【DRF序列化】
前后端分离后,其交互一般都选择使用JSON数据格式,JSON是一个轻量级的数据交互格式.
因此,后端发送给前端(或前端发送给后端)的数据都要转成JSON格式,这就得需要我们把从数据库内取到的数据进行序列化.
本文将详细讲述Django项目中如何使用第三方库rest_framework进行序列化.
在命令行中输入:pip install djangorestframework,方可下载rest_framework.
@
首先,我们准备三张数据表:
from django.db import models__all__ = ['Book', 'Publisher', 'Author']class Book(models.Model):"""书籍表"""title = models.CharField(max_length=62)CHOICES = ((1, '前端'), (2, '后端'), (3, '运维'))category = models.IntegerField(choices=CHOICES)pub_date = models.DateField() # 出版日期publisher = models.ForeignKey(to='Publisher') # 外键出版社表authors = models.ManyToManyField(to='Author') # 多对多作者表class Publisher(models.Model):"""出版社表"""title = models.CharField(max_length=64)class Author(models.Model):"""作者表"""name = models.CharField(max_length=64)
插入数据:
# 在Python脚本中调用Django环境:import os, datetimeif __name__ == '__main__':# 请将'blog091.settings'更改为对应的项目名称及配置文件,更改后直接运行即可os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'blog091.settings')import djangodjango.setup()from blog import models# 添加出版社pub01 = models.Publisher.objects.create(title="上帝出版社")pub02 = models.Publisher.objects.create(title="沙河出版社")pub03 = models.Publisher.objects.create(title="西二旗出版社")# 添加作者au01 = models.Author.objects.create(name="迷之标签大仙")au02 = models.Author.objects.create(name="迷之重启大仙")au03 = models.Author.objects.create(name="迷之算法大仙")# 添加书籍pub_date = {'year': 2099, 'month': 12, 'day': 31}book01 = models.Book.objects.create(title="【论写标签的姿势】", category=1, pub_date=datetime.date(**pub_date),publisher=pub01)book01.authors.add(au01)book02 = models.Book.objects.create(title="【论重启服务的姿势】", category=2, pub_date=datetime.date(**pub_date),publisher=pub02)book02.authors.add(au02)book03 = models.Book.objects.create(title="【论写算法的姿势】", category=3, pub_date=datetime.date(**pub_date),publisher=pub03)book03.authors.add(au03)
基本的序列化操作
既然我们要使用DRF的序列化,那么我们就得遵循人家框架的一些标准.
- 在Django中,我们的CBV继承类是View;而在DRF中,我们的继承类时APIView.
