mysql索引原理及优化(二)
索引原理分析:数据结构
索引是最常见的慢查询优化方式
其是一种优化查询的数据结构,MySql中的索引是用B+树实现,而B+树就是一种数据结构,可以优化查询速度,可以利用索引快速查找数据,优化查询。
可以提高查询速度的数据结构:
哈希表、完全平衡二叉树、B树、B+树等等。
哈希:select* from sanguo where name>'周瑜 哈希表的特点是可以快速的精确查询,但是不支持范围查询。
完全平衡二叉树:对于数据量大情况,它相比于哈希或者B树、B+树需要查找次数更多。
B树:比完全平衡二叉树要矮,查询速度更快,所需索引空间更小。
B+树:B+树比B树要胖,B+树的非叶子节点会冗余一份在叶子节点中,并且也在叶子节点会用指针相连。
B树相比完全平衡二叉树查询次数更少,即有更少的磁盘IO次数,性能更优;
B+树是B树的升级版,其为了提高范围查找的效率。
总结:Mysql选用B+树这种数据结构作为索引,可以提高查询索引时的磁盘IO效率,并且可以提高范围查询的效率,并且B+树里的元素也是有序的。
索引的最左前缀原则:当建立多个字段联合索引时,如(a,b,c) 查询条件只会走三类索引 即 a 、 ab 、 abc, ac也走,但是只走a索引。
为什么哈希表、完全平衡二叉树、B树、B+树都可以优化查询,为何Mysql独独喜欢B+树?
哈希表有什么特点?
假如有这么一张表(表名:sanguo):
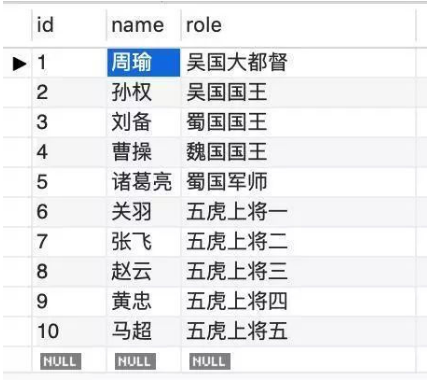
现在对 name 字段建立哈希索引:
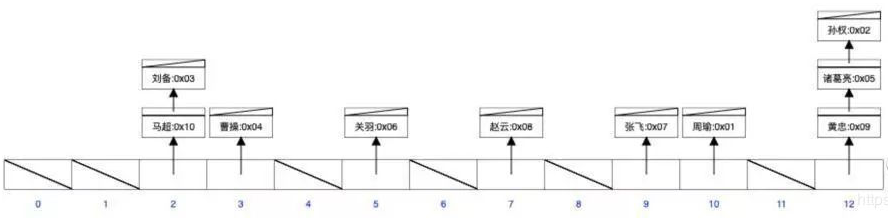
注意字段值所对应的数组下标是哈希算法随机算出来的,所以可能出现哈希冲突。那么对于这样一个索引结构,现在来执行下面的sql语句:
select * from sanguo where name='周瑜'
可以直接对‘周瑜’按哈希算法算出来一个数组下标,然后可以直接从数据中取出数据并拿到所对应那一行数据的地址,进而查询那一行数据。 那么如果现在执行下面的sql语句:
select * from sanguo where name>'周瑜'
则无能为力,因为哈希表的特点就是可以快速的精确查询,但是不支持范围查询。
如果用完全平衡二叉树呢?
还是上面的表数据用完全平衡二叉树表示如下图(为了简单,数据对应的地址就不画在图中了。):
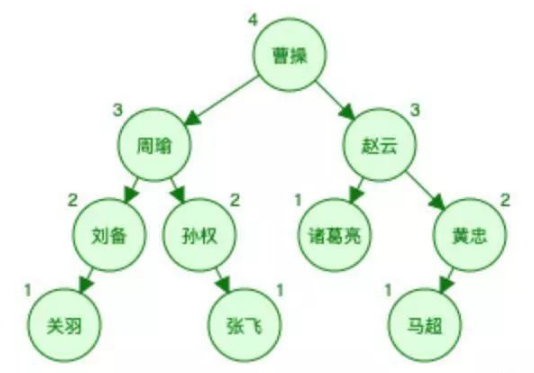
图中的每一个节点实际上应该有四部分:
左指针,指向左子树
键值
键值所对应的数据的存储地址
右指针,指向右子树
另外需要提醒的是,二叉树是有顺序的,简单的说就是“左边的小于右边的”假如我们现在来查找‘周瑜’,需要找2次(第一次曹操,第二次周瑜),比哈希表要多一次。
而且由于完全平衡二叉树是有序的,所以也是支持范围查找的。
如果用B树呢?
还是上面的表数据用B树表示如下图(为了简单,数据对应的地址就不画在图中了。):
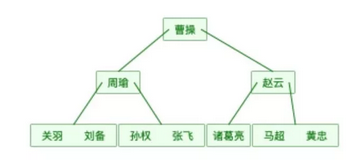
可以发现同样的元素,B树的表示要比完全平衡二叉树要“矮”,原因在于B树中的一个节点可以存储多个元素。
如果用B+树呢?
