使用requests简单的页面爬取
首先安装requests库和准备User Agent
安装requests直接使用pip安装即可
pip install requests
准备User Agent,直接在百度搜索"UA查询",随便找一个即可.
1.进行信息爬取
以爬取政府网站信息为例
############################# 简单的页面爬取 ####################################### # Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0 #导入requests库
import requests
#指定我们的UserAgent
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent':user_agent}
#requests库用来发送请求的语句是requests.get
r = requests.get("http://www.gov.cn/zhengce/2019-05/09/content_5390046.htm",headers = headers)
#打印结果
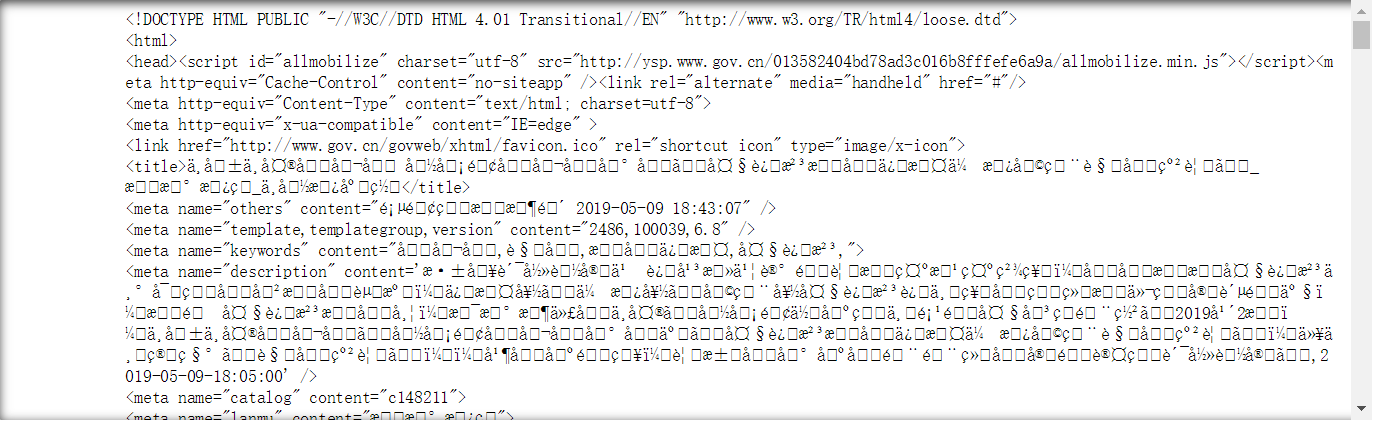
print(r.text)
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.encoding查询编码方式
print('编码方式:',r.encoding)
print('\n====================================')
print('\n\n\n')
代码运行结果:
====================================
编码方式: ISO-8859-1
====================================
#修改encoding为utf-8
r.encoding = 'utf-8'
#重新打印结果
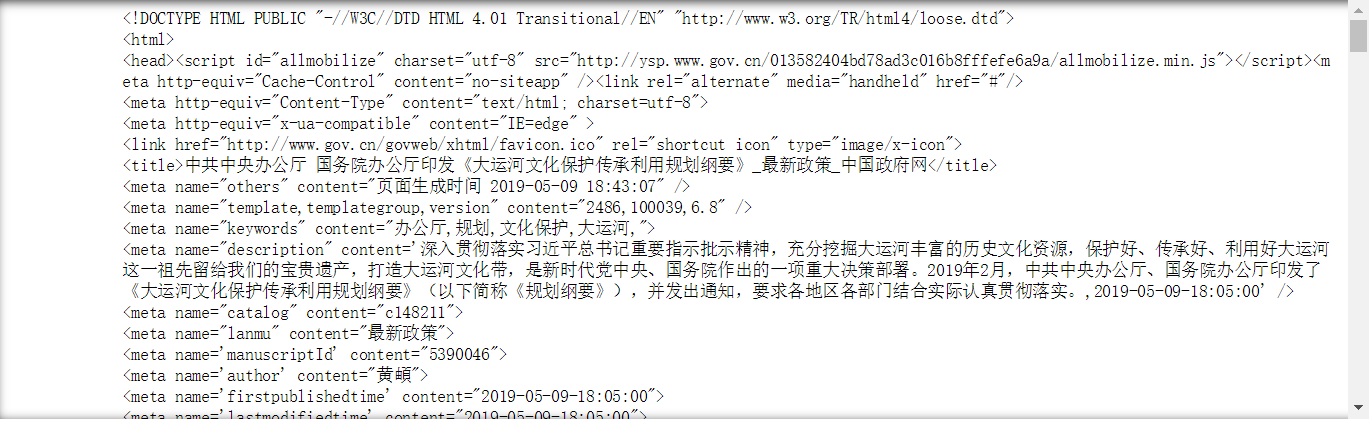
print(r.text)
#保存指定html文件的路径,文件名和编码方式
with open ('d:/jupyternotebook/requests.html','w',encoding = 'utf8') as f :
#将文本写入
f.write(r.text)
'''
'\d+'前面的"r"意思是不要对"\"进行转义-------在pyton中,"\"表示转义符,如我们常用的"\n"就表示换行.
