Advacned Puppet: Puppet Master性能调优
本文是Advanced Puppet系列的第一篇:Puppet master性能调优,谈一谈如何优化和提高C/S架构下master端的性能。
故事情节往往惊人地类似:你是一名使用Puppet管理线上业务的DevOps工程师,随着公司的业务发展,你所管理的集群规模日益扩大。终于某一天,你突然发现执行一次puppet agent -vt的时间长得不可接受,多台agent并发运行时竟然会有节点运行失败,往日从来没有考虑过Puppet的性能居然成为了瓶颈……首先要恭喜你,因为Puppet Master端的性能瓶颈只有在集群发展到一定规模时才会遇到。

图1 性能调优
{kind=link}
笼统地去谈系统的性能调优,是一个泛泛的话题,陈皓在他的《性能调优攻略》中介绍了系统性能的定义和如何定位性能瓶颈。因此,本篇把讨论范围缩小:只关注master端的性能调优,而不涉及Puppet代码的执行效率调优,部署逻辑的调优等等。
我们要对Puppet进行优化前,首先要清楚它有哪些瓶颈。对Puppet的C/S架构所有了解后,我们把它归类到Web服务: puppet agent端向puppet master发送请求,puppet master端处理请求并返回结果。web服务常见的性能度量指标是响应时间,系统吞吐量,系统资源利用率,并发用户数等。那么在这里我们主要关注两个指标:响应时间和并发用户数。因此,在对Puppet Master进行调优前,需要了解agent端和master端是如何交互的。
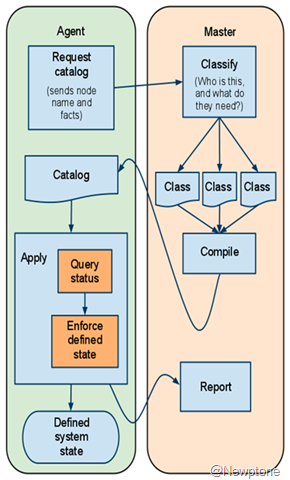 图2 Puppet C/S架构下的处理流程图
图2 Puppet C/S架构下的处理流程图
从图2可以看到一次完整的agent请求catalog的具体流程,Agent和Master之间的交互可以分为三步:
1. agent先向master发送一个请求,希望获取自己的catalog;
2. Master端通过agent附带的fqdn,environment等facts信息判断节点的分类,随后对其所属的class,define等资源进行编译;处理完成后把catalog以json格式返回给agent端;
3. Agent端拿到catalog后先做一个本地的状态查询,然后进行收敛达到预期的状态,完成后发送一个本次执行概况的report给Master端
ok,那我们来看一下实际的运行结果是如何的:以一台RabbitMQ节点向PuppetMaster发起一次执行操作为例,先分析Server端的访问日志有哪些操作:
10.0.1.45 - - [/Aug/::: -] "GET /production/node/server-45.1.test.ustack.in? HTTP/1.1" "-" "-"
10.0.1.45 - - [/Aug/::: -] "GET /production/file_metadatas/plugins?links=manage&recurse=true&checksum_type=md5&ignore=.svn&ignore=CVS&ignore=.git HTTP/1.1" "-" "-"
10.0.1.45 - - [/Aug/::: -] "POST /production/catalog/server-45.1.test.ustack.in HTTP/1.1" "-" "-"
10.0.1.45 - - [/Aug/::: -] "GET /production/file_metadata/modules/rsyslog/rsyslog_default?links=manage HTTP/1.1" "-" "-"
10.0.1.45 - - [/Aug/::: -] "GET /production/file_metadata/modules/ssh/sshd_config?links=manage HTTP/1.1" "-" "-"
10.0.1.45 - - [/Aug/::: -] "GET /production/file_metadata/modules/ssh/ssh_config?links=manage HTTP/1.1" "-" "-"
