Oracle的model语句入门-转
Model语句是Oracle 10g的新功能之一。 本文通过一些简单的例子帮助理解Model语句的用法,复杂使用场景请参考其他文章。
环境:当然需要Oracle 10g以上,本人是在11g上测试的。
1. 什么是model语句
model语句是Oracle10g的新功能,可以在select语句里面像其他编程语言操作数组一样,对SQL的结果集进行处理。执行顺序是位于Having之后。
1. from语句
2. where语句 (结合条件)
3. start with语句
4. connect by语句
5. where语句
6. group by语句
7. having语句
8. model语句
9. select语句
10. union、minus、intersect等集合演算演算
11. order by语句
model的好处
Oracle 9i为止,需要使用各种计算分析函数,union all等,以及借助其他开发语言(C#及Java等)进行复杂计算统计合并等。使用Model之后,这些都可以在SQL里面进行了。
model典型使用场景。
- 合计行追加
- 行列变换
- 使用当前行的前后行
RegExp_Replace函数的循环执行
2. HelloWorld
先看一个简单的例子。
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue, 1 as soeji from dual)
model
dimension by(soeji)
measures(ArrValue)
rules(ArrValue[1] = 'Hello World');
| ArrValue | soeji |
| Hello World |
说明:
model model语句的关键字,必须。
dimension by dimension维度的意思,可以理解为数组的索引,必须。
measures 指定作为数组的列
rules 对数组进行各种操作的描述。
例句1的理解:
select 'abcdefghijklmn' as ArrValue,
1 as soeji from dual;
| abcdefghijklmn | 1 |
根据下面语句
model
dimension by (soeji)
measures(ArrValue)
soeji作为索引对数组ArrValue进行操作,rules(ArrValue[1] = 'Hello World')就是说用Hello World覆盖ArrValue[1]里面的值。
在看一个例子,例句2:
select ArrValue,soeji
from (select 'abcdefghijklmn' as ArrValue,
1 as soeji from dual)
model
dimension by(soeji)
measures(ArrValue)
rules(ArrValue[1] = 'Hello World',
ArrValue[2] = 'Hello model');
| Hello World | 1 |
| Hello model | 2 |
rules的缺省行为是存在就更新,不存在则追加,因此,ArrValue[1] = 'Hello World'是更新一条,ArrValue[2] = 'Hello Model'insert一条。
再看一个例子,例句3:
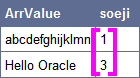
select ArrValue,soeji from (select 'abcdefghijklmn' as ArrValue, 1 assoeji from dual) model dimension by(soeji) measures(ArrValue) rules(ArrValue[3] ='Hello Oracle');
| abcdefghijklmn | 1 |
| Hello Oracle | 3 |
model语句里面,索引可以是不连续的。
再看一个例子,例句4:
select ArrValue,soeji from (select 'abcdefghijklmn' as ArrValue, 1 assoeji from dual) model return updated rows dimension by(soeji) measures(ArrValue) rules(ArrValue[4] = 'Hello CodeZine');
| Hello CodeZine | 4 |
使用model return updated rows的话,被rules更新或者插入的行才显示,没有更新过的行不再作为SQL的结果。
| ID | Val |
| 1 | 30 |
| 2 | 100 |
| 3 | 50 |
| 4 | 300 |
select ID,Val
from addTotal
model
dimension by(ID)
measures(Val)
rules( Val[null] = Val[1]+Val[2]+Val[3]+Val[4] );
| ID | Val |
| 1 | 30 |
| 2 | 100 |
| 3 | 50 |
| 4 | 300 |
| null | 480 |
不使用model的话可以使用rollup,union all等实现。
select ID,sum(Val) as Val from addTotal group by rollup(ID);
union all方式:
select ID,Val from addTotal union all select null,Sum(Val) from addTotal;
=================================================
以产品产量表为例,一个工厂(用code表示)生产多种产品(用p_id表示),每种产品具有生产量(v1)和销售量(v2)
产品代码具有审核关系,比如’10’=’30’+’31’,其中’10’代表大类,’30’和’31’代表’10’大类下的小类。
SQL> create table t603 (code varchar(10),p_id varchar(7),v1 number(10),v2 number(10));
Table created.
