从爬取湖北某高校hub教务系统课表浅谈Java信息抓取的实现 —— import java.*;
原创文章与源码,如果转载请注明来源。
开发环境:Myeclipse,依赖包:apache-httpclient 、 Jsoup、base64
一、概述

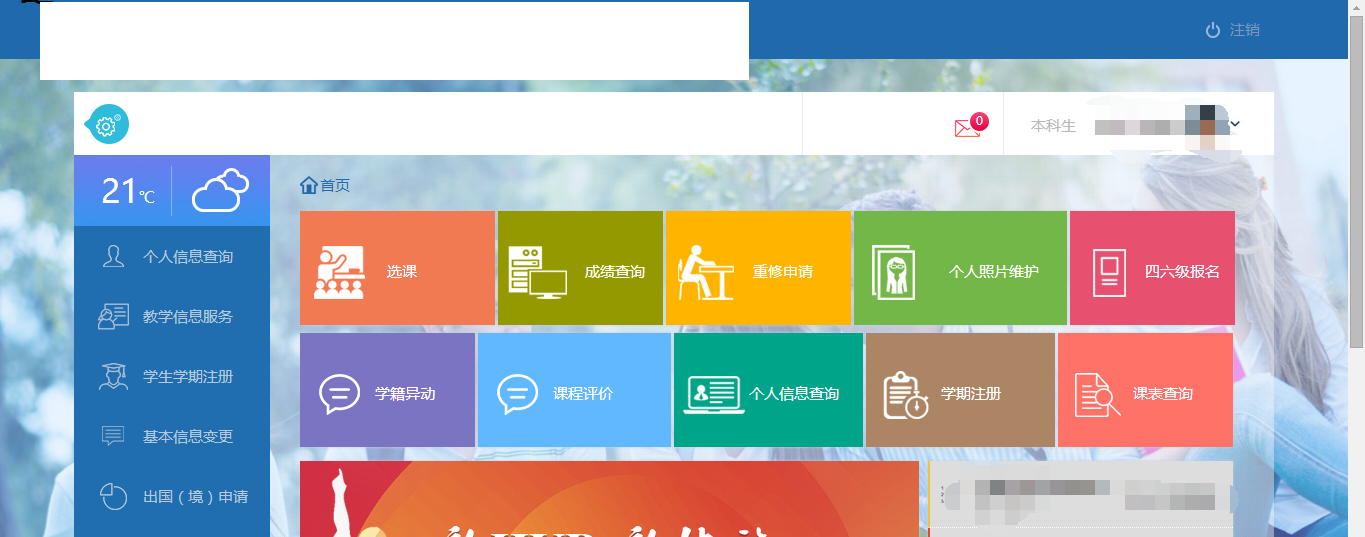
整个系统用Java开发。我们现在要做的是类似于超级课程表、课程格子之类的功能:输入一个学生的教务系统账号、密码,得到Ta的课程表信息。点击进入课表查询,我们发现了这样的页面:
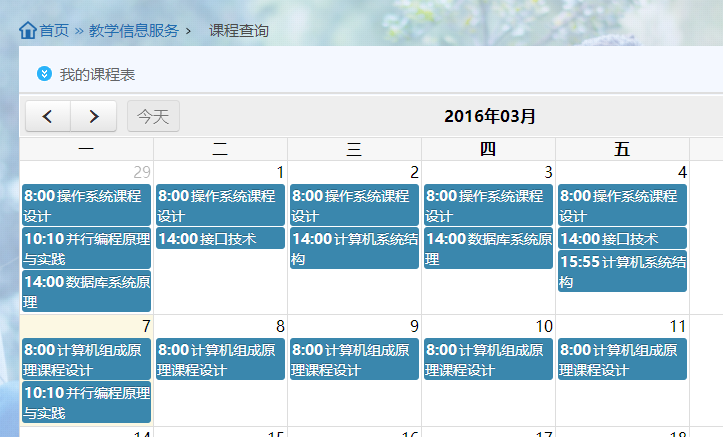
这就是我们需要的结果。其实思路很简单,用java访问这个链接,拿到Html字符串,然后解析链接等需要的数据。
这个页面的URL是http://s.hub.hust.edu.cn/aam/report/scheduleQuery.jsp
因此,我们发送HTTP请求GET http://s.hub.hust.edu.cn/aam/report/scheduleQuery.jsp,这样就可以等到课表的内容了。但是,这个页面必须是在登录之后才能访问的,如果直接发送GET请求的话,系统会认为你没有登录,所以会拒绝你的请求(跳转到登录页面),所以,在发送GET请求之前,必须实现模拟登录。
二、JAVA中GET/POST请求的实现
在进行模拟登录之前,我们需要了解一些基本知识。
首先请看关于HTTP请求的基础知识:http://www.cnblogs.com/yin-jingyu/archive/2011/08/01/2123548.html
在java中,实现执行http请求有多种方式,比如使用urlconnection等等,不过在这里我们使用apache-httpclient。HttpClient 是 Apache Jakarta Common 下的子项目,可以用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。
//1. 首先创建一个CookieStore用于存储Cookie数据 CookieStore cookieStore = new BasicCookieStore(); //2.创建httpclient,并关联CookieStore DefaultHttpClient client = new DefaultHttpClient();
client.setCookieStore(cookieStore); client.getParams().setParameter(CookieSpecPNames.DATE_PATTERNS, Arrays.asList("EEE, dd MMM yyyy HH:mm:ss z")); //该代码用于设置cookie中的expires时间日期格式。添加该代码是因为华科网站使用的cookie日期格式不是标准格式。
创建GET请求:
HttpGet get = new HttpGet("http://xxxx");
get.setHeader("xxx","xxx");
get.setHeader("xxxx","xxxx");
get.setHeader("Cookie","cookie");
HttpResponse response = client.execute(get);
get.releaseConnection();
创建POST请求:
HttpPost post = new HttpPost("http://xxxx");
post.setHeader("xxx","xxxx");
post.setHeader("xxxx","xxxx");
post.setHeader("Cookie","cookie");
//对post请求发送参数
List<NameValuePair> nvps = new ArrayList<NameValuePair>();
nvps.add(new BasicNameValuePair("username", "111"));
nvps.add(new BasicNameValuePair("password", "xxx"));
post.setEntity(new UrlEncodedFormEntity(nvps,"utf-8"));
HttpResponse response = client.execute(post);
从CookieStore得到Cookie字符串
StringBuilder stringBuilder = new StringBuilder();
for(Cookie cookie:cookieStore.getCookies()){