- 在Django中,我们返回数据使用HTTPResponse、JsonResponse、render;而在DRF中,我们使用Response.
第一步 注册app
第二步 新建一个py文件,在文件内声明序列化类
from rest_framework import serializersclass BookSerializer(serializers.Serializer):id = serializers.IntegerField()title = serializers.CharField(max_length=32)# 我们先注释掉一个字段# 然后你读一读下面第二行黄色的字,再看一看第四步骤中的图,你就明白了.# pub_date = serializers.DateField()category = serializers.CharField(source='get_category_display')这里面写的字段必须是在models文件中存在的.
并且,在models文件中有,而在这里没有的字段会被过滤掉.
第三步 使用CBV,序列化对象
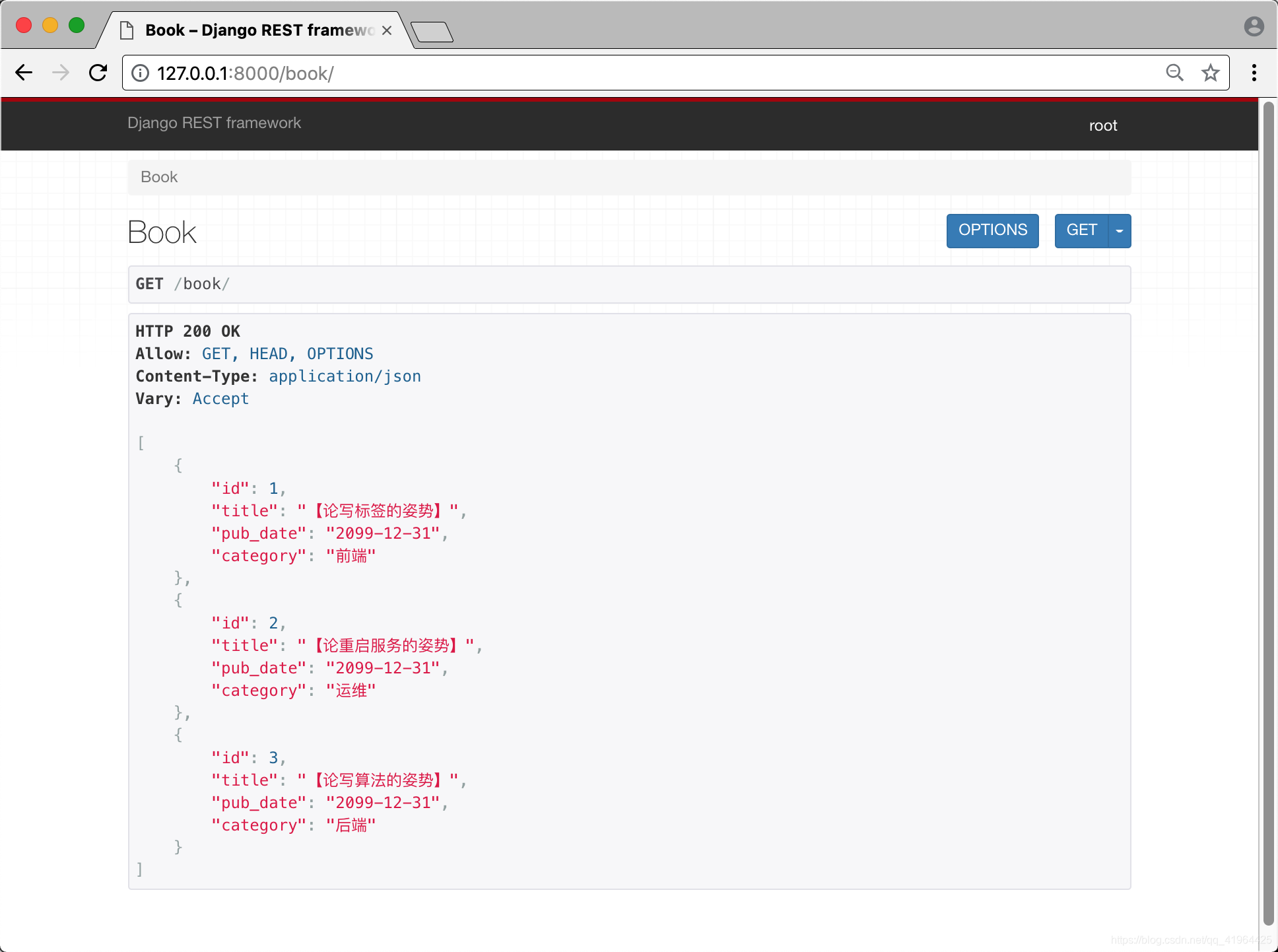
from blog import models# 继承类from rest_framework.views import APIView# 返回数据的方法from rest_framework.response import Response# 导入上一步骤定义的序列化类from .serializers import BookSerializerclass Book(APIView):def get(self, request):# 首先,我们获取书籍列表book_list = models.Book.objects.all()# 然后,将书籍列表传入序列化类ret = BookSerializer(book_list, many=True)# book_list:要过滤的对象列表(过滤的是字段,而不是对象)# many=True:表示取多个(源码中会循环取)# 最后返回数据# 数据在其data中,所以要返回ret.datareturn Response(ret.data)
第四部 启动项目,访问站点
怎么样,四不四很66啊.
外键/多对多关系的序列化
在声明序列化类的文件中添加如下代码:
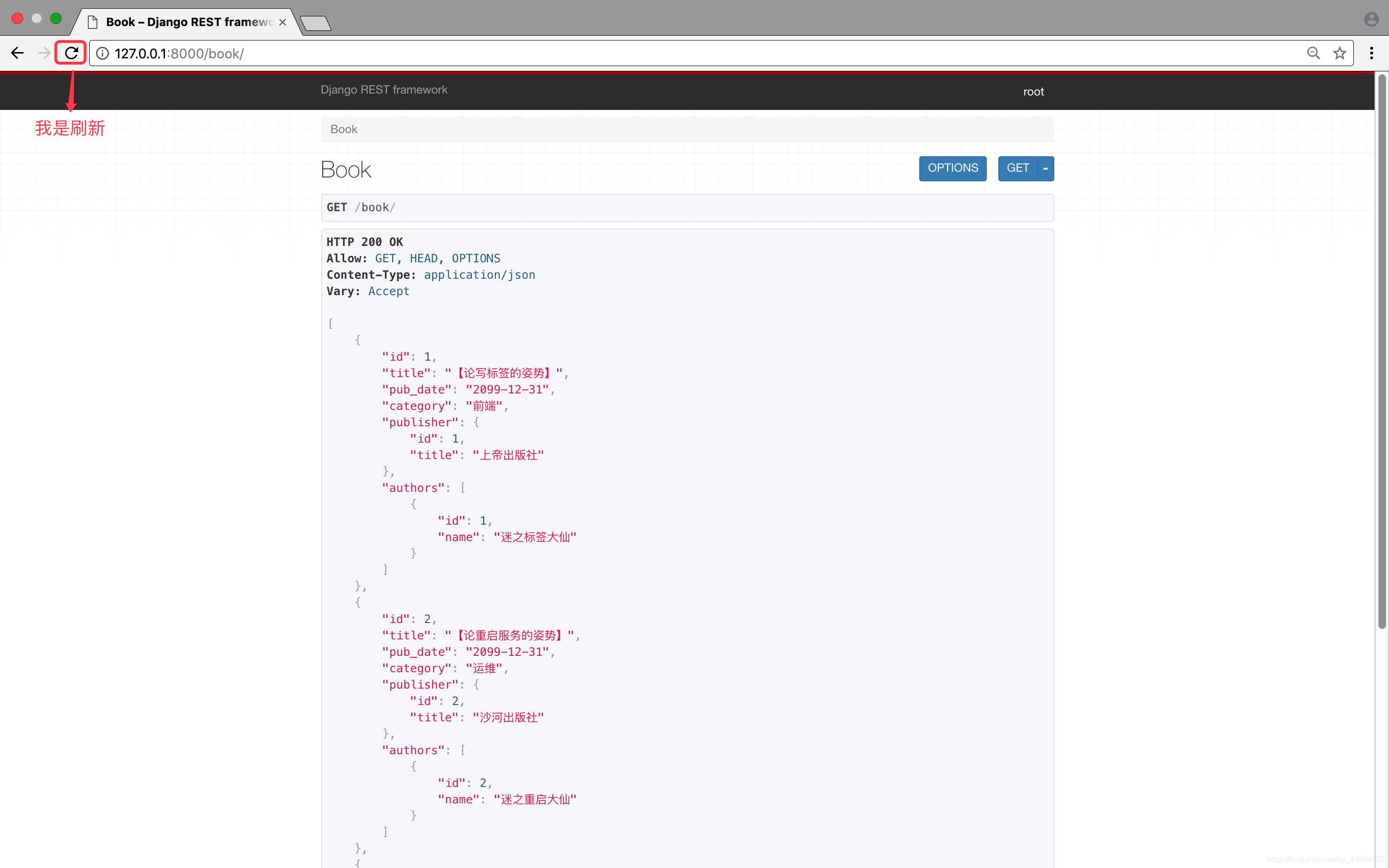
from rest_framework import serializersclass PublisherSerializer(serializers.Serializer):id = serializers.IntegerField()title = serializers.CharField(max_length=64)class AuthorSerializer(serializers.Serializer):id = serializers.IntegerField()name = serializers.CharField(max_length=32)class BookSerializer(serializers.Serializer):id = serializers.IntegerField()title = serializers.CharField(max_length=32)pub_date = serializers.DateField()category = serializers.CharField(source='get_category_display')# 出版社(外键关系) 指定上面写的出版社类即可publisher = PublisherSerializer()# 内部通过外键关系的id找到publisher_object# 再通过PublisherSerializer(publisher_object)得到数据# 作者(多对多关系) 指定上面写的作者类即可authors = AuthorSerializer(many=True)# many=True:表示取多个(源码中会循环取)然后,我们打开浏览器,狂点刷新后,即可看到:
反序列化的操作
当前端给我们传送数据的时候(post请求),我们要进行一些校验然后保存到数据库.
