Hadoop MapReduce编程 API入门系列之FOF(Fund of Fund)(二十三)
不多说,直接上代码。









代码
package zhouls.bigdata.myMapReduce.friend;
import org.apache.hadoop.io.Text;
public class Fof extends Text{//自定义Fof,表示f1和f2关系
public Fof(){//无参构造
super();
}
public Fof(String a,String b){//有参构造
super(getFof(a, b));
}
public static String getFof(String a,String b){
int r =a.compareTo(b);
if(r<0){
return a+"\t"+b;
}else{
return b+"\t"+a;
}
}
}
package zhouls.bigdata.myMapReduce.friend;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class User implements WritableComparable<User>{
//WritableComparable,实现这个方法,要多很多
//readFields是读入,write是写出
private String uname;
private int friendsCount;
public String getUname() {
return uname;
}
public void setUname(String uname) {
this.uname = uname;
}
public int getFriendsCount() {
return friendsCount;
}
public void setFriendsCount(int friendsCount) {
this.friendsCount = friendsCount;
}//这一大段的get和set,可以右键,source,产生get和set,自动生成。
public User() {//无参构造
}
public User(String uname,int friendsCount){//有参构造
this.uname=uname;
this.friendsCount=friendsCount;
}
public void write(DataOutput out) throws IOException { //序列化
out.writeUTF(uname);
out.writeInt(friendsCount);
}
public void readFields(DataInput in) throws IOException {//反序列化
this.uname=in.readUTF();
this.friendsCount=in.readInt();
}
public int compareTo(User o) {//核心
int result = this.uname.compareTo(o.getUname());
if(result==0){
return Integer.compare(this.friendsCount, o.getFriendsCount());
}
return result;
}
}
package zhouls.bigdata.myMapReduce.friend;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class FoFSort extends WritableComparator{
public FoFSort() {//把自定义的User,传进了
super(User.class,true);
}
public int compare(WritableComparable a, WritableComparable b) {//排序核心
User u1 =(User) a;
User u2=(User) b;
int result =u1.getUname().compareTo(u2.getUname());
if(result==0){
return -Integer.compare(u1.getFriendsCount(), u2.getFriendsCount());
}
return result;
}
}
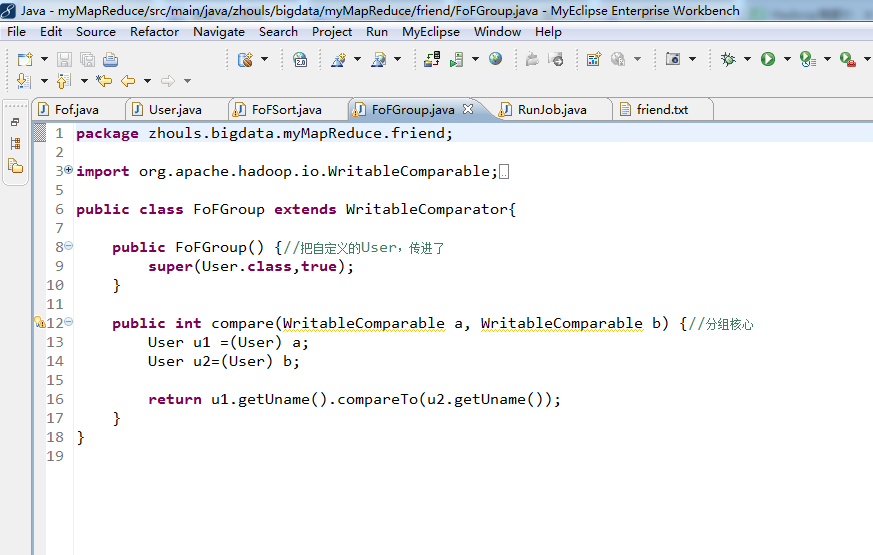
package zhouls.bigdata.myMapReduce.friend;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class FoFGroup extends WritableComparator{
public FoFGroup() {//把自定义的User,传进了
super(User.class,true);
}
public int compare(WritableComparable a, WritableComparable b) {//分组核心
User u1 =(User) a;
User u2=(User) b;
return u1.getUname().compareTo(u2.getUname());
}
}
package zhouls.bigdata.myMapReduce.friend;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.StringUtils;
public class RunJob {
// 小明 老王 如花 林志玲
// 老王 小明 凤姐 排序在FoFSort.java
// 如花 小明 李刚 凤姐
// 林志玲 小明 李刚 凤姐 郭美美 分组在FoFGroup.java
// 李刚 如花 凤姐 林志玲
// 郭美美 凤姐 林志玲
// 凤姐 如花 老王 林志玲 郭美美
public static void main(String[] args) {
Configuration config =new Configuration();
// config.set("fs.defaultFS", "hdfs://HadoopMaster:9000");
// config.set("yarn.resourcemanager.hostname", "HadoopMaster");
// config.set("mapred.jar", "C:\\Users\\Administrator\\Desktop\\wc.jar");
// config.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", ",");//默认分隔符是制表符"\t",这里自定义,如","
if(run1(config)){
run2(config);//设置两个run,即两个mr。
}
}
public static void run2(Configuration config) {
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJarByClass(RunJob.class);
job.setJobName("fof2");
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setSortComparatorClass(FoFSort.class);
job.setGroupingComparatorClass(FoFGroup.class);
job.setMapOutputKeyClass(User.class);
job.setMapOutputValueClass(User.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
// //设置MR执行的输入文件
// FileInputFormat.addInputPath(job, new Path("hdfs://HadoopMaster:9000/f1"));