SQL> insert into t603 values(’600001’,’30’,1,1);
SQL> insert into t603 values(’600001’,’31’,1,1);
SQL> insert into t603 values(’600001’,’10’,2,2);
SQL> insert into t603 values(’600002’,’10’,3,2);
SQL> insert into t603 values(’600002’,’31’,2,1);
SQL> insert into t603 values(’600002’,’30’,2,1);
SQL> commit;
Commit complete.
SQL> select * from t603;
CODE P_ID V1 V2
600001 30 1 1
600001 31 1 1
600001 10 2 2
600002 10 3 2
600002 31 2 1
600002 30 2 1
6 rows selected.
SELECT code,
p_id, v1
FROM t603
WHERE code IN (’600001’,’600002’)
MODEL RETURN UPDATED ROWS
PARTITION BY (code)
DIMENSION BY (p_id)
MEASURES (v1)
RULES (
v1[’err1’] = v1[’30’] + v1[’31’] -v1[’10’])
ORDER BY code, p_id;
其中rule表示计算规则,’err1’表示这条审核关系的代号,它的值等于P_ID为’30’的v1值+P_ID为’31’的v1值-P_ID为’10’的v1值
PARTITION BY (code)表示按工厂分区,即审核在一个工厂内的产品
MODEL 关键字后面的 RETURN UPDATED ROWS 子句将结果限制为在该查询中创建或更新的那些行。使用该子句是使结果集只包含新计算的值,在本例中就是审核结果
CODE P_ID V1
600001 err1 0
600002 err1 1
如果返回值=0,表示v1[’30’] + v1[’31’] =v1[’10’]审核通过,否则,审核不通过
SELECT code,
p_id, v1,v2
FROM t603
WHERE code IN (’600001’,’600002’)
MODEL RETURN UPDATED ROWS
PARTITION BY (code)
DIMENSION BY (p_id)
MEASURES (v1,v2)
RULES (
v1[’err1’] = v1[’30’] + v1[’31’] -v1[’10’],
v2[’err1’] = v2[’30’] + v2[’31’] -v2[’10’])
ORDER BY code, p_id;
CODE P_ID V1 V2
600001 err1 0 0
600002 err1 1 0
如果表格中包含多个维度的数据,比如时间,多个维度都可以编写规则,比如2008年的审核关系
SELECT year,code,
p_id, v1
FROM t603_1
WHERE code IN (’600001’,’600002’)
MODEL RETURN UPDATED ROWS
PARTITION BY (code)
DIMENSION BY (p_id,year)
MEASURES (v1)
RULES (
v1[’err1’,2008] = v1[’30’,2008] + v1[’31’,2008] -v1[’10’,2008])
ORDER BY code, p_id;
YEAR CODE P_ID V1
2008 600001 err1 0
2008 600002 err1 1
如果维度不影响规则,也可以只分区,而沿用原来的规则
SELECT year,code,
p_id, v1
FROM t603_1
WHERE code IN (’600001’,’600002’)
MODEL RETURN UPDATED ROWS
PARTITION BY (code,year)
DIMENSION BY (p_id)
MEASURES (v1)
RULES (
v1[’err1’] = v1[’30’] + v1[’31’] -v1[’10’])
ORDER BY code, p_id;
YEAR CODE P_ID V1
2008 600001 err1 0
2008 600002 err1 1
SQL> create table t603_2 as select * from t603_1;
Table created.
SQL> insert into t603_2 select ’2007’ year,code,p_id,v1,v2 from t603_1;
6 rows created.
