OCR3:tesseract script
通过命令:tesseract -h 可查看 OCR操作脚本参数:
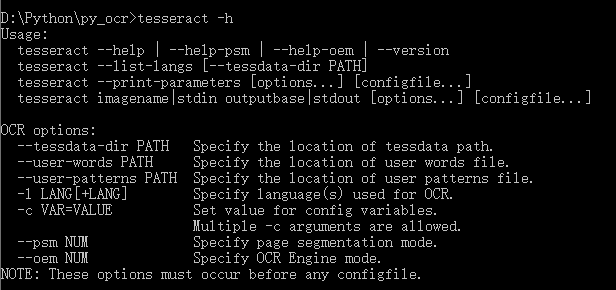
其中参数说明:
- –-oem:指定使用的算法,0:代表老的算法;1:代表LSTM算法;2:代表两者的结合;3:代表系统自己选择。
- –-psm:指定页面切分模式。默认是3,也就是自动的页面切分,但是不进行方向(Orientation)和文字(script,其实并不等同于文字,比如俄文和乌克兰文都使用相同的script,中文和日文的script也有重合的部分)的检测。如果我们要识别的是单行的文字,我可以指定7。我们这里已经知道文字是中文,并且方向是horizontal(从左往右再从上往下的写法,古代中国是从上往下从右往左),因此使用默认的3就可以了。
--psm:
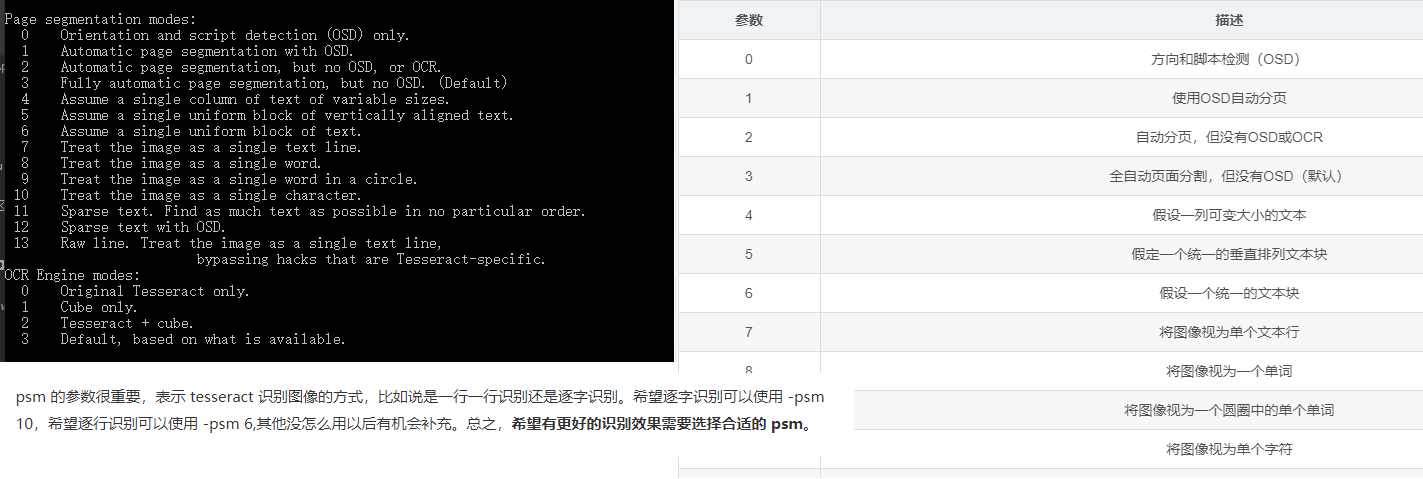
combine_tessdata
- -e:通过-e 指令,可以从一个已经合并了的traineddata文件中提取独立的组件。如:combine_tessdata -e tessdata/eng.traineddata \ /home/$USER/temp/eng.config /home/$USER/temp/eng.unicharset
- -o:通过 -o 指令,可以覆盖一个给定的traineddata文件中的对应组件。如:combine_tessdata -o tessdata/eng.traineddata \ /home/$USER/temp/eng.config /home/$USER/temp/eng.unicharambigs
- -u:通过 -u 指令,可以将所有组件解压到指定路径。如:combine_tessdata -u tessdata/eng.traineddata /home/$USER/temp/eng.
code
NAME
combine_tessdata - combine/extract/overwrite/list/compact Tesseract data
# 用于合并/提取/覆盖/list(-d)/压缩 tesseract data
SYNOPSIS
combine_tessdata [OPTION] FILE... DESCRIPTION
combine_tessdata(1) is the main program to
combine/extract/overwrite/list/compact tessdata components in
[lang].traineddata files.
