Solr学习记录:Getting started
Solr学习记录:Getting started
本教程使用环境:java8或者更高版本、Solr8.1、centos7
1.Solr Tutorial
1.1简介
本篇将用三个部分具体练习以引领对Solr的快速体验。每个练习将基于前一个练习。
- 第一个练习:启动solr,创建一个Collection,索引一些基础文档,执行一些搜索。
- 第二个练习:使用不同数据集,并尝试用其访问页面。
- 第三个练习:开始使用自己的数据,并为实现制定计划。
1.2 解压Solr
方便统一操作,我们将solr安装在/opt 路径下
~$ mv solr-7.7.0.zip /opt/
~$ unzip -q solr-7.7.0.zip
#或者是:tar -zxvf solr-7.7.0.zip
~$ cd solr-7.7.0/
1.3 练习一:索引Techproducts样例数据
目标:
- 以双节点集群启动Solr(同一台机器上),并且在启动期间创建一个collection。
- 为这些样例数据建立索引,并做一些基础的搜索工作。
以SolrCloud模式启动Solr(基于zookeeper的分布式搜索)
启动Solr
bin/solr start -e cloud。注:这将开启一个交互式会话,在机器上开启两个Solr服务。
solr-7.7.0:$ ./bin/solr start -e cloud
Welcome to the SolrCloud example!
This interactive session will help you launch a SolrCloud cluster on your local workstation.
To begin,how many Solr nodes would you like to run in your local cluster? (specify 1-4 nodes)[2]:
你想在本地集群创建多少个节点,默认2个。本例中只需两个节点,直接Enter默认。为建立外部zookeeper集群,因此solr将连接内置的zookeeper。
分别为两个节点选择端口号
#第一个节点
Ok, let's start up 2 Solr nodes for your example SolrCloud cluster.
Please enter the port for node1 [8983]:
#第二个节点
Please enter the port for node2 [7574]:
除非你了解这两个节点已经被占用,我们建议直接Enter选择默认节点即可。
启动完成后将创建一个collection,并要求为其取名
Now let's create a new collection for indexing documents in your 2-node cluster.
Please provide a name for your new collection: [gettingstarted]
在后面我们将索引一些solr下称作
techproducts数据的样例数据,所以为了区别于其他的collection,我们将其命名为techproducts。在提示处键入techproducts并回车确认。在两个节点间拆分索引分片
How many shards would you like to split techproducts into? [2]
选择默认的2,意味着在两个节点间相对平均地进行索引分片。对于我们的双节点集群来说,默认选项是个好的选择。
为分片创建副本
How many replicas per shard would you like to create? [2]
回车默认即可。分片的副本一般会在多个节点中保存,当然此例中仅有两个节点。
为我们创建的collection选择一个配置文件
Please choose a configuration for the techproducts collection, available options are:
_default or sample_techproducts_configs [_default]
一个collection必须要有一个configSet(sets of configuration files),solr提供了两个可直接使用的configSet
- _default:这是一个最基本的选项
- sample_techproducts_configs:支持我们想要使用的样例数据。
由于本实验将使用solr提供的样例数据,所以回车默认即可。
一个configSet至少包含两个主配置文件schema file(schema.xml或者managed-schema)以及solrConfig.xml
通过solr提供的
bin/post工具采集样例数据bin/post -c techproducts example/exampledocs/*
若无报错,可通过 http://ip:8983/solr/#/techproducts/query来访问solr的图形管理界面,如下:
