- awk -F: '$1~/root/' /etc/passwd //输出账户名称包含root的基本信息(第1列包含root):(~:代表正则匹配,模糊匹配)
- awk -F: '$7!~/nologin$/{print $1,$7}' /etc/passwd //输出其中登录Shell不以nologin结尾(对第7个字段做!~反向匹配)的用户名、登录Shell信息
- awk -F: '$3>=1000{print $1,$3}' /etc/passwd //输出账户UID大于等于1000的账户名称和UID信息
- awk -F: '$3<10{print $1,$3}' /etc/passwd //输出账户UID小于10的账户名称和UID信息
- awk -F: '$1=="root"' /etc/passwd //输出用户名为“root”的行: (在awk中字符串要引起来)
- awk -F: '$3>10 && $3<20' /etc/passwd //输出账户UID大于10并且小于20的账户信息
- awk -F: '$3>1000 || $3<10' /etc/passwd //输出账户UID大于1000或者账户UID小于10的账户信息
- seq 100 | awk '$1%7==0||$1~/7/{print}' //列出100以内整数中7的倍数或是含7的数
- seq 2018 | awk '($1%4==0&&$1%100!=0)||$1%400==0' | wc -l //出100以内整数中7的倍数或是含7的数
内置变量:
输出每次处理的行号,以及当前行以“:”分隔的字段个数:
- awk -F: '{print NR,NF}' passwd.txt
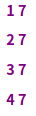
- awk -F: 'NR==3{print}' /etc/passwd //输出第3行(行号NR等于3)的用户记录
原文链接:https://blog.csdn.net/qq_36441027/article/details/80186784
awk处理时机:
1、只做预处理的时候,可以没有操作文件,如:
- awk 'BEGIN{A=24;print A*2}'
- awk 'BEGIN{print x+1}'
- awk 'BEGIN{print 3.2+3.5}'
- awk 'BEGIN{x++;print x}'
- awk 'BEGIN{x=8;print x+=2}'
- awk 'BEGIN{x=8;x--;print x}'
2、举个例子(统计系统中使用bash作为登录Shell的用户总个数):
a.预处理时赋值变量x=0
b.然后逐行读入/etc/passwd文件,如果发现登录Shell是/bin/bash则x加1
c.全部处理完毕后,输出x的值即可。相关操作及结果如下:
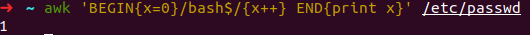
3、格式化输出/etc/passwd文件
要求: 格式化输出passwd文件内容时,要求第一行为列表标题,中间打印用户的名称、UID、家目录信息,最后一行提示一共已处理文本的总行数,如图-1所示。

awk -F: 'BEGIN{print "User\tUID\tHome"} \
{print $1 "\t" $3 "\t" $6} \
END{print "Total",NR,"lines."}' /etc/passwd | column -t
awk过滤中的if分支结构
- awk -F: '{if($3<=1000){i++}}END{print i}' /etc/passwd // 统计/etc/passwd文件中UID小于或等于1000的用户个数
- awk -F: '{if($3>1000){i++}}END{print i}' /etc/passwd //统计/etc/passwd文件中UID大于1000的用户个数
- awk -F: '{if($7~/bash$/){i++}}END{print i}' /etc/passwd //统计/etc/passwd文件中登录Shell是“/bin/bash”的用户个数