//
// //该目录表示MR执行之后的结果数据所在目录,必须不能存在
// Path outputPath=new Path("hdfs://HadoopMaster:9000/out/f2");
//设置MR执行的输入文件
FileInputFormat.addInputPath(job, new Path("./out/f1"));
//该目录表示MR执行之后的结果数据所在目录,必须不能存在
Path outputPath=new Path("./out/f2");
if(fs.exists(outputPath)){
fs.delete(outputPath, true);
}
FileOutputFormat.setOutputPath(job, outputPath);
boolean f =job.waitForCompletion(true);
if(f){
System.out.println("job 成功执行");
}
} catch (Exception e) {
e.printStackTrace();
}
}
public static boolean run1(Configuration config) {
try {
FileSystem fs =FileSystem.get(config);
Job job =Job.getInstance(config);
job.setJarByClass(RunJob.class);
job.setJobName("friend");
job.setMapperClass(FofMapper.class);
job.setReducerClass(FofReducer.class);
job.setMapOutputKeyClass(Fof.class);
job.setMapOutputValueClass(IntWritable.class);
job.setInputFormatClass(KeyValueTextInputFormat.class);
// FileInputFormat.addInputPath(job, new Path("hdfs://HadoopMaster:9000/friend/friend.txt"));//下有friend.txt
//
// Path outpath =new Path("hdfs://HadoopMaster:9000/out/f1");
FileInputFormat.addInputPath(job, new Path("./data/friend/friend.txt"));//下有friend.txt
Path outpath =new Path("./out/f1");
if(fs.exists(outpath)){
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
boolean f= job.waitForCompletion(true);
return f;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}
static class FofMapper extends Mapper<Text, Text, Fof, IntWritable>{
protected void map(Text key, Text value,
Context context)
throws IOException, InterruptedException {
String user =key.toString();
String[] friends =StringUtils.split(value.toString(), '\t');
for (int i = 0; i < friends.length; i++) {
String f1 = friends[i];
Fof ofof =new Fof(user, f1);
context.write(ofof, new IntWritable(0));
for (int j = i+1; j < friends.length; j++) {
String f2 = friends[j];
Fof fof =new Fof(f1, f2);
context.write(fof, new IntWritable(1));
}
}
}
}
static class FofReducer extends Reducer<Fof, IntWritable, Fof, IntWritable>{
protected void reduce(Fof arg0, Iterable<IntWritable> arg1,
Context arg2)
throws IOException, InterruptedException {
int sum =0;
boolean f =true;
for(IntWritable i: arg1){
if(i.get()==0){
f=false;
break;
}else{
sum=sum+i.get();
}
}
if(f){
arg2.write(arg0, new IntWritable(sum));
}
}
}
static class SortMapper extends Mapper<Text, Text, User, User>{
protected void map(Text key, Text value,
Context context)
throws IOException, InterruptedException {
String[] args=StringUtils.split(value.toString(),'\t');
String other=args[0];
int friendsCount =Integer.parseInt(args[1]);
context.write(new User(key.toString(),friendsCount), new User(other,friendsCount));
context.write(new User(other,friendsCount), new User(key.toString(),friendsCount));
}
}
static class SortReducer extends Reducer<User, User, Text, Text>{
protected void reduce(User arg0, Iterable<User> arg1,
Context arg2)
throws IOException, InterruptedException {
String user =arg0.getUname();
StringBuffer sb =new StringBuffer();
for(User u: arg1 ){
sb.append(u.getUname()+":"+u.getFriendsCount());
sb.append(",");
}
arg2.write(new Text(user), new Text(sb.toString()));
}
}
Hadoop MapReduce编程 API入门系列之FOF(Fund of Fund)(二十三)的更多相关文章
- Hadoop MapReduce编程 API入门系列之小文件合并(二十九)
不多说,直接上代码. Hadoop 自身提供了几种机制来解决相关的问题,包括HAR,SequeueFile和CombineFileInputFormat. Hadoop 自身提供的几种小文件合并机制 ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- Hadoop MapReduce编程 API入门系列之join(二十六)(未完)
不多说,直接上代码. 天气记录数据库 Station ID Timestamp Temperature 气象站数据库 Station ID Station Name 气象站和天气记录合并之后的示意图如 ...
