基于虎书实现LALR(1)分析并生成GLSL编译器前端代码(C#)
基于虎书实现LALR(1)分析并生成GLSL编译器前端代码(C#)
为了完美解析GLSL源码,获取其中的信息(都有哪些in/out/uniform等),我决定做个GLSL编译器的前端(以后简称编译器或FrontEndParser)。
以前我做过一个CGCompiler,可以自动生成LL(1)文法的编译器代码(C#语言的)。于是我从《The OpenGL ® Shading Language》(以下简称"PDF")找到一个GLSL的文法,就开始试图将他改写为LL(1)文法。等到我重写了7次后发现,这是不可能的。GLSL的文法超出了LL(1)的范围,必须用更强的分析算法。于是有了现在的LALR(1)Compiler。
理论来源
《现代编译原理-c语言描述》(即"虎书")中提供了详尽的资料。我就以虎书为理论依据。
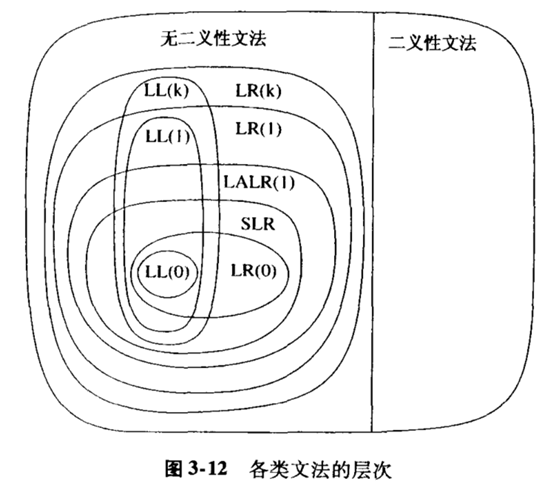
虎书中的下图表明了各种类型的文法的范围。一般正常的程序语言都是符合LALR(1)文法的。
由于LR(0)是SLR的基础,SLR是LR(1)的基础;又由于LR(1)是LALR(1)的基础(这看上去有点奇怪),所以我必须从LR(0)文法开始一步一步实现LALR(1)算法。
输入
给定文法,这个文法所描述的语言的全部信息就都包含进去了。文法里包含了这个语言的关键字、推导结构等所有信息。这也是我觉得YACC那些东西不好的地方:明明有了文法,还得自己整理出各种关键字。
下面是一个文法的例子:
// 虎书中的文法3-10
<S> ::= <V> "=" <E> ;
<S> ::= <E> ;
<E> ::= <V> ;
<V> ::= "x" ;
<V> ::= "*" <E> ;
下面是6个符合此文法的代码:
x
*x
x = x
x = * x
*x = x
**x = **x
输出
输出结果是此文法的编译器代码(C#)。这主要是词法分析器LexicalAnalyzer和语法分析器SyntaxParser两个类。
之后利用C#的CSharpCodeProvider和反射技术来加载、编译、运行生成的代码,用一些例子(例如上面的*x = x)测试是否能正常运行。只要能正常生成语法树,就证明了我的LALR(1)Compiler的实现是正确的。
例如对上述文法的6个示例代码,LALR(1)Compiler可以分别dump出如下的语法树:
(__S)[S][<S>]
└─(__E)[E][<E>]
└─(__V)[V][<V>]
└─(__xLeave__)[x][x]
x
(__S)[S][<S>]
└─(__E)[E][<E>]
└─(__V)[V][<V>]
├─(__starLeave__)[*]["*"]
└─(__E)[E][<E>]
└─(__V)[V][<V>]
└─(__xLeave__)[x][x]
*x
(__S)[S][<S>]
├─(__V)[V][<V>]
│ └─(__xLeave__)[x][x]
├─(__equalLeave__)[=]["="]
└─(__E)[E][<E>]
└─(__V)[V][<V>]
└─(__xLeave__)[x][x]
x = x
(__S)[S][<S>]
├─(__V)[V][<V>]
│ └─(__xLeave__)[x][x]
├─(__equalLeave__)[=]["="]
└─(__E)[E][<E>]
└─(__V)[V][<V>]
├─(__starLeave__)[*]["*"]
└─(__E)[E][<E>]
└─(__V)[V][<V>]
└─(__xLeave__)[x][x]
x = * x
(__S)[S][<S>]
├─(__V)[V][<V>]
│ ├─(__starLeave__)[*]["*"]
│ └─(__E)[E][<E>]
│ └─(__V)[V][<V>]
│ └─(__xLeave__)[x][x]
├─(__equalLeave__)[=]["="]
└─(__E)[E][<E>]
└─(__V)[V][<V>]
└─(__xLeave__)[x][x]
*x = x
(__S)[S][<S>]
├─(__V)[V][<V>]
│ ├─(__starLeave__)[*]["*"]
│ └─(__E)[E][<E>]
│ └─(__V)[V][<V>]
│ ├─(__starLeave__)[*]["*"]
│ └─(__E)[E][<E>]
│ └─(__V)[V][<V>]
│ └─(__xLeave__)[x][x]
├─(__equalLeave__)[=]["="]
└─(__E)[E][<E>]
└─(__V)[V][<V>]
├─(__starLeave__)[*]["*"]
└─(__E)[E][<E>]
└─(__V)[V][<V>]
├─(__starLeave__)[*]["*"]
└─(__E)[E][<E>]
└─(__V)[V][<V>]
└─(__xLeave__)[x][x]
**x = **x
能够正确地导出这些结果,就说明整个库是正确的。其实,只要能导出这些结果而不throw Exception(),就可以断定结果是正确的了
计划
所以我的开发步骤如下:
示例
虎书中已有了文法3-1(如下)的分析表和一个示例分析过程,所以先手工实现文法3-1的分析器。从这个分析器的代码中抽取出所有LR分析器通用的部分,作为LALR(1)Compiler的一部分。
// 虎书中的文法3-1
<S> ::= <S> ";" <S> ;
<S> ::= identifier ":=" <E> ;
<S> ::= "print" "(" <L> ")" ;
<E> ::= identifier ;
<E> ::= number ;
<E> ::= <E> "+" <E> ;
<E> ::= "(" <S> "," <E> ")" ;
<L> ::= <E> ;
<L> ::= <L> "," <E> ;
算法
经此之后就对语法分析器的构成心中有数了。下面实现虎书中关于自动生成工具的算法。
最妙的是,即使开始时不理解这些算法的原理,也能够实现之。实现后通过测试用例debug的过程,就很容易理解这些算法了。
LR(0)
首先有两个基础算法。Closure用于补全一个state。Goto用于找到一个state经过某个Node后会进入的下一个state。说是算法,其实却非常简单。虽然简单,要想实现却有很多额外的工作。例如比较两个LR(0)Item的问题。

然后就是计算文法的状态集和边集(Goto动作集)的算法。这个是核心内容。

用此算法可以画出文法3-8的状态图如下:
// 虎书中的文法3-8
<S> ::= "(" <L> ")" ;
<S> ::= "x" ;
<L> ::= <S> ;
<L> ::= <L> "," <S> ;

最后就是看图作文——构造分析表了。有了分析表,语法分析器的核心部分就完成了。

SLR
在A->α.可以被归约时,只在下一个单词是Follow(A)时才进行归约。看起来很有道理的样子。

LR(1)
LR(1)项(A->α.β,x)指出,序列α在栈顶,且输入中开头的是可以从βx导出的符号。看起来更有道理的样子。

LR(1)的state补全和转换算法也要调整。

然后又是看图作文。

LALR(1)
LALR(1)是对LA(1)的化简处理。他占用空间比LR(1)少,但应用范围也比LR(1)小了点。

为了实现LALR(1),也为了提高LR(1)的效率,必须优化LR(1)State,不能再单纯模仿LR(0)State了。
文法的文法
输入的是文法,输出的是编译器代码,这个过程也可以用一个编译器来实现。这个特别的编译器所对应的文法(即描述文法的文法)如下:(此编译器命名为ContextfreeGrammarCompiler)
// 文法是1到多个产生式
<Grammar> ::= <ProductionList> <Production> ;
// 产生式列表是0到多个产生式
<ProductionList> ::= <ProductionList> <Production> | null ;
// 产生式是左部+第一个候选式+若干右部
<Production> ::= <Vn> "::=" <Canditate> <RightPartList> ";" ;
// 候选式是1到多个结点
<Canditate> ::= <VList> <V> ;
// 结点列表是0到多个结点
<VList> ::= <VList> <V> | null ;
// 右部列表是0到多个候选式
<RightPartList> ::= "|" <Canditate> <RightPartList> | null ;
// 结点是非叶结点或叶结点
<V> ::= <Vn> | <Vt> ;
// 非叶结点是<>括起来的标识符
<Vn> ::= "<" identifier ">" ;
// 叶结点是用"引起来的字符串常量或下列内容:null, identifier, number, constString, userDefinedType
// 这几个标识符就是ContextfreeGrammar的关键字
<Vt> ::= "null" | "identifier" | "number" | "constString" | "userDefinedType"| constString ;
设计
算法看起来还是很简单的。即使不理解他也能实现他。但是实现过程中还是出现了不少的问题。
Hash缓存
如何判定两个对象(LR(0)Item)相同?