- awk -F: '{if($3<=500){i++}else{j++}}END{print i,j}' /etc/passwd //分别统计/etc/passwd文件中UID小于或等于1000、UID大于1000的用户个数
- awk -F: '{if($7~/bash$/){i++}else{j++}} END{print i,j}' /etc/passwd //分别统计/etc/passwd文件中登录Shell是“/bin/bash”、 登录Shell不是“/bin/bash”的用户个数
awk数组
1)数组的语法格式
数组是一个可以存储多个值的变量,具体使用的格式如下:
定义数组的格式:数组名[下标]=元素值
调用数组的格式:数组名[下标]
遍历数组的用法:for(变量 in 数组名){print 数组名[变量]}。
- awk 'BEGIN{a[0]=11;a[1]=88;print a[1],a[0]}'
- awk 'BEGIN{a[0]=00;a[1]=11;a[2]=22; for(i in a){print i,a[i]}}'
- awk 'BEGIN{a["hehe"]=11;print a["hehe"]}' //awk数组的下标除了可以使用数字,也可以使用字符串,字符串需要使用双引号




5、sort
sort命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出。


自动判断
中文
中文(简体)
中文(香港)
中文(繁体)
英语
日语
朝鲜语
德语
法语
俄语
泰语
南非语
阿拉伯语
阿塞拜疆语
比利时语
保加利亚语
加泰隆语
捷克语
威尔士语
丹麦语
第维埃语
希腊语
世界语
西班牙语
爱沙尼亚语
巴士克语
法斯语
芬兰语
法罗语
加里西亚语
古吉拉特语
希伯来语
印地语
克罗地亚语
匈牙利语
亚美尼亚语
印度尼西亚语
冰岛语
意大利语
格鲁吉亚语
哈萨克语
卡纳拉语
孔卡尼语
吉尔吉斯语
立陶宛语
拉脱维亚语
毛利语
马其顿语
蒙古语
马拉地语
马来语
马耳他语
挪威语(伯克梅尔)
荷兰语
北梭托语
旁遮普语
波兰语
葡萄牙语
克丘亚语
罗马尼亚语
梵文
北萨摩斯语
斯洛伐克语
斯洛文尼亚语
阿尔巴尼亚语
瑞典语
斯瓦希里语
叙利亚语
泰米尔语
泰卢固语
塔加路语
茨瓦纳语
土耳其语
宗加语
鞑靼语
乌克兰语
乌都语
乌兹别克语
越南语
班图语
祖鲁语
自动选择
中文
中文(简体)
中文(香港)
中文(繁体)
英语
日语
朝鲜语
德语
法语
俄语
泰语
南非语
阿拉伯语
阿塞拜疆语
比利时语
保加利亚语
加泰隆语
捷克语
威尔士语
丹麦语
第维埃语
希腊语
世界语
西班牙语
爱沙尼亚语
巴士克语
法斯语
芬兰语
法罗语
加里西亚语
古吉拉特语
希伯来语
印地语
克罗地亚语
匈牙利语
亚美尼亚语
印度尼西亚语
冰岛语
意大利语
格鲁吉亚语
哈萨克语
卡纳拉语
孔卡尼语
吉尔吉斯语
立陶宛语
拉脱维亚语
毛利语
马其顿语
蒙古语
马拉地语
马来语
马耳他语
挪威语(伯克梅尔)
荷兰语
北梭托语
旁遮普语
波兰语
葡萄牙语
克丘亚语
罗马尼亚语
梵文
北萨摩斯语
斯洛伐克语
斯洛文尼亚语
阿尔巴尼亚语
瑞典语
斯瓦希里语
叙利亚语
泰米尔语
泰卢固语
塔加路语
茨瓦纳语
土耳其语
宗加语
鞑靼语
乌克兰语
乌都语
乌兹别克语
越南语
班图语
祖鲁语
有道翻译
百度翻译
谷歌翻译
谷歌翻译(国内)
翻译 朗读 复制 正在查询,请稍候…… 重试 朗读 复制 复制 朗读 复制 via 谷歌翻译(国内)译
awk -F: '{print NR,NF}' passwd.txt
格式化输出/etc/passwd文件
格式化输出/etc/passwd文件
输出用户名为“root”的行: (在awk中字符串要引起来)
shell常用语法的更多相关文章
- linux shell常用语法
特殊变量 $0 当前脚本的文件名$n 传递给脚本或函数的参数.n 是一个数字,表示第几个参数.例如,第一个参数是$1,第二个参数是$2.$# 传递给脚本或函数的参数个数.$* 传递给脚本或函数的所有参 ...
- [Shell]常用语法
赋值 FILE=$1 //=两边不能有空格 echo $FILE 逻辑判断 表达式 .if [ expression ]; then ... fi //[]两边必须有空格 . if [[ expres ...
