Spark 系列(六)—— 累加器与广播变量
一、简介
在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable):
- 累加器:用来对信息进行聚合,主要用于累计计数等场景;
- 广播变量:主要用于在节点间高效分发大对象。
二、累加器
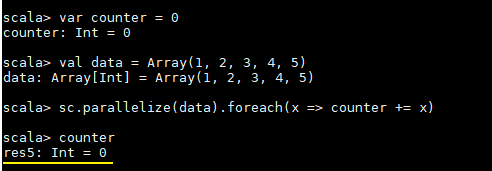
这里先看一个具体的场景,对于正常的累计求和,如果在集群模式中使用下面的代码进行计算,会发现执行结果并非预期:
var counter = 0
val data = Array(1, 2, 3, 4, 5)
sc.parallelize(data).foreach(x => counter += x)
println(counter)counter 最后的结果是 0,导致这个问题的主要原因是闭包。
2.1 理解闭包
1. Scala 中闭包的概念
这里先介绍一下 Scala 中关于闭包的概念:
var more = 10
val addMore = (x: Int) => x + more如上函数 addMore 中有两个变量 x 和 more:
- x : 是一个绑定变量 (bound variable),因为其是该函数的入参,在函数的上下文中有明确的定义;
- more : 是一个自由变量 (free variable),因为函数字面量本生并没有给 more 赋予任何含义。
按照定义:在创建函数时,如果需要捕获自由变量,那么包含指向被捕获变量的引用的函数就被称为闭包函数。
2. Spark 中的闭包
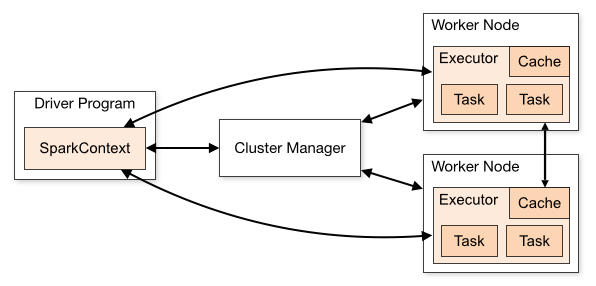
在实际计算时,Spark 会将对 RDD 操作分解为 Task,Task 运行在 Worker Node 上。在执行之前,Spark 会对任务进行闭包,如果闭包内涉及到自由变量,则程序会进行拷贝,并将副本变量放在闭包中,之后闭包被序列化并发送给每个执行者。因此,当在 foreach 函数中引用 counter 时,它将不再是 Driver 节点上的 counter,而是闭包中的副本 counter,默认情况下,副本 counter 更新后的值不会回传到 Driver,所以 counter 的最终值仍然为零。
需要注意的是:在 Local 模式下,有可能执行 foreach 的 Worker Node 与 Diver 处在相同的 JVM,并引用相同的原始 counter,这时候更新可能是正确的,但是在集群模式下一定不正确。所以在遇到此类问题时应优先使用累加器。
累加器的原理实际上很简单:就是将每个副本变量的最终值传回 Driver,由 Driver 聚合后得到最终值,并更新原始变量。
2.2 使用累加器
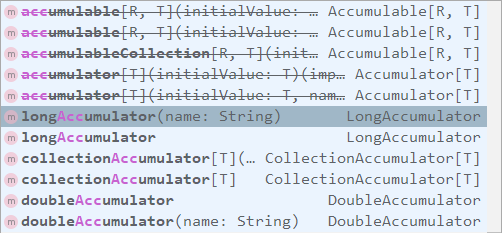
SparkContext 中定义了所有创建累加器的方法,需要注意的是:被中横线划掉的累加器方法在 Spark 2.0.0 之后被标识为废弃。
使用示例和执行结果分别如下:
val data = Array(1, 2, 3, 4, 5)
// 定义累加器
val accum = sc.longAccumulator("My Accumulator")
sc.parallelize(data).foreach(x => accum.add(x))
// 获取累加器的值
accum.value
三、广播变量
在上面介绍中闭包的过程中我们说道每个 Task 任务的闭包都会持有自由变量的副本,如果变量很大且 Task 任务很多的情况下,这必然会对网络 IO 造成压力,为了解决这个情况,Spark 提供了广播变量。
广播变量的做法很简单:就是不把副本变量分发到每个 Task 中,而是将其分发到每个 Executor,Executor 中的所有 Task 共享一个副本变量。
// 把一个数组定义为一个广播变量
val broadcastVar = sc.broadcast(Array(1, 2, 3, 4, 5))
// 之后用到该数组时应优先使用广播变量,而不是原值
sc.parallelize(broadcastVar.value).map(_ * 10).collect()参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Spark 系列(六)—— 累加器与广播变量的更多相关文章
- spark累加器、广播变量
一言以蔽之: 累加器就是只写变量 通常就是做事件统计用的 因为rdd是在不同的excutor去执行的 你在不同excutor中累加的结果 没办法汇总到一起 这个时候就需要累加器来帮忙完成 广播变量是只 ...