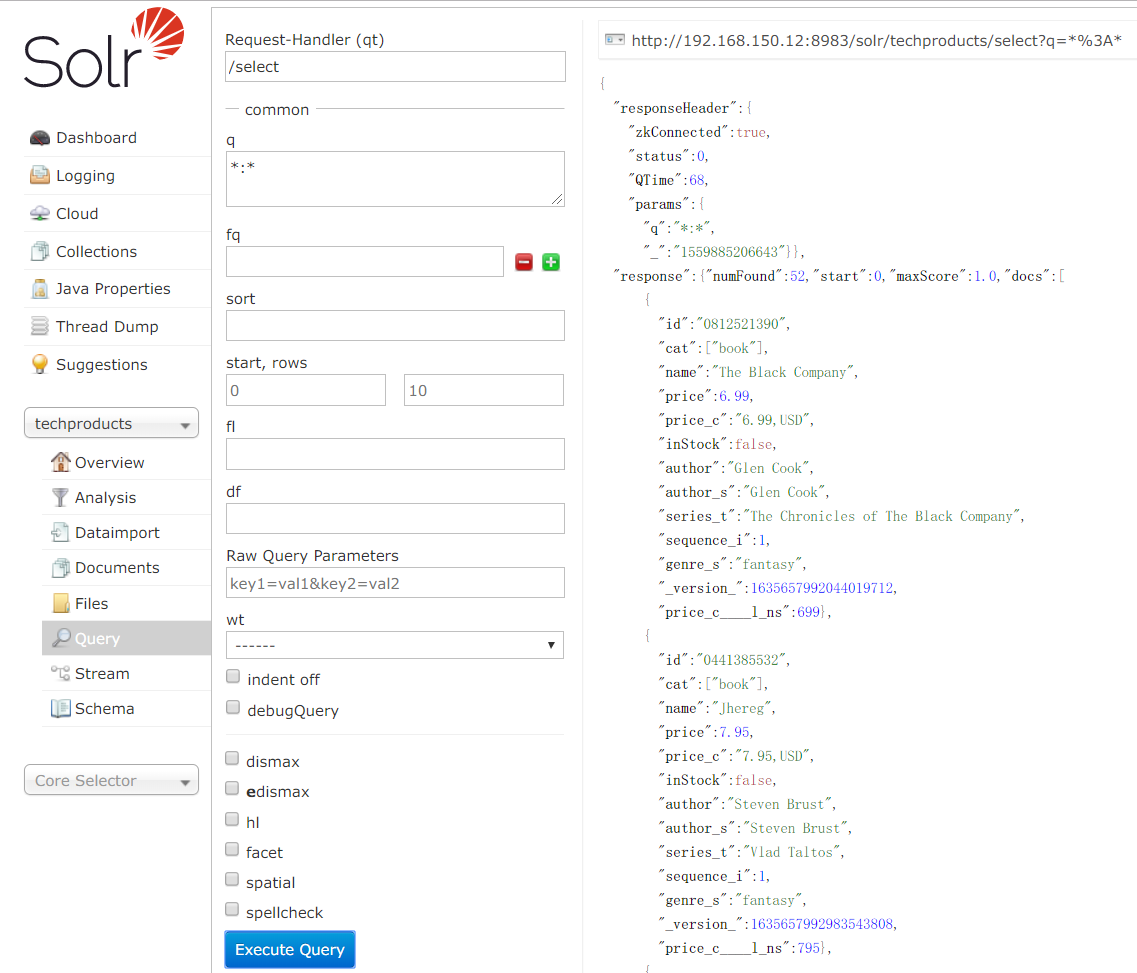
下面简单介绍一下这个图形管理界面的一些信息:
标号为q的文本框:qBox。它支持单术语搜索和多术语搜索(即短语搜索),多术语搜索时,只 要其中一个在索引中匹配到了solr就返回其结果。qBox还支持组合搜索,术语前加“+”号,表示必须匹配,相反,加“-”号表示,禁 止匹配该术语。rowsBox限制最大返回条数。
8. 额外补充命令
#删除collection
bin/solr delete -c techproducts
#创建自己的collection
bin/solr create -c <yourCollection> -s 2 -rf 2
#关闭Solr所有的节点
bin/solr stop -all
9. 在启动过程中可能遇到的问题,以及注意事项
以非root用户启动solr,为此创建普通用户solr
useradd solr && echo "1234"|passwd --stdin solrSolr用户对solr的安装目录及其子目录(文件)须得有访问权限,在此我们直接将其所属者改为solr
chown solr:solr /opt/solr-7.7.2安装好
lsof这个工具(用于展示已经打开的文件),solr需要使用这个东西。将solr可执行文件路径导入环境变量,方便操作(直接输入命令,无需加绝对路径)。修改solr家目录下的
.bash_profile或者/etc/profile都可以,修改内容如下:export SOLR_HOME=/opt/solr-7.7.2
export PATH=$PATH:$SOLR_HOME/bin
若是在虚拟机或者远程服务器中运行,必须要开启防火墙中相应的端口号。
1.4 练习二:修改Schema和Films Data
重启Solr节点
./bin/solr start -c -p 8983 -s example/cloud/node1/solr
./bin/solr start -c -p 7574 -s example/cloud/node2/solr -z localhost:9983
什么是schema
schema是一个独立的xml文件,它存储着:
- solr能够理解的字段以及字段类型的详细信息
- 一个字段在索引前所作的修改。
- 支持包含通配符的动态搜索
创建新的collection
因为本练习使用的全新的数据集,所以新建collection。使用默认的configSet,它包含一个最小化的schema,由solr自行根据数据推断出要添加哪些字段信息。
#分别指定collection的名字,shard和replicas的数量
bin/solr create -c films -s 2 -rf 2
注:当我们不指定configSet时,他默认就使用_default这个configSet
Preparing Schemaless for the Films Data
使用
_defaultconfigSet,schama有两点注意:- 我们将使用
managed schema,他被配置为只能使用Solr提供的Schema API来做修改。Schema API允许我们修改字段、字段类型以及其他schema规则。 - 使用在
solrconfig.xml中配置的"field guessing"。这使得我们在索引文档前无需手动添加字段,直接启动solr,这就是他叫做schemaless的原因。
但是“field guessing”这种简单粗暴的方式也是有缺陷的。一旦它“guess wrong”,那么你除非重新索引,否则无法修改字段信息。而如果这个索引量非常庞大的话就很可怕了。解决方式:schema api与schemaless混合使用,利用schema api定义一个或几个关键字段,剩余的非关键字段交给solr去guess。
- 我们将使用
Create the "names" Field
- curl命令:定义字段“name”,类型为“text_general”
curl -X POST -H 'Content-type:application/json' --data-binary '{"add-field": {"name":"name",
"type":"text_general", "multiValued":false, "stored":true}}'
http://localhost:8983/solr/films/schema
- Admin UI创建
Create a "catchall" Copy Field
从所有字段中采集数据,并建立索引到一个叫做
_text_的字段中。- curl命令
curl -X POST -H 'Content-type:application/json' --data-binary '{"add-copy-field" :
{"source":"*","dest":"_text_"}}' http://localhost:8983/solr/films/schema
- Admin UI创建