DRF中的Serializer给我们提供了一些校验和保存数据的方法,首先我们写出反序列化用到的一些字段,有些字段要跟序列化区分开来,基本步骤如下.
步骤一 声明反序列化类
·
序列化和反序列化的字段不统一,因此我们需要分别定义序列化和反序列化的字段
from rest_framework import serializersfrom blog import modelsclass PublisherSerializer(serializers.Serializer):id = serializers.IntegerField()title = serializers.CharField(max_length=64)class AuthorSerializer(serializers.Serializer):id = serializers.IntegerField()name = serializers.CharField(max_length=32)class BookSerializer(serializers.Serializer):# 序列化和反序列化的字段不统一,因此必须分别定义序列化和反序列化的字段"""我们先了解如下三个参数:required=False -> 反序列化时不校验此字段read_only=True -> 反序列化时不校验此字段write_only=True -> 序列化时不校验此字段"""# ==== 指定序列化时校验,而反序列化时不校验的字段 ====id = serializers.IntegerField(required=False)category = serializers.CharField(source='get_category_display', read_only=True)publisher = PublisherSerializer(read_only=True)authors = AuthorSerializer(many=True, read_only=True)# ==== 始终校验的字段 ====title = serializers.CharField(max_length=64)pub_date = serializers.DateField()# ==== 指定反序列化时校验,而序列化时不校验的字段 ====post_category = serializers.IntegerField(write_only=True)publisher_id = serializers.IntegerField(write_only=True)author_list = serializers.ListField(write_only=True)def create(self, validated_data):"""用于增加数据的方法:param