String key =cookie.getName();
String value = cookie.getValue();
stringBuilder.append(key).append("=").append(value).append(";");
} return stringBuilder.toString();
从HttpResponse对象中获取执行的结果(输入流)
InputStream inputStream = response.getEntity().getContent();
//获取结果的输入流
从输入流中获取字符串,可以用如下的函数(注意编码问题)
public static String in2Str(InputStream in) throws IOException{
BufferedReader rd = new BufferedReader(new InputStreamReader(in,"utf-8"));
String line = null;
StringBuilder sb = new StringBuilder();
while ((line=rd.readLine())!=null) {
sb.append(line).append("\r\n");
}
return sb.toString();
}
Jsoup解析
参考资料:http://www.open-open.com/jsoup/
以上几段程序代码就是我们程序工作的核心了,在我的源码中,对这些代码进行了封装,你可以轻松找到它们(在spider包中)。
三、模拟登录的实现
一般地,在java web中,登录可以由类似于如下的代码实现:
前台html的代码如下:
<form action="/login.action" method="post" >
<label for="username">用户名</label>
<input id="username" name=“username" type="text" />
<label for="password">密码</label>
<input id="password" name=“password" type="password" />
<input type="submit" value="登录" /> </form>
后台action如下(spring mvc):
@RequestMapping("/login.action")
public String loginSubmit(HttpServletRequest request,HttpServletResponse response,
@RequestParam("username") String username,@RequestParam("password") String password) {
5
if(username==null||password==null){
request.setAttribute("msg", "您的输入有误!");
return "/login";
}
if(username.equals("")||password.equals("")){
request.setAttribute("msg", "您的输入有误!");
return "/login";
}
User user = userDao.getUser(username, password);
if(user==null){
//TODO 登录失败
return "xxx";
}else{
request.getSession().setAttribute("loginUser",user); //保存登录后的用户到session
//TODO 登录成功
return "xxx";
}
}
其实登录也就是发送POST请求,服务器接收到POST请求(Request)后,对其处理(查询数据库等),返回Response。
其中最关键的与身份验证有关的操作就是request.getSession().setAttribute("loginUser",user) 了。将登录后的用户保存到session中,这样,在访问其他需要身份验证的页面时,服务器只需要判断session中是否有该用户,如果有就表示身份验证通过,如果没有则表示身份验证失败。而java中对于session的实现是依赖于cookie中的jsessionid属性的(参考文档),如果模拟出登录请求后(也就是模拟一个POST请求),得到cookie(也就是得到jsessionid),下次请求时将cookie发送给服务器以表明身份,不就可以访问带有权限的URL了么?