- 【shell 大系】Linux Shell常用技巧
在最近的日常工作中由于经常会和Linux服务器打交道,如Oracle性能优化.我们数据采集服务器的资源利用率监控,以及Debug服务器代码并解决其效率和稳定性等问题.因此这段时间总结的有关Linux ...
- Linux Shell常用技巧(目录)
Linux Shell常用技巧(一) http://www.cnblogs.com/stephen-liu74/archive/2011/11/10/2240461.html一. 特殊文件: /dev ...
- PHP中Smarty引擎的常用语法
PHP中Smarty引擎的常用语法 输出今天的日期: {$smarty.now|date_format:"%H:%M %A, %B %e, %Y"} 实际上用到了PHP的time( ...
- saltstack常用语法
一.常用语法 1.添加用户 示例1: #添加zabbix用户和组 zabbix: group.present: - name: zabbix - gid: 1001 user.present: - f ...
- Shell脚本语法---在Makefile等文件…
1. Shell脚本语法 1.1. 条件测试:test [ 命令test或[可以测试一个条件是否成立,如果测试结果为真,则该命令的Exit Status为0,如果测试结果为假,则命令的Exit Sta ...
- Shell的语法
Shell的语法: 变量:字符串.数字.环境和参数: 条件:shell中的布尔值: 程序控制:if.elif.for.while.until.case: 命令列表: 函数: Shell内置命令: 获取 ...
- 1、uiautomator2常用语法
uiautomator2常用语法 连接设备 使用USB连接: d=u2.connect_USB('148b4090')输入手机序列号 d是给当前连接设备定位一个变量 获取设备的信息: print(d. ...
随机推荐
- cogs 22. [HAOI2005] 路由选择问题
22. [HAOI2005] 路由选择问题 ★★★ 输入文件:route.in 输出文件:route.out 简单对比时间限制:1 s 内存限制:128 MB [问题描述] X城有一个 ...
- Linux - Virsh
virsh命令 suspend resume dumpxml KVM平台以存储池的形式对存储进行统一管理,所谓存储池能够理解为本地文件夹.通过远端磁盘阵列(iSCSI.NFS)分配过来磁盘或文件夹 ...
- Oracle 自己主动内存管理 SGA、PGA 具体解释
ASMM自己主动共享内存管理: 自己主动依据工作量变化调整 最大程度地提高内存利用率 有助于消除内存不足的错误 SYS@PROD>show parameter sga NAME ...
- Unable to instantiate Action, xxxAction, defined for 'xxx' in namespace '/'xxxAction解决方式
出现这个问题的解决办法主要有两个 1.假设项目没有使用Spring,则struts.xml配置文件里,这个action的class属性的路径没有写完整,应该是包名.类名 2.假设项目使用了Spring ...
- Wscript对象具体解释
15.6 Windows脚本宿主的内建对象 每一个编程环境都提供了自己的对象模型,开发者 能够使用这些对象模型实现各种解决方式,WSH也不例外.WSH包括了一组核心对象,分别包括了属性和方法,能够用 ...
- 新手玩个人server(阿里云)
阿里云如火如荼的0元活动,事实上一開始我仅仅是去直播吧看阿森纳vs贝西克塔斯.姑且算是一种乱入,url这样的奇妙的东西应该是万维网的最真实的写照.当然那是上周第一会回合的事了.可是故事却如此的类似.并 ...
- oc30--id
// // Person.h #import <Foundation/Foundation.h> @interface Person : NSObject - (void)sleep; @ ...
- poj--3061--Subsequence(贪心)
Subsequence Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 10882 Accepted: 4498 Desc ...
- jQuery获取及设置单选框、多选框、文本框
获取一组radio被选中项的值 var item = $("input[@name=items][@checked]").val(); 获取select被选中项的文本 var it ...
- .net中的WebForm引人MVC的控制器
当下.net中比较火的模式MVC模式,说实话对于菜鸟的我还没有遇到一个比较健全的MVC模式的项目也是比较遗憾.偶然间在网上看到WebForm实现MVC中的模式(主要是控制器...)就学习了一波,下面是 ...