validated_data: 校验通过的数据(就是步骤二中传过来的book_obj):return: validated_data"""# 开始ORM操作:book_obj = models.Book.objects.create(title=validated_data['title'],pub_date=validated_data['pub_date'],category=validated_data['post_category'],publisher_id=validated_data['publisher_id'])book_obj.authors.add(*validated_data['author_list'])return validated_data
步骤二 使用CBV 反序列化对象
from blog import models# 继承类from rest_framework.views import APIView# 返回数据的方法from rest_framework.response import Response# 导入上一步骤定义的序列化类from .serializers import BookSerializerclass Book(APIView):def get(self, request):book_list = models.Book.objects.all()ret = BookSerializer(book_list, many=True)return Response(ret.data)# 重点在这里:def post(self, request):"""post请求的基本思路:确定数据类型以及数据结构,对前端传过来的数据进行校验"""book_obj = request.data # 提取post请求发过来的数据ser_obj = BookSerializer(data=book_obj)# data=book_obj:指定反序列化数据if ser_obj.is_valid(): # 开始校验ser_obj.save() # 保存数据return Response(ser_obj.validated_data) # 校验成功,返回校验信息return Response(ser_obj.errors) # 校验失败,返回错误信息
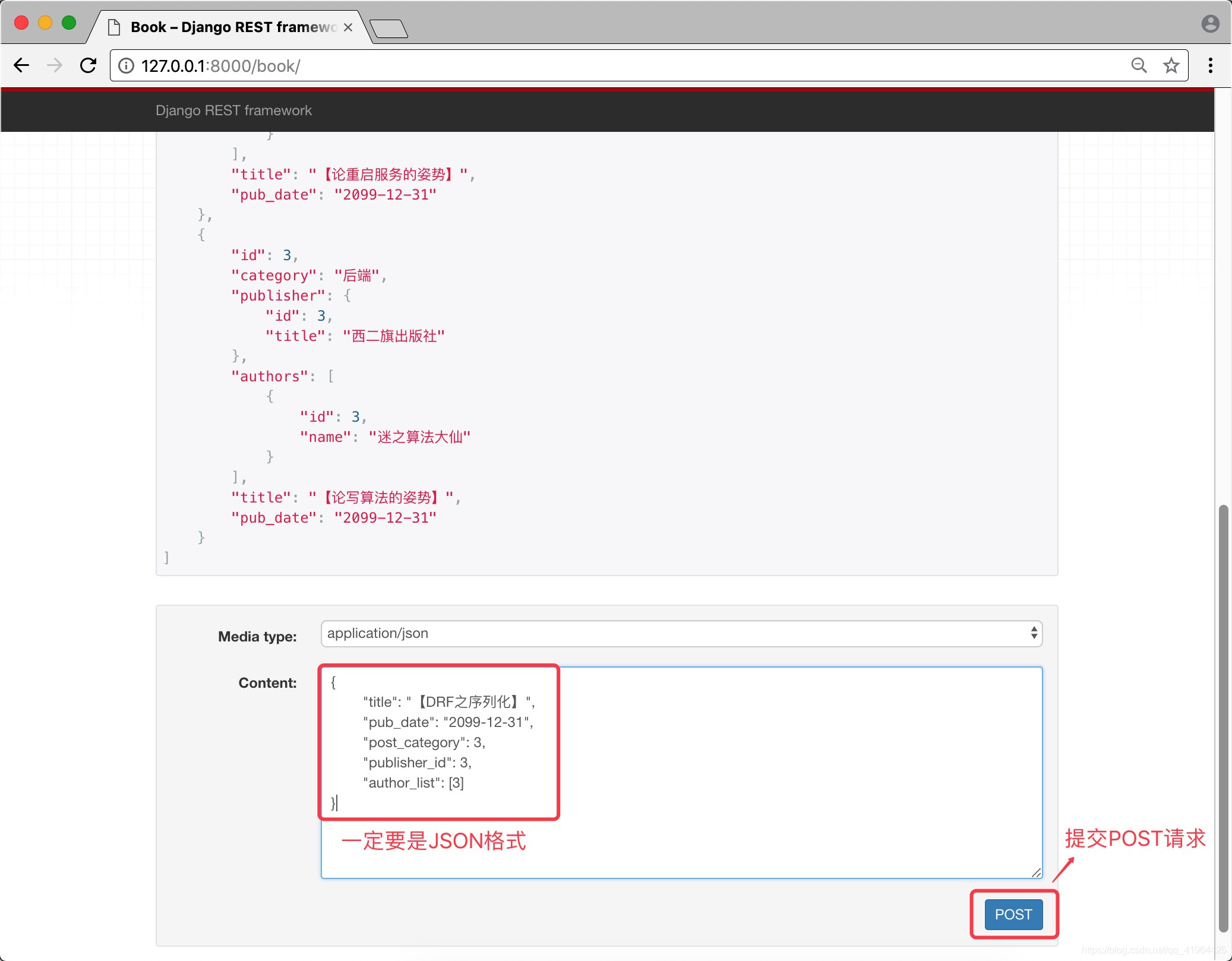
步骤三 启动项目 访问页面并提交JSON数据
成功后,会展示出提交的数据,如下:
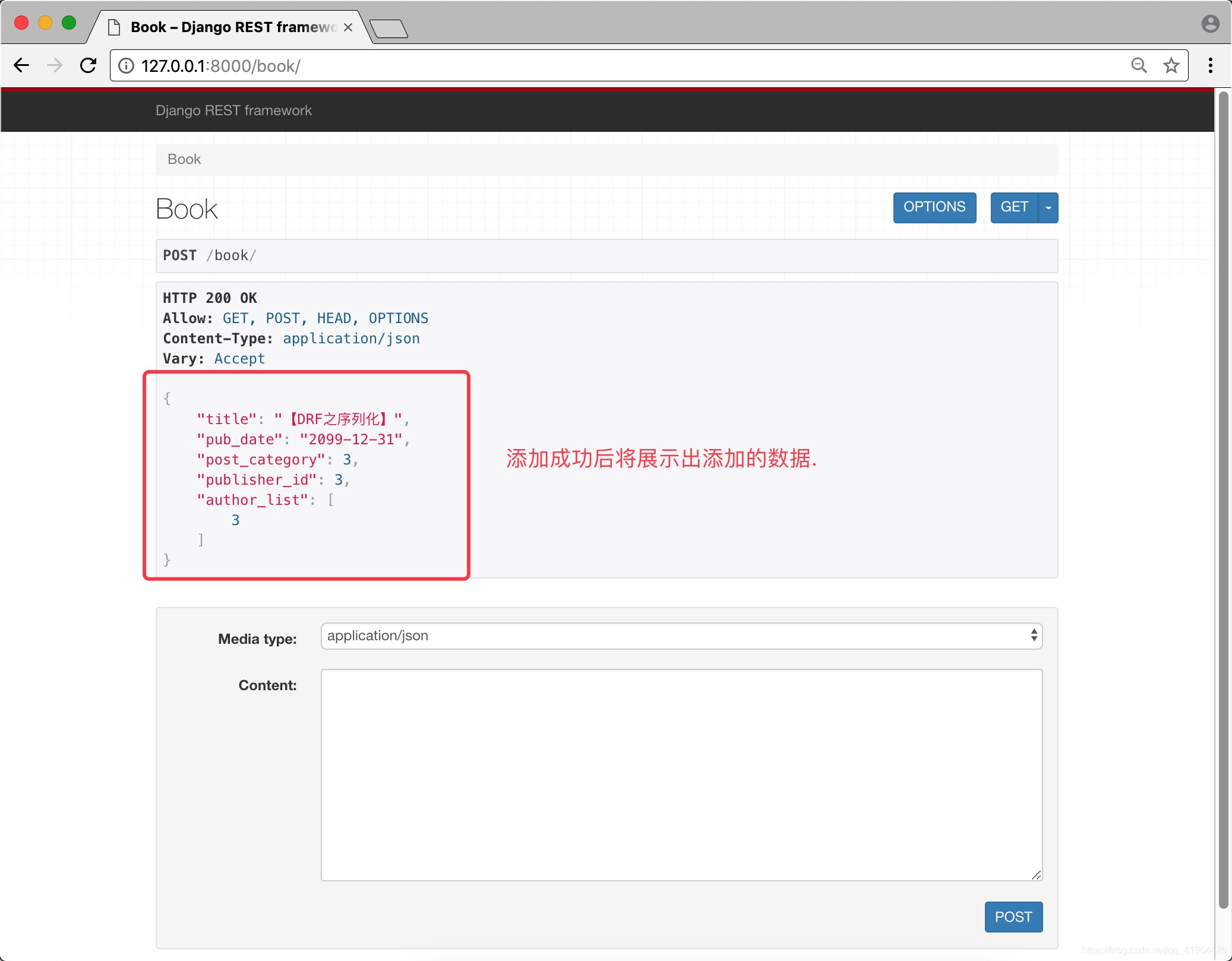
单条数据查询及更新
步骤一 准备url
from blog import viewsurlpatterns = [url(r'^book/(?P<book_id>\d+)$', views.BookEdit.as_view()),]