这是个不可小觑的问题。
必须重写==、!=运算符,override掉Equals和GetHashCode方法。这样才能判定两个内容相同但不是同一个对象的Item、State相等。
对于LR(0)Item的比较,在计算过程中有太多次,这对于实际应用(例如GLSL的文法)是不可接受的。所以必须缓存这类对象的HashCode。
/// <summary>
/// 缓存一个对象的hash code。提高比较(==、!=、Equals、GetHashCode、Compare)的效率。
/// </summary>
public abstract class HashCache : IComparable<HashCache>
{
public static bool operator ==(HashCache left, HashCache right)
{
object leftObj = left, rightObj = right;
if (leftObj == null)
{
if (rightObj == null) { return true; }
else { return false; }
}
else
{
if (rightObj == null) { return false; }
} return left.Equals(right);
} public static bool operator !=(HashCache left, HashCache right)
{
return !(left == right);
} public override bool Equals(object obj)
{
HashCache p = obj as HashCache;
if ((System.Object)p == null)
{
return false;
} return this.HashCode == p.HashCode;
} public override int GetHashCode()
{
return this.HashCode;
} private Func<HashCache, string> GetUniqueString; private bool dirty = true; /// <summary>
/// 指明此cache需要更新才能用。
/// </summary>
public void SetDirty() { this.dirty = true; } private int hashCode;
/// <summary>
/// hash值。
/// </summary>
public int HashCode
{
get
{
if (this.dirty)
{
Update(); this.dirty = false;
} return this.hashCode;
}
} private void Update()
{
string str = GetUniqueString(this);
int hashCode = str.GetHashCode();
this.hashCode = hashCode;
#if DEBUG
this.uniqueString = str;// debug时可以看到可读的信息
#else
this.uniqueString = string.Format("[{0}]", hashCode);// release后用最少的内存区分此对象
#endif
} // TODO: 功能稳定后应精简此字段的内容。
/// <summary>
/// 功能稳定后应精简此字段的内容。
/// </summary>
private string uniqueString = string.Empty; /// <summary>
/// 可唯一标识该对象的字符串。
/// 功能稳定后应精简此字段的内容。
/// </summary>
public string UniqueString
{
get
{
if (this.dirty)
{
Update(); this.dirty = false;
} return this.uniqueString;
}
} /// <summary>
/// 缓存一个对象的hash code。提高比较(==、!=、Equals、GetHashCode、Compare)的效率。
/// </summary>
/// <param name="GetUniqueString">获取一个可唯一标识此对象的字符串。</param>
public HashCache(Func<HashCache, string> GetUniqueString)
{
if (GetUniqueString == null) { throw new ArgumentNullException(); } this.GetUniqueString = GetUniqueString;
} public override string ToString()
{
return this.UniqueString;
} public int CompareTo(HashCache other)
{
if (other == null) { return ; } if (this.HashCode < other.HashCode)// 如果用this.HashCode - other.HashCode < 0,就会发生溢出,这个bug让我折腾了近8个小时。
{ return -; }
else if (this.HashCode == other.HashCode)
{ return ; }
else
{ return ; }
}
}
HashCache
有序集合
如何判定两个集合(LR(0)State)相同?
一个LR(0)State是一个集合,集合内部的元素是没有先后顺序的区别的。但是为了比较两个State,其内部元素必须是有序的(这就可以用二分法进行插入和比较)。否则比较两个State会耗费太多时间。为了尽可能快地比较State,也要缓存State的HashCode。
有序集合的应用广泛,因此独立成类。
/// <summary>
/// 经过优化的列表。插入新元素用二分法,速度更快,但使用者不能控制元素的位置。
/// 对于LALR(1)Compiler项目,只需支持“添加元素”的功能,所以我没有写修改和删除元素的功能。
/// </summary>
/// <typeparam name="T">元素也要支持快速比较。</typeparam>
public class OrderedCollection<T> :
HashCache // 快速比较两个OrderedCollection<T>是否相同。
, IEnumerable<T> // 可枚举该集合的元素。
where T : HashCache // 元素也要支持快速比较。
{
private List<T> list = new List<T>();
private string seperator = Environment.NewLine; /// <summary>
/// 这是一个只能添加元素的集合,其元素是有序的,是按二分法插入的。
/// 但是使用者不能控制元素的顺序。
/// </summary>
/// <param name="separator">在Dump到流时用什么分隔符分隔各个元素?</param>
public OrderedCollection(string separator)
: base(GetUniqueString)
{
this.seperator = separator;
} private static string GetUniqueString(HashCache cache)
{
OrderedCollection<T> obj = cache as OrderedCollection<T>;
return obj.Dump();
} public virtual bool TryInsert(T item)
{
if (this.list.TryBinaryInsert(item))
{
this.SetDirty();
return true;
}
else
{
return false;
}
} public int IndexOf(T item)
{
return this.list.BinarySearch(item);
} public bool Contains(T item)
{
int index = this.list.BinarySearch(item);
return ( <= index && index < this.list.Count);
} public T this[int index] { get { return this.list[index]; } } public IEnumerator<T> GetEnumerator()
{
foreach (var item in this.list)
{
yield return item;
}
} public int Count { get { return this.list.Count; } } System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator()
{
return this.GetEnumerator();
} public override void Dump(System.IO.TextWriter stream)
{
for (int i = ; i < this.list.Count; i++)
{
this.list[i].Dump(stream);
if (i + < this.list.Count)
{
stream.Write(this.seperator);
}
}
}
}
OrderedCollection<T>
其中有个TryBinaryInsert的扩展方法,用于向 IList<T> 插入元素。这个方法我经过严格测试。如果有发现此方法的bug向我说明,我愿意奖励¥100元。
/// <summary>
/// 尝试插入新元素。如果存在相同的元素,就不插入,并返回false。否则返回true。
/// </summary>
/// <typeparam name="T"></typeparam>
/// <param name="list"></param>
/// <param name="item"></param>
/// <returns></returns>
public static bool TryBinaryInsert<T>(this List<T> list, T item)
where T : IComparable<T>
{
bool inserted = false; if (list == null || item == null) { return inserted; } int left = , right = list.Count - ;
if (right < )
{
list.Add(item);
inserted = true;
}
else
{
while (left < right)
{
int mid = (left + right) / ;
T current = list[mid];
int result = item.CompareTo(current);
if (result < )
{ right = mid; }
else if (result == )
{ left = mid; right = mid; }
else
{ left = mid + ; }
}
{
T current = list[left];
int result = item.CompareTo(current);
if (result < )
{
list.Insert(left, item);
inserted = true;
}
else if (result > )
{
list.Insert(left + , item);
inserted = true;
}
}
} return inserted;
}
TryBinaryInsert<T>(this IList<T> list, T item) where T : IComparable<T>
迭代到不动点
虎书中的算法大量使用了迭代到不动点的方式。

这个方法虽好,却仍有可优化的余地。而且这属于核心的计算过程,也应当优化。
优化方法也简单,用一个Queue代替"迭代不动点"的方式即可。这就避免了很多不必要的重复计算。
/// <summary>
/// LR(0)的Closure操作。
/// 补全一个状态。
/// </summary>
/// <param name="list"></param>
/// <param name="state"></param>
/// <returns></returns>
static LR0State Closure(this RegulationList list, LR0State state)
{
Queue<LR0Item> queue = new Queue<LR0Item>();
foreach (var item in state)
{
queue.Enqueue(item);
}
while (queue.Count > )
{
LR0Item item = queue.Dequeue();
TreeNodeType node = item.GetNodeNext2Dot();
if (node == null) { continue; } foreach (var regulation in list)
{
if (regulation.Left == node)
{
var newItem = new LR0Item(regulation, );
if (state.TryInsert(newItem))
{
queue.Enqueue(newItem);
}
}
}
} return state;
}
Closure
测试
以前我总喜欢做个非常精致的GUI来测试。现在发现没那个必要,简单的Console就可以了。
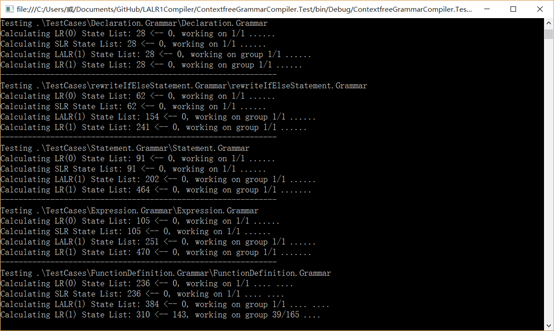
详细的测试结果导出到文件里,可以慢慢查看分析。
=====> Processing .\TestCases\3_8.Grammar\3_8.Grammar
Get grammar from source code...