# combine_tessdata 是主要的程序,用来合并/提取/覆盖/list/压缩 [lang].traineddata files 中的tessdata组件。 To combine all the individual tessdata components (unicharset, DAWGs,
classifier templates, ambiguities, language configs) located at, say,
/home/$USER/temp/eng.* run: combine_tessdata /home/$USER/temp/eng. The result will be a combined tessdata file
/home/$USER/temp/eng.traineddata
# 将所有独立的tessdat组件合并在一起 Specify option -e if you would like to extract individual components
from a combined traineddata file. For example, to extract language
config file and the unicharset from tessdata/eng.traineddata run: combine_tessdata -e tessdata/eng.traineddata \
/home/$USER/temp/eng.config /home/$USER/temp/eng.unicharset The desired config file and unicharset will be written to
/home/$USER/temp/eng.config /home/$USER/temp/eng.unicharset
# 通过-e 指令,可以从一个已经合并了的traineddata文件中提取独立的组件。 Specify option -o to overwrite individual components of the given
[lang].traineddata file. For example, to overwrite language config and
unichar ambiguities files in tessdata/eng.traineddata use: combine_tessdata -o tessdata/eng.traineddata \
/home/$USER/temp/eng.config /home/$USER/temp/eng.unicharambigs As a result, tessdata/eng.traineddata will contain the new language
config and unichar ambigs, plus all the original DAWGs, classifier
templates, etc.
# 通过 -o 指令,可以覆盖一个给定的traineddata文件中的对应组件。
# Note: the file names of the files to extract to and to overwrite from
should have the appropriate file suffixes (extensions) indicating their
tessdata component type (.unicharset for the unicharset, .unicharambigs
for unichar ambigs, etc). See k*FileSuffix variable in
ccutil/tessdatamanager.h.
# 要提取和覆盖的文件的文件名应具有对应文件相同的后缀名,以表明其tessdata组件的类型。 Specify option -u to unpack all the components to the specified path:
combine_tessdata -u tessdata/eng.traineddata /home/$USER/temp/eng. This will create /home/$USER/temp/eng.* files with individual tessdata
components from tessdata/eng.traineddata.
# 通过 -u 指令,可以将所有组件解压到指定路径 OPTIONS
-c .traineddata FILE...: Compacts the LSTM component in the
.traineddata file to int. -d .traineddata FILE...: Lists directory of components from the
.traineddata file. -e .traineddata FILE...: Extracts the specified components from the
.traineddata file -o .traineddata FILE...: Overwrites the specified components of the
.traineddata file with those provided on the command line. -u .traineddata PATHPREFIX Unpacks the .traineddata using the provided
prefix. CAVEATS
Prefix refers to the full file prefix, including period (.)
# 注意点 指令中的前缀要包含‘.’
COMPONENTS
#组件
The components in a Tesseract lang.traineddata file as of Tesseract 4.0
are briefly described below; For more information on many of these
files, see
https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract and
https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract-4.00 lang.config
(Optional) Language-specific overrides to default config variables.
For 4.0 traineddata files, lang.config provides control parameters
which can affect layout analysis, and sub-languages.
# 根据语言特定,用来覆盖默认的配置变量。
# 对于4.0的traineddata文件来说,config文件提供影响布局分析(不知道跟文字分割算法有关)和子语言的控制参数 lang.unicharset
(Required - 3.0x legacy tesseract) The list of symbols that
Tesseract recognizes, with properties. See unicharset(5).
# 3.0 必需的
# tesseract识别的符号列表,包含属性. lang.unicharambigs
(Optional - 3.0x legacy tesseract) This file contains information
on pairs of recognized symbols which are often confused. For
example, rn and m.
# 3.0 可选的
# 这个文件包含经常容易混淆的符号对的信息,例如‘rn和m’
# (如果识别中文的话,应该可以用来处理一些形似字,比如日和曰) lang.inttemp
(Required - 3.0x legacy tesseract) Character shape templates for
each unichar. Produced by mftraining(1).
# 3.0 必需
# 每个字符的形状模板
# 通过模仿mftraining创建 lang.pffmtable
(Required - 3.0x legacy tesseract) The number of features expected
for each unichar. Produced by mftraining(1) from .tr files.
# 3.0 必需
# 每个字符的期望特征数量
# 由 mftraining 通过 .tr文件产生 lang.normproto
(Required - 3.0x legacy tesseract) Character normalization
prototypes generated by cntraining(1) from .tr files.
# 3.0 必需
# 字符的归一化原型,由cntraining通过.tr文件生成 lang.punc-dawg
(Optional - 3.0x legacy tesseract) A dawg made from punctuation
patterns found around words. The "word" part is replaced by a
single space.
# 3.0 可选的
# 一个由字符周围标点符号构建的dawg
# word部分由一个单独的空格替代 lang.word-dawg
(Optional - 3.0x legacy tesseract) A dawg made from dictionary
words from the language.