首先我们需要下载webscrab,这个软件有多强大这里就不细说了,大家可以自行百度下载地址。下载后是.jar格式,怎么运行不用我多说了吧。关于webscrab的使用见webscrab.pdf
(webscrab的核心设置)
1.拦截登录时的POST请求:(如果不会请参考使用说明或者百度webscrab的使用)
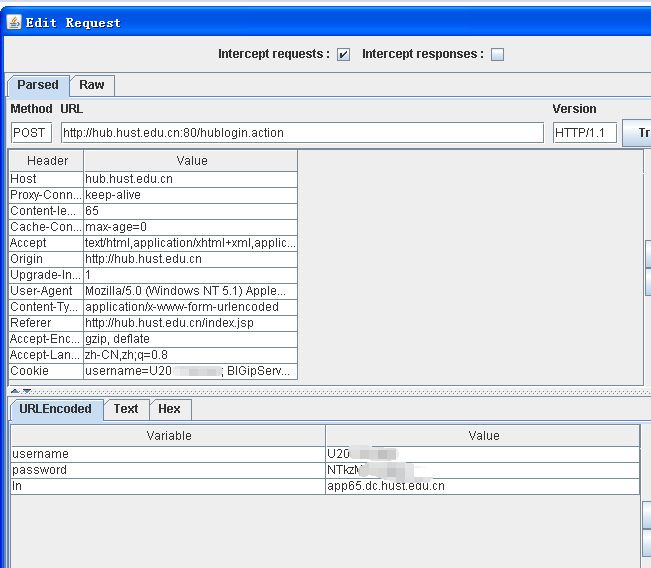
这里我们需要这两种信息:Parsed和URLEncoded,其中,Parsed是POST请求的URL和Header,而URLEncoded则是该请求发送的参数。
我们先看Parsed部分,Parsed部分是由Method、URL和响应头(以<Header,Value>表示的Map型结构)组成。Method表示该请求是POST请求还是GET请求;响应头对应了HttpGet/HttpPost类中的setHeader方法,大多数Header不是必须的,但是在请求时,最好加上相同的Header,以免出现一些问题。例如:如果没有Host(该值表示域名,例如url是http://www.abc.com/login.action,则该值就是www.abc.com)或者Referer头(表示发起请求时的页面,告诉服务器我是从哪里过来的,比如是http://www.abc.com/login.html),在某些情况下可能会出现404错误。【这可能是由于服务器设置了防盗链机制】
因此,最好的处理是将拦截到的Header,都添加到HttpGet/HttpPost中。
或者以一个HashMap的方式存储:(spider.tools.hub.HubEventAdapter和SHubEventAdapter)
HashMap<String, String > map = new HashMap<>();
map.put("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
map.put("Referer", "http://hub.hust.edu.cn/index.jsp");
map.put("Accept-Language","zh-CN,zh;q=0.8");
map.put("User-Agent", useragent);
map.put("Accept-Encoding", "gzip, deflate");
map.put("Host", "hub.hust.edu.cn");
map.put("Proxy-Connection", "Keep-Alive");
map.put("Pragma", "no-cache");
遍历它们,调用setHeader方法。
下面我们再来看URLEncoded部分,该部分表示POST请求发送给服务器的数据。我们发现,其中有三项数据username、password、ln。
我们发现,这里的password值并不是我们刚刚输入的密码,而似乎是一种加密之后的结果,查看http://hub.hust.edu.cn/index.jsp的源代码,发现如下代码:(第210行)
var password = $("input[name='password']").val();
if(password==""){
alert("请输入用户密码(Password)");
$("input[name='password']").focus();
return false;
}
$("input[name='password']").val($.base64.encode(password)); //我们要找的东西在这里!!!