Dump 3_8.TokenList.log
Dump 3_8.Tree.log
Dump 3_8.FormatedGrammar.log
Dump 3_8.FIRST.log
Dump 3_8.FOLLOW.log
LR() parsing...
Dump 3_8.State.log
Dump 3_8.Edge.log
Dump LR() Compiler's source code...
SLR parsing...
Dump 3_8.State.log
Dump 3_8.Edge.log
Dump SLR Compiler's source code...
LALR() parsing...
Dump 3_8.State.log
Dump 3_8.Edge.log
Dump LALR() Compiler's source code...
LR() parsing...
Dump 3_8.State.log
Dump 3_8.Edge.log
Dump LR() Compiler's source code...
Compiling 3_8 of LR() version
Test Code 3_8 of LR() version
Compiling 3_8 of SLR version
Test Code 3_8 of SLR version
Compiling 3_8 of LALR() version
Test Code 3_8 of LALR() version
Compiling 3_8 of LR() version
Test Code 3_8 of LR() version
=====> Processing .\TestCases\Demo.Grammar\Demo.Grammar
Get grammar from source code...
Dump Demo.TokenList.log
Dump Demo.Tree.log
Dump Demo.FormatedGrammar.log
Dump Demo.FIRST.log
Dump Demo.FOLLOW.log
LR() parsing...
Dump Demo.State.log
Dump Demo.Edge.log
Dump LR() Compiler's source code...
【Exists Conflicts in Parsingmap】
SLR parsing...
Dump Demo.State.log
Dump Demo.Edge.log
Dump SLR Compiler's source code...
【Exists Conflicts in Parsingmap】
LALR() parsing...
Dump Demo.State.log
Dump Demo.Edge.log
Dump LALR() Compiler's source code...
【Exists Conflicts in Parsingmap】
LR() parsing...
Dump Demo.State.log
Dump Demo.Edge.log
Dump LR() Compiler's source code...
【Exists Conflicts in Parsingmap】
Compiling Demo of LR() version
Test Code Demo of LR() version
No need to Test Code with conflicts in SyntaxParser
Compiling Demo of SLR version
Test Code Demo of SLR version
No need to Test Code with conflicts in SyntaxParser
Compiling Demo of LALR() version
Test Code Demo of LALR() version
No need to Test Code with conflicts in SyntaxParser
Compiling Demo of LR() version
Test Code Demo of LR() version
No need to Test Code with conflicts in SyntaxParser
=====> Processing .\TestCases\GLSL.Grammar\GLSL.Grammar
Get grammar from source code...
Dump GLSL.TokenList.log
Dump GLSL.Tree.log
Dump GLSL.FormatedGrammar.log
Dump GLSL.FIRST.log
Dump GLSL.FOLLOW.log
LR() parsing...
Test.log
初战GLSL
测试完成后,就可以磨刀霍霍向GLSL文法了。由于GLSL文法比那些测试用的文法规模大的多,最初的版本里,计算过程居然花了好几个小时。最终出现内存不足的Exception,不得不进行优化。
书中给的GLSL文法也是比较奇葩。或许是有什么特别的门道我没有看懂吧。总之要降低难度先。
思路是,把grammar拆分成几个部分,分别处理。
首先是Expression,这是其他部分的基础。Expression部分是符合SLR的,非常好。
然后是statement,statement里有个else悬空的问题,幸好虎书里专门对这个问题做了说明,说可以容忍这个冲突,直接选择Shift,忽略Reduction即可。也非常好。
然后是function_definition,出乎意料的是这部分也是符合SLR的。Nice。
最后是declaration,这里遇到了意想不到的大麻烦。GLSL文法里有个<TYPE_NAME>。这个东西我研究了好久,最后发现他代表的含义竟然是"在读取源代码时动态发现的用户定义的类型"。比如 struct LightInfo{ … } ,他代表的是 LightInfo 这种类型。如果简单的用identifier代替<TYPE_NAME>,文法就会产生无法解决的冲突。
我只好就此打住,先去实现另一种更强的分析方式——同步分析。
同步分析
现在,我的词法分析、语法分析是分开进行的。词法分析全部完成后,才把单词流交给语法分析器进行分析。为了及时识别出用户自定义的类型,这种方式完全不行,必须用"分析一个单词->语法分析->可能的语义分析->分析一个单词"这样的同步分析方式。例如下面的代码:
struct LightInfo {
vec4 Position; // Light position in eyecoords.
vec3 La; // Ambient light intensity
vec3 Ld; // Diffuse light intensity
vec3 Ls; // Specular light intensity
};
uniform LightInfo Light;
在读到第二个单词"LightInfo"后,就必须立即将这个"LightInfo"类型加到用户自定义的类型表里。这样,在继续读到"uniform LightInfo Light"里的"LightInfo"时,词法分析器才会知道"LightInfo"是一个userDefinedType,而不是一个随随便便的identifier。(对照上文的文法的文法,可见为实现一个看似不起眼的userDefinedType需要做多少事)
前端分析器(FrontEndParser)
既然要同步解析了,那么词法分析和语法分析就是结结实实绑在一起的过程,所有用个FrontEndParser封装一下就很有必要。其中的UserDefinedTypeCollection就用来记录用户自定义的类型。
/// <summary>
/// 前端分析器。
/// 词法分析、语法分析、语义动作同步进行。
/// </summary>
public class FrontEndParser
{
private LexicalAnalyzer lexicalAnalyzer;
private LRSyntaxParser syntaxParser; public FrontEndParser(LexicalAnalyzer lexicalAnalyzer, LRSyntaxParser syntaxParser)
{
this.lexicalAnalyzer = lexicalAnalyzer;
this.syntaxParser = syntaxParser;
} /// <summary>
/// 词法分析、语法分析、语义动作同步进行。
/// </summary>
/// <param name="sourceCode"></param>
/// <param name="tokenList"></param>
/// <returns></returns>
public SyntaxTree Parse(string sourceCode, out TokenList tokenList)
{
tokenList = new TokenList();
UserDefinedTypeCollection userDefinedTypeTable = new UserDefinedTypeCollection();
this.lexicalAnalyzer.StartAnalyzing(userDefinedTypeTable);
this.syntaxParser.StartParsing(userDefinedTypeTable);
foreach (var token in this.lexicalAnalyzer.AnalyzeStep(sourceCode))
{
tokenList.Add(token);
this.syntaxParser.ParseStep(token);
} SyntaxTree result = this.syntaxParser.StopParsing();
return result;
}
}
同步词法分析
词法分析器需要每读取一个单词就返回之,等待语法分析、语义分析结束后再继续。C#的 yield return 语法糖真是甜。
public abstract partial class LexicalAnalyzer
{
protected UserDefinedTypeCollection userDefinedTypeTable;
private bool inAnalyzingStep = false; internal void StartAnalyzing(UserDefinedTypeCollection userDefinedTypeTable)
{
if (!inAnalyzingStep)
{
this.userDefinedTypeTable = userDefinedTypeTable;
inAnalyzingStep = true;
}
} internal void StopAnalyzing()
{
if (inAnalyzingStep)
{
this.userDefinedTypeTable = null;
inAnalyzingStep = false;
}
} /// <summary>
/// 每次分析都返回一个<see cref="Token"/>。
/// </summary>
/// <param name="sourceCode"></param>
/// <returns></returns>
internal IEnumerable<Token> AnalyzeStep(string sourceCode)
{
if (!inAnalyzingStep) { throw new Exception("Must invoke this.StartAnalyzing() first!"); } if (!string.IsNullOrEmpty(sourceCode))
{
var context = new AnalyzingContext(sourceCode);
int count = sourceCode.Length; while (context.NextLetterIndex < count)
{
Token token = NextToken(context);
if (token != null)
{
yield return token;
}
}
} this.StopAnalyzing();
}
}
同步词法分析
同步语法/语义分析
每次只获取一个新单词,据此执行可能的分析步骤。如果分析动作还绑定了语义分析(这里是为了找到自定义类型),也执行之。
public abstract partial class LRSyntaxParser
{
bool inParsingStep = false;
ParsingStepContext parsingStepContext; internal void StartParsing(UserDefinedTypeCollection userDefinedTypeTable)
{
if (!inParsingStep)
{
LRParsingMap parsingMap = GetParsingMap();
RegulationList grammar = GetGrammar();
var tokenTypeConvertor = new TokenType2TreeNodeType();
parsingStepContext = new ParsingStepContext(
grammar, parsingMap, tokenTypeConvertor, userDefinedTypeTable);
inParsingStep = true;
}
} internal SyntaxTree StopParsing()
{
SyntaxTree result = null;
if (inParsingStep)
{
result = ParseStep(Token.endOfTokenList);
parsingStepContext.TokenList.RemoveAt(parsingStepContext.TokenList.Count - );
parsingStepContext = null;
inParsingStep = false;
} return result;
}
/// <summary>
/// 获取归约动作对应的语义动作。
/// </summary>
/// <param name="parsingAction"></param>
/// <returns></returns>
protected virtual Action<ParsingStepContext> GetSemanticAction(LRParsingAction parsingAction)
{
return null;
