SketchyGAN: Towards Diverse and Realistic Sketch to Image Synthesis - 1 - 论文学习
https://github.com/wchen342/SketchyGAN
Abstract
从人体草图中合成逼真的图像是计算机图形学和视觉学中的一个具有挑战性的课题。现有的方法要么需要精确的边缘图,要么依赖于检索现有的照片。在这项工作中,我们提出了一种新颖的生成对抗网络(GAN)方法,它综合了包括摩托车、马和沙发在内的50个类别的可信图像。我们展示了一种完全自动化的草图数据扩充技术,并说明扩充的数据对我们的任务是有帮助的。提出了一种既适用于生成器又适用于判别器的新型网络结构块,通过注入多尺度的输入图像来改善信息流动。与最先进的图像转换方法相比,我们的方法生成更真实的图像,并获得更高的Inception分数

1. Introduction
我们怎样才能快速地想象出一个场景或物体?最简单的方法之一是画一个草图。与摄影相比,草图不需要任何捕捉设备,也不局限于对现实的忠实采样。然而,草图往往是简单和不完美的,因此从新手草图中合成逼真的图像是具有挑战性的。基于草图的图像合成可以使非技术人员在没有显著的艺术技能或图像合成领域的专业知识的情况下创建现实的图像。这通常是困难的,因为草图是稀疏的,而且新手的人类艺术家不能画出精确反映物体边界的草图。由草图合成的真实图像应该尽可能地尊重艺术家的意图,但为了保留在自然的图像流形上,可能需要偏离粗糙的笔画。在过去的30年里,最流行的基于草图的图像合成技术是由图像检索方法驱动的,如Photosketcher[13]和Sketch2photo[5]。这种方法通常需要精心设计的特征表示,这些特征表示在草图和照片之间是不变的。它们还涉及复杂的后处理过程,如图形切割合成和梯度域混合,以使合成的图像逼真。
最近出现的深度卷积神经网络[33,32,18]为图像合成提供了诱人的方法,其中生成对抗网络(GANs)[14]显示了巨大的潜力。GAN将它的训练定义为生成器和判别器之间的零和游戏。判别器的目标是判断给定的图像是真实的还是假的,而生成器试图生成真实的图像,这样判别器就会将它们误分类为真实的。基于草图的图像合成可以表述为基于输入草图的图像转换问题。有几种方法使用GANs将图像从一个域转换到另一个域[25,62]。然而,没有一个是专门为从草图合成图像而设计的。
在本文中,我们提出了一种基于gan的、端到端可训练的图形合成方法SketchyGAN,它可以从50个类生成对象。输入是一个草图说明一个对象,输出是一个现实的图像,包含有着相似姿势的对象。这是一个挑战,因为:
- (i)配对的照片和草图很难获得,所以没有庞大的数据库可供学习。
- (ii)目前还没有建立针对不同类别的草图到图像合成的神经网络方法。以往的工作训练模型为单一或少数类别[28,50]。
我们解决了第一个挑战,通过扩展Sketchy数据库[49],它包含了近75000个实际的人体草图和照片对,以及一个更大的边缘图和照片配对数据集。这个增强数据集是从50个类别的2299,144张Flickr图片中收集来的,并从中生成他们的边缘图。在训练过程中,我们调整了边缘映射图像和草图图像对之间的比例,使得网络可以逐步地将其知识从边缘图像合成转移到草图图像合成。
对于第二个挑战,我们建立了一个基于gan的模型,以输入草图为条件,加入几个额外的损失项来提高合成质量。我们还引入了一种新的构建块,称为掩码残差单元(MRU),它有助于生成更高质量的图像。该块接受一个额外的图像输入,并利用其内部掩码来动态地决定网络的信息流。通过连接这些块,我们可以输入一个不同的规模的图像金字塔。我们证明了这种结构在图像合成任务上比单纯的卷积方法和ResNet块有更好的性能。我们的主要贡献如下:
- 提出了Sketchy,一种草图到图像生成的深度学习方法。与以前的非参数方法不同,我们在测试时不进行图像检索。与以前的深度图像转换方法不同,我们的网络不学习直接复制输入的边缘图(即进行有效地着色,而不是将草图转换成照片)。我们的方法能够从50个不同的类别中生成可信的对象。基于草图的图像合成是非常具有挑战性的,我们的结果通常不具有真实感,但我们证明了与现有的深度生成模型相比,质量有所提高。
- 我们演示了一种用于草图数据的数据扩充技术,解决了缺乏足够的人工标注的训练数据的问题。
- 我们制定了一个具有额外目标函数和新的网络构建块的GAN模型。我们表明,所有这些都是有利于我们的任务的,缺乏其中任何一个将降低我们结果的质量。
2. Related Work
基于草图的图像检索和合成。基于草图的图像检索已有大量的研究工作[11,12,21,2,3,55,23,22,26,54,38,56,34]。大多数方法使用单词表示和边缘检测来构建跨两个域的(理想情况下)不变的特性。常见的缺点包括无法执行细粒度的检索,以及无法从糟糕的草图边缘图映射到照片边界。为了解决这些问题,Yu等人[60]和Sangkloy等人[49]训练深度卷积神经网络(deep convolutional neural network, CNNs)将草图和照片联系起来,将基于草图的图像检索作为学习后的特征嵌入空间的搜索。它们表明,使用CNNs极大地提高了性能,并且能够进行细粒度和实例级检索。除了检索的任务,Sketch2Photo[5]和PhotoSketcher[13]通过组合从给定的草图检索到的对象和背景来合成真实的图像。PoseShop[6]通过允许用户在查询中输入额外的2D框架来合成人物图像,从而使检索更加精确。
基于Sketch的数据集。人类绘制的草图的数据集很少,而且由于收集图纸的工作需要,这些数据集通常很小。最常用的草图数据集之一是TU-Berlin数据集[10],它包含了跨越250个类别的20,000个人体草图。Yu等人的[60]提出了一个带有配对的草图和图像的新的数据集,但只有两类-鞋和椅子。CUHK香港中文大学的Face Sketches[57]亦包括606张由艺术家所画的脸部速写。最新发布的QuickDraw数据集[16]拥有令人印象深刻的5000万张草图。然而,由于10秒钟的时间限制,这些草图非常粗糙。草图缺乏细节,往往只包含标志性的或规范的视图。相比之下,Sketchy数据库[49]有更多更详细的图片,姿势也更多样。它涵盖了125个类别,总共有75,471张草图,涉及12,500件物品。关键的是,它是唯一的配对草图和照片跨越不同类别的实质性数据集,所以我们选择使用这个数据集。
使用GANs进行图像到图像的转换。生成对抗网络(GANs)在生成自然的、真实的图像方面显示了巨大的潜力[15,43]。GANs相对于使用直接优化每个像素的重建误差的方法——这常常导致结果模糊和保守,它使用一个判别器来区分不真实的图像和真实的图像,从而迫使生成器产生更清晰的图像。isa等人[25]的“pix2pix”工作演示了一种使用条件GANs将一个图像转换成另一个图像的简单方法。条件设置也适用于其他图像转换任务,包括草图着色[50],风格转换[59]和域适应[1]任务。与使用条件GANs和成对数据相比,Liu等人在[39]中引入了一个由CoupledGAN[40]和一对变分自编码器[30]组成的无监督图像转换框架。最近,CycleGAN[62]通过加强周期一致性损失,在无监督图像转换方面显示了有希望的结果。
3. Sketchy Database Augmentation
在这一节中,我们将讨论如何使用Flickr图像来扩充Sketchy数据库[49],并合成我们希望的近似人类草图的边缘图。数据集是公开的。第3.2节描述了图像采集、图像内容过滤和类别选择。第3.3节描述了我们的边缘图的合成。第3.4节描述了我们使用增强数据集的方式。
3.1. Edges vs Sketches
图2显示了图像边缘图edges和草图sketches之间的区别:

草图是一组模拟物体的近似边界和内部轮廓的人类绘制的笔画,而边缘图是由机器生成的像素阵列,精确地对应于照片的强度边界。从草图生成照片比从边缘生成要难得多。
与边缘图不同的是,草图并不精确地与物体边界对齐,因此生成模型需要学习空间转换来纠正变形的笔画。
其次,边缘图通常包含更多关于背景和细节的信息,而草图则没有,因此生成模型必须插入更多的信息。
最后,草图可能包含漫画或标志性特征,如图2c中猫脸上的“老虎”条纹,模型必须学会处理。
尽管有这些巨大的差异,对于有限的Sketchy数据库来说,边缘图仍然是一个有价值的补充。
3.2. Data Collection
学习边缘或草图到照片的映射需要大量的训练数据。对于每个类别我们都想要成千上万的图像。ImageNet每个类只有大约1000个图像,而COCO中的照片往往很杂乱,因此他们作为对象草图的范例都并不理想。理想情况下,我们希望照片有一个主要对象,就像Sketchy数据库照片一样。因此,我们通过将类别名称作为关键字查询来使用Flickr API直接从Flickr收集图像,每个类别都收集了100,000张图片,并按“相关性”进行排序。使用了两个不同的模型用于过滤不相关的图像。我们使用Inception-ResNet-v2网络[52]来过滤来自38 ImageNet[47]类别的与Sketchy重叠的图像,使用Single Shot MultiBox Detector[41]来检测在18 COCO[37]类别中包含着一个对象的图像是否与Sketchy重叠。对于SSD,被检测对象的边界框必须覆盖图像区域的5%以上,否则图像将被丢弃。过滤之后,我们得到了一个数据集,平均每个ImageNet类别有46,265张图片,每个COCO类别有61,365张图片。在本文的其余部分,我们使用了56个可用类别中的50个,排除了通常以人为主要对象的6个类别。被排除在外的有竖琴、小提琴、雨伞、萨克斯管、球拍和小号。
3.3. Edge Map Creation
我们使用边缘检测和几个后处理步骤来获得类似草图的边缘图。步骤如图3所示:

b) 第一步是使用完整嵌套的边缘检测(HED)[58]来检测边缘,如Isola等人的[25]。
c\d) 在对输出进行二值化并细化所有边缘之后[61],我们对孤立的像素进行清除,并删除小的连接组件。
e) 接下来,我们在所有边缘上设置一个阈值,进一步减少边缘碎片的数量。
f) 剩下的spur被移除。
g) 由于边缘非常稀疏,我们为每个边缘映射计算一个无符号的欧几里德距离场来获得一个稠密的表示(参见图3g)。在最近的三维形状恢复研究中也使用了类似的距离场表示[53,17]。我们还计算了Sketchy数据库中的距离场。
3.4. Training Adaptation from Edges to Sketches
因为我们的最终目标是构建一个从草图生成图像的网络,所以有必要在边缘图和草图上对网络进行训练。为了简化训练过程,我们使用了一种策略,将输入从边缘图逐渐转换为草图图:在训练开始时,训练数据主要是成对的图像和边缘图。在训练过程中,我们慢慢地增加草图-图像对的比例。令imax为最大训练迭代次数,icur为当前迭代次数,则草图和边缘图在当前迭代中的比例为:
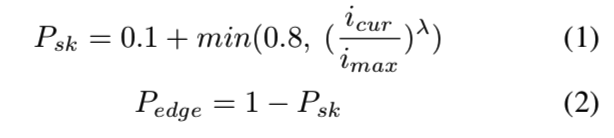
λ是一个可调的超参数,用来指示草图比例的增长速度。在我们的实验中我们使用λ= 1。很容易看出,Psk从0.1缓慢增长到0.9。利用该训练策略,我们消除了在边缘图单独预训练的需要,使整个训练过程统一起来。我们将此方法与先对边缘图进行训练,然后再对草图进行微调的方法相比较。我们发现,相对于从边缘到草图的渐变(6.73 vs . 7.90),离散的预训练和随后的微调会导致测试集中的Inception分数较低。
4. SketchyGAN
在本节中,我们提出了一个生成对抗网络框架,它将输入草图转换为图像。我们的GAN学习了一个从输入草图x到输出图像y的映射,即:x→y。这个GAN有两个部分,一个生成器G和一个判别器D。第4.1节介绍了掩码残差单元(Residual Unit, MRU),第4.2节描述了网络结构,第4.3节讨论了目标函数。
4.1. Masked Residual Unit (MRU)
我们介绍了一个网络模块,它允许一个ConvNet在一个输入图像上条件反复。该模块使用一个学习过的内部掩模,有选择地从输入图像中提取新特征,并与迄今为止网络计算出的特征图相结合。我们称这个模块为掩码残差单元或MRU。
图6显示了掩码单元(MRU)的结构:

与DCGAN[46]和ResNet生成架构的定性和定量比较可以在5.3节中找到。MRU块有两个输入:输入特征图xi和图像I,输出特征图yi。为了方便起见,我们只讨论输入和输出具有相同空间维数的情况。令[·,·]为串联,Conv(x)为x上的卷积,f(x)为激活函数。我们首先要将输入图像I中的信息合并到输入特征映射xi中。一种幼稚的方法是沿着特征深度维度将它们串联起来并执行卷积:
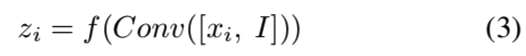
然而,如果块能够在接收到新图像时决定它希望保留多少信息,那就更好了。所以我们采用以下方法:
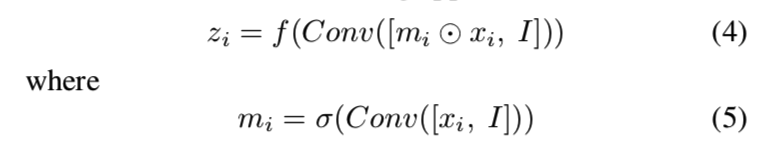
mi是输入特征图上的掩码。可以在这里堆叠多个卷积层以提高性能。然后,我们希望动态地组合来自新卷积的特征图zi和原始输入特征图xi的信息,因此我们使用另一个掩码:
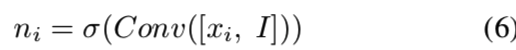
用来将输入特征图和新的特征图连接起来,得到最后的输出:

方程7中的第二项是残差连接。由于有确定信息流的内部掩码,我们称这种结构为掩码残差单元。我们可以将多个这样的单元堆叠起来,重复输入不同的比例的相同的图像,这样网络就可以在其计算路径上动态地从输入图像中检索信息。
MRU公式类似于门控递归单元(GRU)[7]。然而,我们的动机是不同的,有几个关键的区别:
- 1) 我们的动机是重复输入相同的图像,以改善信息流。GRU被设计用来修饰递归神经网络中的消失梯度。
- 2) GRU单元是周期性的,因此部分输出被反馈回同一个单元,而MRU块是级联的,因此前一个块的输出被反馈到下一个块。
- 3) GRU对每个步骤共享权重,因此它只能接收固定长度的输入。没有两个MRU块共享权值,因此我们可以像普通的卷积层一样缩小或扩大输出特征图的大小。
4.2. Network Structure
我们完整的网络结构如图5所示:

该发生器采用编码器-解码器结构。编码器和解码器都是用MRU块构建的,在这些MRU块中,草图被重新调整大小并输入到路径上的每个MRU块中。在图9的最佳结果中,我们还在编码器和解码器块之间应用了跳跃连接,因此编码器块的输出特征图将连接到相应解码器块的输出。判别器也是用MRU块建造的,但是在空间尺寸上会缩小。在判别器的最后,我们输出两个logits,一个用于GAN loss,一个用于分类 loss。
4.3. Objective Function
设x、y为图像或草图,z为噪声矢量,c为类标签,我们的GAN目标函数可以表示为:
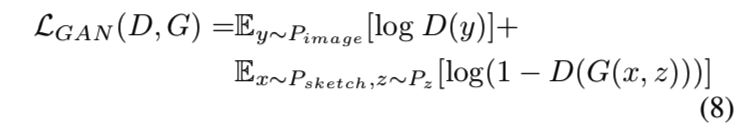
而生成器LGAN (G)的目标是最小化第二项。
结果表明,给出模型侧信息可以提高生成图像的质量,因此我们在生成器中使用条件Instance Normalization[44],并传递输入草图的标签labels。此外,我们让判别器从它看到的图像中预测类标签。判别器的辅助分类损失最大化预测标签与真实标签之间的对数似然值:
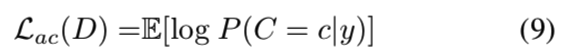
生成器则最大化与固定的判别器相同的对数似然Lac(G) = Lac(D)。
由于我们已经有了成对的图像数据,我们能够通过生成的图像与真实图像之间的L1距离对网络进行直接监督:
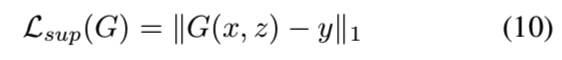
然而,直接最小化生成图像与真实图像之间的L1损失会抑制多样性,因此我们增加了感知损失来鼓励网络生成多样化的图像[8,27,4]。我们使用来自Inception-V4[52]的四个中间层来计算感知损失。让φi作为Inception模型中一层的过滤器的响应。我们将生成器上的感知损失定义为:

为了进一步鼓励多样性,我们将高斯噪声连接到生成器瓶颈处的特征图上。以往的研究得出结论,有条件的GANs容易完全忽略噪声[25]或由于噪声[45]而产生更差的结果。简单的多样性损失为:

其将提高生成图像的质量和多样性。其解释很简单:z1和z2是一对不同的噪声矢量条件作用于相同的图像,那么生成器应该输出一对有着轻微不同的图像。
我们完整的生成器和判别去的损失是:

其中判别器使方程13值最大,发生器使方程14值最小。在实践中,我们使用DRAGAN loss[31]来稳定训练,使用focal loss[36]作为分类损失。
5. Experiments
5.1. Experiment settings
数据集分割. 我们从Sketchy的训练分割中选取了50个类别的草图-图像对作为基本训练数据,并使用边缘映射-图像对进行扩充。在接下来的小节中,我们将来自Sketchy数据库的数据称为“Sketchy”,而使用边缘图进行Sketchy增强的数据称为“augmented Sketchy”。由于我们只对草图到图像的合成感兴趣,所以所有的模型都是在Sketchy的测试分割上进行测试的。不管原始的长宽比如何,所有的图像都被调整为64×64。草图和边缘图都被转换成距离场。
实现细节. 在所有实验中,除了图9使用32的批大小外,我们都使用8的批大小。我们在训练中使用随机的水平翻转。我们使用Adam优化器[29],设置生成器的初始学习率为0.0001,判别器的初始学习率为0.0002[20]。
评价指标. 对于我们的图像合成任务,我们使用Inception分数[48]来衡量合成图像的质量。Inception分数背后的直觉是一个好的合成图像应该有容易被现成的识别系统识别的对象。除了Inception分数,我们还进行了一个感知的研究,评估生成的图像有多真实,以及它们对输入草图有多忠实。
5.2. Comparison to Baselines
我们的比较集中在流行的pix2pix及其变体上。除了第一个模型外,所有的模型都接受了300k迭代的训练。我们包括三个基线:
- pix2pix on Sketchy. 这是最简单的模型。我们直接采用作者的pix2pix代码,并在Sketchy的50个类别中进行训练。因为我们发现100k迭代后图像质量停止改善,所以我们在150k迭代早期停止并报告结果。
- pix2pix on Augmented Sketchy. 在这个模型中,我们在图像-边缘图和图像-草图对上训练了pix2pix,就像我们在我们的方法中所做的那样。网络结构和损失函数保持不变。
- Label-Supervised pix2pix on Augmented Sketchy. 在该模型中,我们对pix2pix进行了修改,通过条件Instance Normalization将类标签labels传递给生成器,并在判别器中加入了辅助的分类损失。这是一个更强的基线,因为标签信息有助于网络确定对象类型,从而提高生成的图像质量[15,44]。
Inception分数的比较可以在表1中找到:

可视化结果可以在图7中找到:

我们的观察结果如下:
- (i) 在Sketchy上训练的pix2pix是失败的,产生无法识别的色块。模型无法从草图转换成图像。由于pix2pix已经成功地实现了边缘到图像的转换,这暗示着从草图到图像的合成更加困难。
- (ii) 在经过增强的Sketchy上训练的pix2pix表现稍好,开始产生物体的大致形状。这表明边缘图有助于训练。
- (iii) 在Augmented Sketchy上的标签监督的pix2pix比前两个基线更好。它更经常地给对象正确着色,并开始生成一些有意义的背景。结果仍然是模糊的,并且可以观察到许多人为因素。
- (iv) 与基线相比,我们的方法生成更清晰的图像,获得正确的对象颜色,在对象上放置更详细的纹理,并输出有意义的背景。整个画面也更加丰富多彩。
5.3. Component Analysis
在这里,我们分析模型的哪个部分更重要。我们解耦我们的目标函数并分析它的每个部分的影响。所有的模型都在有着相同的参数集的增强的Sketchy上训练。具体比较见表5:

首先去除GAN损失和判别器(即-GAN)。结果是令人惊讶的糟糕,因为图像非常模糊。这与isa等人的观察结果一致。
接下来,我们删除了辅助损失,并用Batch Normalization[24]代替条件Instance Normalization。这导致了图像质量的显著下降,以及错误的颜色和错位的纹理。这表明类信息帮助很大,这是有意义的,因为我们从单个模型生成了50个类别。
然后我们去除L1损失和感知缺失。我们发现它们对图像质量也有很大的影响。从样本图像我们可以看到,模型使用了错误的颜色,对象边界是不现实的或有缺失得。
最后,我们去除多样性损失,这样做也会稍微降低图像质量。这可能与我们如何应用这种多样性损失有关,其迫使生成器生成真实但不同的图像对。这鼓励了泛化,因为生成器需要找到一个解决方案,即当给定不同的噪声向量时,只在无约束区域(例如背景)对图像进行更改。
MRU和其他结构的对比. 为了证明MRU块的有效性,我们比较了MRU、ResNet、级联细化网络(CRN)[4]和DCGAN结构在图像合成任务中的性能。我们训练了几个额外的模型:
- 一个使用改进的ResNet块[19],这是用于生成器和判别器中的,在[18]发布的最佳变体;
- 一是弱基线,采用DCGAN结构;
- 一个在生成器中使用CRN代替MRU;
- 一个是仅使用了GAN损失和ACGAN损失的MRU模型。
我们通过减少MRU中的特征深度来保持MRU模型和ResNet模型的参数数量大致相同。详细的参数计数见表2:
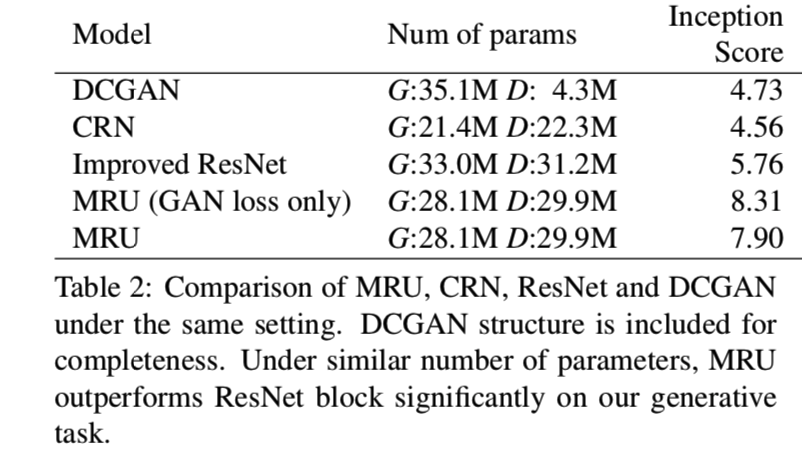
从视觉质量和Inception分数来看,MRU模型比ResNet和CRN模型生成更好的图像,我们证明即使只使用标准的GAN损失,MRU也比其他结构有更好的表现。从图8中我们注意到MRU模型倾向于产生更高质量的前景对象。这可能是由于MRU的内部掩码作为一种注意力机制,导致网络选择性地聚焦于主要对象。