# 3.0 可选
# 一个由字典单词构建的dawg lang.number-dawg
(Optional - 3.0x legacy tesseract) A dawg made from tokens which
originally contained digits. Each digit is replaced by a space
character.
# 3.0 可选
# 一个由符号构建的dawg,最初包含数字,每一个数字被一个空格字符代替???不是很理解 lang.freq-dawg
(Optional - 3.0x legacy tesseract) A dawg made from the most
frequent words which would have gone into word-dawg.
# 3.0 可选
# 一个由最常用单词构建的dawg,这些单词将会进入word-dwag lang.fixed-length-dawgs
(Optional - 3.0x legacy tesseract) Several dawgs of different fixed
lengths — useful for languages like Chinese.
# 3.0 可选
# 混合长度dawgs
# 对类似于中文的语言有用
# lang.shapetable
(Optional - 3.0x legacy tesseract) When present, a shapetable is an
extra layer between the character classifier and the word
recognizer that allows the character classifier to return a
collection of unichar ids and fonts instead of a single unichar-id
and font.
# 3.0 可选
# 如果存在,shapetable是字符分类器和单词识别器之间的额外层,允许字符分类器返回unichar ID和字体的集合,而不是单个unichar-id和字体。
# (应该是指用来应对多字符识别的,应该能够提高准确率) lang.bigram-dawg
(Optional - 3.0x legacy tesseract) A dawg of word bigrams where the
words are separated by a space and each digit is replaced by a ?.
# 一个由双字母组构成的dawg
# bigram??二元语法
[wiki bigram](https://en.wikipedia.org/wiki/N-gram) lang.unambig-dawg
(Optional - 3.0x legacy tesseract) . lang.params-model
(Optional - 3.0x legacy tesseract) . lang.lstm
(Required - 4.0 LSTM) Neural net trained recognition model
generated by lstmtraining.
# 4.0 必需
# 由lstmtraining生成的神经网络识别模型 lang.lstm-punc-dawg
(Optional - 4.0 LSTM) A dawg made from punctuation patterns found
around words. The "word" part is replaced by a single space. Uses
lang.lstm-unicharset.
# 4.0 可选
# 由单词周边的标点符号构造的dawg,需要用到lang.lstm-unicharset lang.lstm-word-dawg
(Optional - 4.0 LSTM) A dawg made from dictionary words from the
language. Uses lang.lstm-unicharset.
# 4.0 可选
# 由指定的语言的字典单词构造的dawg,需要用到lang.lstm-unicharset lang.lstm-number-dawg
(Optional - 4.0 LSTM) A dawg made from tokens which originally
contained digits. Each digit is replaced by a space character. Uses
lang.lstm-unicharset.
# 4.0可选
# 一个由最初包含数字的符号集构造的dawg
# Each digit is replaced by a space character.这句话还是不是很理解,直译的话就是每个数字都由一个空格字符代替,
我想或者是不是可以理解为每个数字都由一个空格字符所占用的位置代表??
# 需要用到lang.lstm-unicharset lang.lstm-unicharset
(Required - 4.0 LSTM) The unicode character set that Tesseract
recognizes, with properties. Same unicharset must be used to train
the LSTM and build the lstm-*-dawgs files.
# 4.0 必需
# 一个Tesseract可以识别的包含属性的unicode字符集。
# 相同的单字符集必须用来被训练LSTM,并且构造the lstm-*-dawgs files
lang.lstm-recoder
(Required - 4.0 LSTM) Unicharcompress, aka the recoder, which maps
the unicharset further to the codes actually used by the neural
network recognizer. This is created as part of the starter
traineddata by combine_lang_model.
# 4.0 必需
# Unicharcompress又名the recoder (单字符压缩?又名编码器?)
# 将单字符集合进一步映射到神经网络识别器实际使用到的代码上
# 这个lang.lang_recoder由combine_lang_model创建的starter traineddata的一部分
# (这个lang.lang_recoder可以通过combine_tessdata从traineddata中提取出来) lang.version
(Optional) Version string for the traineddata file. First appeared
in version 4.0 of Tesseract. Old version of traineddata files will
report Version string:Pre-4.0.0. 4.0 version of traineddata files
may include the network spec used for LSTM training as part of
version string.
# 4.0 可选
# 为the traineddata file.创建的版本字符串
# HISTORY
combine_tessdata(1) first appeared in version 3.00 of Tesseract SEE ALSO
tesseract(1), wordlist2dawg(1), cntraining(1), mftraining(1),
unicharset(5), unicharambigs(5) COPYING
Copyright (C) 2009, Google Inc. Licensed under the Apache License,
Version 2.0 AUTHOR
The Tesseract OCR engine was written by Ray Smith and his research
groups at Hewlett Packard (1985-1995) and Google (2006-present).
