Python中使用requests和parsel爬取喜马拉雅电台音频
场景
喜马拉雅电台:
找到一步小说音频,这里以下面为例
https://www.ximalaya.com/youshengshu/16411402/
博客:
https://blog.csdn.net/badao_liumang_qizhi
关注公众号
霸道的程序猿
获取编程相关电子书、教程推送与免费下载。
实现
找到下载地址
使用谷歌浏览器打开上面网址,按F12打开调试,点击播放按钮后,然后找到Network下的Media下的Headers下的RequestURL,然后选中在新窗口中打开

打开之后就可以点击三个点出来之后的下载按钮,便可以下载

使用代码下载
打开PyCharm,新建一个Python项目
导入requests库,然后为了防止其反扒机制,找到浏览器上Headers下的Requests
Headers下的User-Agent,复制出来。
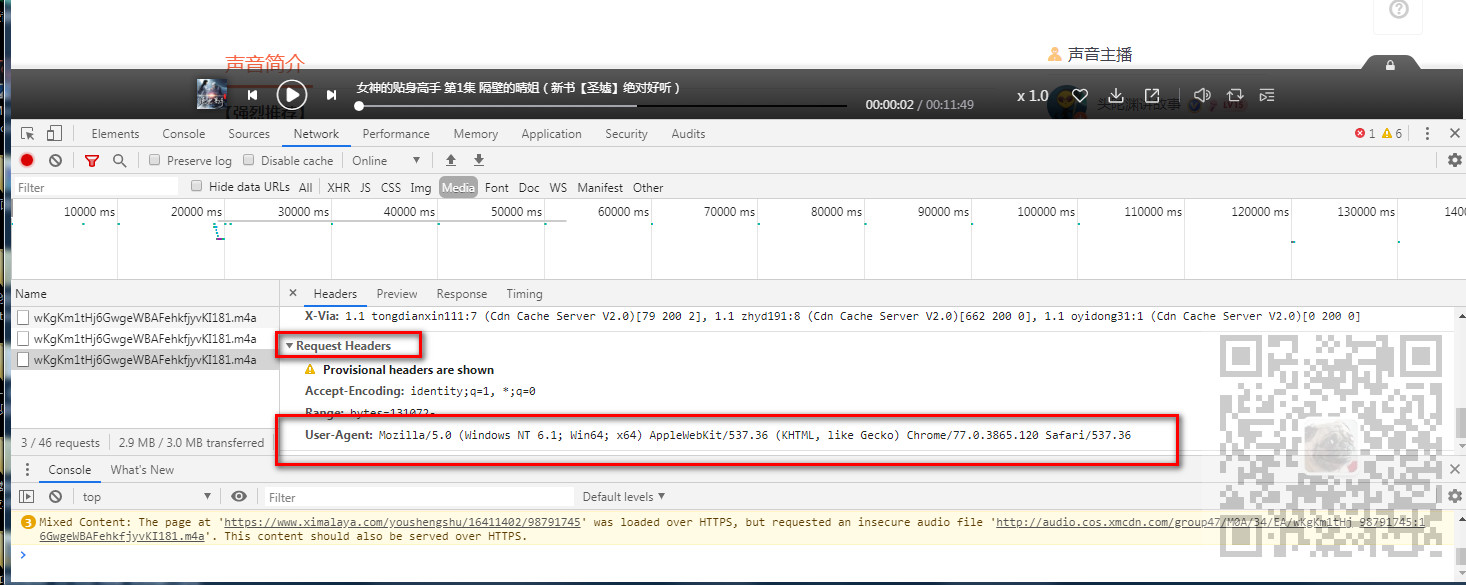
- #能发送http请求的库
- import requests
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.120 Safari/537.36'
}
media_url = 'http://audio.cos.xmcdn.com/group47/M0A/34/EA/wKgKm1tHj6GwgeWBAFehkfjyvKI181.m4a' response = requests.get(media_url,headers = headers); with open('badao.mp4',mode='wb') as f: f.write(response.content)