- Hadoop MapReduce编程 API入门系列之MapReduce多种输入格式(十七)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.ScoreCount; import java.io.DataInput; import java.i ...
- Hadoop MapReduce编程 API入门系列之自定义多种输入格式数据类型和排序多种输出格式(十一)
推荐 MapReduce分析明星微博数据 http://git.oschina.net/ljc520313/codeexample/tree/master/bigdata/hadoop/mapredu ...
- Hadoop MapReduce编程 API入门系列之wordcount版本1(五)
这个很简单哈,编程的版本很多种. 代码版本1 package zhouls.bigdata.myMapReduce.wordcount5; import java.io.IOException; im ...
- Hadoop MapReduce编程 API入门系列之薪水统计(三十一)
不多说,直接上代码. 代码 package zhouls.bigdata.myMapReduce.SalaryCount; import java.io.IOException; import jav ...
随机推荐
- Data mapping-数据映射
数据映射:根据数据的结构信息建立数据间的映射操作机制. 数据映射的要素: 一.数据 1.源数据: 2.目标数据: 3.数据间关系: 4.数据的元数据(结构信息). 5.元素类型的对应关系. 二.元数据 ...
- Hadoop-2.2.0在Unbuntu ADM64中需要重新编译Native Lib
通过:cat /etc/issue 查看当前系统版本: Ubuntu 12.04.3 通过:uname -ar 查看更想起信息: Linux ubuntu-236 3.8.0-29-generic # ...
- python tips:dict的key顺序
python3.6+版本中,dict的键值保持插入有序. t = list(range(10)) b = t[:] d = dict(zip(t, b)) print(list(d.items())) ...
- CentOS6.9下NFS配置说明
NFS是Network File System的缩写,即网络文件系统.它的主要功能是通过网络(一般是局域网)让不同的主机系统之间可以共享文件或目录.NFS客户端可以通过挂载(mount)的方式将NFS ...
- java中为什么不允许类多重继承,却允许接口多重继承
首先看下面这一段代码:(底下有热心网友更正,jdk1.8之后情况确实有点变化,等改天有空继续更) interface a{ void b();}interface a1 extends a{ void ...
- 复习MySQL③导入数据、检查及修改
导入数据: 用insert into语句为表插入数据: - insert into 表名(字段1,字段2,…) values …… 导入外部文本文件: - 导入外部txt文件(导入CSV文件分隔符为' ...
- 慕课网页面app的滑动
#coding=utf-8from appium import webdriver def get_driver(): desc={ "platformName":"An ...
- 洛谷P1208 [USACO1.3]混合牛奶 Mixing Milk【贪心+背包】
由于乳制品产业利润很低,所以降低原材料(牛奶)价格就变得十分重要.帮助Marry乳业找到最优的牛奶采购方案. Marry乳业从一些奶农手中采购牛奶,并且每一位奶农为乳制品加工企业提供的价格是不同的.此 ...
- Linux思维导图之进程管理
查漏补缺,理解概念,及时总结,欢迎拍砖.
- 解决HTML select控件 设置属性 disabled 后无法向后台传值的方法
大家都知道有时候修改数据的时候我们希望有一些数据是不可以修改的,通常情况下我们会将input框设置为 readonly , 但是 select 控件没有这个属性,需要使用另一个属性 disabled ...