在我们的任务中,这是有帮助的,因为我们主要对从草图生成特定对象感兴趣。
5.4. Human Evaluation of Realism and Faithfulness
我们做了两次人工评估来衡量我们的模型在真实性和对输入草图的忠实度方面与基线的比较。在“忠实度”测试中,参与者可以看到pix2pix、SketchyGAN或使用在Sketchy数据库[49]中学习到的表征进行1-最近邻检索的输出。在每个图像中,参与者还会看到9个相同类别的随机草图,其中一个是实际的输入/查询草图。参与者被要求选择得到输出图像的草图。然后我们计算参与者选择正确的输入草图的频率,因此较高的正确选择率表明模型产生了更“忠实”的输出。
在“真实感”测试中,参与者会看到pix2pix变体和SketchyGAN的输出成对比较,同时还会看到相应的输入草图。参与者被要求选择他们认为更真实的图像。对于每个模型,我们计算参与者认为它更真实的频率。图像检索基线不用于评估真实性,因为它只返回现有的、真实的照片。
我们进行了696条“忠实”测试,348条“真实”测试。结果表明,SketchyGAN比检索模型更忠实,但不如pix2pix忠实,pix2pix更常精确地保存输入的边缘(表3):

与此同时,比起pix2pix变体,SketchyGAN被认为是更真实的(表4):

结果符合我们的目标,我们的模型应该尊重输入草图的意图,但同时在必要时偏离笔画以产生真实的图像。
6. Conclusion
在这项工作中,我们提出了一种新的方法来解决草图到图像的合成问题。鉴于草图的性质,这个问题具有挑战性,这就引入了一种深度生成模型,这种模型在草图合成中很有前景。我们介绍了一种用于草图-图像对的数据增强技术,以鼓励这方面的研究。所演示的GAN框架可以合成比现有生成模型更真实的图像,生成的图像也更多样。目前,GANs的研究主要集中在寻找更好的概率度量作为目标函数,但在GANs中寻找更好的网络结构的研究工作很少。我们为我们的生成任务提出了一个新的网络结构,我们证明它比现有的结构表现得更好。
局限性. 理想情况下,我们希望我们的结果既真实又忠实于输入草图的意图的。对于许多草图,我们都不能达到其中一个或两个目标。结果通常不是逼真的,也没有足够高的分辨率。有时过于忠实于草图又会失去真实感 —— 例如瘦马腿这种紧密遵循着糟糕绘制的输入边界的结果(如图9):

