第五周周二练习:实验 5 Spark SQL 编程初级实践
1.题目:
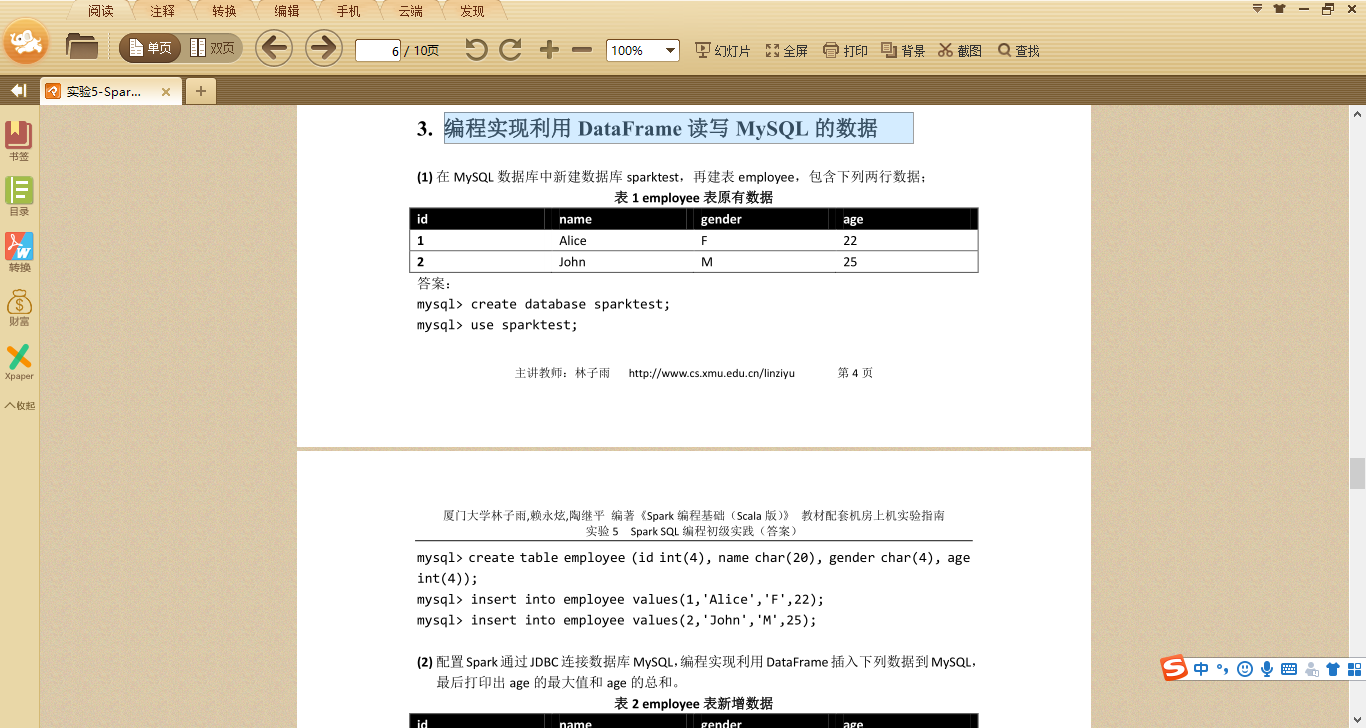 源码:
源码:
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrameReader
object TestMySQL {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("RddToDFrame").master("local").getOrCreate()
import spark.implicits._
val employeeRDD = spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" "))
val schema = StructType(List(StructField("id", IntegerType,true),StructField("name", StringType, true),StructField("gender", StringType,true),StructField("age", IntegerType, true)))
val rowRDD = employeeRDD.map(p => Row(p().toInt,p().trim,p().trim,p().toInt))
val employeeDF = spark.createDataFrame(rowRDD, schema)
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "hadoop")
prop.put("driver","com.mysql.jdbc.Driver")
employeeDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest","sparktest.employee", prop)
val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/sparktest").option("driver","com.mysql.jdbc.Driver").option("dbtable","employee").option("user","root").option("password", "hadoop").load()
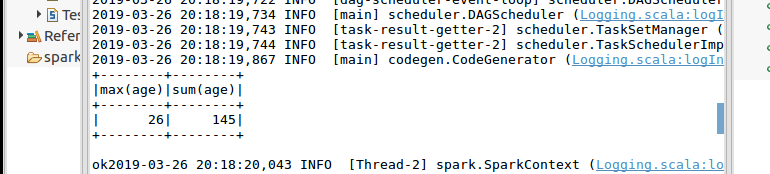
jdbcDF.agg("age" -> "max", "age" -> "sum").show()
print("ok")
}
}
数据库数据: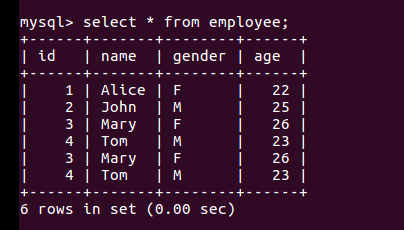
结果:
2.编程实现将 RDD 转换为 DataFrame

官网给出两种方法,这里给出一种(使用编程接口,构造一个 schema 并将其应用在已知的 RDD 上。):
源码:
import org.apache.spark.sql.types._
import org.apache.spark.sql.Encoder
