51、Spark Streaming之输入DStream和Receiver详解
- 输入DStream代表了来自数据源的输入数据流。在之前的wordcount例子中,lines就是一个输入DStream(JavaReceiverInputDStream),
- 代表了从netcat(nc)服务接收到的数据流。除了文件数据流之外,所有的输入DStream都会绑定一个Receiver对象,该对象是一个关键的组件,
- 用来从数据源接收数据,并将其存储在Spark的内存中,以供后续处理。
- Spark Streaming提供了两种内置的数据源支持:
- 1、基础数据源:StreamingContext API中直接提供了对这些数据源的支持,比如文件、socket、Akka Actor等。
- 2、高级数据源:诸如Kafka、Flume、Kinesis、Twitter等数据源,通过第三方工具类提供支持。这些数据源的使用,需要引用其依赖。
- 3、自定义数据源:我们可以自己定义数据源,来决定如何接受和存储数据。
- 要注意的是,如果你想要在实时计算应用中并行接收多条数据流,可以创建多个输入DStream。这样就会创建多个Receiver,从而并行地接收多个数据流。
- 但是要注意的是,一个Spark Streaming Application的Executor,是一个长时间运行的任务,因此,它会独占分配给Spark Streaming Application的cpu core。
- 所以只要Spark Streaming运行起来以后,这个节点上的cpu core,就没法给其他应用使用了。
- 使用本地模式,运行程序时,绝对不能用local或者local[1],因为那样的话,只会给执行输入DStream的executor分配一个线程。而Spark Streaming底层的
- 原理是,至少要有两条线程,一条线程用来分配给Receiver接收数据,一条线程用来处理接收到的数据。因此必须使用local[n],n>=2的模式。
- 如果不设置Master,也就是直接将Spark Streaming应用提交到集群上运行,那么首先,必须要求集群节点上,有>1个cpu core,其次,给Spark Streaming的
- 每个executor分配的core,必须>1,这样,才能保证分配到executor上运行的输入DStream,两条线程并行,一条运行Receiver,接收数据;一条处理数据。
- 否则的话,只会接收数据,不会处理数据。
- 企业工作中,机器肯定是不只一个cpu core,这个问题应该不大。
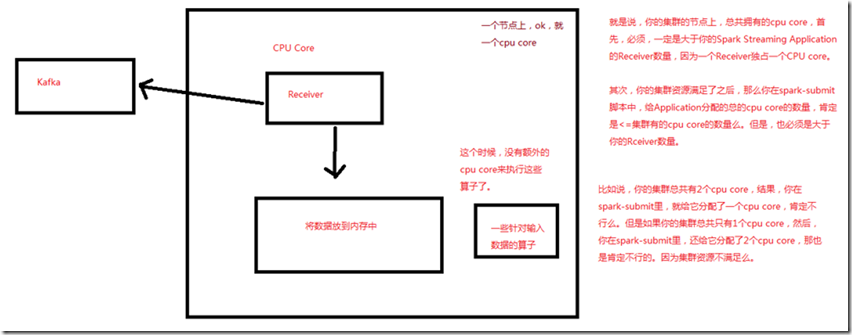
- 所以说,集群的节点上,总共拥有的cpu core,首先,必须是大于Spark Streaming Application的Receiver数量,因为一个Receiver独占一个CPU core;
- 其次,在spark-submit脚本中,给Application分配的总的cpu core,肯定小于等于集群的cpu core的数量,大于Receiver的数量;
51、Spark Streaming之输入DStream和Receiver详解的更多相关文章
- 输入DStream和Receiver详解
输入DStream代表了来自数据源的输入数据流.在之前的wordcount例子中,lines就是一个输入DStream(JavaReceiverInputDStream),代表了从netcat(nc) ...
- StreamingContext详解,输入DStream和Reveiver详解
StreamingContext详解,输入DStream和Reveiver详解 一.StreamingContext详解 1.1两种创建StreamingContext的方式 1.2SteamingC ...