10.0.1.45 - - [/Aug/::: -] "GET /production/file_metadatas/modules/mcollective/site_libdir?links=manage&recurse=true&checksum_type=md5 HTTP/1.1" "-" "-"
10.0.1.45 - - [/Aug/::: -] "GET /production/file_metadatas/modules/mcollective/plugins/actionpolicy?links=manage&recurse=true&checksum_type=md5 HTTP/1.1" "-" "-"
10.0.1.45 - - [/Aug/::: -] "GET /production/file_metadata/modules/logrotate/etc/logrotate.conf?links=manage HTTP/1.1" "-" "-"
10.0.1.45 - - [/Aug/::: -] "GET /production/file_metadata/modules/logrotate/etc/cron.hourly/logrotate?links=manage HTTP/1.1" "-" "-"
10.0.1.45 - - [/Aug/::: -] "GET /production/file_metadata/modules/logrotate/etc/cron.daily/logrotate?links=manage HTTP/1.1" "-" "-"
10.0.1.45 - - [/Aug/::: -] "PUT /production/report/server-45.1.test.ustack.in HTTP/1.1" "-" "-"
再来看agent端的输出日志:
time puppet agent -vt Info: Retrieving plugin
Info: Caching catalog for server-45.1.test.ustack.in
Info: Applying configuration version ''
Notice: Finished catalog run in 4.57 seconds real 0m17.579s
所谓catalog的编译,实质上是生成一个资源执行的有向状态图,是一个消耗CPU和磁盘IO资源的计算操作。在一次没有任何变更操作的情况,Puppet在分类和编译catalog上花费了整整11秒的时间,而作为文件服务器向agent端提供文件下载只花费了4秒,那么我们能从哪些方面来缩短master的响应时间?首先我们要分析慢在哪里,有哪些可能的原因会导致运行速度慢?
1. 升级软件版本
根据我的交流发现有不少公司仍在使用2.x版本的puppet,尤其以2.7.x居多。因为在Ubuntu/CentOS下,使用默认源安装的puppet版本就是2.7(6).x。根据官方的3.x Release Note,3.x的性能相比2.x相比有非常显著的提升,尤其是与2.7.x相比有50%的提升,我们目前使用的Puppet版本是3.3.1,实测结果是:相比2.7.14,整体的执行速度约提升了30%(与具体的部署逻辑相关)。
升级带来另外一个重要的问题:兼容性。我们知道把一个项目从Python2.7升级到Python3.4是一个非常困难的事情,某些语法的变更,最让人头疼的是大量的第三方库并不支持3.x。但是从Puppet 2.7(6).x升级到3.x你不需要太担心兼容性问题,因为绝大多数的puppet modules支持3.x的puppet语法规范。可能需要变动的是你自己编写的模块,例如模板,变量的命令空间等一些变动,并且这些兼容性问题只是以warning的形式提醒你进行修改。
2. 设置客户端合理的运行间隔
常常有不少同学喜欢把puppet agent端的运行间隔runinterval参数设置得很短,例如180s甚至60s。他们希望通过这种不停运行agent的方式,一是能够替代主动推送的需求,二是可以做到当服务意外停止,配置文件被人为修改后,可以尽快地恢复。这些想法并不能满足上述需求。
首先,推和拉是两个不同的操作模式,若以频繁的被动拉取节点配置来替代主动推送带来了几个问题:
1. 无意义地浪费server端的性能,从前面的数据中可以得知编译catalog是一个非常耗资源的操作;