如果表中具有多个年份的数据,每个年份的审核结果都能显示
SELECT year,code,
p_id, v1
FROM t603_2
WHERE code IN (’600001’,’600002’)
MODEL RETURN UPDATED ROWS
PARTITION BY (code,year)
DIMENSION BY (p_id)
MEASURES (v1)
RULES (
v1[’err1’] = v1[’30’] + v1[’31’] -v1[’10’])
ORDER BY code, p_id;
YEAR CODE P_ID V1
2008 600001 err1 0
2007 600001 err1 0
2007 600002 err1 1
2008 600002 err1 1
规则也可以是多个维度不同取值,本例假定不同年份之间比较,比如要求2008年的’10’=2007年的’30’+’31’
SELECT year,code,
p_id, v1
FROM t603_2
WHERE code IN (’600001’,’600002’)
MODEL RETURN UPDATED ROWS
PARTITION BY (code)
DIMENSION BY (p_id,year)
MEASURES (v1)
RULES (
v1[’err1’,2008] = v1[’30’,2007] + v1[’31’,2007] -v1[’10’,2008])
ORDER BY code, p_id;
YEAR CODE P_ID V1
2008 600001 err1 0
2008 600002 err1 1
如果年份很多,每个年份都是和上年比较,这种描述可以用CV()函数简化
SQL> insert into t603_2 select ’2006’ year,code,p_id,v1,v2 from t603_1;
SELECT year,code,
p_id, v1
FROM t603_2
WHERE code IN (’600001’,’600002’)
MODEL RETURN UPDATED ROWS
PARTITION BY (code)
DIMENSION BY (p_id,year)
MEASURES (v1)
RULES (
v1[’err1’,for year in( 2007 ,2008)] = v1[’30’,CV(year)-1] + v1[’31’,CV(year)-1] -v1[’10’,CV(year)])
ORDER BY code, p_id;
YEAR CODE P_ID V1
2007 600001 err1 0
2008 600001 err1 0
2007 600002 err1 1
2008 600002 err1 1
如果year是数值类型,还可以用for year from 2007 to 2009 increment 1的语法,如果是其他类型,还可以用在in子句带子查询的办法,
比如for year in (select year from t603_2)。
但需要注意不能采用year in 的语法,year in的语法只能符号引用已经存在的单元格,而v1[’err1’,x]是新单元格。
单个年份的写法如下:
SELECT year,code,
p_id, v1
FROM t603_2
WHERE code IN (’600001’,’600002’)
MODEL RETURN UPDATED ROWS
PARTITION BY (code)
DIMENSION BY (p_id,year)
MEASURES (v1)
RULES (
v1[’err1’,2008] = v1[’30’,CV()] + v1[’31’,CV()] -v1[’10’,CV()])
ORDER BY code, p_id;
YEAR CODE P_ID V1
2008 600001 err1 0
2008 600002 err1 1
而
SELECT year,code,
p_id, v1
FROM t603_2
WHERE code IN (’600001’,’600002’)
MODEL RETURN UPDATED ROWS
PARTITION BY (code)
DIMENSION BY (p_id,year)
MEASURES (v1)
RULES (
v1[’err1’,year in (’2008’)] = v1[’30’,CV()] + v1[’31’,CV()] -v1[’10’,CV()])
则返回0行
Oracle的model语句入门-转的更多相关文章
- 【Oracle】转:通过案例学调优之--Oracle Time Model(时间模型)
转自:http://blog.51cto.com/tiany/1596012 通过案例学调优之--Oracle Time Model(时间模型) 数据库时间 优化不仅仅是缩短等待时间.优化旨在缩短最终 ...
- SQL基础语句入门
SQL语句入门 起因 学校开设数据库相关的课程了,打算总结一篇关于基础SQL语句的文章. SQL介绍 SQL最早版本是由IBM开发的,一直发展到至今. SQL语言有如下几个部分: 数据定义语言DDL: ...
- Oracle的update语句优化研究
最近研究sql优化,以下文章转自互联网: 1. 语法 单表:UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值 如:update t_join_situation s ...