很明显,$.base64,这是base64加密,所以在我们发送POST请求之前,应该对密码进行一次base64加密后再发送。(可以根据密码长度判断是什麼加密类型,一般都是base64加密,32位一般是MD5加密,再长一些则可能是AES加密,如果结果非常长则很可能是RSA加密。)
而ln值,你可以尝试反复刷新页面,反复提交、拦截,会发现每次ln值都会改变,对于这样每次会改变的值,我们采取这样的方式:
GET /index.jsp -> cookie、ln - >POST /login.action
首先对首页执行GET方法,获取首页的HTML内容,并保存cookie。、
接下来用Jsoup解析首页的html内容,得到ln值。
最后将ln值与cookie,加上用户输入的用户名、密码一起POST到/login.action 。
3.中转登录
在发送POST请求后,使用(二)中提供的in2Str方法,得到返回结果,居然发现结果如下:
<body>
<form action="" method="post" name="form1">
<input type="hidden" id="usertype" name="usertype" value="xs">
<input type="hidden" id="username" name="username" value="U2013">
<input type="hidden" id="password" name="password" value="1061d0c (这里为了用户隐私我没有显示)
269c">
<input type="hidden" id="url" name="url" value="http://s.hub.hust.edu.cn/">
<input type="hidden" name="key1" value="367265"/>
<input type="hidden" name="key2" value="a261ab7e0cecb430651868727cd3fb35"/>
<input type="hidden" name="F_App" value="From kslgin. App:app61.dc.hust.edu.cn
|app614|IP:10.10.10.247"/>
</form>
<script type="text/javascript">
var url = document.getElementById("url").value;
document.form1.action=url+'hublogin.action';
document.form1.submit();
</script>
</body>
原来这就是华科中转登录的机制啊。还是一样的发送POST请求
POST http://s.hub.hust.edu.cn/hublogin.action
usertype,username,password,url,key1,key2,F_App。
注意:此时的域名已经改为http://s.hub.hust.edu.cn/了,那么Header中的Host和Refer值最好也改为http://s.hub.hust.edu.cn/。
4.返回
使用下面代码获取POST执行后的整型返回值:
int code = response.getStatusLine().getStatusCode();
如果code=302则登录成功,否则登录失败。(302也就是表示登录已经成功,可以跳转到其他页面了。)
四、课表的获取
在第三部登录成功之后,我们发现GET http://s.hub.hust.edu.cn/aam/report/scheduleQuery.jsp 似乎不包含我想要的课表信息,于是继续使用webscrab。
点击“课表查询”,继续拦截请求,通过几次拦截,发现有一个请求应该包含我需要的课表信息。
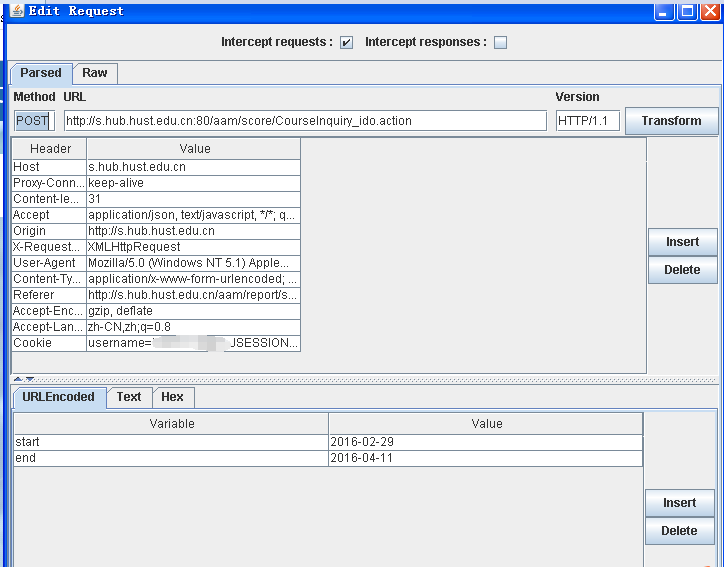
因此,还是使用跟之前类似的方法,发送POST请求
POST http://s.hub.hust.edu.cn:80/aam/score/CourseInquiry_ido.action
start = 2016-02-29
end = 2016-04-11
别忘记带上第三步(登录后)的Cookie!