2. 线上的一切变更均属于严肃的变更流程,需要主动地控制升级策略,例如两个web服务节点的升级流程,先得把web-01从lb背后摘下,进行变更,然后再重新上线,接着对web-02做同样的操作,拉模型明显不符合这样的部署需求;
3. 服务监控属于监控体系来管理,让puppet来做,心有余而力不足;
一个合理的runinterval值应该根据集群的规模来进行调整,官方的推荐值是1800s。
3.设置Splay避免惊群效应
举个简单的例子,当你往一群鸽子中间扔一块食物,虽然最终只有一个鸽子抢到食物,但所有鸽子都会被惊动来争夺,没有抢到食物的鸽子只好回去继续睡觉, 等待下一块食物到来。这样,每扔一块食物,都会惊动所有的鸽子,称为惊群。对于PuppetMaster来说,多个puppetmaster进程在等待CPU和IO资源时也会产生类似的情况。
在搭建内部开发环境的初期,我对puppet agent的运行间隔设置随意设置了一个较短的值:300s。本以为大功告成,但是当集群规模增加了一倍后,我发现agent从Puppet Master获取一次catalog的时间超过了我的预期。通过分析apache日志我才发现,所有节点几乎在同个时间段向这台可怜的PuppetMaster发出了请求,瞬间把这台运行在hypervisor上的master的CPU资源跑满。解决这个问题的办法就是设法错开Agent的拉取时间点,puppet默认提供了splay参数来满足这个需求。
你需要在每台agent节点的puppet配置文件中,添加:
splay = true
还有一个splaylimit参数,若不设置则默认会取runinterval的值。Puppet agent每次会在runinterval的基础上,增加0~splaylimit(秒)间的随机值后再运行,大大降低了agent同一时刻运行的概率。
4.弃用Webrick
很多同学喜欢使用ruby自带的webrick webserver来启动puppetmaster服务,因为简单方便。例如:
service puppetmaster start
首先,你要明白一点的是这些语言的内置webserver目的仅是为了方便调试代码,是根本不能放到生产环境去使用。
使用WebRick运行的Puppetmaster性能有多差?
仅9个并发请求就能把它拖垮。
我在在一台E5 2620的服务器上试验:只要9个puppet agent同时向运行在webrick上的puppet master发送请求,就处理不过来了,你会发现总有某台agent会出现40x Error的错误。
要提高单台Puppetmaster的性能很简单,只要使用常见的Web Server软件就可以显著地提高Puppet master的性能,例如Apache,Nginx等。这类文档很多,这里就不再详细说明配置的步骤了。
5.禁止使用activerecord + SQL作为Storeconfigs Backend
当你在开启了storeconfigs来使用Puppet的一些高级特性时,请注意不要使用activerecord + SQL的组合作为其后端存储。这对组合常常在2.x版本中出现得比较多,因为那时它的替代品PuppetDB还没有成熟,我们也曾经使用了近一年的ActiveRecord + MySQL的方式来做后端存储,它的目的就是把生成的catalog,facts等等都存到数据库中,其性能就是慢,慢,慢。去年我们在做私有云项目时,起初部署一台控制节点,竟然要30分钟!慢到老大一度想要用shell脚本去取代puppet,一度让我想把代码中所有高级特性全部禁用。我不得不寻求其他替代技术来改善storeconfigs的运行效率。
Puppet 3.x升级的另一个特性就是把这些老古董标记为弃用,当时社区推出了PuppetDB + PostgreSQL的新组合,其目的就是为了替代它们的。在执行存储和查询操作时,性能上提升不止快了一倍,最终交付给用户的时候,部署时间下降到了18分钟。不过,我已经忘记把测试对比数据丢哪了,可能是随ActiveRecord + MySQL一起丢了 :D。
6. 横向扩展Puppet集群
经过上述的优化后,你通过观察CPU负载发现单台Puppet已无法管理当前的集群规模时,可以对Puppet进行横向扩展。web服务的性能扩展较为容易,通过简单地增加puppet master节点的数量就能轻松地提高处理能力。在前端放置七层负载均衡,用于处理SSL认证和转发请求。如何搭建Puppet集群,如何在前端设置七层负载均衡的配置过程,我之前已写过相关的文章,也可以通过网上找到相应的资料。