下载成功之后
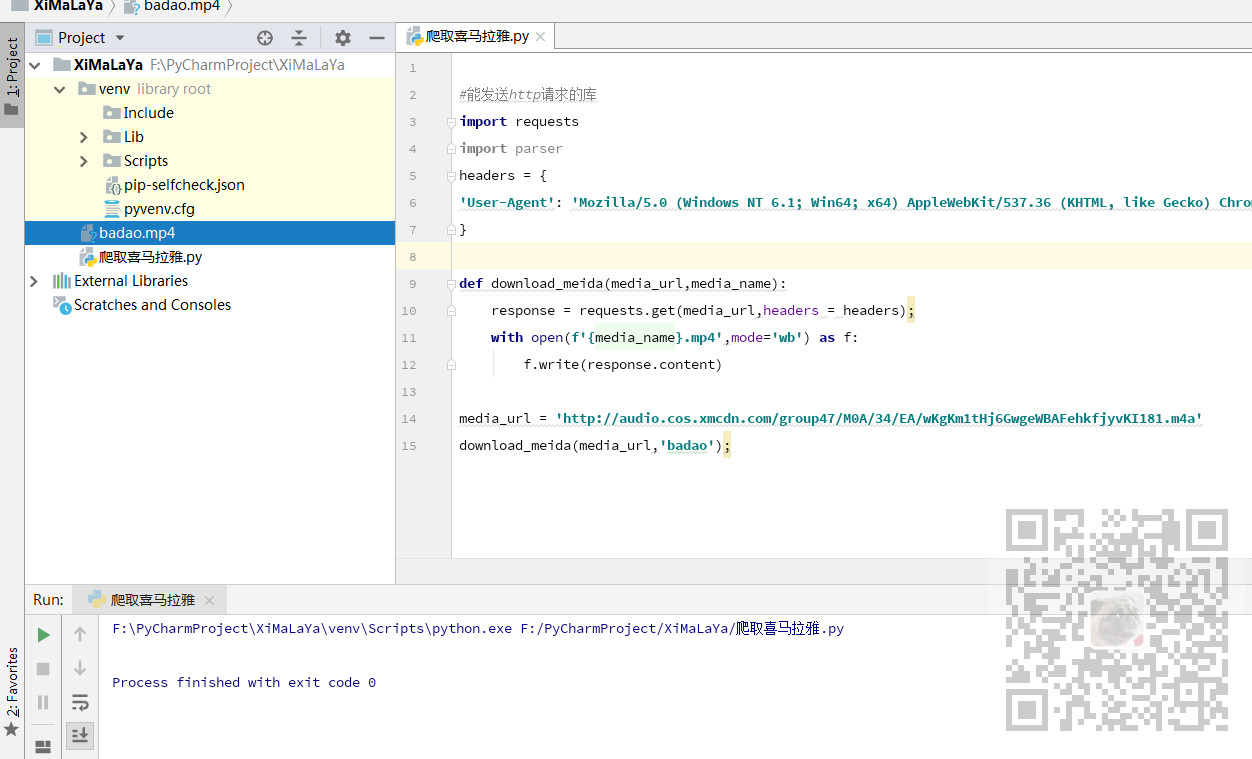
下载地址获取
上面只是获取一个音频的下载地址,怎样获取每一集的下载地址
还是刚才的调试页面,我们点击放大镜样的搜索按钮,出来搜索框之后,输入刚才下载地址的文件名

点击第一个返回json数据的接口url,找到其Headers下的RequestURL。

然后在新窗口打开
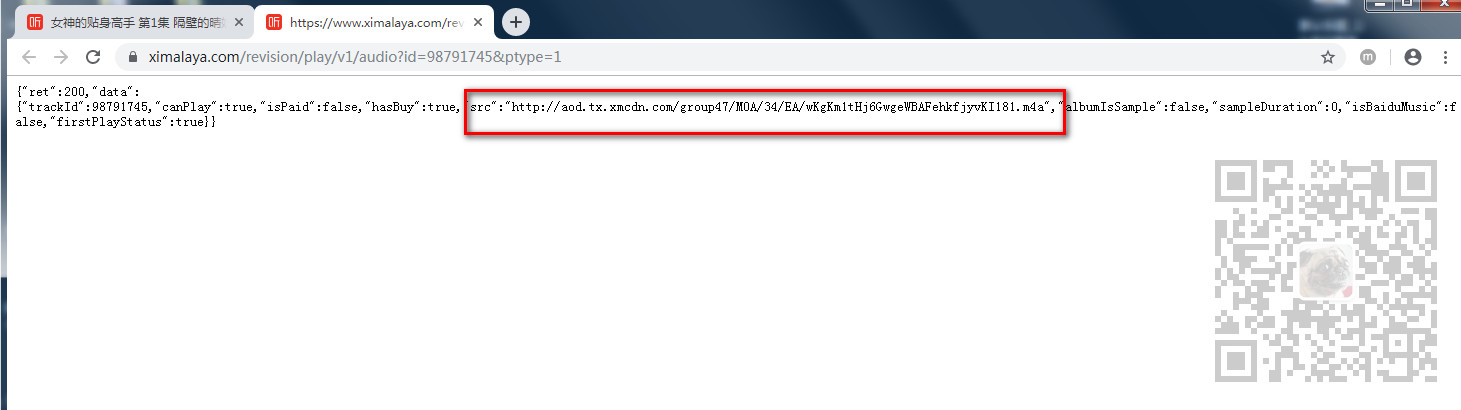
可以看到是通过这个API返回的Json数据中的下载地址。
那么这个API需要传递什么参数。通过其Headers底部的请求参数可以看到需要一个id参数和pytype参数。
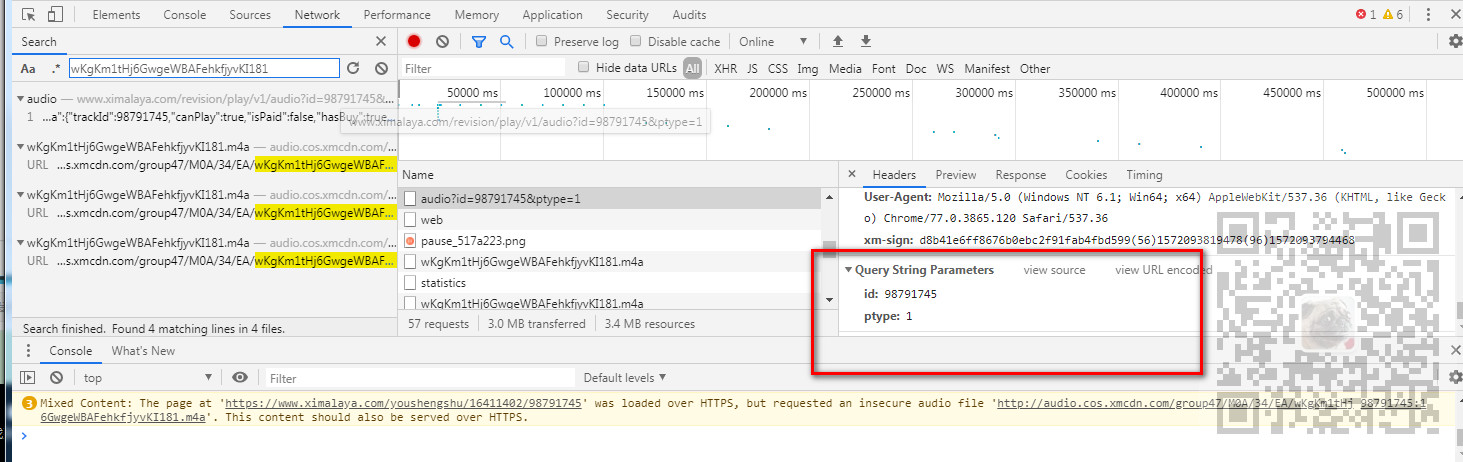