最后得到的结果如下:
当当~~当————
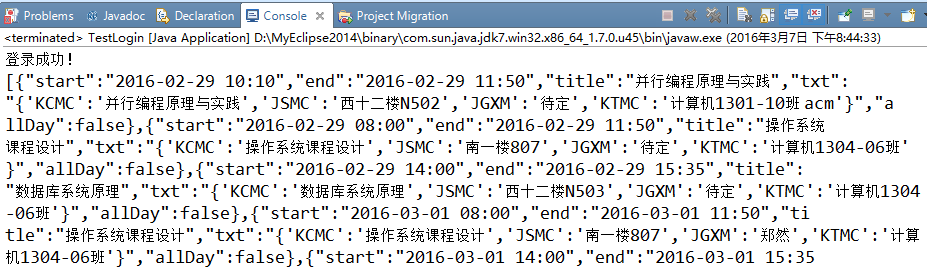
点击下一月,URLEncoded变成了:

这样的日期似乎比较乱啊,
如果将start设置为2016-03-01,end设置为2016-03-31,获取的就是3月的课表。
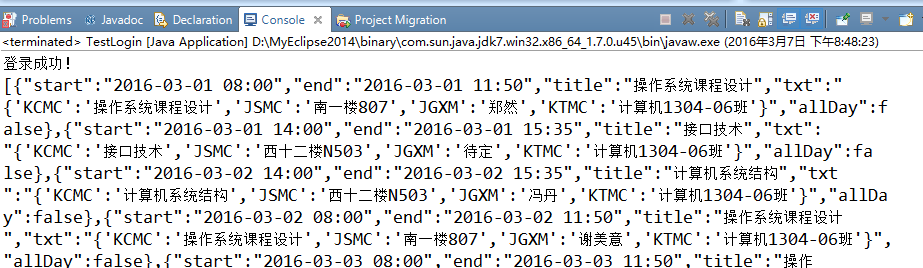
至此,华科大教务系统课表爬取完成!
五、总结
我的代码的编程思路:(用抽象语言表述)
//整体代码用抽象Java语言表示,这些代码只是表示设计思路。不能运行
Header header1 = {"refer","http://hub.hust.edu.cn/index.jsp","host":"hub.hust.edu.cn"}; //响应头header1
Header header2 = {"refer","http://s.hub.hust.edu.cn/index.jsp","host","s.hub.hust.edu.cn"}; //响应头header2
Get get = new Get ("http://hub.hust.edu.cn/index.jsp").header(header1); //进入首页
Response res1 = get.execute();
String content1 = res1.getContent(); //获取index.jsp的html代码
String ln = getln(Jsoup.parse(content1)); //使用jsoup解析index.jsp的html代码,从中获取出ln(input hidden name='ln'的value)
Post post = new Post("http://hub.hust.edu.cn/hubulogin.action").header(header1); //准备模拟登录的,POST提交
//添加post数据
post.add("username","123456789");
post.add("password",base64encode("mypassword"));
post.add("ln",ln)
Response res2 = post.execute(); //执行post请求
Post post2 = new Post("http://s.hub.hust.edu.cn/hublogin.action").header(header2); //中转登录,注意header的变化
Document dform = Jsoup.parse(res2.getContent()); //得到返回的动态表单内容
post.add("usertype",getUserType(d));
post.add("username",getUserName(d));
post.add("password",getPassword(d));
post.add("url",getURL(d));
post.add("key1",getKey1(d));
post.add("key2",getKey2(d));
post.add("F_App",getFApp(d));
Response res3 = post2.execute();
if(res3.getStatusLine().getStatusCode()==302){
syso("登录成功");
}else{
syso("登录失败");
return;
}
Post kbPost = new Post("http://s.hub.hust.edu.cn:80/aam/score/CourseInquiry_ido.action").header(header2); //获取课表的post请求
kbPost.add("start","2016-03-01");
kbPost.add("end","2016-03-30");
Response res4 = kbPost.execute();
if(res4.getStatusLine().getStatusCode()==200){
syso(res4.getContent());
}else{
syso("服务器异常!");
}
扩展:
你可以直接在我的基础上扩展,适用于其他学校的“课程格子”。
你可以选择继承AbstractTask类来表示一项POST/GET请求任务,用getEvent方法来表示该任务的具体内容,最好是对SpiderTaskEvent使用适配器模式。
示例代码如下:(这是基于另一个学校的教务系统实现)
public abstract class JwxtEventAdapter implements SpiderTaskEvent{
private static final String useragent = "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko";
List<StringHeader> headers;
private Cookies cookies;