} internal SyntaxTree ParseStep(Token token)
{
if (!inParsingStep) { throw new Exception("Must invoke this.StartParsing() first!"); } parsingStepContext.AddToken(token); while (parsingStepContext.CurrentTokenIndex < parsingStepContext.TokenList.Count)
{
// 语法分析
TreeNodeType nodeType = parsingStepContext.CurrentNodeType();
int stateId = parsingStepContext.StateIdStack.Peek();
LRParsingAction action = parsingStepContext.ParsingMap.GetAction(stateId, nodeType);
int currentTokenIndex = action.Execute(parsingStepContext);
parsingStepContext.CurrentTokenIndex = currentTokenIndex;
// 语义分析
Action<ParsingStepContext> semanticAction = GetSemanticAction(action);
if (semanticAction != null)
{
semanticAction(parsingStepContext);
}
} if (parsingStepContext.TreeStack.Count > )
{
return parsingStepContext.TreeStack.Peek();
}
else
{
return new SyntaxTree();
}
}
}
同步语法/语义分析
再战GLSL
此时武器终于齐备。
文法->解析器
为下面的GLSL文法生成解析器,我的笔记本花费大概10分钟左右。
<translation_unit> ::= <external_declaration> ;
<translation_unit> ::= <translation_unit> <external_declaration> ;
<external_declaration> ::= <function_definition> ;
<external_declaration> ::= <declaration> ;
<function_definition> ::= <function_prototype> <compound_statement_no_new_scope> ;
<variable_identifier> ::= identifier ;
<primary_expression> ::= <variable_identifier> ;
<primary_expression> ::= number ;
<primary_expression> ::= number ;
<primary_expression> ::= number ;
<primary_expression> ::= <BOOLCONSTANT> ;
<primary_expression> ::= number ;
<primary_expression> ::= "(" <expression> ")" ;
<BOOLCONSTANT> ::= "true" ;
<BOOLCONSTANT> ::= "false" ;
<postfix_expression> ::= <primary_expression> ;
<postfix_expression> ::= <postfix_expression> "[" <integer_expression> "]" ;
<postfix_expression> ::= <function_call> ;
<postfix_expression> ::= <postfix_expression> "." <FIELD_SELECTION> ;
<postfix_expression> ::= <postfix_expression> "++" ;
<postfix_expression> ::= <postfix_expression> "--" ;
<FIELD_SELECTION> ::= identifier ;
<integer_expression> ::= <expression> ;
<function_call> ::= <function_call_or_method> ;
<function_call_or_method> ::= <function_call_generic> ;
<function_call_generic> ::= <function_call_header_with_parameters> ")" ;
<function_call_generic> ::= <function_call_header_no_parameters> ")" ;
<function_call_header_no_parameters> ::= <function_call_header> "void" ;
<function_call_header_no_parameters> ::= <function_call_header> ;
<function_call_header_with_parameters> ::= <function_call_header> <assignment_expression> ;
<function_call_header_with_parameters> ::= <function_call_header_with_parameters> "," <assignment_expression> ;
<function_call_header> ::= <function_identifier> "(" ;
<function_identifier> ::= <type_specifier> ;
<function_identifier> ::= <postfix_expression> ;
<unary_expression> ::= <postfix_expression> ;
<unary_expression> ::= "++" <unary_expression> ;
<unary_expression> ::= "--" <unary_expression> ;
<unary_expression> ::= <unary_operator> <unary_expression> ;
<unary_operator> ::= "+" ;
<unary_operator> ::= "-" ;
<unary_operator> ::= "!" ;
<unary_operator> ::= "~" ;
<multiplicative_expression> ::= <unary_expression> ;
<multiplicative_expression> ::= <multiplicative_expression> "*" <unary_expression> ;
<multiplicative_expression> ::= <multiplicative_expression> "/" <unary_expression> ;
<multiplicative_expression> ::= <multiplicative_expression> "%" <unary_expression> ;
<additive_expression> ::= <multiplicative_expression> ;
<additive_expression> ::= <additive_expression> "+" <multiplicative_expression> ;
<additive_expression> ::= <additive_expression> "-" <multiplicative_expression> ;
<shift_expression> ::= <additive_expression> ;
<shift_expression> ::= <shift_expression> "<<" <additive_expression> ;
<shift_expression> ::= <shift_expression> ">>" <additive_expression> ;
<relational_expression> ::= <shift_expression> ;
<relational_expression> ::= <relational_expression> "<" <shift_expression> ;
<relational_expression> ::= <relational_expression> ">" <shift_expression> ;
<relational_expression> ::= <relational_expression> "<=" <shift_expression> ;
<relational_expression> ::= <relational_expression> ">=" <shift_expression> ;
<equality_expression> ::= <relational_expression> ;
<equality_expression> ::= <equality_expression> "==" <relational_expression> ;
<equality_expression> ::= <equality_expression> "!=" <relational_expression> ;
<and_expression> ::= <equality_expression> ;
<and_expression> ::= <and_expression> "&" <equality_expression> ;
<exclusive_or_expression> ::= <and_expression> ;
<exclusive_or_expression> ::= <exclusive_or_expression> "^" <and_expression> ;
<inclusive_or_expression> ::= <exclusive_or_expression> ;
<inclusive_or_expression> ::= <inclusive_or_expression> "|" <exclusive_or_expression> ;
<logical_and_expression> ::= <inclusive_or_expression> ;
<logical_and_expression> ::= <logical_and_expression> "&&" <inclusive_or_expression> ;
<logical_xor_expression> ::= <logical_and_expression> ;
<logical_xor_expression> ::= <logical_xor_expression> "^^" <logical_and_expression> ;
<logical_or_expression> ::= <logical_xor_expression> ;
<logical_or_expression> ::= <logical_or_expression> "||" <logical_xor_expression> ;
<conditional_expression> ::= <logical_or_expression> ;
<conditional_expression> ::= <logical_or_expression> "?" <expression> ":" <assignment_expression> ;
<assignment_expression> ::= <conditional_expression> ;
<assignment_expression> ::= <unary_expression> <assignment_operator> <assignment_expression> ;
<assignment_operator> ::= "=" ;
<assignment_operator> ::= "*=" ;
<assignment_operator> ::= "/=" ;
<assignment_operator> ::= "%=" ;
<assignment_operator> ::= "+=" ;
<assignment_operator> ::= "-=" ;
<assignment_operator> ::= "<<=" ;
<assignment_operator> ::= ">>=" ;
<assignment_operator> ::= "&=" ;
<assignment_operator> ::= "^=" ;
<assignment_operator> ::= "|=" ;
<expression> ::= <assignment_expression> ;
<expression> ::= <expression> "," <assignment_expression> ;
<constant_expression> ::= <conditional_expression> ;
<declaration> ::= <function_prototype> ";" ;
<declaration> ::= <init_declarator_list> ";" ;
<declaration> ::= "precision" <precision_qualifier> <type_specifier> ";" ;
<declaration> ::= <type_qualifier> identifier "{" <struct_declaration_list> "}" ";" ;
<declaration> ::= <type_qualifier> identifier "{" <struct_declaration_list> "}" identifier ";" ;
<declaration> ::= <type_qualifier> identifier "{" <struct_declaration_list> "}" identifier <array_specifier> ";" ;