如果不希望python对'\'进行转义,有两种方法,一是在转义符前面再增加一个斜杠'\',如:'\\n',那么python就不会对字符进行转义,
另一种方法就是在前面添加'r',如本例中的"r'\d+"
'''
#导入re模块
import re
#指定匹配模式为从开始位置匹配数字
pattern = re.compile(r'\d+')
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#第一句话前面是文本,后面是数字
result1 = re.match(pattern,'你说什么都是对的456')
#如果匹配成功,打印匹配的内容
if result1:
print(result1.group())
#否则打印"匹配失败"
else:
print('匹配失败')
#第二句话前面是数字,后面是文本
result2 = re.match(pattern,"465你说什么都是对的---")
#如果匹配成功,打印匹配的内容
if result2:
print(result2.group())
#否则打印"匹配失败"
else:
print('匹配失败')
print('\n====================================')
print('\n\n\n')
代码运行结果:
====================================
匹配失败
465
====================================
#用.search()来进行搜索
result3 = re.search(pattern,'你说什么456都是对的')
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#如果匹配成功,打印结果,否则打印'匹配失败'
if result3:
print(result3.group())
#否则打印"匹配失败"
else:
print('匹配失败')
print('\n====================================')
print('\n\n\n')
代码运行结果:
====================================
456
====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.split()把数字之间的文本拆分出来
print(re.split(pattern,'你说什么56565都是对的79879879啊哈'))
print('\n====================================')
print('\n\n\n')
代码运行结果:
====================================
['你说什么', '都是对的', '啊哈']
====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.findall()把数字之间的文本拆分出来
print(re.findall(pattern,'你说什么56565都是对的79879879啊哈'))
print('\n====================================')
print('\n\n\n')
代码运行结果:
====================================
['56565', '79879879']
====================================
#导入BeautifulSoup
from bs4 import BeautifulSoup
#创建一个名为soup的对象
soup = BeautifulSoup(r.text,'lxml',from_encoding='utf8')
print(soup)

print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.'标签名'即可提取这部分内容
print(soup.title)
print('\n====================================')
print('\n\n\n')
代码运行结果:
====================================
<title>中共中央办公厅 国务院办公厅印发《大运河文化保护传承利用规划纲要》_最新政策_中国政府网</title>
====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.string即可提取这部分内容中的文本数据
print(soup.title.string)
print('\n====================================')
print('\n\n\n')
代码运行结果:
====================================
中共中央办公厅 国务院办公厅印发《大运河文化保护传承利用规划纲要》_最新政策_中国政府网