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
object RDDtoDF {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("RddToDFrame").master("local").getOrCreate()
import spark.implicits._
val employeeRDD =spark.sparkContext.textFile("file:///usr/local/spark/employee.txt")
val schemaString = "id name age"
val fields = schemaString.split(" ").map(fieldName => StructField(fieldName,
StringType, nullable = true))
val schema = StructType(fields)
val rowRDD = employeeRDD.map(_.split(",")).map(attributes =>
Row(attributes().trim, attributes(), attributes().trim))
val employeeDF = spark.createDataFrame(rowRDD, schema)
employeeDF.createOrReplaceTempView("employee")
val results = spark.sql("SELECT id,name,age FROM employee")
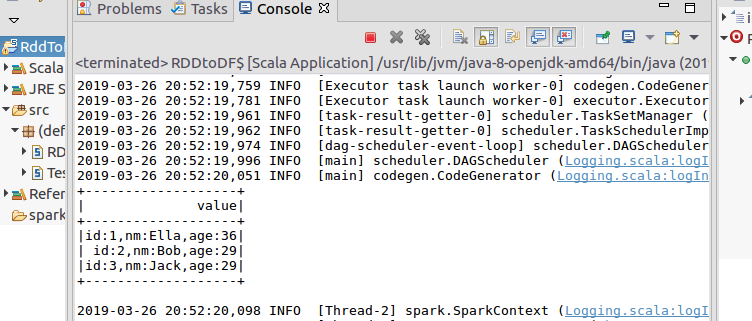
results.map(t => "id:"+t()+","+"name:"+t()+","+"age:"+t()).show()
}
}
结果:
第五周周二练习:实验 5 Spark SQL 编程初级实践的更多相关文章
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
- 实验 5 Spark SQL 编程初级实践
实验 5 Spark SQL 编程初级实践 参考厦门大学林子雨 1. Spark SQL 基本操作 将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并 ...
- 实验5 Spark SQL 编程初级实践
源文件内容如下(包含 id,name,age),将数据复制保存到 ubuntu 系统/usr/local/spark 下, 命名为 employee.txt,实现从 RDD 转换得到 DataFram ...
- spark实验(五)--Spark SQL 编程初级实践(1)
一.实验目的 (1)通过实验掌握 Spark SQL 的基本编程方法: (2)熟悉 RDD 到 DataFrame 的转化方法: (3)熟悉利用 Spark SQL 管理来自不同数据源的数据. 二.实 ...
- Spark SQL 编程初级实践
一.实验目的 (1) 通过实验掌握 Spark SQL 的基本编程方法: (2) 熟悉 RDD 到 DataFrame 的转化方法: (3) 熟悉利用 Spark ...