public JwxtEventAdapter(Cookies cookies){
HashMap<String, String> map = new HashMap<>();
map.put("Accept","text/html, application/xhtml+xml, image/jxr, */*");
map.put("Referer", "http://jwxt.hubu.edu.cn/");
map.put("Accept-Language","zh-Hans-CN,zh-Hans;q=0.8,en-GB;q=0.5,en;q=0.3");
map.put("User-Agent", useragent);
map.put("Accept-Encoding", "gzip, deflate");
map.put("Host", "jwxt.hubu.edu.cn");
map.put("Proxy-Connection", "Keep-Alive");
map.put("Pragma", "no-cache");
headers = StringHeader.build(map);
this.cookies = cookies;
}
public JwxtEventAdapter(){
this(null);
}
@Override
public void beforeExecute(SpiderRequest request) throws IOException {
request.setTimeout(20000);
request.setHeaders(headers);
if(cookies!=null){
request.setCookie(cookies);
}
}
@Override
public void afterExecute(SpiderRequest request, SpiderResponse response)
throws IOException {
}
}
public class JwxtRandomTask extends AbstractTask {
private String random;
private Image image;
public Image getImage(){
return image;
}
/**
* @param client
*/
public JwxtRandomTask(HttpClient client) {
super(client);
}
public String getRandom() {
return random;
}
@Override
public Method getMethod() {
return Method.GET;
}
@Override
public String getURL() {
return "http://jwxt.hubu.edu.cn/verifycode.servlet";
}
@Override
public SpiderTaskEvent getEvent() {
return new JwxtEventAdapter() {
@Override
public void afterExecute(SpiderRequest request,
SpiderResponse response) throws IOException {
image = ImageIO.read(response.getContentStream());
}
};
}
我在写这个程序的时候,确实遇到了一些麻烦,就比如本文提到的404的问题;以及我可能是有点急躁吧,一开始没有注意到其实这个登录action是有一次中转的,导致后面的GET操作都被系统提示为非法操作。
确实做这个让自己感慨万千,大学几年来一直难以踏踏实实的做一些事情,太浮躁,C语言、算法、Java等等都是不精,只学了一点皮毛。一个大三学生班门弄斧,满纸荒唐言,如有错误还请各位大神批评和指出,非常感谢!最后感谢一下提供账号的同学d=====( ̄▽ ̄*)b。
希望以后能越走越远!import java.*;
从爬取湖北某高校hub教务系统课表浅谈Java信息抓取的实现 —— import java.*;的更多相关文章
- 网页信息抓取进阶 支持Js生成数据 Jsoup的不足之处
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/23866427 今天又遇到一个网页数据抓取的任务,给大家分享下. 说道网页信息抓取 ...
- 网页信息抓取 Jsoup的不足之处 httpunit
今天又遇到一个网页数据抓取的任务,给大家分享下. 说道网页信息抓取,相信Jsoup基本是首选的工具,完全的类JQuery操作,让人感觉很舒服.但是,今天我们就要说一说Jsoup的不足. 1.首先我们新 ...
- Ajax异步信息抓取方式
淘女郎模特信息抓取教程 源码地址: cnsimo/mmtao 网址:https://0x9.me/xrh6z 判断一个页面是不是Ajax加载的方法: 查看网页源代码,查找网页中加载的数据信息,如果 ...