在其他情况下,我们所做的偏离用户草图,但是使输出更真实(如在图1中的摩托车和飞机,在图9中的蘑菇,教堂,喷泉,和城堡),当然仍然尊重输入草图中对象的姿势和位置。这是更可取的。人类的意图是很难学习的,SketchyGAN的失败,即太字面上地对待输入的草图,当然这可能是由于缺乏草图-照片训练对。尽管我们的结果还不具有真实感,但我们认为它比以前的方法有了很大的改进。
SketchyGAN: Towards Diverse and Realistic Sketch to Image Synthesis - 1 - 论文学习的更多相关文章
- CVPR2018资源汇总
CVPR 2018大会将于2018年6月18~22日于美国犹他州的盐湖城(Salt Lake City)举办. CVPR2018论文集下载:http://openaccess.thecvf.com/m ...
- sketch 相关论文
sketch 相关论文 Sketch Simplification We present a novel technique to simplify sketch drawings based on ...
- Sketch 画原型比 Axure 好用吗?为什么?
对工具而言,个人觉得没有说哪个工具好用不好用之分,更重要一点,做设计的来讲什么时候用什么工具来提高工作效率,这个最重要.下面我也来讲讲这二款工具的不同之处: Axure算是原型工具里的 Old Sch ...
- Self-Supervised Representation Learning
Self-Supervised Representation Learning 2019-11-11 21:12:14 This blog is copied from: https://lilia ...
- matplotlib 入门之Sample plots in Matplotlib
文章目录 Line Plot One figure, a set of subplots Image 展示图片 展示二元正态分布 A sample image Interpolating images ...
- Elsevier系旗下期刊论文投稿流程
目录 1.上传文件需求 2.注册账号和填写相关信息 3.以作者身份登入 4.开始提交论文:点击submit New Manuscript 5.选择论文类型:一般是科技长文Full Length Art ...
- 关于Cewu Lu等的《Combining Sketch and Tone for Pencil Drawing Production》一文铅笔画算法的理解和笔录。
相关论文的链接:Combining Sketch and Tone for Pencil Drawing Production 第一次看<Combining Sketch and Tone f ...
- 【APP设计利器】Sketch 41 Mac中文破解版(含汉化插件)
Sketch是一款拥有美观界面和强大功能适用于所有设计师的专业矢量绘图工具.它旨在为美术设计师创造出一款更优秀的作品,不是复制品,而是提升品.Sketch简约的设计是基于无限的规模和层次的绘图空间,免 ...
- 【产品 & 设计】入门 - 工具篇 - Sketch + Skala Preview
前言 做产品和设计快 1 年了,积累了一点经验分享一下 —— 抛砖引玉,欢迎交流. 声明 欢迎转载,但请保留文章原始出处:) 博客园:http://www.cnblogs.com 农民伯伯: ht ...
随机推荐
- Linux下设置Nginx开机自启
1.本地环境 [root@dev ~]#cat /etc/redhat-release CentOS Linux release 7.5.1804 (Core) 2.在/etc/init.d创建ngi ...
- k8s 初识pod (二)
kubernetes中调用pod到哪个节点上是无关紧要的,但由于实际情况,每台node的硬件环境不一致,所以某些情况要求将不同pod调到指定节点上运行.也可以通过label实现. kubectl la ...
- SaltStack--快速入门
saltstack快速入门 saltstack介绍 Salt,一种全新的基础设施管理方式,部署轻松,在几分钟内可运行起来,扩展性好,很容易管理上万台服务器,速度够快,服务器之间秒级通讯 主要功能远程执 ...
- php的选择排序
往前. <?php /** * 选择排序 * 工作原理是每次从待排序的元素中的第一个元素设置为最小值, * 遍历每一个没有排序过的元素,如果元素小于现在的最小值, * 就将这个元素设置成为最小值 ...
- hadoop安装教程,分布式配置 CentOS7 Hadoop3.1.2
安装前的准备 1. 准备4台机器.或虚拟机 4台机器的名称和IP对应如下 master:192.168.199.128 slave1:192.168.199.129 slave2:192.168.19 ...
- 缺jar包异常:java.lang.NoClassDefFoundError: org/springframework/core/convert/support/PropertyTypeDescriptor
严重: StandardWrapper.Throwable java.lang.NoClassDefFoundError: org/springframework/core/convert/suppo ...
- ArcGIS Server 注册托管数据库
需要已经安装好ArcGIS for Desktop.ArcGIS for Server和ArcSDE,并且已经创建了地理数据库 我试了用管理网站添加,总是不成功,后来用ArcCatalog添加成功.这 ...
- 金生芳-实验十四 团队项目评审&课程学习总结
实验十四 团队项目评审&课程学习总结 项目 内容 这个作业属于哪个课程 [教师博客主页链接] 这个作业的要求在哪里 [作业链接地址] 作业学习目标 (1)掌握软件项目评审会流程(2)反思总结课 ...
- Arthas - 开源的java诊断工具,非常有用
常用命令 help 查看帮助 help COMMAND 查看指定命令的详细帮助 COMMAND -h 查看指定命令的详细帮助 double tab 查看支持的所有命令 dashboard 查看线程JV ...
- 跟UI自动化测试有关的技术
大家都知道,针对UI的自动化技术一般要支持下列的东西: 1. 识别窗口 能够识别尽量多的窗口种类,支持尽量多的UI技术.比如Win32.WinForm.WPF以及WebPage(这个比较特殊,确切 ...