参考资料
- https://fancyerii.github.io/2019/03/12/3_tesseract/
- https://blog.csdn.net/qq_32674197/article/details/81983444
OCR3:tesseract script的更多相关文章
- 服务端调用js:javax.script
谈起js在服务端的应用,大部分人的第一反应都是node.js.node.js作为一套服务器端的 JavaScript 运行环境,有自己的独到之处,但不是所有的地方都需要使用它. 例如在已有的服务端代码 ...
- Ansible 脚本运行一次后,再次运行时出现报错情况,原因:ansible script 的格式不对,应改成Unix编码
Ansible 脚本运行一次后,再次运行时出现报错情况,原因:ansible script 的格式不对,应改成Unix编码 find . -name "*" | xargs do ...
- npm run dev 报错:missing script:dev
一.问题: 今天在运行vue项目时,在mac终端输入npm run dev,结果报错: 翻译是: npm错误:缺少script:dev npm错误:完整路径见:users/mymac/ .npm/_l ...
- LR:HTML-based script和URL-based script方式录制的区别
转http://www.cnblogs.com/xiaojinniu425/p/6275257.html 一.区别: 为了更加直观的区别这两种录制方式,我们可以分别使用这两种方式录制同一场景(打开百度 ...
- OCR2:tesseract字库训练
由于tesseract的中文语言包“chi_sim”对中文字体或者环境比较复杂的图片,识别正确率不高,因此需要针对特定情况用自己的样本进行训练,提高识别率,通过训练,也可以形成自己的语言库. 工具: ...
- V-rep学习笔记:main script and child scripts
The main and child scripts The main script and the child scripts, which are simulation scripts, play ...
- Fiddler 高级用法:Fiddler Script 与 HTTP 断点调试
转载自 https://my.oschina.net/leejun2005/blog/399108 1.Fiddler Script 1.1 Fiddler Script简介 在web前端开发的过程中 ...
- 一起来学linux:shell script(二)关于脚本
(一)首先来看shell脚本的执行方式,shell脚本的后缀名都是sh文件. 1 sh test.sh 2 source test.sh 这两种方式有什么区别呢.test.sh 里的脚本很简单, 从键 ...
- OCR4:Tesseract 4
Tesseract OCR 该软件包包含一个OCR引擎 - libtesseract和一个命令行程序 - tesseract. Tesseract 4增加了一个基于OCR引擎的新神经网络(LSTM ...
随机推荐
- 微信小程序 vscode 自动保存 保存自动编译 微信开发者工具崩溃
修改vscode的自动保存延迟时间,将 auto save delay 选项 修改的长一点.
- 【java异常】Building workspace has encountered a problem. Error
可能是workspace设置错误,检查一下 或者把项目重新下一下,或者重新maven导入
- [RN] React Native 头部 滑动吸顶效果的实现
React Native 头部 滑动吸顶效果的实现 效果如下图所示: 实现方法: 一.吸顶组件封装 StickyHeader .js import * as React from 'react'; i ...
- vue之非父子通信
一.非父子通信: 思路: 找个中间存储器,组件一把信息放入其中,组件二去拿 代码如下: let hanfei = new Vue(); # 实列化个空的vue对象,作为中间存储器来时间 ...
- js之juery
目录 JQuery 属性选择器: 操作标签 文本操作 属性操作 文档处理 事件 JQuery 属性选择器: 属性选择器: [attribute] [attribute=value]// 属性等于 [a ...
- C程序获取命令行参数
命令行参数 命令行界面中,可执行文件可以在键入命令的同一行中获取参数用于具体的执行命令.无论是Python.Java还是C等等,这些语言都能够获取命令行参数(Command-line argument ...
- webpack的一些坑
最近自己着手做一个小的Demo需要webpack,目前版本号是4.41.2,想使用的版本是3.6.0,因3x版本和4x版本很多地方不同,所以在安装过程中也是很多坎坷,下面是遇到的一些坑,和一些解决办法 ...
- 【转】Web实现前后端分离,前后端解耦
一.前言 ”前后端分离“已经成为互联网项目开发的业界标杆,通过Tomcat+Ngnix(也可以中间有个Node.js),有效地进行解耦.并且前后端分离会为以后的大型分布式架构.弹性计算架构.微服务架构 ...
- python jenkins api
#!/usr/bin/pythonimport sys, timeimport shutil, commands#coding=utf-8 import sysreload(sys)sys.setde ...
- Django学习----js传参给view.py
需求: 散点图中每选择一个点,获取到id之后传给view.py,根据这个id进行sql语句的查询. 问题: 要求实时查询 解决办法: ajax查询 js页面 .on("mousedown&q ...