索引样例Film Data
#To Index JSON Format
bin/post -c films example/films/films.json
#To Index XML Format
bin/post -c films example/films/films.xml
#To Index CSV Format
bin/post -c films example/films/films.csv -params
"f.genre.split=true&f.directed_by.split=true&f.genre.separator=|&f.directed_by.separator=|"
参数解释
- -c 指定collection的名字。
- /films/films.json (or films.xml or films.csv):指定要采集的数据文件
Faceting
将查询的结果分类,并且统计每个分类的数量
Field Facets
#按"genre"字段分组,并统计数量
curl "http://localhost:8983/solr/films/select?q=*:*&rows=0&facet=true&facet.field=genre_str"
#使用facet.mincount限制返回返回分类数量的最小值
curl "http://localhost:8983/solr/films/select=&q=*:*&facet.field=genre_str&facet.mincount=200&fa
cet=on&rows=0"
Range Facets
对返回的结果分段,而不是一堆零碎的结果
curl 'http://localhost:8983/solr/films/select?q=*:*&rows=0'\
'&facet=true'\
'&facet.range=initial_release_date'\
'&facet.range.start=NOW-20YEAR'\
'&facet.range.end=NOW'\
'&facet.range.gap=%2B1YEAR'
- facet.range.start:设置最低下限
- facet.range.end:设置最高上限
- facet.range.gap:设置步进
Pivot Facets
允许使用两个至多个字段嵌套为各种可能的组合
#以逗号分隔多字段
#返回某一类型的film由同意导演执导的影片数量
curl "http://localhost:8983/solr/films/selectq=*:*&rows=0&facet=on&facet.pivot=genre_str,directe
d_by_str
收尾:删除本实验的collection
bin/solr delete -c films
1.5 练习三: Index Your Own Data
在最后一个练习中,我们将探索索引本地数据,而不再是solr提供的样例数据
在实验开始之前,先创建将要使用的collection
bin/solr create -c myfiles -s 2 -rf 2
Indexing Ideas(solr索引数据的各种方法)
Local Files with
bin/post数据格式: JSON,XML,CSV,HTML,PDF,MS word,纯文本等。
数据准备: 假设数据放在家目录下,~/myDocument
数据采集:
bin/post -c myfiles ~/myDocumentDataImportHandler
用于连接数据库、邮件服务,或者其他结构化的数据源
SolrJ
一个用于和Solr交互的,基于java的客户端。通过编码创建文档发送到solr。
Documents Screen
通过Admin UI提供的Document Tab添加索引文档。
Updating Data
无论索引多少次都不会出现相同的结果,因为在schema中指定了唯一字段id。当向Solr添加新的文档,这个唯一值存在重复时,那么新的文档将会自动替换旧的文档。
Deleting Data
清除collection中的数据并不会改变事先对字段的定义。
#删除指定文档
bin/post -c myfiles -d "<delete><id>SP2514N</id></delete>"
#删除所有文档
bin/post -c myfiles -d "<delete><query>*:*</query></delete>"
收尾
停止solr,并将环境重置到初始状态
bin/solr stop -all ; rm -Rf example/cloud/
2. A Quick Overview
Solr学习记录:Getting started的更多相关文章
- Solr学习总结(六)SolrNet的高级用法(复杂查询,分页,高亮,Facet查询)
上一篇,讲到了SolrNet的基本用法及CURD,这个算是SolrNet 的入门知识介绍吧,昨天写完之后,有朋友评论说,这些感觉都被写烂了.没错,这些基本的用法,在网上百度,资料肯定一大堆,有一些写的 ...