====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#使用.get_text()也可以提取这部分内容中的文本数据
print(soup.title.get_text())
print('\n====================================')
print('\n\n\n')
代码运行结果:
====================================
中共中央办公厅 国务院办公厅印发《大运河文化保护传承利用规划纲要》_最新政策_中国政府网
====================================
print('\n\n\n')
print('代码运行结果:')
print('====================================\n')
#打印标签<p>中的内容
print(soup.p.string)
print('\n====================================')
print('\n\n\n')

#使用find_all找到所有的<p>标签中的内容
texts = soup.find_all('p')
#使用for循环来打印所有的内容
for text in texts:
print(text.string)

#找到倒数第一个<a>标签
link = soup.find_all('a')[-1]
print('\n\n\n')
print('BeautifulSoup提取的连接:')
print('====================================\n')
print(link.get('href'))
print('\n====================================')
print('\n\n\n')
BeautifulSoup提取的连接:
====================================
None
====================================
2.对目标页面进行爬取并保存到本地
############################# 简单的页面爬取,并保存为excel文件实例 #######################################
# Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0 #导入requests库
import requests
#导入CSV库便于我们把爬取的内容保存为CSV文件
import csv
#导入BeautifulSoup
from bs4 import BeautifulSoup
#导入正则表达式re库
import re #定义爬虫的User Agent
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'
headers = {'User-Agent':user_agent} #使用requests发送请求
policies = requests.get('http://www.gov.cn/zhengce/zuixin.htm',headers = headers)
#指定编码为"utf-8"
policies.encoding = 'utf-8'
#创建BeatifulSoup对象
p = BeautifulSoup(policies.text,'lxml')
#用正则表达式匹配所有包含"content"单词的链接
contents = p.find_all(href = re.compile('content'))
#定义一个空列表
rows = []
#设计一个for循环,将每个数据中的链接和文本进行提取
for content in contents:
href = content.get('href')
row = ('国务院',content.string,href)
#将提取的内容添加到前面定义的空列表中
rows.append(row)
#定义CSV的文件头
header = ['发文部门','标题','链接']
#建立一个名叫policies.csv的文件,以写入模式打开,记得设置编码为gb18030,否则会乱码
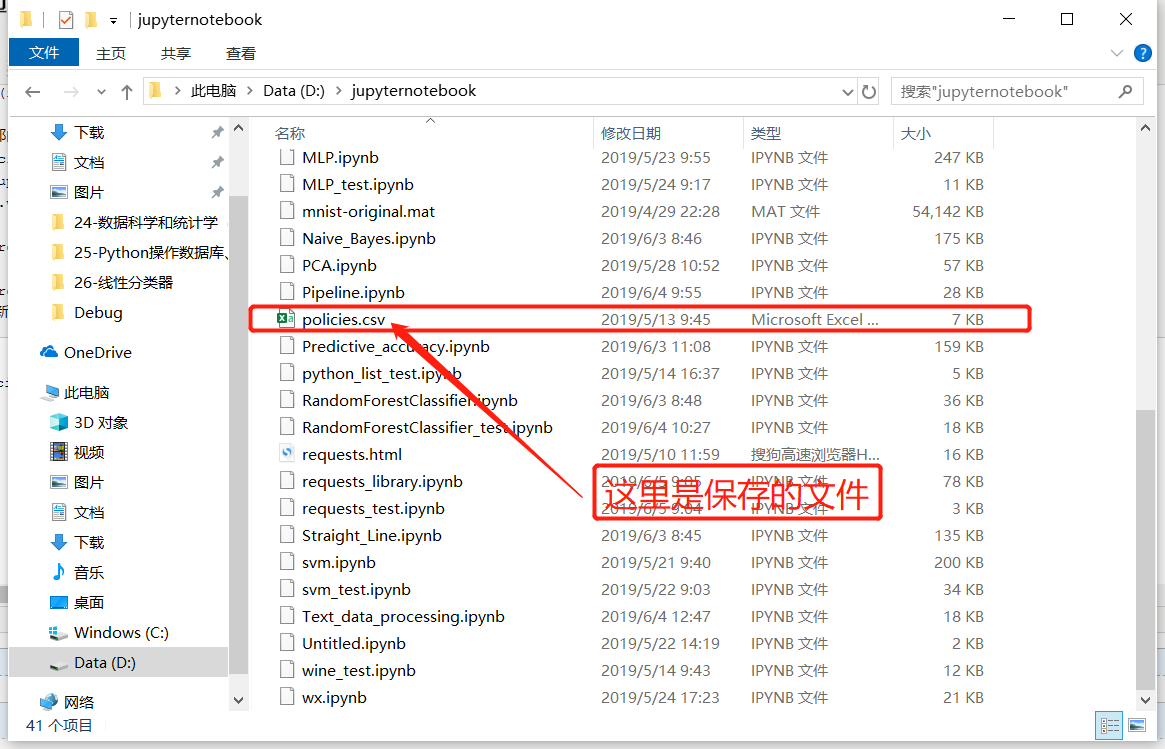
with open('d:/jupyternotebook/policies.csv','w',encoding='gb18030') as f:
f_csv = csv.writer(f)
#写入文件头
f_csv.writerow(header)
#写入列表
f_csv.writerows(rows)
print('\n\n\n最新信息获取完成\n结果保存在D盘policies.csv文件\n\n\n')
最新信息获取完成
结果保存在D盘policies.csv文件

总结 :
这里是简单的对网页进行爬取,如果想进行复杂的爬取,可以深入了解Scrapy,其目前是最常用的python开发爬虫的工具之一.