步骤二 声明(反)序列化类
from rest_framework import serializersfrom blog import modelsclass PublisherSerializer(serializers.Serializer):id = serializers.IntegerField()title = serializers.CharField(max_length=64)class AuthorSerializer(serializers.Serializer):id = serializers.IntegerField()name = serializers.CharField(max_length=32)class BookSerializer(serializers.Serializer):# 序列化和反序列化的字段不统一,因此必须分别定义序列化和反序列化的字段"""我们先了解如下三个参数:required=False -> 反序列化时不校验此字段read_only=True -> 反序列化时不校验此字段write_only=True -> 序列化时不校验此字段"""# ==== 指定序列化时校验,而反序列化时不校验的字段 ====id = serializers.IntegerField(required=False)category = serializers.CharField(source='get_category_display', read_only=True)publisher = PublisherSerializer(read_only=True)authors = AuthorSerializer(many=True, read_only=True)# ==== 始终校验的字段 ====title = serializers.CharField(max_length=64)pub_date = serializers.DateField()# ==== 指定反序列化时校验,而序列化时不校验的字段 ====post_category = serializers.IntegerField(write_only=True)publisher_id = serializers.IntegerField(write_only=True)author_list = serializers.ListField(write_only=True)def update(self, instance, validated_data):"""用于更新数据的方法:param instance: 要更新的数据就是步骤三中传过来的book_obj):param validated_data: 校验通过的数据:return: instance"""# 