<declaration> ::= <type_qualifier> ";" ;
<declaration> ::= <type_qualifier> identifier ";" ;
<declaration> ::= <type_qualifier> identifier <identifier_list> ";" ;
<identifier_list> ::= "," identifier ;
<identifier_list> ::= <identifier_list> "," identifier ;
<function_prototype> ::= <function_declarator> ")" ;
<function_declarator> ::= <function_header> ;
<function_declarator> ::= <function_header_with_parameters> ;
<function_header_with_parameters> ::= <function_header> <parameter_declaration> ;
<function_header_with_parameters> ::= <function_header_with_parameters> "," <parameter_declaration> ;
<function_header> ::= <fully_specified_type> identifier "(" ;
<parameter_declarator> ::= <type_specifier> identifier ;
<parameter_declarator> ::= <type_specifier> identifier <array_specifier> ;
<parameter_declaration> ::= <type_qualifier> <parameter_declarator> ;
<parameter_declaration> ::= <parameter_declarator> ;
<parameter_declaration> ::= <type_qualifier> <parameter_type_specifier> ;
<parameter_declaration> ::= <parameter_type_specifier> ;
<parameter_type_specifier> ::= <type_specifier> ;
<init_declarator_list> ::= <single_declaration> ;
<init_declarator_list> ::= <init_declarator_list> "," identifier ;
<init_declarator_list> ::= <init_declarator_list> "," identifier <array_specifier> ;
<init_declarator_list> ::= <init_declarator_list> "," identifier <array_specifier> "=" <initializer> ;
<init_declarator_list> ::= <init_declarator_list> "," identifier "=" <initializer> ;
<single_declaration> ::= <fully_specified_type> ;
<single_declaration> ::= <fully_specified_type> identifier ;
<single_declaration> ::= <fully_specified_type> identifier <array_specifier> ;
<single_declaration> ::= <fully_specified_type> identifier <array_specifier> "=" <initializer> ;
<single_declaration> ::= <fully_specified_type> identifier "=" <initializer> ;
<fully_specified_type> ::= <type_specifier> ;
<fully_specified_type> ::= <type_qualifier> <type_specifier> ;
<invariant_qualifier> ::= "invariant" ;
<interpolation_qualifier> ::= "smooth" ;
<interpolation_qualifier> ::= "flat" ;
<interpolation_qualifier> ::= "noperspective" ;
<layout_qualifier> ::= "layout" "(" <layout_qualifier_id_list> ")" ;
<layout_qualifier_id_list> ::= <layout_qualifier_id> ;
<layout_qualifier_id_list> ::= <layout_qualifier_id_list> "," <layout_qualifier_id> ;
<layout_qualifier_id> ::= identifier ;
<layout_qualifier_id> ::= identifier "=" number ;
<precise_qualifier> ::= "precise" ;
<type_qualifier> ::= <single_type_qualifier> ;
<type_qualifier> ::= <type_qualifier> <single_type_qualifier> ;
<single_type_qualifier> ::= <storage_qualifier> ;
<single_type_qualifier> ::= <layout_qualifier> ;
<single_type_qualifier> ::= <precision_qualifier> ;
<single_type_qualifier> ::= <interpolation_qualifier> ;
<single_type_qualifier> ::= <invariant_qualifier> ;
<single_type_qualifier> ::= <precise_qualifier> ;
<storage_qualifier> ::= "const" ;
<storage_qualifier> ::= "inout" ;
<storage_qualifier> ::= "in" ;
<storage_qualifier> ::= "out" ;
<storage_qualifier> ::= "centroid" ;
<storage_qualifier> ::= "patch" ;
<storage_qualifier> ::= "sample" ;
<storage_qualifier> ::= "uniform" ;
<storage_qualifier> ::= "buffer" ;
<storage_qualifier> ::= "shared" ;
<storage_qualifier> ::= "coherent" ;
<storage_qualifier> ::= "volatile" ;
<storage_qualifier> ::= "restrict" ;
<storage_qualifier> ::= "readonly" ;
<storage_qualifier> ::= "writeonly" ;
<storage_qualifier> ::= "subroutine" ;
<storage_qualifier> ::= "subroutine" "(" <type_name_list> ")" ;
<type_name_list> ::= userDefinedType ;
<type_name_list> ::= <type_name_list> "," userDefinedType ;
<type_specifier> ::= <type_specifier_nonarray> ;
<type_specifier> ::= <type_specifier_nonarray> <array_specifier> ;
<array_specifier> ::= "[" "]" ;
<array_specifier> ::= "[" <constant_expression> "]" ;
<array_specifier> ::= <array_specifier> "[" "]" ;
<array_specifier> ::= <array_specifier> "[" <constant_expression> "]" ;
<type_specifier_nonarray> ::= "void" ;
<type_specifier_nonarray> ::= "float" ;
<type_specifier_nonarray> ::= "double" ;
<type_specifier_nonarray> ::= "int" ;
<type_specifier_nonarray> ::= "uint" ;
<type_specifier_nonarray> ::= "bool" ;
<type_specifier_nonarray> ::= "vec2" ;
<type_specifier_nonarray> ::= "vec3" ;
<type_specifier_nonarray> ::= "vec4" ;
<type_specifier_nonarray> ::= "dvec2" ;
<type_specifier_nonarray> ::= "dvec3" ;
<type_specifier_nonarray> ::= "dvec4" ;
<type_specifier_nonarray> ::= "bvec2" ;
<type_specifier_nonarray> ::= "bvec3" ;
<type_specifier_nonarray> ::= "bvec4" ;
<type_specifier_nonarray> ::= "ivec2" ;
<type_specifier_nonarray> ::= "ivec3" ;
<type_specifier_nonarray> ::= "ivec4" ;
<type_specifier_nonarray> ::= "uvec2" ;
<type_specifier_nonarray> ::= "uvec3" ;
<type_specifier_nonarray> ::= "uvec4" ;
<type_specifier_nonarray> ::= "mat2" ;
<type_specifier_nonarray> ::= "mat3" ;
<type_specifier_nonarray> ::= "mat4" ;
<type_specifier_nonarray> ::= "mat2x2" ;
<type_specifier_nonarray> ::= "mat2x3" ;
<type_specifier_nonarray> ::= "mat2x4" ;
<type_specifier_nonarray> ::= "mat3x2" ;
<type_specifier_nonarray> ::= "mat3x3" ;
<type_specifier_nonarray> ::= "mat3x4" ;
<type_specifier_nonarray> ::= "mat4x2" ;
<type_specifier_nonarray> ::= "mat4x3" ;
<type_specifier_nonarray> ::= "mat4x4" ;
<type_specifier_nonarray> ::= "dmat2" ;
<type_specifier_nonarray> ::= "dmat3" ;
<type_specifier_nonarray> ::= "dmat4" ;
<type_specifier_nonarray> ::= "dmat2x2" ;
<type_specifier_nonarray> ::= "dmat2x3" ;
<type_specifier_nonarray> ::= "dmat2x4" ;
<type_specifier_nonarray> ::= "dmat3x2" ;
<type_specifier_nonarray> ::= "dmat3x3" ;
<type_specifier_nonarray> ::= "dmat3x4" ;
<type_specifier_nonarray> ::= "dmat4x2" ;
<type_specifier_nonarray> ::= "dmat4x3" ;
<type_specifier_nonarray> ::= "dmat4x4" ;
<type_specifier_nonarray> ::= "atomic_uint" ;
<type_specifier_nonarray> ::= "sampler1D" ;
<type_specifier_nonarray> ::= "sampler2D" ;
<type_specifier_nonarray> ::= "sampler3D" ;
<type_specifier_nonarray> ::= "samplerCube" ;
<type_specifier_nonarray> ::= "sampler1DShadow" ;
<type_specifier_nonarray> ::= "sampler2DShadow" ;
<type_specifier_nonarray> ::= "samplerCubeShadow" ;
<type_specifier_nonarray> ::= "sampler1DArray" ;
<type_specifier_nonarray> ::= "sampler2DArray" ;
<type_specifier_nonarray> ::= "sampler1DArrayShadow" ;
<type_specifier_nonarray> ::= "sampler2DArrayShadow" ;
<type_specifier_nonarray> ::= "samplerCubeArray" ;
<type_specifier_nonarray> ::= "samplerCubeArrayShadow" ;