文章引自 : 《深入浅出python机器学习》
使用requests简单的页面爬取的更多相关文章
- Python Requests库入门——应用实例-京东商品页面爬取+模拟浏览器爬取信息
京东商品页面爬取 选择了一款荣耀手机的页面(给华为打广告了,荣耀play真心不错) import requests url = "https://item.jd.com/7479912.ht ...
- 一个简单java爬虫爬取网页中邮箱并保存
此代码为一十分简单网络爬虫,仅供娱乐之用. java代码如下: package tool; import java.io.BufferedReader; import java.io.File; im ...
- python3编写网络爬虫14-动态渲染页面爬取
一.动态渲染页面爬取 上节课我们了解了Ajax分析和抓取方式,这其实也是JavaScript动态渲染页面的一种情形,通过直接分析Ajax,借助requests和urllib实现数据爬取 但是javaS ...
- 爬虫系列4:scrapy技术进阶之多页面爬取
多页面爬取有两种形式. 1)从某一个或者多个主页中获取多个子页面的url列表,parse()函数依次爬取列表中的各个子页面. 2)从递归爬取,这个相对简单.在scrapy中只要定义好初始页面以及爬虫规 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- python爬爬爬之单网页html页面爬取
python爬爬爬之单网页html页面爬取 作者:vpoet mail:vpoet_sir@163.com 注:随意copy 不用告诉我 #coding:utf-8 import urllib2 Re ...
- py3+requests+re+urllib,爬取并下载不得姐视频
实现原理及思路请参考我的另外几篇爬虫实践博客 py3+urllib+bs4+反爬,20+行代码教你爬取豆瓣妹子图:http://www.cnblogs.com/UncleYong/p/6892688. ...
- 爬虫系列5:scrapy动态页面爬取的另一种思路
前面有篇文章给出了爬取动态页面的一种思路,即应用Selenium+Firefox(参考<scrapy动态页面爬取>).但是selenium需要运行本地浏览器,比较耗时,不太适合大规模网页抓 ...
- Java两种方式简单实现:爬取网页并且保存
注:如果代码中有冗余,错误或者不规范,欢迎指正. Java简单实现:爬取网页并且保存 对于网络,我一直处于好奇的态度.以前一直想着写个爬虫,但是一拖再拖,懒得实现,感觉这是一个很麻烦的事情,出现个小错 ...
随机推荐
- 20189220 余超《Linux内核原理与分析》第一周作业
实验一 Linux系统简介 通过实验一主要是学习到了Linux 的历史简介,linux与windows之间的区别,主要是免费和收费,软件和支持,安全性,使用习惯,可制定性,应用范畴等.linux具有稳 ...
- 第07组 Alpha冲刺(6/6)
队名:摇光 队长:杨明哲 组长博客:求戳 作业博客:求再戳 队长:杨明哲 过去两天完成了哪些任务 文字/口头描述:博客生成的逻辑 展示GitHub当日代码/文档签入记录:(组内共用,已询问过助教小姐姐 ...
- python 文件夹下的图片转PDF
from PIL import Image import os def rea(path, pdf_name): file_list = os.listdir(path) pic_name = [] ...
- 扩展自easyui的combo组件的下拉多选控件
首先上效果图 代码片段: 有需要的朋友微信联系我. 如果这篇文章对您有帮助,您可以打赏我 技术交流QQ群:15129679
- python操作excel——openpyxl
一.概述 python操作excel各个库对比:https://www.cnblogs.com/paul-liang/p/9187503.html 官方文档:https://openpyxl.read ...
- 自定义Shell分隔符
在shell中使用for循环语句时,参数列表有时候需要将空格纳入参数当中,这时就不好使用空格作为分隔符.如下例中,我实际想要输出的是a1.a2.b1.b2以及hello world,但却输出了如下内容 ...
- Swift自定义AlertView
今天项目加新需求,添加积分过期提醒功能: 第一反应就用系统的UIAlertViewController,但是message中积分是需要红色显示. // let str = "尊敬的顾客,您有 ...
- [LeetCode] 81. Search in Rotated Sorted Array II 在旋转有序数组中搜索 II
Follow up for "Search in Rotated Sorted Array":What if duplicates are allowed? Would this ...
- python测试工具nosetests
今天在github上找东西,找到个工具是python写的,但是需要安装nosetests,因此了解了下nosetests python除了unittest,还有nosetests,使用更快捷 nose ...
- 算法练习之x的平方根,爬楼梯,删除排序链表中的重复元素, 合并两个有序数组
1.x的平方根 java (1)直接使用函数 class Solution { public int mySqrt(int x) { int rs = 0; rs = (int)Math.sqrt(x ...