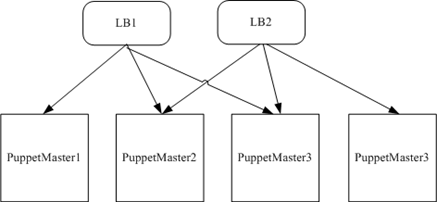
图3 Puppet集群的典型架构图
7. 纵向扩展与横向扩展PuppetDB服务
当你选择使用PuppetDB作为storeconfigs的组件时,那么PuppetDB将是Puppet部署中的重要组件,如果PuppetDB挂了,那么agent节点将无法得到catalog。PuppetDB节点是属于典型的耗CPU,耗内存,耗磁盘IO的资源使用大户。下面我们来看看实际使用中可能会遇到的瓶颈以及解决办法。
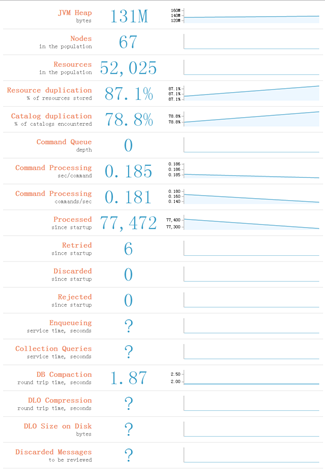 图4 PuppetDB性能监控面板
图4 PuppetDB性能监控面板
7.1 数据库的性能瓶颈
PuppetDB主要作用是存储和查询catalog,facts和reports,其主要瓶颈主要在于后端PostgreSQL的读写性能,我们不可能花费精力去做PG的性能调优,需要找一种廉价的方式来提高性能。我的老大常常教育我,如果钱能解决的问题,那都不是事儿。因此若通过纵向扩展就能解决问题,其实是一种非常经济的手段:D。因此在生产环境中,推荐使用企业级的SSD盘去替代SATA盘,否则随着集群规模的增加,大量的随机读写操作会让PostgreSQL慢如蜗牛。
7.2 Java Heap大小的瓶颈
在使用PostgreSQL的情况下,分配128MB内存作为基础,然后根据集群的规模来增加额外的内存配置,原则是为每一台puppet node分配1M内存。然后通过观察PuppetDB的性能检测面板再进行适当地调整。修改方式是编辑puppetdb的启动脚本,修改JAVA_ARGS参数,为其分配2G内存:
JAVA_ARGS="-Xmx2g"
7.3 PuppetDB worker进程数的瓶颈
PuppetDB可以有效利用多核来处理其队列中的请求,每个核可以运行一个worker进程,PuppetDB默认只会运行该台机器一半核数的worker。因此,当你发现PuppetDB的性能监控面板上queue depth值长时间不为0时,你就需要配置更多的worker数。

图5 Command Queue 监控图
那如果单台PuppetDB不能满足需求了,如何处理? 那就需要横向扩展PuppetDB,构建PostgreSQL集群,其实大可不必如此忧愁。Puppetlabs官方给出的数据是使用一台2012年的笔记本 (16 GB of RAM, consumer-grade SSD, and quad-core processor)运行PuppetDB和PostgreSQL足以支撑8000台Puppet nodes每30分钟一次的运行。
8 总结
本篇中,我们先后从软件版本的升级,相关参数的调整,选择Web服务器作为容器,横向扩展,纵向扩展,后端存储的替换等多个方面考虑去提高Puppetmaster端的性能,具体到生产环境中,实际情况会所有不同,但是方法都是相同的:分析问题本质,找出问题所在,确定合理的优化方案。
Advacned Puppet: Puppet Master性能调优的更多相关文章
- Spark 常规性能调优
1. 常规性能调优 一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围内,增加资源的分配与性能的提升是成正比的,实现了最优的资源配置后,在此基础上再考虑进行后面论述的性 ...
- Redis基础用法、高级特性与性能调优以及缓存穿透等分析
一.Redis介绍 Redis是一个开源的,基于内存的结构化数据存储媒介,可以作为数据库.缓存服务或消息服务使用.Redis支持多种数据结构,包括字符串.哈希表.链表.集合.有序集合.位图.Hype ...
- Redis基础、高级特性与性能调优
本文将从Redis的基本特性入手,通过讲述Redis的数据结构和主要命令对Redis的基本能力进行直观介绍.之后概览Redis提供的高级能力,并在部署.维护.性能调优等多个方面进行更深入的介绍和指导. ...
- Redis 基础、高级特性与性能调优
本文将从Redis的基本特性入手,通过讲述Redis的数据结构和主要命令对Redis的基本能力进行直观介绍.之后概览Redis提供的高级能力,并在部署.维护.性能调优等多个方面进行更深入的介绍和指导. ...