- 52、Spark Streaming之输入DStream之基础数据源以及基于HDFS的实时wordcount程序
一.概述 1.Socket:之前的wordcount例子,已经演示过了,StreamingContext.socketTextStream() 2.HDFS文件 基于HDFS文件的实时计算,其实就是, ...
- Spark Streaming初步使用以及工作原理详解
在大数据的各种框架中,hadoop无疑是大数据的主流,但是随着电商企业的发展,hadoop只适用于一些离线数据的处理,无法应对一些实时数据的处理分析,我们需要一些实时计算框架来分析数据.因此出现了很多 ...
- 64、Spark Streaming:StreamingContext初始化与Receiver启动原理剖析与源码分析
一.StreamingContext源码分析 ###入口 org.apache.spark.streaming/StreamingContext.scala /** * 在创建和完成StreamCon ...
- Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
本期内容 : Receiver启动的方式设想 Receiver启动源码彻底分析 多个输入源输入启动,Receiver启动失败,只要我们的集群存在就希望Receiver启动成功,运行过程中基于每个Tea ...
- Spark Streaming之三:DStream解析
DStream 1.1基本说明 1.1.1 Duration Spark Streaming的时间类型,单位是毫秒: 生成方式如下: 1)new Duration(milli seconds) 输入毫 ...
- Spark RDD、DataFrame原理及操作详解
RDD是什么? RDD (resilientdistributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用. RDD内部可以 ...
- 输入一个url全过程详解
1. 用户在浏览器中输入url,浏览器接收到url. 2.浏览器接收到这个url之后,会根据这个url会先查看缓存,如果有缓存且没有过期的话直接提供给客户端,完成页面渲染. 3.否则浏览器就会通过DN ...
随机推荐
- java之spring mvc之Restful风格开发及相关的配置
1. Restful : 表征状态状态转移. 传统 : url : http://localhost:8080/usersys/delete.do?user.id=12 Restful 风格:url ...
- CSS控制DIV水平垂直居中
<div style="position:absolute; width: 600px; height: 200px; left: 50%; top: 50%; margin-left ...
- [JLOI2014]松鼠的新家 (树剖)
题目 P3258 [JLOI2014]松鼠的新家 解析 非常裸的一道树剖题 链上修改+单点查询的板子 记录一下所经过的点\(now[i]\),每次更新\(now[i-1]到now[i]\) 我们链上更 ...
- js模块基础练习题
题目描述 完成函数 createModule,调用之后满足如下要求: 1.返回一个对象 2.对象的 greeting 属性值等于 str1, name 属性值等于 str2 3.对象存在一个 sayI ...
- Vue学习之webpack中使用vue(十七)
一.包的查找规则: 1.在项目根目录中找有没有 node_modules 的文件夹: 2.在 node_modules 中根据包名,找对应的vue 文件夹: 3.在vue 文件夹中,找 一个叫做 pa ...
- CSS3 小黄人案例
使用 CSS3 和 HTML5 制作一个小黄人. 结构代码: <div class="wrap"> <!-- 头发 --> <div class=&q ...
- VSCode 控制台面板输出乱码 字符编码问题 PHP --已解决
首先上一张效果图,看看是不是你想要的效果. 第一步: 按F1,输入settings.json,添加 "code-runner.runInTerminal": true, 第二步:将 ...
- Gtest:死亡测试
转自:玩转Google开源C++单元测试框架Google Test系列(gtest)之五 - 死亡测试 一.前言 “死亡测试”名字比较恐怖,这里的“死亡”指的的是程序的崩溃.通常在测试过程中,我们需要 ...
- IDEA中css文件包红色下划线
选中该文件,右键 -> Analyze -> Configure Current File Analysis... Highlighting Level置为None
- OpenGL学习(2)—— 创建第一个窗口
创建 GLFW GLFW是一个专门针对OpenGL的C语言库,它提供了一些渲染物体所需的最低限度的接口.它允许用户创建OpenGL上下文,定义窗口参数以及处理用户输入,这正是我们需要的. #inclu ...