- iOS—网络实用技术OC篇&网络爬虫-使用java语言抓取网络数据
网络爬虫-使用java语言抓取网络数据 前提:熟悉java语法(能看懂就行) 准备阶段:从网页中获取html代码 实战阶段:将对应的html代码使用java语言解析出来,最后保存到plist文件 上一 ...
- java网页抓取
网页抓取就是,我们想要从别人的网站上得到我们想要的,也算是窃取了,有的网站就对这个网页抓取就做了限制,比如百度 直接进入正题 //要抓取的网页地址 String urlStr = "http ...
- Java爬虫,信息抓取的实现
转载请注明出处:http://blog.csdn.net/lmj623565791/article/details/23272657 今天公司有个需求,需要做一些指定网站查询后的数据的抓取,于是花了点 ...
- iOS开发——网络实用技术OC篇&网络爬虫-使用java语言抓取网络数据
网络爬虫-使用java语言抓取网络数据 前提:熟悉java语法(能看懂就行) 准备阶段:从网页中获取html代码 实战阶段:将对应的html代码使用java语言解析出来,最后保存到plist文件 上一 ...
- (转)Java爬虫,信息抓取的实现
转载请注明出处:http://blog.csdn.net/lmj623565791/article/details/23272657 今天公司有个需求,需要做一些指定网站查询后的数据的抓取,于是花了点 ...
- 如何使用JAVA语言抓取某个网页中的邮箱地址
现实生活中咱们常常在浏览网页时看到自己需要的信息,但由于信息过于庞大而又不能逐个保存下来. 接下来,咱们就以获取邮箱地址为例,使用java语言抓取网页中的邮箱地址 实现思路如下: 1.使用Java.n ...
随机推荐
- 小丁带你走进git的世界四-重写历史记录
一.git对象文件创建 开篇先补充一个知识点,就是比如我建立一个文件之后,使用git add就会生成一个git对象,但是git对象生成后可以在.git/objects里面对应,首先我们来初始化一个仓库 ...
- CSharpGL(25)一个用raycast实现体渲染VolumeRender的例子
CSharpGL(25)一个用raycast实现体渲染VolumeRender的例子 本文涉及的VolumeRendering相关的C#代码是从(https://github.com/toolchai ...
- 详解mmseg
本文先介绍下mmseg的概念和算法,再说下mmseg4j-solor的3个分词器用法 1.mmseg概念 mmseg是用于中文切词的算法,即Maximum Matching Segment,最大匹配分 ...
- C# - 缓存OutputCache(二)缓存详细介绍
本文是通过网上&个人总结的 1.缓存介绍 缓存是为了提高访问速度,而做的技术. 缓存主要有以下几类:1)客户端缓存Client Caching 2)代理缓存Proxy Caching 3)方向 ...
- 错误: 从内部类中访问本 地变量vvv; 需要被声明为最终类型
从github 下载了源码, 进行编译, 出现了下面的错误 E:\downloads\ff\elasticsearch-master\elasticsearch-master>GRADLE :b ...
- 大数据之Oozie——源码分析(一)程序入口
工作中发现在oozie中使用sqoop与在shell中直接调度sqoop性能上有很大的差异.为了更深入的探索其中的缘由,开始了oozie的源码分析之路.今天第一天阅读源码,由于没有编译成功,不能运行测 ...
- AngularJs之四(作用域)
一:angulaJs的作用域scope Scope(作用域) 是应用在 HTML (视图) 和 JavaScript (控制器)之间的纽带.scope 是一个 JavaScript 对象,带有属性和方 ...
- .NetCore之EF跳过的坑
我在网上看到很多.netCore的信息,就动手自己写一个例子测试哈,但是想不到其中这么多坑: 1.首先.netCore和EF的安装就不用多说了,网上有很多的讲解可以跟着一步一步的下载和安装,但是需要注 ...
- JavaScript权威设计--JavaScript对象(简要学习笔记七)
1.with语句 语法: width(object){ statement } with语句可用于临时扩展作用域链.作用域链可以按序检索的对象列表,通过它可以进行变量名解析. with将object添 ...
- NotePad++中JSLint的使用
1.第一步下载Notepad++ 2.安装JSLint插件 3.运行JSlint 4.前提是你设置了当前语言或者本身文件就是js 5.JSLint的作用主要就是检查你的JS的规则正确性(至少是绝大部分 ...