sqlalchemy(2)
orm介绍
orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。
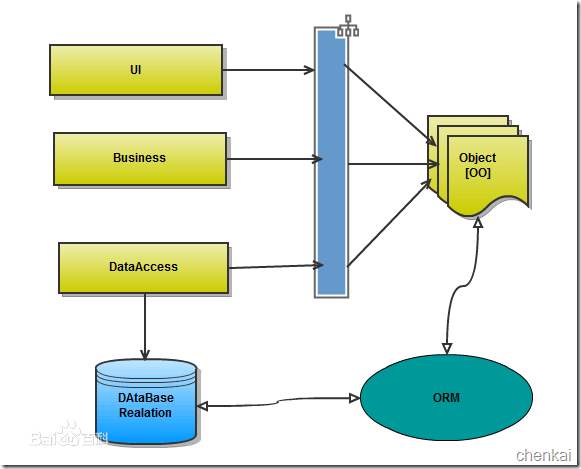
orm的优点:
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。
- ORM使我们构造固化数据结构变得简单易行。
缺点:
- 无可避免的,自动化意味着映射和关联管理,代价是牺牲性能(早期,这是所有不喜欢ORM人的共同点)。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
sqlalchemy
在Python中,最有名的ORM框架是SQLAlchemy。用户包括openstack\Dropbox等知名公司或应用,主要用户列表http://www.sqlalchemy.org/organizations.html#openstack
sqlalchemy的基本使用
创建表结构
mport sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String engine = create_engine("mysql+pymysql://root:alex3714@localhost/testdb",
encoding='utf-8', echo=True) Base = declarative_base() #生成orm基类 class User(Base):
__tablename__ = 'user' #表名
id = Column(Integer, primary_key=True)
name = Column(String(32))
password = Column(String(64)) Base.metadata.create_all(engine) #创建表结构
创建数据
Session_class = sessionmaker(bind=engine) #创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
Session = Session_class() #生成session实例 user_obj = User(name="alex",password="alex3714") #生成你要创建的数据对象
print(user_obj.name,user_obj.id) #此时还没创建对象呢,不信你打印一下id发现还是None Session.add(user_obj) #把要创建的数据对象添加到这个session里, 一会统一创建
print(user_obj.name,user_obj.id) #此时也依然还没创建 Session.commit() #现此才统一提交,创建数据
查询

my_user = Session.query(User).filter_by(name="alex").first()
print(my_user) #输出
<__main__.User object at 0x105b4ba90> print(my_user.id,my_user.name,my_user.password) #输出
alex alex3714
不过刚才上面的显示的内存对象对址你是没办法分清返回的是什么数据的,除非打印具体字段看一下,如果想让它变的可读,只需在定义表的类下面加上这样的代码
def __repr__(self):
return "<User(name='%s', password='%s')>" % (
self.name, self.password)
修改
my_user = Session.query(User).filter_by(name="alex").first() my_user.name = "Alex Li" Session.commit()
回滚
my_user = Session.query(User).filter_by(id=1).first()
my_user.name = "Jack" fake_user = User(name='Rain', password='')
Session.add(fake_user) print(Session.query(User).filter(User.name.in_(['Jack','rain'])).all() ) #这时看session里有你刚添加和修改的数据 Session.rollback() #此时你rollback一下 print(Session.query(User).filter(User.name.in_(['Jack','rain'])).all() ) #再查就发现刚才添加的数据没有了。 # Session
# Session.commit()
获取所有数据
print(Session.query(User.name,User.id).all() )
多条件查询
objs = Session.query(User).filter(User.id>0).filter(User.id<7).all()
统计
Session.query(User).filter(User.name.like("Ra%")).count()
分组
from sqlalchemy import func
print(Session.query(func.count(User.name),User.name).group_by(User.name).all() )
外键关联
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship class Address(Base):
__tablename__ = 'addresses'
id = Column(Integer, primary_key=True)
email_address = Column(String(32), nullable=False)
user_id = Column(Integer, ForeignKey('user.id')) user = relationship("User", backref="addresses") #这个nb,允许你在user表里通过backref字段反向查出所有它在addresses表里的关联项 def __repr__(self):
return "<Address(email_address='%s')>" % self.email_address
创建关联对象
obj = Session.query(User).filter(User.name=='rain').all()[0]
print(obj.addresses) obj.addresses = [Address(email_address="r1@126.com"), #添加关联对象