- Informatica_(6)性能调优
六.实战汇总31.powercenter 字符集 了解源或者目标数据库的字符集,并在Powercenter服务器上设置相关的环境变量或者完成相关的设置,不同的数据库有不同的设置方法: 多数字符集的问题 ...
- MySql(十):MySQL性能调优——MySQL Server性能优化
本章主要通过针对MySQL Server( mysqld)相关实现机制的分析,得到一些相应的优化建议.主要涉及MySQL的安装以及相关参数设置的优化,但不包括mysqld之外的比如存储引擎相关的参数优 ...
- MySQL性能调优与架构设计——第 18 章 高可用设计之 MySQL 监控
第 18 章 高可用设计之 MySQL 监控 前言: 一个经过高可用可扩展设计的 MySQL 数据库集群,如果没有一个足够精细足够强大的监控系统,同样可能会让之前在高可用设计方面所做的努力功亏一篑.一 ...
- MySQL性能调优与架构设计——第 17 章 高可用设计之思路及方案
第 17 章 高可用设计之思路及方案 前言: 数据库系统是一个应用系统的核心部分,要想系统整体可用性得到保证,数据库系统就不能出现任何问题.对于一个企业级的系统来说,数据库系统的可用性尤为重要.数据库 ...
- MySQL性能调优与架构设计——第 16 章 MySQL Cluster
第 16 章 MySQL Cluster 前言: MySQL Cluster 是一个基于 NDB Cluster 存储引擎的完整的分布式数据库系统.不仅仅具有高可用性,而且可以自动切分数据,冗余数据等 ...
随机推荐
- hihoCoder 1305 区间求差
#1305 : 区间求差 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 给定两个区间集合 A 和 B,其中集合 A 包含 N 个区间[ A1, A2 ], [ A3, ...
- ABP的工作单元
http://www.aspnetboilerplate.com/Pages/Documents/Unit-Of-Work 工作单元位于领域层. ABP的数据库连接和事务处理: 1,仓储类 ASP ...
- 使用 IntraWeb (41) - 数据控件速查
TIWDBCheckBox 所在单元及继承链: IWDBStdCtrls.TIWDBCheckBox 主要成员: property AutoEditable: Boolean //根据 DataSou ...
- json jackson
1.引入依赖 <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId&g ...
- HDU-3548-Enumerate the Triangles
求由所有的点组成的三角形中周长最小的三角形的周长 1.将所有的点按横坐标大小排序 2.从第一个点开始往后枚举,判断能否组成三角形,判断当前三角形周长是否小于已经得到的最小周长 代码如下: #inclu ...
- C语言中scanf()的用法!
好文章转自:http://blog.tianya.cn/blogger/post_show.asp?BlogID=287129&PostID=3668453 scanf详解 scanf 原型: ...
- C++内存分配方式详解——堆、栈、自由存储区、全局/静态存储区和常量存储区
栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区.里面的变量通常是局部变量.函数参数等.在一个进程中,位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用.和堆一样 ...
- OWIN的理解和实践(一) – 解耦,协作和开放
概述 OWIN的全称是Open Web Interface For .Net, 是MS在VS2013期间引入的全新的概念, 网上已经有不少的关于它的信息, 这里我就谈下我自己的理解: OWIN是一种规 ...
- [MSSQL]SCOPE_IDENTITY,IDENT_CURRENT以及@@IDENTITY的区别
简单解释下SCOPE_IDENTITY函数,IDENT_CURRENT函数以及@@IDENTITY全局变量的区别 SCOPE_IDENTITY函数返回当前作用域内,返回最后一次插入数据表的标识,意思是 ...
- 更改MySql表和字段区分大小写
数据库和表名在 Windows 中是大小写不敏感的 ,而在大多数类型的 Unix 系统中是大小写敏感的Windows 版的 MySQL 默认继承 os 的大小写习惯,即使 SQL中有区分,在导入的时候 ...