- 第五周学习总结&实验报告(三)
第五周学习总结&实验报告(三) 这一周又学习了新的知识点--继承. 一.继承的基本概念是: *定义一个类,在接下来所定义的类里面如果定义的属性与第一个类里面所拥有的属性一样,那么我们在此就不需 ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- 实验 2 Scala 编程初级实践
实验 2 Scala 编程初级实践 一.实验目的 1.掌握 Scala 语言的基本语法.数据结构和控制结构: 2.掌握面向对象编程的基础知识,能够编写自定义类和特质: 3.掌握函数式编程的基础知识,能 ...
- 第五周课程总结&实验报告(四)
第五周课程总结 本周主要学习了 1.抽象类 抽象类的定义格式 abstract class抽象类名称{ 属性; 访问权限返回值类型方法名称(参数){ //普通方法 [return返回值]; } 访问权 ...
随机推荐
- FFT_应用和例题
卷积 现有两个定义在 N 上的函数 \(f(n),g(n)\),定义 \(f\) 和 \(g\) 的卷积(convolution)为 \(f \otimes g\) \[ (f \otimes g)( ...
- CF1221G Graph And Number(容斥,搜索,FMT)
至今觉得这场 edu 的 G 比 EF 都要简单-- 不知道为什么出题人要把 \(m=0\) 放进去,先特判掉. 要求至少一个 \(0\),至少一个 \(1\),至少一个 \(2\),容斥一波,变成总 ...
- 无聊系列 - C#中一些常用类型与java的类型对应关系
昨天在那个.NET转java群里,看到一位朋友在问C#的int 对应java的哪个对象,就心血来潮,打算写一下C#中一些基础性的东西,在java中怎么找. 1. 基础值类型 如:int,long,do ...
- 记一次Lua语言中死循环查错
前言 如果在Lua语言中某一处死循环了!你特么的怎么去查出这特么的该死的循环到底在特么的哪里!!! 重现步骤 一打开技能界面,整个游戏就卡死不动了 开始排查 查看一下cpu占用率,unity占用60% ...
- 《Spring + MyBatis 企业应用实战》书评
最近公司的前端用 MpVUE.JS 开发微信小程序遇到一个问题,对后端传来的富文本编辑器的标签无法进行解析.因为公司小,这个问题前端人员直接反映给老板,跟老板说,“ MpVUE.JS 无法解析富文本编 ...
- 在.net中读写config文件的各种方法【转】
今天谈谈在.net中读写config文件的各种方法. 在这篇博客中,我将介绍各种配置文件的读写操作. 由于内容较为直观,因此没有过多的空道理,只有实实在在的演示代码, 目的只为了再现实战开发中的各种场 ...
- MySQL for OPS 02:SQL 基础
写在前面的话 上一节主要谈谈 MySQL 是怎么安装的以及最简单的初始化我们应该做哪些配置.其中也用到了一些简单的用户操作 SQL,所以这一节主要学习常用的 SQL 使用. SQL 介绍 在了解 SQ ...
- ASP.NET MVC过滤器学习笔记
1.过滤器的两个特征 1.他是一种特性,可以引用到控制器类和Action方法上.比如下图 这里控制器类和action方法都引用了过滤器,这个过滤器是用来做授权的 2.特征继承自FilterAttrib ...
- APS.NET MVC + EF (06)---模型
在实际开发中,模型往往被划分为视图模型和业务模型两部分,视图模型靠近视图,业务模型靠近业务,但是在具体编码上,它们之间并不是隔离的. 6.1 视图模型和业务模型 模型大多数时候都是用来传递数据的.然而 ...
- Linux磁盘系统——管理磁盘的命令
Linux磁盘系统——管理磁盘的命令 摘要:本文主要学习了Linux系统中管理磁盘的命令,包括查看磁盘使用情况.磁盘挂载相关.磁盘分区相关.磁盘格式化等操作. df命令 df命令用于显示Linux系统 ...