Address(email_address="r2@126.com")] Session.commit()
反查
obj = Session.query(User).first()
for i in obj.addresses: #通过user对象反查关联的addresses记录
print(i) addr_obj = Session.query(Address).first()
print(addr_obj.user.name) #在addr_obj里直接查关联的user表
连表查询
ret=Session.query(User,Address).filter(User.id==Address.id).all()
print(ret)
多外键关联
from sqlalchemy import Integer, ForeignKey, String, Column
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship Base = declarative_base() class Customer(Base):
__tablename__ = 'customer'
id = Column(Integer, primary_key=True)
name = Column(String) billing_address_id = Column(Integer, ForeignKey("address.id"))
shipping_address_id = Column(Integer, ForeignKey("address.id")) billing_address = relationship("Address", foreign_keys=[billing_address_id])
shipping_address = relationship("Address", foreign_keys=[shipping_address_id]) class Address(Base):
__tablename__ = 'address'
id = Column(Integer, primary_key=True)
street = Column(String)
city = Column(String)
state = Column(String)
多对多关系
多对多创建
#一本书可以有多个作者,一个作者又可以出版多本书 from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker Base = declarative_base() book_m2m_author = Table('book_m2m_author', Base.metadata,
Column('book_id',Integer,ForeignKey('books.id')),
Column('author_id',Integer,ForeignKey('authors.id')),
) class Book(Base):
__tablename__ = 'books'
id = Column(Integer,primary_key=True)
name = Column(String(64))
pub_date = Column(DATE)
authors = relationship('Author',secondary=book_m2m_author,backref='books') def __repr__(self):
return self.name class Author(Base):
__tablename__ = 'authors'
id = Column(Integer, primary_key=True)
name = Column(String(32)) def __repr__(self):
return self.name Session_class = sessionmaker(bind=engine) #创建与数据库的会话session class ,注意,这里返回给session的是个class,不是实例
s = Session_class() #生成session实例 b1 = Book(name="跟Alex学Python")
b2 = Book(name="跟Alex学把妹")
b3 = Book(name="跟Alex学装逼")
b4 = Book(name="跟Alex学开车") a1 = Author(name="Alex")
a2 = Author(name="Jack")
a3 = Author(name="Rain") b1.authors = [a1,a2]
b2.authors = [a1,a2,a3] s.add_all([b1,b2,b3,b4,a1,a2,a3]) s.commit()
查询数据
print('--------通过书表查关联的作者---------')
book_obj = s.query(Book).filter_by(name="跟Alex学Python").first()
print(book_obj.name, book_obj.authors)
print('--------通过作者表查关联的书---------')
author_obj =s.query(Author).filter_by(name="Alex").first()
print(author_obj.name , author_obj.books)
s.commit()
输出如下:
--------通过书表查关联的作者---------
跟Alex学Python [Alex, Jack]
--------通过作者表查关联的书---------
Alex [跟Alex学把妹, 跟Alex学Python]
多对多删除
通过书删除作者
author_obj =s.query(Author).filter_by(name="Jack").first() book_obj = s.query(Book).filter_by(name="跟Alex学把妹").first() book_obj.authors.remove(author_obj) #从一本书里删除一个作者
s.commit()
直接删除作者
author_obj =s.query(Author).filter_by(name="Alex").first()
# print(author_obj.name , author_obj.books)
s.delete(author_obj)
s.commit()
sqlalchemy(2)的更多相关文章
- sqlalchemy学习
sqlalchemy官网API参考 原文作为一个Pythoner,不会SQLAlchemy都不好意思跟同行打招呼! #作者:笑虎 #链接:https://zhuanlan.zhihu.com/p/23 ...