- Solr学习笔记之3、Solr dataimport - 从SQLServer导入数据建立索引
Solr学习笔记之3.Solr导入SQLServer数据建立索引 一.下载MSSQLServer的JDBC驱动 下载:Microsoft JDBC Driver 4.0 for SQL Server ...
- Solr学习笔记之1、环境搭建
Solr学习笔记之1.环境搭建 一.下载相关安装包 1.JDK 2.Tomcat 3.Solr 此文所用软件包版本如下: 操作系统:Win7 64位 JDK:jdk-7u25-windows-i586 ...
- Solr学习之二-Solr基础知识
一 基本说明 简单来说Solr是基于Lucene的高性能的,开源的Java企业搜索服务器.Solr可以看作一个Web app,运行在tomcat或Jetty这类HTTP服务器上, 底层是一个基于Luc ...
- Solr学习之四-Solr配置说明之二
上一篇的配置说明主要是说明solrconfig.xml配置中的查询部分配置,在solr的功能中另外一个重要的功能是建索引,这是提供快速查询的核心. 按照Solr学习之一所述关于搜索引擎的原理中说明了建 ...
- solr学习笔记-入门
solr学习笔记 1.安装前准备 solr依赖java 8 运行环境,所以我们先安装java.如果没有java环境无法启动solr服务,并且会看到如下提示: [root@localhost solr- ...
- solr学习(一)安装与部署
经过测试,同步MongoDB数据到Solr的时候,Solr版本为8.4.0会出现连接不上的错误,8.3.0未经测试不知,博主测试好用的一版为8.2.0,但是官网已经下不到了,所以我会把下载链接放在文末 ...
- Quartz 学习记录1
原因 公司有一些批量定时任务可能需要在夜间执行,用的是quartz和spring batch两个框架.quartz是个定时任务框架,spring batch是个批处理框架. 虽然我自己的小玩意儿平时不 ...
- Java 静态内部类与非静态内部类 学习记录.
目的 为什么会有这篇文章呢,是因为我在学习各种框架的时候发现很多框架都用到了这些内部类的小技巧,虽然我平时写代码的时候基本不用,但是看别人代码的话至少要了解基本知识吧,另外到底内部类应该应用在哪些场合 ...
随机推荐
- Android 四大组件学习之ContentProvider五
上几节学习了ContentProvider的实际用途,读取短信.插入短信,读取联系人.插入联系人等. 本节课在学习ContentProvider的观察者. 在生活中有第三方的软件.比方什么短信软件.此 ...
- HDOJ题目3440 House Man(差分约束)
House Man Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total ...
- [深入学习C#]输入输出安全性——可变类型形參列表的变化安全性
可变类型形參列表(variant-type-parameter-lists) 可变类型形參列表(variant-type-parameter-lists )仅仅能在接口和托付类型上出现.它与普通的ty ...
- VBS+bat后强大的功能
set wshshell=createobject("script.shell") wshshell.run "cmd.exe /c [dos命令]",0,tr ...
- hdu 2988(最小生成树 kruskal算法)
Dark roads Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total ...
- Principal Component Analysis ---- PRML读书笔记
To summarize, principal component analysis involves evaluating the mean x and the covariance matrix ...
- 89. Ext.Button 按钮
转自:http://www.cnblogs.com/lipan/archive/2011/12/13/2274797.html 从本篇开始讲基础控件,ExtJs对所有的UI控件都有它自己的一套封装.本 ...
- Java压缩技术(三) ZIP解压缩——Java原生实现
原文:http://snowolf.iteye.com/blog/642492 JavaEye的朋友跟我说:“你一口气把ZIP压缩和解压缩都写到一个帖子里,我看起来很累,不如分开好阅读”.ok,面向读 ...
- [转]逐步解說:在 WPF 應用程式中使用 ReportViewer 显示 rdlc
本文转自:http://msdn.microsoft.com/zh-tw/library/hh273267 若要在 WPF 應用程式中使用 ReportViewer 控制項,您需要將 ReportVi ...
- 谈谈对Java中Unicode、编码的理解
我们经常会遇到编码问题.Java号称国际化的语言,是因为它的class文件采用UTF-8,而JVM运行时使用UTF-16(至于为什么JVM中要采用UTF-16,我没看过 相关的资料,但我猜可能是因为J ...