还是上面的表数据用B+树表示如下图(为了简单,数据对应的地址就不画在图中了。):
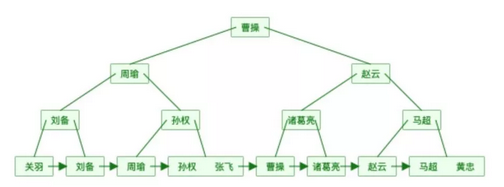
我们可以发现同样的元素,B+树的表示要比B树要“胖”,原因在于B+树中的非叶子节点会冗余一份在叶子节点中,并且叶子节点之间用指针相连。
那么B+树到底有什么优势呢?
这里我们用“反证法”,假如我们现在就用完全平衡二叉树作为索引的数据结构,我们来看一下有什么不妥的地方。实际上,索引也是很“大”的,因为索引也是存储元素的,我们的一个表的数据行数越多,那么对应的索引文件其实也是会很大的,实际上也是需要存储在磁盘中的,而不能全部都放在内存中,所以我们在考虑选用哪种数据结构时,我们可以换一个角度思考,哪个数据结构更适合从磁盘中读取数据,或者哪个数据结构能够提高磁盘的IO效率。回头看一下完全平衡二叉树,当我们需要查询“张飞”时,需要以下步骤:
从磁盘中取出“曹操”到内存,CPU从内存取出数据进行比较,“张飞”<“曹操”,取左子树(产生了一次磁盘IO)
从磁盘中取出“周瑜”到内存,CPU从内存取出数据进行比较,“张飞”>“周瑜”,取右子树(产生了一次磁盘IO)
从磁盘中取出“孙权”到内存,CPU从内存取出数据进行比较,“张飞”>“孙权”,取右子树(产生了一次磁盘IO)
从磁盘中取出“黄忠”到内存,CPU从内存取出数据进行比较,“张飞”=“张飞”,找到结果(产生了一次磁盘IO)
从上面可以发现:完全平衡二叉树,当我们需要查询“张飞”时需要4次磁盘IO,也就是4次从磁盘中取出数据(磁盘块)到内存
同理,回头看一下B树,我们发现只发送三次磁盘IO就可以找到“张飞”了,这就是B树的优点:一个节点可以存储多个元素,相对于完全平衡二叉树所以整棵树的高度就降低了,磁盘IO效率提高了。
而B+树是B树的升级版,只是把非叶子节点冗余一下,这么做的好处是为了提高范围查找的效率。
Mysql中MyISAM和innodb 的B+树结构如下图:
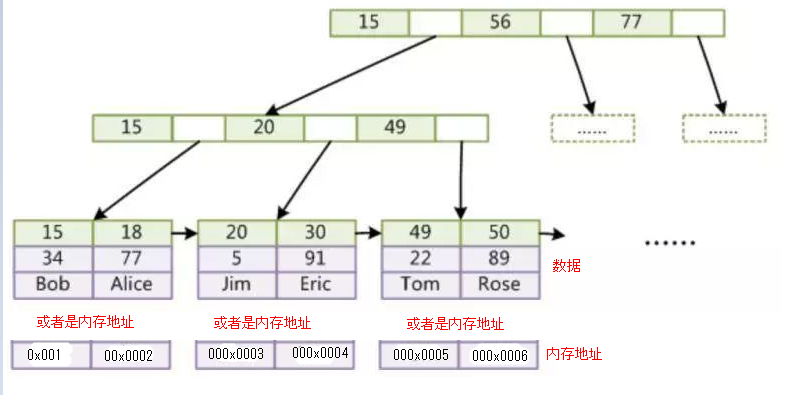
通常我们认为B+树的非叶子节点不存储数据,只有叶子节点才存储数据;而B树的非叶子和叶子节点都会存储数据,会导致非叶子节点存储的索引值会更少,树的高度相对会比B+树高,平均的I/O效率会比较低,所以使用B+树作为索引的数据结构,再加上B+树的叶子节点之间会有指针相连,也方便进行范围查找。上图的data区域两个存储引擎会有不同。
那么,一个B+树的节点中到底存多少个元素合适呢?
其实也可以换个角度来思考B+树中一个节点到底多大合适?
答案是:B+树中一个节点为一页或页的倍数最为合适。因为如果一个节点的大小小于1页,那么读取这个节点的时候其实也会读出1页,造成资源的浪费;如果一个节点的大小大于1页,比如1.2页,那么读取这个节点的时候会读出2页,也会造成资源的浪费;所以为了不造成浪费,所以最后把一个节点的大小控制在1页、2页、3页、4页等倍数页大小最为合适。
那么,Mysql中B+树的一个节点大小为多大呢?