- tornado+sqlalchemy+celery,数据库连接消耗在哪里
随着公司业务的发展,网站的日活数也逐渐增多,以前只需要考虑将所需要的功能实现就行了,当日活越来越大的时候,就需要考虑对服务器的资源使用消耗情况有一个清楚的认知. 最近老是发现数据库的连接数如果 ...
- 冰冻三尺非一日之寒-mysql(orm/sqlalchemy)
第十二章 mysql ORM介绍 2.sqlalchemy基本使用 ORM介绍: orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似pyt ...
- Python 【第六章】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度 ...
- SQLAlchemy(一)
说明 SQLAlchemy只是一个翻译的过程,我们通过类来操作数据库,他会将我们的对应数据转换成SQL语句. 运用ORM创建表 #!/usr/bin/env python #! -*- coding: ...
- sqlalchemy(二)高级用法
sqlalchemy(二)高级用法 本文将介绍sqlalchemy的高级用法. 外键以及relationship 首先创建数据库,在这里一个user对应多个address,因此需要在address上增 ...
- sqlalchemy(一)基本操作
sqlalchemy(一)基本操作 sqlalchemy采用简单的Python语言,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型. 安装 需要安装MySQLdb pip install ...
- python SQLAlchemy
这里我们记录几个python SQLAlchemy的使用例子: 如何对一个字段进行自增操作 user = session.query(User).with_lockmode('update').get ...
- Python-12-MySQL & sqlalchemy ORM
MySQL MySQL相关文章这里不在赘述,想了解的点击下面的链接: >> MySQL安装 >> 数据库介绍 && MySQL基本使用 >> MyS ...
- 20.Python笔记之SqlAlchemy使用
Date:2016-03-27 Title:20.Python笔记之SqlAlchemy使用 Tags:python Category:Python 作者:刘耀 博客:www.liuyao.me 一. ...
随机推荐
- Python面试题分享——图迹信息科技
本帖最后由 逆风TO 于 2019-5-23 14:25 编辑 公司名称:西安图迹信息科技有限公司 公司地址:锦业路69号创业研发园瞪羚谷A座9层 主营概况:2013年成立,大数据应用工程中心,为五大 ...
- 面向对象程序设计(JAVA) 第11周学习指导及要求
2019面向对象程序设计(Java)第11周学习指导及要求 (2019.11.8-2018.11.11) 学习目标 理解泛型概念: 掌握泛型类的定义与使用: 掌握泛型方法的声明与使用: 掌握泛型接 ...
- 使用Fiddler模拟弱网测试教程
一.下载抓包工具Fiddler 官网下载链接:https://www.telerik.com/fiddler 二.设置Fiddler Tools>>Connections 然后修改监听端 ...
- angular的Hash 模式和 HTML 5 模式
去除地址 # ,将{ provide: LocationStrategy, useClass: HashLocationStrategy }改为 { provide: LocationStrategy ...
- django 报错Reverse for 'detail' with keyword arguments '{'pk': '2'}' not found. 1 pattern(s) tried: ['$post/(?P<pk>[0-9]+)/$']
Django报错:Reverse for 'detail' with keyword arguments '{'pk': '2'}' not found. 1 pattern(s) tried: [' ...
- pytest--生成HTML报告
前戏 我们做自动化,测试报告是必不可少的.方便自己查看,也可以供领导查看,一个测试报告就可以说明我们做了哪些事情,pytest-html插件给我们提供了一个很简陋的测试报告,为什么说简陋,因为是真简陋 ...
- nuxtjs踩坑指南
1.nuxt引入问题:Can't resolve 'stylus-loader' 原因在于没有安装stylus,安装即可:npm install stylus stylus-loader --save ...
- poi实现excel数据的导入和导出
内容来源于网络,侵删. 1.需要的jar包 <dependency> <groupId>org.apache.poi</groupId> <artifactI ...
- HBase的java操作,最新API。(查询指定行、列、插入数据等)
关于HBase环境搭建和HBase的原理架构,请见笔者相关博客. 1.HBase对java有着较优秀的支持,本文将介绍如何使用java操作Hbase. 首先是pom依赖: <dependency ...
- CSS3倒影效果
比较简单的倒影效果 <pre><div class="box-reflect"><img src="https://www.baidu.co ...