<type_specifier_nonarray> ::= "isampler1D" ;
<type_specifier_nonarray> ::= "isampler2D" ;
<type_specifier_nonarray> ::= "isampler3D" ;
<type_specifier_nonarray> ::= "isamplerCube" ;
<type_specifier_nonarray> ::= "isampler1DArray" ;
<type_specifier_nonarray> ::= "isampler2DArray" ;
<type_specifier_nonarray> ::= "isamplerCubeArray" ;
<type_specifier_nonarray> ::= "usampler1D" ;
<type_specifier_nonarray> ::= "usampler2D" ;
<type_specifier_nonarray> ::= "usampler3D" ;
<type_specifier_nonarray> ::= "usamplerCube" ;
<type_specifier_nonarray> ::= "usampler1DArray" ;
<type_specifier_nonarray> ::= "usampler2DArray" ;
<type_specifier_nonarray> ::= "usamplerCubeArray" ;
<type_specifier_nonarray> ::= "sampler2DRect" ;
<type_specifier_nonarray> ::= "sampler2DRectShadow" ;
<type_specifier_nonarray> ::= "isampler2DRect" ;
<type_specifier_nonarray> ::= "usampler2DRect" ;
<type_specifier_nonarray> ::= "samplerBuffer" ;
<type_specifier_nonarray> ::= "isamplerBuffer" ;
<type_specifier_nonarray> ::= "usamplerBuffer" ;
<type_specifier_nonarray> ::= "sampler2DMS" ;
<type_specifier_nonarray> ::= "isampler2DMS" ;
<type_specifier_nonarray> ::= "usampler2DMS" ;
<type_specifier_nonarray> ::= "sampler2DMSArray" ;
<type_specifier_nonarray> ::= "isampler2DMSArray" ;
<type_specifier_nonarray> ::= "usampler2DMSArray" ;
<type_specifier_nonarray> ::= "image1D" ;
<type_specifier_nonarray> ::= "iimage1D" ;
<type_specifier_nonarray> ::= "uimage1D" ;
<type_specifier_nonarray> ::= "image2D" ;
<type_specifier_nonarray> ::= "iimage2D" ;
<type_specifier_nonarray> ::= "uimage2D" ;
<type_specifier_nonarray> ::= "image3D" ;
<type_specifier_nonarray> ::= "iimage3D" ;
<type_specifier_nonarray> ::= "uimage3D" ;
<type_specifier_nonarray> ::= "image2DRect" ;
<type_specifier_nonarray> ::= "iimage2DRect" ;
<type_specifier_nonarray> ::= "uimage2DRect" ;
<type_specifier_nonarray> ::= "imageCube" ;
<type_specifier_nonarray> ::= "iimageCube" ;
<type_specifier_nonarray> ::= "uimageCube" ;
<type_specifier_nonarray> ::= "imageBuffer" ;
<type_specifier_nonarray> ::= "iimageBuffer" ;
<type_specifier_nonarray> ::= "uimageBuffer" ;
<type_specifier_nonarray> ::= "image1DArray" ;
<type_specifier_nonarray> ::= "iimage1DArray" ;
<type_specifier_nonarray> ::= "uimage1DArray" ;
<type_specifier_nonarray> ::= "image2DArray" ;
<type_specifier_nonarray> ::= "iimage2DArray" ;
<type_specifier_nonarray> ::= "uimage2DArray" ;
<type_specifier_nonarray> ::= "imageCubeArray" ;
<type_specifier_nonarray> ::= "iimageCubeArray" ;
<type_specifier_nonarray> ::= "uimageCubeArray" ;
<type_specifier_nonarray> ::= "image2DMS" ;
<type_specifier_nonarray> ::= "iimage2DMS" ;
<type_specifier_nonarray> ::= "uimage2DMS" ;
<type_specifier_nonarray> ::= "image2DMSArray" ;
<type_specifier_nonarray> ::= "iimage2DMSArray" ;
<type_specifier_nonarray> ::= "uimage2DMSArray" ;
<type_specifier_nonarray> ::= <struct_specifier> ;
<type_specifier_nonarray> ::= userDefinedType ;
<precision_qualifier> ::= "high_precision" ;
<precision_qualifier> ::= "medium_precision" ;
<precision_qualifier> ::= "low_precision" ;
// semantic parsing needed
<struct_specifier> ::= "struct" identifier "{" <struct_declaration_list> "}" ;
<struct_specifier> ::= "struct" "{" <struct_declaration_list> "}" ;
<struct_declaration_list> ::= <struct_declaration> ;
<struct_declaration_list> ::= <struct_declaration_list> <struct_declaration> ;
<struct_declaration> ::= <type_specifier> <struct_declarator_list> ";" ;
<struct_declaration> ::= <type_qualifier> <type_specifier> <struct_declarator_list> ";" ;
<struct_declarator_list> ::= <struct_declarator> ;
<struct_declarator_list> ::= <struct_declarator_list> "," <struct_declarator> ;
<struct_declarator> ::= identifier ;
<struct_declarator> ::= identifier <array_specifier> ;
<initializer> ::= <assignment_expression> ;
<initializer> ::= "{" <initializer_list> "}" ;
<initializer> ::= "{" <initializer_list> "," "}" ;
<initializer_list> ::= <initializer> ;
<initializer_list> ::= <initializer_list> "," <initializer> ;
<declaration_statement> ::= <declaration> ;
<statement> ::= <compound_statement> ;
<statement> ::= <simple_statement> ;
<simple_statement> ::= <declaration_statement> ;
<simple_statement> ::= <expression_statement> ;
<simple_statement> ::= <selection_statement> ;
<simple_statement> ::= <switch_statement> ;
<simple_statement> ::= <case_label> ;
<simple_statement> ::= <iteration_statement> ;
<simple_statement> ::= <jump_statement> ;
<compound_statement> ::= "{" "}" ;
<compound_statement> ::= "{" <statement_list> "}" ;
<statement_no_new_scope> ::= <compound_statement_no_new_scope> ;
<statement_no_new_scope> ::= <simple_statement> ;
<compound_statement_no_new_scope> ::= "{" "}" ;
<compound_statement_no_new_scope> ::= "{" <statement_list> "}" ;
<statement_list> ::= <statement> ;
<statement_list> ::= <statement_list> <statement> ;
<expression_statement> ::= ";" ;
<expression_statement> ::= <expression> ";" ;
<selection_statement> ::= "if" "(" <expression> ")" <selection_rest_statement> ;
<selection_rest_statement> ::= <statement> "else" <statement> ;
<selection_rest_statement> ::= <statement> ;
<condition> ::= <expression> ;
<condition> ::= <fully_specified_type> identifier "=" <initializer> ;
<switch_statement> ::= "switch" "(" <expression> ")" "{" <switch_statement_list> "}" ;
<switch_statement_list> ::= <statement_list> ;
<case_label> ::= "case" <expression> ":" ;
<case_label> ::= "default" ":" ;
<iteration_statement> ::= "while" "(" <condition> ")" <statement_no_new_scope> ;
<iteration_statement> ::= "do" <statement> "while" "(" <expression> ")" ";" ;
<iteration_statement> ::= "for" "(" <for_init_statement> <for_rest_statement> ")" <statement_no_new_scope> ;
<for_init_statement> ::= <expression_statement> ;
<for_init_statement> ::= <declaration_statement> ;
<conditionopt> ::= <condition> ;
<for_rest_statement> ::= <conditionopt> ";" ;
<for_rest_statement> ::= <conditionopt> ";" <expression> ;
<jump_statement> ::= "continue" ";" ;
<jump_statement> ::= "break" ";" ;
<jump_statement> ::= "return" ";" ;
<jump_statement> ::= "return" <expression> ";" ;
<jump_statement> ::= "discard" ";" ;
GLSL.Grammar
补充语义分析片段
语义分析是不能自动生成的。此时需要的语义分析,只有找到自定义类型这一个目的。
在GLSL文法里,是下面这个state需要进行语义分析。此时,分析器刚刚读到用户自定义的类型名字(identifier)。
State [172]:
<struct_specifier> ::= "struct" identifier . "{" <struct_declaration_list> "}" ;, identifier "," ")" "(" ";" "["
语义分析动作内容则十分简单,将identifier的内容作为自定义类型名加入UserDefinedTypeTable即可。
// State [172]:
// <struct_specifier> ::= "struct" identifier . "{" <struct_declaration_list> "}" ;, identifier "," ")" "(" ";" "["
static void state172_struct_specifier(ParsingStepContext context)
{
SyntaxTree tree = context.TreeStack.Peek();
string name = tree.NodeType.Content;
context.UserDefinedTypeTable.TryInsert(new UserDefinedType(name));
}
当然,别忘了在初始化时将此动作绑定到对应的state上。
static GLSLSyntaxParser()
{
// 将语义动作绑定的到state上。
dict.Add(new LR1ShiftInAction(), state172_struct_specifier);
}
static Dictionary<LRParsingAction, Action<ParsingStepContext>> dict =
new Dictionary<LRParsingAction, Action<ParsingStepContext>>(); protected override Action<ParsingStepContext> GetSemanticAction(LRParsingAction parsingAction)
{
Action<ParsingStepContext> semanticAction = null;
if (dict.TryGetValue(parsingAction, out semanticAction))
{
return semanticAction;
}
else
{
return null;
}
}
userDefinedType
下面是上文的LightInfo代码片段的词法分析结果。请注意在定义LightInfo时,他是个identifier,定义之后,就是一个userDefinedType类型的单词了。
TokenList[Count: ]
[[struct](__struct)[struct]]$[Ln:, Col:]
[[LightInfo](identifier)[LightInfo]]$[Ln:1, Col:8]
[[{](__left_brace)["{"]]$[Ln:, Col:]
[[vec4](__vec4)[vec4]]$[Ln:, Col:]
[[Position](identifier)[Position]]$[Ln:, Col:]
[[;](__semicolon)[";"]]$[Ln:, Col:]
[[vec3](__vec3)[vec3]]$[Ln:, Col:]
[[La](identifier)[La]]$[Ln:, Col:]
[[;](__semicolon)[";"]]$[Ln:, Col:]
[[vec3](__vec3)[vec3]]$[Ln:, Col:]
[[Ld](identifier)[Ld]]$[Ln:, Col:]
[[;](__semicolon)[";"]]$[Ln:, Col:]
[[vec3](__vec3)[vec3]]$[Ln:, Col:]
[[Ls](identifier)[Ls]]$[Ln:, Col:]
[[;](__semicolon)[";"]]$[Ln:, Col:]
[[}](__right_brace)["}"]]$[Ln:, Col:]
[[;](__semicolon)[";"]]$[Ln:, Col:]
[[uniform](__uniform)[uniform]]$[Ln:, Col:]
[[LightInfo](__userDefinedType)[LightInfo]]$[Ln:7, Col:9]
[[Light](identifier)[Light]]$[Ln:, Col:]
[[;](__semicolon)[";"]]$[Ln:, Col:]
下面是LightInfo片段的语法树。你可以看到单词的类型对照着叶结点的类型。
(__translation_unit)[<translation_unit>][translation_unit]
├─(__translation_unit)[<translation_unit>][translation_unit]
│ └─(__external_declaration)[<external_declaration>][external_declaration]
│ └─(__declaration)[<declaration>][declaration]
│ ├─(__init_declarator_list)[<init_declarator_list>][init_declarator_list]
│ │ └─(__single_declaration)[<single_declaration>][single_declaration]
│ │ └─(__fully_specified_type)[<fully_specified_type>][fully_specified_type]
│ │ └─(__type_specifier)[<type_specifier>][type_specifier]
│ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
│ │ └─(__struct_specifier)[<struct_specifier>][struct_specifier]
│ │ ├─(__structLeave__)[struct][struct]
│ │ ├─(identifierLeave__)[LightInfo][LightInfo]
│ │ ├─(__left_braceLeave__)["{"][{]
│ │ ├─(__struct_declaration_list)[<struct_declaration_list>][struct_declaration_list]
│ │ │ ├─(__struct_declaration_list)[<struct_declaration_list>][struct_declaration_list]
│ │ │ │ ├─(__struct_declaration_list)[<struct_declaration_list>][struct_declaration_list]
│ │ │ │ │ ├─(__struct_declaration_list)[<struct_declaration_list>][struct_declaration_list]
│ │ │ │ │ │ └─(__struct_declaration)[<struct_declaration>][struct_declaration]
│ │ │ │ │ │ ├─(__type_specifier)[<type_specifier>][type_specifier]
│ │ │ │ │ │ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
│ │ │ │ │ │ │ └─(__vec4Leave__)[vec4][vec4]
│ │ │ │ │ │ ├─(__struct_declarator_list)[<struct_declarator_list>][struct_declarator_list]
│ │ │ │ │ │ │ └─(__struct_declarator)[<struct_declarator>][struct_declarator]
│ │ │ │ │ │ │ └─(identifierLeave__)[Position][Position]
│ │ │ │ │ │ └─(__semicolonLeave__)[";"][;]
│ │ │ │ │ └─(__struct_declaration)[<struct_declaration>][struct_declaration]
│ │ │ │ │ ├─(__type_specifier)[<type_specifier>][type_specifier]
│ │ │ │ │ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
│ │ │ │ │ │ └─(__vec3Leave__)[vec3][vec3]
│ │ │ │ │ ├─(__struct_declarator_list)[<struct_declarator_list>][struct_declarator_list]
│ │ │ │ │ │ └─(__struct_declarator)[<struct_declarator>][struct_declarator]
│ │ │ │ │ │ └─(identifierLeave__)[La][La]
│ │ │ │ │ └─(__semicolonLeave__)[";"][;]
│ │ │ │ └─(__struct_declaration)[<struct_declaration>][struct_declaration]
│ │ │ │ ├─(__type_specifier)[<type_specifier>][type_specifier]
│ │ │ │ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
│ │ │ │ │ └─(__vec3Leave__)[vec3][vec3]
│ │ │ │ ├─(__struct_declarator_list)[<struct_declarator_list>][struct_declarator_list]
│ │ │ │ │ └─(__struct_declarator)[<struct_declarator>][struct_declarator]
│ │ │ │ │ └─(identifierLeave__)[Ld][Ld]
│ │ │ │ └─(__semicolonLeave__)[";"][;]
│ │ │ └─(__struct_declaration)[<struct_declaration>][struct_declaration]
│ │ │ ├─(__type_specifier)[<type_specifier>][type_specifier]
│ │ │ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
│ │ │ │ └─(__vec3Leave__)[vec3][vec3]
│ │ │ ├─(__struct_declarator_list)[<struct_declarator_list>][struct_declarator_list]
│ │ │ │ └─(__struct_declarator)[<struct_declarator>][struct_declarator]
│ │ │ │ └─(identifierLeave__)[Ls][Ls]
│ │ │ └─(__semicolonLeave__)[";"][;]
│ │ └─(__right_braceLeave__)["}"][}]
│ └─(__semicolonLeave__)[";"][;]
└─(__external_declaration)[<external_declaration>][external_declaration]
└─(__declaration)[<declaration>][declaration]
├─(__init_declarator_list)[<init_declarator_list>][init_declarator_list]
│ └─(__single_declaration)[<single_declaration>][single_declaration]
│ ├─(__fully_specified_type)[<fully_specified_type>][fully_specified_type]
│ │ ├─(__type_qualifier)[<type_qualifier>][type_qualifier]
│ │ │ └─(__single_type_qualifier)[<single_type_qualifier>][single_type_qualifier]
│ │ │ └─(__storage_qualifier)[<storage_qualifier>][storage_qualifier]
│ │ │ └─(__uniformLeave__)[uniform][uniform]
│ │ └─(__type_specifier)[<type_specifier>][type_specifier]
│ │ └─(__type_specifier_nonarray)[<type_specifier_nonarray>][type_specifier_nonarray]
│ │ └─(__userDefinedTypeLeave__)[LightInfo][LightInfo]
│ └─(identifierLeave__)[Light][Light]
└─(__semicolonLeave__)[";"][;]
SyntaxTree
再加上其他的测试用例,这个GLSL解析器终于实现了。
最终目的
解析GLSL源代码,是为了获取其中的信息(都有哪些in/out/uniform等)。现在语法树已经有了,剩下的就是遍历此树的事了。不再详述。
故事
故事,其实是事故。由于心急,此项目第一次实现时出现了几乎无法fix的bug。于是重写了一遍,这次一步一步走,终于成功了。
LALR(1)State
LALR(1)State集合在尝试插入一个新的State时,如果已有在LALR(1)意义上"相等"的状态,仍旧要尝试将新state的LookAhead列表插入已有状态。
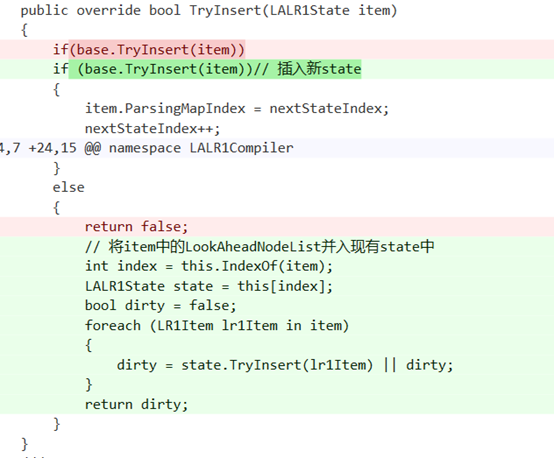
否则,下面的例子就显示了文法3-8在忽视了这一点时的state集合与正确的state集合的差别(少了一些LookAhead项)。
State []:
<S> ::= . "(" <L> ")" ;, "$"
<S'> ::= . <S> "$" ;, "$"
<S> ::= . "x" ;, "$"
State []:
<S> ::= "(" <L> ")" . ;, "$"
State []:
<S> ::= "x" . ;, "$"
State []:
<L> ::= <S> . ;, ","")"
State []:
<L> ::= <L> "," <S> . ;, ","")"
State []:
<L> ::= <L> . "," <S> ;, ","")"
<S> ::= "(" <L> . ")" ;, "$"
State []:
<S> ::= . "(" <L> ")" ;, ","")"
<S> ::= . "x" ;, ","")"
<L> ::= <L> "," . <S> ;, ","")"
State []:
<S> ::= . "(" <L> ")" ;, ","")"
<S> ::= . "x" ;, ","")"
<S> ::= "(" . <L> ")" ;, "$"
<L> ::= . <L> "," <S> ;, ","")"
<L> ::= . <S> ;, ","")"
State []:
<S'> ::= <S> . "$" ;, "$"
少LookAhead项的
State []:
<S> ::= . "(" <L> ")" ;, "$"
<S'> ::= . <S> "$" ;, "$"
<S> ::= . "x" ;, "$"
State []:
<S> ::= "(" <L> ")" . ;, "$"","")"
State []:
<S> ::= "x" . ;, "$"","")"
State []:
<L> ::= <S> . ;, ","")"
State []:
<L> ::= <L> "," <S> . ;, ","")"
State []:
<L> ::= <L> . "," <S> ;, ","")"
<S> ::= "(" <L> . ")" ;, "$"","")"
State []:
<S> ::= . "(" <L> ")" ;, ","")"
<S> ::= . "x" ;, ","")"
<L> ::= <L> "," . <S> ;, ","")"
State []:
<S> ::= . "(" <L> ")" ;, ","")"
<S> ::= . "x" ;, ","")"
<S> ::= "(" . <L> ")" ;, "$"","")"
<L> ::= . <L> "," <S> ;, ","")"
<L> ::= . <S> ;, ","")"
State []:
<S'> ::= <S> . "$" ;, "$"
正确的
CodeDom
CodeDom不支持readonly属性,实在是遗憾。CodeDom还会对以"__"开头的变量自动添加个@前缀,真是无语。
// private static TreeNodeType NODE__Grammar = new TreeNodeType(ContextfreeGrammarSLRTreeNodeType.NODE__Grammar, "Grammar", "<Grammar>");
CodeMemberField field = new CodeMemberField(typeof(TreeNodeType), GetNodeNameInParser(node));
// field.Attributes 不支持readonly,遗憾了。
field.Attributes = MemberAttributes.Private | MemberAttributes.Static;
var ctor = new CodeObjectCreateExpression(typeof(TreeNodeType),
new CodeFieldReferenceExpression(
new CodeTypeReferenceExpression(GetTreeNodeConstTypeName(grammarId, algorithm)),
GetNodeNameInParser(node)),
new CodePrimitiveExpression(node.Content),
new CodePrimitiveExpression(node.Nickname));
field.InitExpression = ctor;
复杂的词法分析器
从算法上说,理解语法分析器要比较理解词法分析器困难的多。但是LR语法分析器的结构却比词法分析器的结构和LL语法分析器的结果简单得多。目前实现dump词法分析器代码的代码是最绕的。要处理注释(//和/**/)是其中最复杂的问题。这段代码写好了我再也不想动了。
LL和LR
LR分析法确实比LL强太多。其适用各种现今的程序语言,对文法的限制极少,分析器结构还十分简单。奇妙的是,稍微改动下文法,就可以减少LR分析的state,精简代码。
例如ContextfreeGrammarCompiler的文法,稍微改改会有不同的state数目。
====================================================================
set action items
<Grammar> ::= <ProductionList> <Production> ;
<ProductionList> ::= <ProductionList> <Production> | null ;
<Production> ::= <Vn> "::=" <Canditate> <RightPartList> ";" ;
<Canditate> ::= <V> <VList> ;
<VList> ::= <V> <VList> | null ;
<RightPartList> ::= "|" <Canditate> <RightPartList> | null ;
<V> ::= <Vn> | <Vt> ;
<Vn> ::= "<" identifier ">" ;
<Vt> ::= "null" | "identifier" | "number" | "constString" | constString ;
====================================================================
set action items
<Grammar> ::= <Production> <ProductionList> ;
<ProductionList> ::= <Production> <ProductionList> | null ;
<Production> ::= <Vn> "::=" <Canditate> <RightPartList> ";" ;
<Canditate> ::= <V> <VList> ;
<VList> ::= <V> <VList> | null ;
<RightPartList> ::= "|" <Canditate> <RightPartList> | null ;
<V> ::= <Vn> | <Vt> ;
<Vn> ::= "<" identifier ">" ;
<Vt> ::= "null" | "identifier" | "number" | "constString" | constString ;
====================================================================
set action items
<Grammar> ::= <ProductionList> <Production> ;
<ProductionList> ::= <ProductionList> <Production> | null ;
<Production> ::= <Vn> "::=" <LeftPartList> <Canditate> ";" ;
<LeftPartList> ::= <LeftPartList> <LeftPart> | null ;
<LeftPart> ::= <Canditate> "|" ;
<Canditate> ::= <V> <VList> ;
<VList> ::= <V> <VList> | null ;
<V> ::= <Vn> | <Vt> ;
<Vn> ::= "<" identifier ">" ;
<Vt> ::= "null" | "identifier" | "number" | "constString" | constString ;
====================================================================
set action items
<Grammar> ::= <ProductionList> <Production> ;
<ProductionList> ::= <ProductionList> <Production> | null ;
<Production> ::= <Vn> "::=" <Canditate> <RightPartList> ";" ;
<Canditate> ::= <VList> <V> ;
<VList> ::= <VList> <V> | null ;
<RightPartList> ::= "|" <Canditate> <RightPartList> | null ;
<V> ::= <Vn> | <Vt> ;
<Vn> ::= "<" identifier ">" ;
<Vt> ::= "null" | "identifier" | "number" | "constString" | constString ;
ContextfreeGrammars
总结
实现了LALR(1)分析和GLSL解析器。
今后做任何语言、格式的解析都不用愁了。
基于虎书实现LALR(1)分析并生成GLSL编译器前端代码(C#)的更多相关文章
- 实战录 | 基于openflow协议的抓包分析
<实战录>导语 云端卫士<实战录>栏目定期会向粉丝朋友们分享一些在开发运维中的经验和技巧,希望对于关注我们的朋友有所裨益.本期分享人为云端卫士安全SDN工程师宋飞虎,将带来基于 ...
- 龙书(Dragon book) +鲸书(Whale book)+虎书(Tiger book)
1.龙书(Dragon book)书名是Compilers: Principles,Techniques,and Tools作者是:Alfred V.Aho,Ravi Sethi,Jeffrey D. ...
- 基于byte[]的HTTP协议头分析代码
smark 专注于高并发网络和大型网站架规划设计,提供.NET平台下高吞吐的网络通讯应用技术咨询和支持 基于byte[]的HTTP协议头分析代码 最近需要为组件实现一个HTTP的扩展包,所以简单地实现 ...
- 语法设计——基于LL(1)文法的预测分析表法
实验二.语法设计--基于LL(1)文法的预测分析表法 一.实验目的 通过实验教学,加深学生对所学的关于编译的理论知识的理解,增强学生对所学知识的综合应用能力,并通过实践达到对所学的知识进行验证.通过对 ...
- 基于335X的UBOOT网口驱动分析
基于335X的UBOOT网口驱动分析 一.软硬件平台资料 1. 开发板:创龙AM3359核心板,网口采用RMII形式 2. UBOOT版本:U-Boot-2016.05,采用FDT和DM. 参考链 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- 分享一个基于小米 soar 的开源 sql 分析与优化的 WEB 图形化工具
soar-web 基于小米 soar 的开源 sql 分析与优化的 WEB 图形化工具,支持 soar 配置的添加.修改.复制,多配置切换,配置的导出.导入与导入功能. 环境需求 python3.xF ...
- 基于UML的毕业设计管理系统的分析与设计
基于UML的毕业设计管理系统的分析与设计 <本段与标题无关,自行略过 最近各种忙,天气不错,导师心情不错:“我们要写一个关于UML的专著”,一句话:“一个完整的系统贯穿整个UML的知识”:我:“ ...
- (4.2)基于LingPipe的文本基本极性分析【demo】
酒店评论情感分析系统(四)—— 基于LingPipe的文本基本极性分析[demo] (Positive (favorable) vs. Negative (unfavorable)) 这篇文章为Lin ...
随机推荐
- 简谈百度坐标反转至WGS84的三种思路
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 基于百度地图进行数据展示是目前项目中常见场景,但是因为百度地图 ...
- PHP源码分析-变量
1. 变量的三要素变量名称,变量类型,变量值 那么在PHP用户态下变量类型都有哪些,如下: // Zend/zend.h #define IS_NULL 0 #define IS_LONG 1 #de ...
- 【转】为什么我们都理解错了HTTP中GET与POST的区别
GET和POST是HTTP请求的两种基本方法,要说它们的区别,接触过WEB开发的人都能说出一二. 最直观的区别就是GET把参数包含在URL中,POST通过request body传递参数. 你可能自己 ...
- Android手机相册的布局
实现类似下面的这种布局的方法
- Android之SAX解析XML
一.SAX解析方法介绍 SAX(Simple API for XML)是一个解析速度快并且占用内存少的XML解析器,非常适合用于Android等移动设备. SAX解析器是一种基于事件的解析器,事件驱动 ...
- Form 表单提交参数
今天因为要额外提交参数数组性的参数给form传到后台而苦恼了半天,结果发现,只需要在form表单对应的字段html空间中定义name = 后台参数名 的属性就ok了. 后台本来是只有模型参数的,但是后 ...
- nginx安装
nginx工作模式-->1个master+n个worker进程 安装nginx的所需pcre库[用于支持rewrite模块] 下载软件方法: 搜索 pcre download 网址:http: ...
- centos 6 安装配置openvpn
下载地址:http://swupdate.openvpn.org/community/releases/http://www.oberhumer.com/opensource/lzo/download ...
- Android快乐贪吃蛇游戏实战项目开发教程-06虚拟方向键(五)绘制方向键箭头
本系列教程概述与目录:http://www.cnblogs.com/chengyujia/p/5787111.html本系列教程项目源码GitHub地址:https://github.com/jack ...
- 读过MBA的CEO更自私?《哈佛商业评论》2016年第12期。4星
老牌管理杂志.每期都值得精度.本期我还是给4星. 以下是本书中的一些内容的摘抄: 1:他们发现在Airbnb上,如果客人姓名听起来像黑人,那么比名字像白人的客人的接受率会低16%.#45 2:对立组织 ...