- Oracle动态执行语句
一.为什么要使用动态执行语句? 由于在PL/SQL 块或者存储过程中只支持DML语句及控制流语句,并不支持DDL语句,所以Oracle动态执行语句便应允而生了.关于DDL与DML的区别,请参见:D ...
- 1.SQL语句入门
--SQL语句入门-- --1.sql语言是解释语言 --2.它不区分大小写 --3.没有"",所有字符或者字符串都使用''包含 --4.sql里面也有类似于c#的运算符 -- 算 ...
- 【转】Oracle 执行动态语句
1.静态SQLSQL与动态SQL Oracle编译PL/SQL程序块分为两个种:其一为前期联编(early binding),即SQL语句在程序编译期间就已经确定,大多数的编译情况属于这种类型:另外一 ...
- Oracle分页查询语句的写法(转)
Oracle分页查询语句的写法(转) 分页查询是我们在使用数据库系统时经常要使用到的,下文对Oracle数据库系统中的分页查询语句作了详细的介绍,供您参考. Oracle分页查询语句使我们最常用的 ...
- oracle常用SQL语句(汇总版)
Oracle数据库常用sql语句 ORACLE 常用的SQL语法和数据对象一.数据控制语句 (DML) 部分 1.INSERT (往数据表里插入记录的语句) INSERT INTO 表名(字段名1, ...
- oracle之sql语句优化
oracle之sql语句优化 sql语句的优化 1.在where子句中使用 is null 或 is not null 时,oracle优化器就不能使用索引了. 2.对于有连接的列,即使最有一个是静态 ...
随机推荐
- iPhone中修改iMessage关联手机号码的终极方法
同事换iPhone时,也换了手机号码,从联通的换成移动的.但iPhone激活后,iMessage始终关联的是以前的手机号码,试了很多方法都没解决. 后来在网上找到一段视频-Fix most iMess ...
- mongodb(二) 安装和使用
mongodb的安装和使用 最近的项目需要使用到mongodb,从而开始熟悉nosql,有了本篇文章,记录和方便他人. mongodb的安装 下载地址:http://www.mongodb.org/d ...
- 拉勾网ThoughtWorks面试题代码实现
今天看到一个很有意思的面试活动(活动链接),不需要简历,只有一道编程题目,在线提交你的代码即可. 本菜鸟对面试不感兴趣,但题目让我很兴奋,特来挑战一下~ 或许当你看到这篇博文的时候活动已经失效了,所以 ...
- Spring基本概念
spring优点: 1降低组件间耦合度,实现软件各层之间的解耦. 2可以使用容器提供的各种服务.如,事务管理服务,消息服务等等. 当我们使用容器管理事务时,开发人员就不再需要手工控制事务,也不需处理复 ...
- iOS-App生命周期
iOS APP 生命周期 官方文档: https://developer.apple.com/library/ios/documentation/iPhone/Conceptual/iPhoneO ...
- iOS-APP发布应注意要点
Android和IOS的app发布的流程有一个相同之处,就是都需要先将编译好的app签名,然后上传到market里,但两者的复杂度是冰火两重天.Android可以手动通过集成在eclipse里的工具进 ...
- Unity中的协程是什么?
什么是协程? 1.协程是一个分部执行,遇到条件(yield return 语句)会挂起,直到条件满足才会被唤醒继续执行后面的代码. 2.Unity在每一帧(Frame)都会去处理对象上的协程.Unit ...
- jsp实现验证码
在web开发领域里面,验证码是一个比较常见的功能,而归根到底,验证码其实就是一组随机数,或者是一个随机算术 一.基本知识 1.为什么需要验证码? 验证码,很多时候出现在注册页面或者登陆界面,在这些页面 ...
- RTL8710 ROM 符号表 函数,常量,变量
函数 Name Address Ordinal ---- ------- ------- __vectors_table Reset_Handler NMI_Handler HardFault_Han ...
- windows地址转发
netsh interface portproxy add v4tov4 listenport=8080 connectaddress=192.168.8.108 connectport=8080 把 ...