开始ORM操作:instance.title = validated_data.get('title', instance.title)instance.pub_date = validated_data.get('pub_date', instance.pub_date)instance.category = validated_data.get('category', instance.category)instance.publisher_id = validated_data.get('publisher_id', instance.publisher_id)if validated_data.get('author_list'):instance.authors.set(validated_data['author_list'])instance.save()return instance
步骤三 使用CBV (反)序列化对象
class BookEdit(APIView):def get(self, request, book_id):# 1. 获取指定id的数据book_obj = models.Book.objects.filter(id=book_id).first()# 2. 过滤字段(序列化)ser_obj = BookSerializer(book_obj)# 3. 返回数据,数据在data中return Response(ser_obj.data)# put请求def put(self, request, book_id):book_obj = models.Book.objects.filter(id=book_id).first() # 先获取要更新的数据ser_obj = BookSerializer(instance=book_obj, data=request.data, partial=True)# instance=book_obj:要更新的数据# data=request.data:新的数据# partial=True:部分校验if ser_obj.is_valid():ser_obj.save()return Response(ser_obj.validated_data) # 校验成功,返回校验信息return Response(ser_obj.errors) # 校验失败,返回错误信息
步骤四 启动项目 查询指定id的数据
这就是单条数据查询.
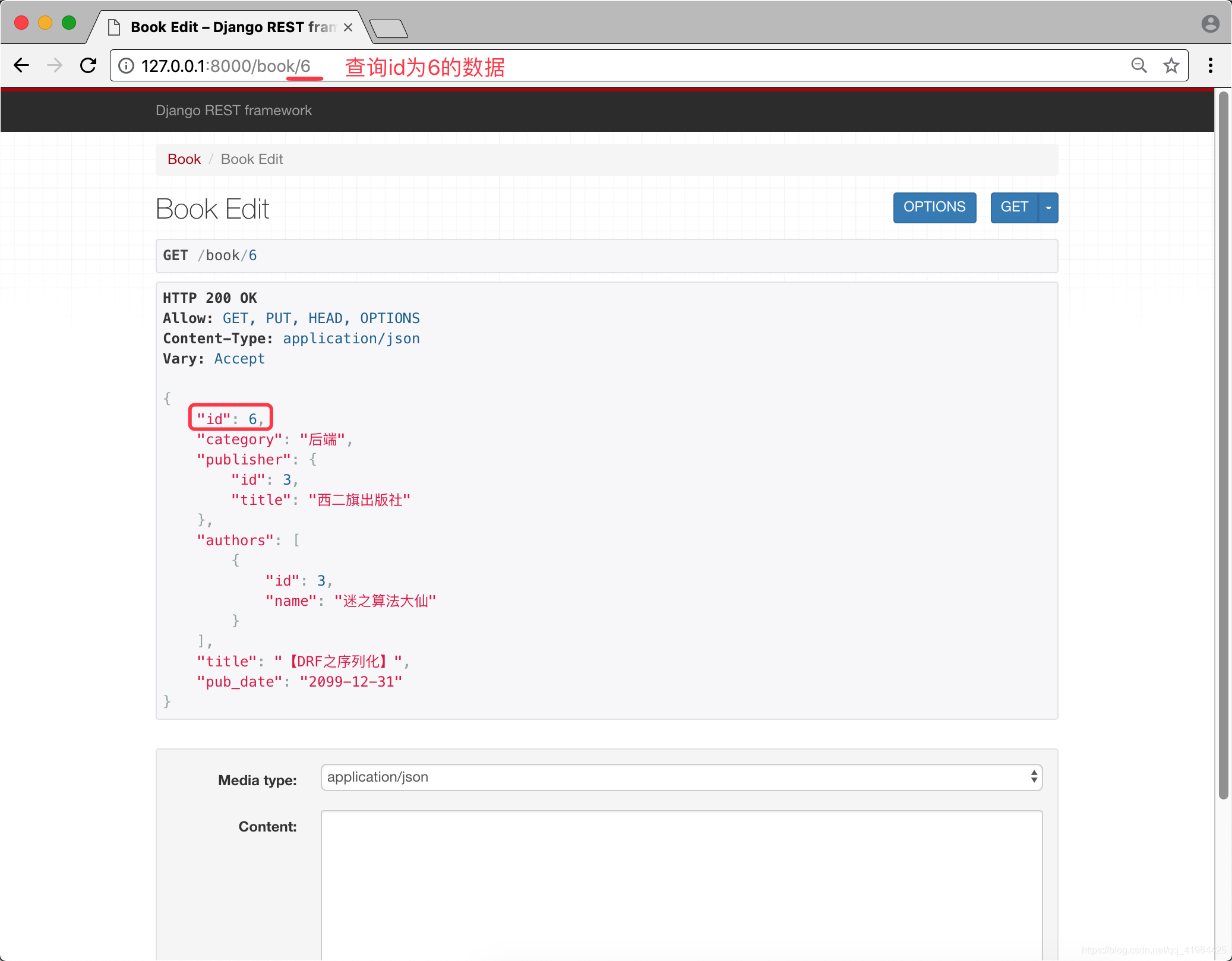
步骤五 更新指定id的数据
提交成功后,将展示出更新的数据,如下:

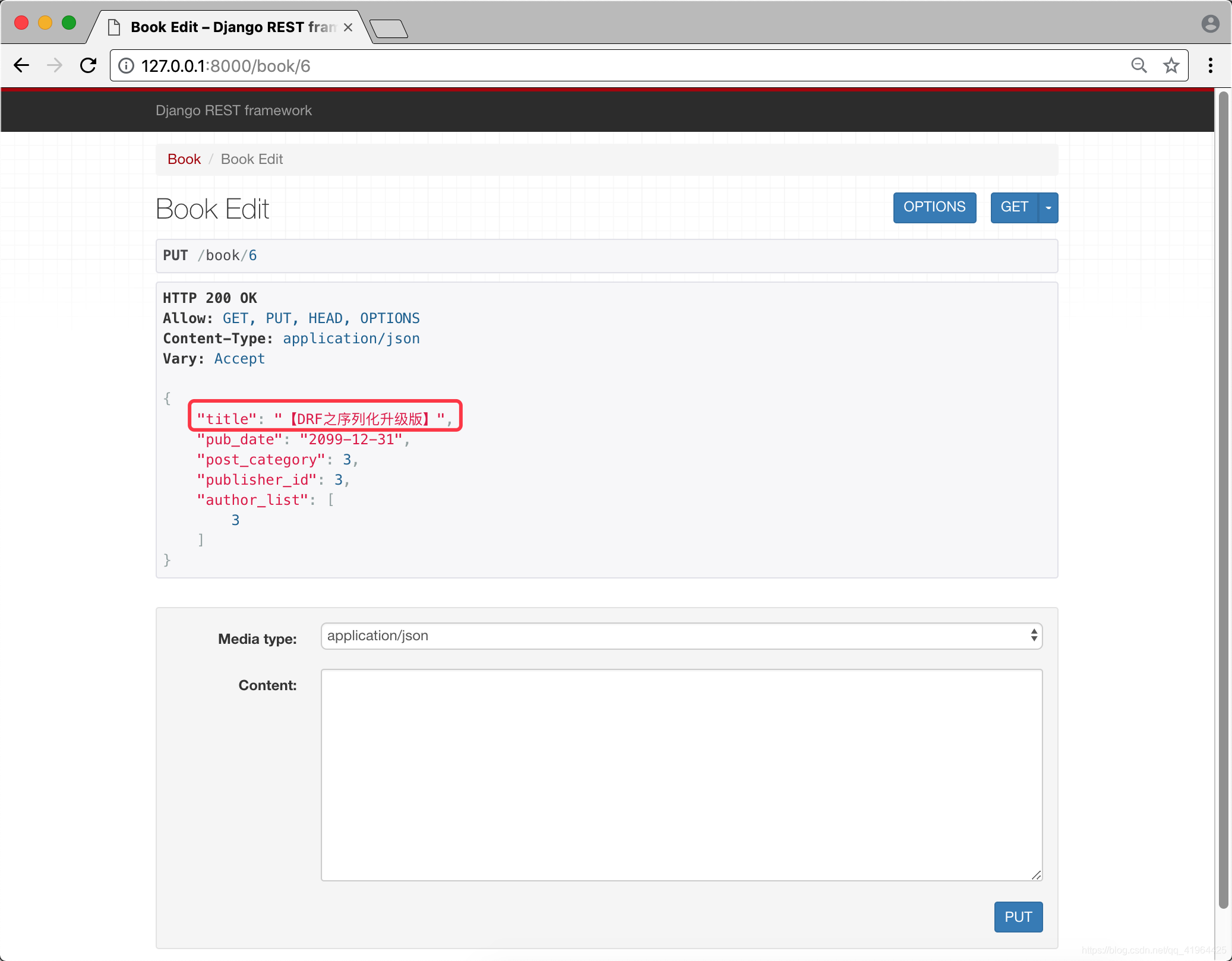
数据的校验
DRF为我们提供了钩子函数,可用于校验单个或多个字段.
单个字段的校验
在(反)序列化类中添加钩子函数.