这个问题的答案是“1页”,这里说的“页”是Mysql自定义的单位(其实和操作系统类似),Mysql的Innodb引擎中一页的默认大小是16k(如果操作系统中一页大小是4k,那么Mysql中1页=操作系统中4页),可以使用命令SHOW GLOBAL STATUS like 'Innodb_page_size'; 查看。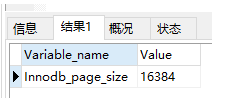
对着上面Mysql中Innodb中对B+树的实际应用(主要看主键索引),可以发现B+树中的一个节点存储的内容是:
非叶子节点:主键+指针
叶子节点:数据
那么,假设我们一行数据大小为1K,那么一页就能存16条数据,也就是一个叶子节点能存16条数据;再看非叶子节点,假设主键ID为bigint类型,那么长度为8B,指针大小在Innodb源码中为6B,一共就是14B,那么一页里就可以存储16K/14=1170个(主键+指针),那么一颗高度为2的B+树能存储的数据为:117016=18720条,一颗高度为3的B+树能存储的数据为:11701170*16=21902400(千万级条)。所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。在查找数据时一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次IO操作即可查找到数据。所以也就回答了我们的问题,1页=16k这么设置是比较合适的,是适用大多数的企业的,当然这个值是可以修改的,所以也能根据业务的时间情况进行调整。
mysql索引原理及优化(二)的更多相关文章
- MySQL索引原理及优化
一.各种数据结构介绍 这一小节结合哈希表.完全平衡二叉树.B树以及B+树的优缺点来介绍为什么选择B+树. 假如有这么一张表(表名:sanguo): (1)Hash索引 对name字段建立哈希索引: 根 ...
- Mysql 索引原理及优化
本文内容主要来源于互联网上主流文章,只是按照个人理解稍作整合,后面附有参考链接. 一.摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引 ...
- (转)Mysql 索引原理及优化
本文内容主要来源于互联网上主流文章,只是按照个人理解稍作整合,后面附有参考链接. 一.摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引 ...
- mysql索引原理及优化(一)
什么是索引 索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-tree的形式保存.如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录.表 ...
- mysql索引原理以及优化
一.常见查找算法: 1.顺序查找: 最基础的查找方法,对比每一个元素进行查找.在数据量很大的时候效率相当的慢. 数据结构:有序或者无需的队列 时间复杂度:O(n) 2.二分查找: 二分查找首先要求数组 ...
- mysql索引原理及优化(三)
B+Tree原理详解 MyISAM中的 B+Tree (非聚簇索引) MYISAM中叶子节点的数据区域存储的是数据记录的地址 主键索引 辅助索引 MyISAM存储引擎在使用索引查询数据时,会先根据索引 ...
- mysql索引原理及优化(四)
聚簇索引和非聚簇索引 分析了MySQL的索引结构的实现原理,然后我们来看看具体的存储引擎怎么实现索引结构的,MySQL中最常见的两种存储引擎分别是MyISAM和InnoDB,分别实现了非聚簇索引和聚簇 ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- (转)MySQL索引原理及慢查询优化
转自美团技术博客,原文地址:http://tech.meituan.com/mysql-index.html 建索引的一些原则: 1.最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到 ...
随机推荐
- iOS学习——(转)解决iOS App打包后dSYM文件找不到的问题
dSYM文件缺失通常有两种情况**: 情况一:配置错误导致打包时没有生成dSYM文件 针对这种情况,通常是因为Project -> Build Settings下的Debug Informati ...
- idea安装与注册码破解
idea安装与注册码破解 https://www.cnblogs.com/jajian/p/7989032.html
- AM335X有关MMC的启动参数问题分析
AM335X有关MMC的启动参数问题分析 一. 问题来源 硬件平台:AM335X芯片 SDK版本:ti-processor-sdk-linux-am335x-evm-03.00.00.04-Linux ...
- FriendlyCore overlayfs 挂载方式
友善 friendlycore 挂载 overlayfs 过程: uboot 引导系统启动的时候加载 ramdisk.img 这个 cpio 格式的 initrd(虚拟文件系统). 注意: ramd ...
- Unicode原理和互转中文
代码点Unicode标准的本意很简单:希望给世界上每一种文字系统的每一个字符,都分配一个唯一的整数,这些整数叫做代码点(Code Points). 代码空间所有的代码点构成一个代码空间(Code Sp ...
- G1垃圾收集器系统化说明【官方解读】
还是继续G1官网解读,上一次已经将这三节的东东读完了,如下: 所以接一来则继续往下读: Reviewing Generational GC and CMS[回顾一下CMS收集器] The Concur ...
- ActiveMQ-启动服务异常
如果报这种异常: Caused by: java.io.IOException: Failed to bind to server socket: tcp://0.0.0.0:61616?maximu ...
- Dict.Count
static void Main(string[] args) { Dictionary<string, string> paraNameValueDict = new Dictionar ...
- SparkSQL读写外部数据源-jext文件和table数据源的读写
object ParquetFileTest { def main(args: Array[String]): Unit = { val spark = SparkSession .builder() ...
- 【转】RabbitMQ三种Exchange模式
[转]RabbitMQ三种Exchange模式 RabbitMQ中,所有生产者提交的消息都由Exchange来接受,然后Exchange按照特定的策略转发到Queue进行存储 RabbitMQ提供了四 ...