- Spark学习之路(六)—— 累加器与广播变量
一.简介 在Spark中,提供了两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: 广播变量 ...
- 入门大数据---Spark累加器与广播变量
一.简介 在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景: ...
- Spark入门3(累加器和广播变量)
一.概要 通常情况下,当向Spark操作传递一个函数时,它会在一个远程集群节点上执行,它会使用函数中所有变量的副本.这些变量被复制到所有的机器上,远程机器上并没有被更新的变量会向驱动程序回传.在任务之 ...
- 小白学习Spark系列六:Spark调参优化
前几节介绍了下常用的函数和常踩的坑以及如何打包程序,现在来说下如何调参优化.当我们开发完一个项目,测试完成后,就要提交到服务器上运行,但运行不稳定,老是抛出如下异常,这就很纳闷了呀,明明测试上没问题, ...
- 【Spark调优】Broadcast广播变量
[业务场景] 在Spark的统计开发过程中,肯定会遇到类似小维表join大业务表的场景,或者需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时应该使用Spark的广 ...
- Spark系列(六)Master注册机制和状态改变机制
各组件的注册流程如下图: 注册机制源码说明: 入口:org.apache.spark.deploy.master文件下的receiveWithLogging方法中的case RegisterAppli ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- SparkCore | Rdd| 广播变量和累加器
Spark中三大数据结构:RDD: 广播变量: 分布式只读共享变量: 累加器:分布式只写共享变量: 线程和进程之间 1.RDD中的函数传递 自己定义一些RDD的操作,那么此时需要主要的是,初始化工作 ...
随机推荐
- 原创:搜索排序算法之自定义性能优良的PriorityQueue(与Python的heap比较)
前几天写了一篇关于"史上对BM25模型最全面最深刻解读以及lucene排序深入解读"的博客,lucene最后排序用到的思想是"从海量数据中寻找topK"的时间空 ...
- mysql tan() 函数
mysql> ); +--------------------+ | tan(pi()/) | +--------------------+ | 0.9999999999999999 | +-- ...
- h5的复制功能的使用,Clipboard.js的使用,主要是在app里面使用
app中使用,框架用的是vue.js 1.显示要下载这个Clipboard.js插件 package-lock.json里面 "clipboard-polyfill": { &qu ...
- nginx 平滑重启的实现方法
一.背景 在服务器开发过程中,难免需要重启服务加载新的代码或配置,如果能够保证server重启的过程中服务不间断,那重启对于业务的影响可以降为0.最近调研了一下nginx平滑重启,觉得很有意思,记录下 ...
- html5 css3 背景视频循环播放代码
<div style ="position: absolute; z-index: -1; top: 0px; left: 0px; bottom: 0px; right: 0px; ...
- IDEA将指定package(指定文件)打成jar包
写在前面 真的是好记性不如烂笔头 需求 将项目中包名为org的package打成jar包 步骤 1.选择Artifacts>绿色+号>JAR>Empty name自定义, 我这里命名 ...
- tomcat乱码解决
一.修改Tomcat的conf的server.xml文件加上 URIEncoding="UTF-8" 二.在tomcat的bin 目录下的catalina.bat 配置文件中,添加 ...
- EasyNVR摄像机网页Chrome无插件视频播放功能二次开发之通道配置文件上传下载示例代码
背景需求 熟悉EasyNVR产品的朋友们都知道,产品设计初期根据整个直播流程层级,我们将EasyNVR无插件直播系统划分为:硬件层.能力层.应用层,连接硬件与应用之间的桥梁,同时屏蔽各种厂家硬件的不同 ...
- Excel四象限散点图的制作方法
Excel中四象限散点图带文本数据标签,可以在散点图的基础上进行一些设置即可得到,无需第三方插件或者宏代码,非常方便,以office2013为例,效果如下: 步骤: 1.准备好数据源,选中两列数据源( ...
- TortoiseGit 查看单个文件日志显示全部提交记录了 解决办法
右击文件,Show log.后来在界面上发现,“显示整个工程”的选项.才发现不能勾这个. 去掉勾选,就可以看到单个文件日志了,如果勾选"All Branches"就可以看到该文件在 ...