def validate_title(self, value):"""validate_字段名, 对单个字段进行校验:param value: 对应提交的title的值:return:"""if "之" not in value:raise serializers.ValidationError("书名必须含有 之")
此时,添加/更新书籍时,如果书名中没有"之"字,则将抛出错误信息:
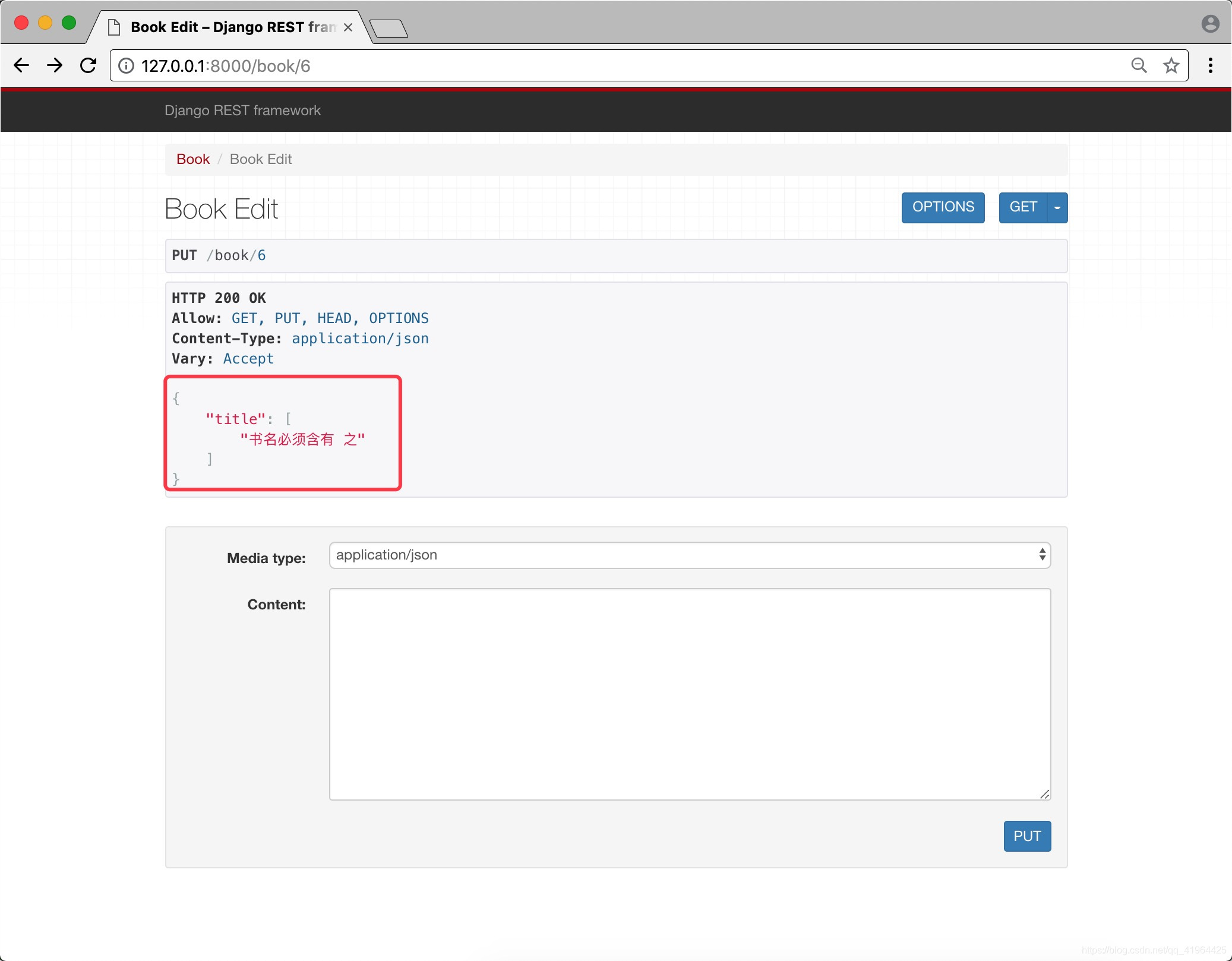
多个字段的校验
在(反)序列化类中添加钩子函数.
def validate(self, attrs):"""可对对所有字段进行校验:param attrs: 提交的所有数据:return: 校验通过时返回attrs"""if attrs['post_category'] == 3 and attrs['pub_date'] == '2099-12-31':return attrselse:raise serializers.ValidationError("类型必须指定 3,且出版日期必须为 2099-12-31")
此时,添加/更新书籍时,如果不符合校验规则,则将抛出错误信息.
自定义校验器
# 首先,定义一个校验器函数def my_validate(value):"""自定义的校验器函数"""if "敏感信息" in value.lower():raise serializers.ValidationError("内容包含敏感词汇!")class BookSerializer(serializers.Serializer):# 然后,在校验器中调用此函数title = serializers.CharField(max_length=64, validators=[my_validate,])# validators=[my_validate,]:指定校验函数列表
现在,我们已经很清楚Serializer的用法了,然而我们发现,所有的序列化都跟我们的模型紧密相关...
对,没错,DRF也给我们提供了跟模型紧密相关的序列化器——ModelSerializer.
终极用法 ModelSerializer
根据模型自动生成字段.
默认就实现了添加与更新的方法.
以下示例将实现上述的所有功能:
from rest_framework import serializersfrom blog import modelsclass PublisherSerializer(serializers.Serializer):id = serializers.IntegerField()title = serializers.CharField(max_length=64)class AuthorSerializer(serializers.Serializer):id = serializers.IntegerField()name = serializers.CharField(max_length=32)def my_validate(value):"""自定义的校验器函数"""if "敏感信息" in value.lower():raise serializers.ValidationError("内容包含敏感词汇!")class BookSerializer(serializers.ModelSerializer):""" 重写字段 + def get_自定义字段名(self, obj): """# 重写的字段如果与原字段同名,则会覆盖掉原字段# 外键关联的对象有很多字段我们是用不到的, 都传给前端会有数据冗余, 就需要我们自己去定制序列化外键对象的哪些字段publisher_info = serializers.SerializerMethodField(read_only=True)def get_publisher_info(self, obj):# obj是要序列化的每个对象return {'id': obj.publisher.id, 'title': obj.publisher.title}authors_info = serializers.SerializerMethodField(read_only=True)def get_authors_info(self, obj):return [{'id': author.id, 'name': author.name} for author in obj.authors.all()]# 再比如我们的选择字段,默认显示的是key, 而我们要展示给用户的是value, 因此,我们重写选择字段来自定制:category_dis = serializers.SerializerMethodField(read_only=True)def get_category_dis(self, obj):return obj.get_category_display()class Meta:""" 指定数据表 """model = models.Book""" 获取字段 """fields = "__all__" # 所有字段# fields = ['id', 'title', '...'] # 包含指定字段# exclude=["id", '...'] # 排除指定字段""" depth """# 代表找嵌套关系的第几层,指定找外键关系向下找几层# depth = 1# 会将所有的外键关系变成只读read_only=True# 这个参数几乎不用,最好不要错过4层""" 只读字段 """# 即反序列化时不校验的字段read_only_fields = ['id', ]""" extra_kwargs """# 按照下面的格式, 可为所有字段设置参数extra_kwargs = {"title": {"validators": [my_validate, ]},'publisher': {'write_only': True},'authors': {'write_only': True}}
【DRF序列化】的更多相关文章
- DRF 序列化组件
Serializers 序列化组件 Django的序列化方法 class BooksView(View): def get(self, request): book_list = Book.objec ...
- python 全栈开发,Day99(作业讲解,DRF版本,DRF分页,DRF序列化进阶)
昨日内容回顾 1. 为什么要做前后端分离? - 前后端交给不同的人来编写,职责划分明确. - API (IOS,安卓,PC,微信小程序...) - vue.js等框架编写前端时,会比之前写jQuery ...
- python 全栈开发,Day95(RESTful API介绍,基于Django实现RESTful API,DRF 序列化)
昨日内容回顾 1. rest framework serializer(序列化)的简单使用 QuerySet([ obj, obj, obj]) --> JSON格式数据 0. 安装和导入: p ...
- Django的DRF序列化方法
安装rest_framework -- pip install djangorestframework -- 注册rest_framework序列化 -- Python--json -- 第一版 用v ...
- drf序列化器与反序列化
什么是序列化与反序列化 """ 序列化:对象转换为字符串用于传输 反序列化:字符串转换为对象用于使用 """ drf序列化与反序列化 &qu ...
- drf序列化及反序列化
假如把drf看做一个汉堡包,我们之前讲的模块属于汉堡包前面的盖盖(请求模块.渲染模块)和底底(异常模块.解析模块.响应模块),但是真正中间的夹心没有讲,那么今天我就和大家来看一下汉堡包的夹心(序列化及 ...
- drf序列化和反序列化
目录 drf序列化和反序列化 一.自定义序列化 1.1 设置国际化 二.通过视图类的序列化和反序列化 三.ModelSerializer类实现序列化和反序列化 drf序列化和反序列化 一.自定义序列化 ...
- DRF 序列化组件 模型层中参数补充
一. DRF序列化 django自带有序列化组件,但是相比rest_framework的序列化较差,所以这就不提django自带的序列化组件了. 首先rest_framework的序列化组件使用同fr ...
- 4)drf序列化组件 Serializer(偏底层)、ModelSerializer(重点)、ListModelSerializer(辅助群改)
知识点:Serializer(偏底层).ModelSerializer(重点).ListModelSerializer(辅助群改) 一.Serializer 偏底层 一般不用 理解原理 1.序列化准备 ...
- 揭开DRF序列化技术的神秘面纱
在RESTful API中,接口返回的是JSON,JSON的内容对应的是数据库中的数据,DRF是通过序列化(Serialization)的技术,把数据模型转换为JSON的,反之,叫做反序列化(dese ...
随机推荐
- 2017国家集训队作业[agc016b]Color Hats
2017国家集训队作业[agc016b]Color Hats 题意: 有\(N\)个人,每个人有一顶帽子.帽子有不同的颜色.现在,每个人都告诉你,他看到的所有其它人的帽子共有多少种颜色,问有没有符合所 ...
- es6 学习2 模板字符
es6模板字符简直是开发者的福音啊,解决了ES5在字符串功能上的痛点. 1.第一个用途,基本的字符串格式化.将表达式嵌入字符串中进行拼接.用${}来界定 //es5 var name = 'lux' ...
- navigator.mediaDevices.getUserMedia
navigator.mediaDevices.getUserMedia: 作用:为用户提供直接连接摄像头.麦克风的硬件设备的接口 语法: navigator.mediaDevices.getUserM ...
- 钓鱼WIFI的防范
实际上,Wi-Fi接入点(AP).路由器和热点常常是高度暴露的攻击面.用户一不小心就有可能踏进攻击者设置的Wi-Fi陷阱,为企业造成信息泄露或经济损失. 如今Wi-Fi 6时代悄然到来,为高密海量无线 ...
- TCP 三次握手,四次挥手
TCP 三次握手,四次挥手 1. TCP 三次握手 建立连接前,客户端和服务端需要通过握手来确认对方: 客户端发送 syn(同步序列编号) 请求,进入 syn_send 状态,等待确认 服务端接收并确 ...
- 【Henu ACM Round#19 D】 Points on Line
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 考虑l..r这个区间. 且r是满足a[r]-a[l]<=d的最大的r 如果是第一个找到的区间,则直接累加C(r-l+1,3); ...
- Select For update语句浅析
Select -forupdate语句是我们经常使用手工加锁语句.通常情况下,select语句是不会对数据加锁,妨碍影响其他的DML和DDL操作.同时,在多版本一致读机制的支持下,select语句也不 ...
- Ubuntu下安装git工具
环境:Ubuntu 9.10 git-1.8.2.3.tar.bz2 1.将安装包下载到所选文件夹下,如:/tmp 2.tar -xjf git-1.8.2.3.tar.bz2 3.cd git-1. ...
- SQLite: sqlite_master(转)
转自:http://blog.sina.com.cn/s/blog_6afeac500100yn9k.html SQLite数据库中一个特殊的名叫 SQLITE_MASTER 上执行一个SELECT查 ...
- JS 引擎基础之 Shapes and Inline Caches
阅读下面这篇文章,需要20分钟: 一起了解下 JS 引擎是如何运作的吧! JS 的运作机制可以分为 AST 分析.引擎执行两个步骤: JS 源码通过 parser(分析器)转化为 AST(抽象语法树) ...