通过对比每一集的接口的请求参数得知,pytype是固定的,id是每一集对应的链接中的id相对应的。
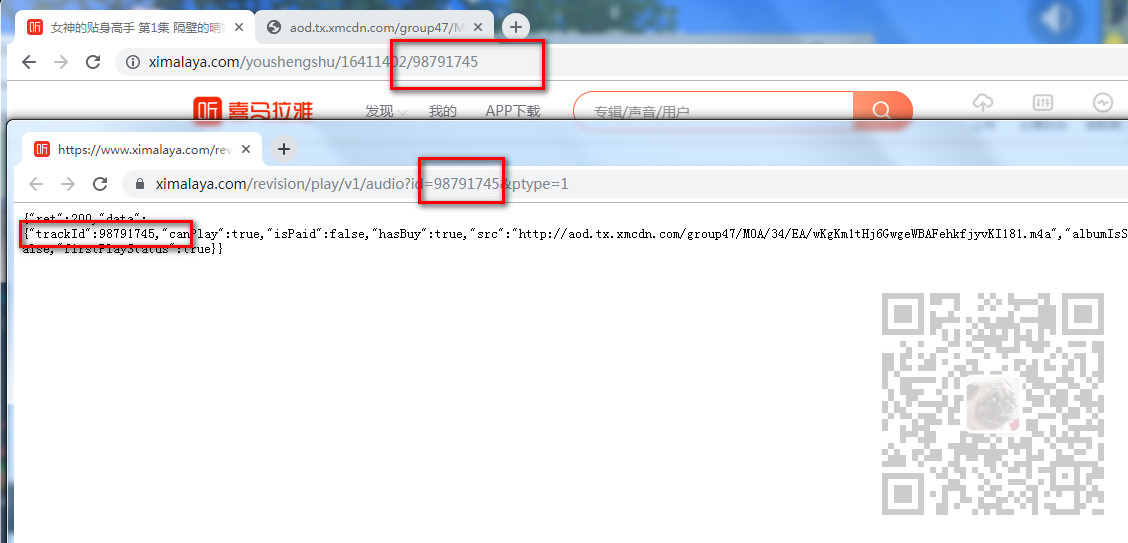
所以要是循环下载多集的话,需要在目录页面获取超链接的href属性中对应的id。
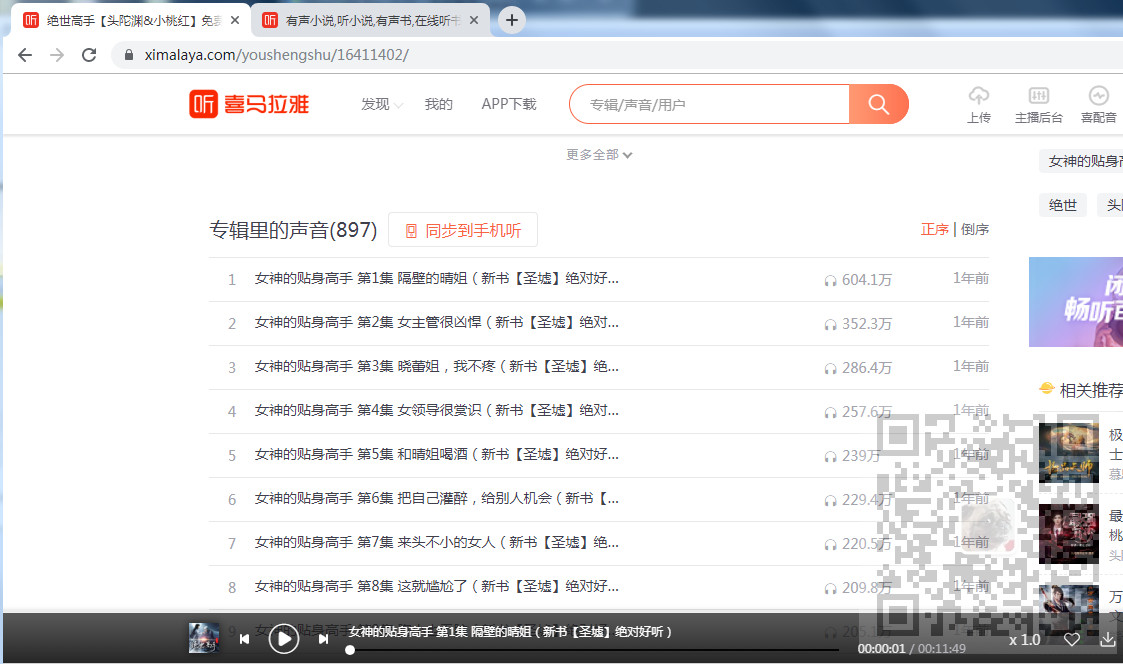
这里我们定义一个请求下载地址json数据的方法
- defmedia_api(track_id):
api_url=f'https://www.ximalaya.com/revision/play/v1/audio?id={track_id}&ptype=1';- response = requests.get(api_url,headers = headers)
- print(response.json())
- media_api()
运行下打印json数据
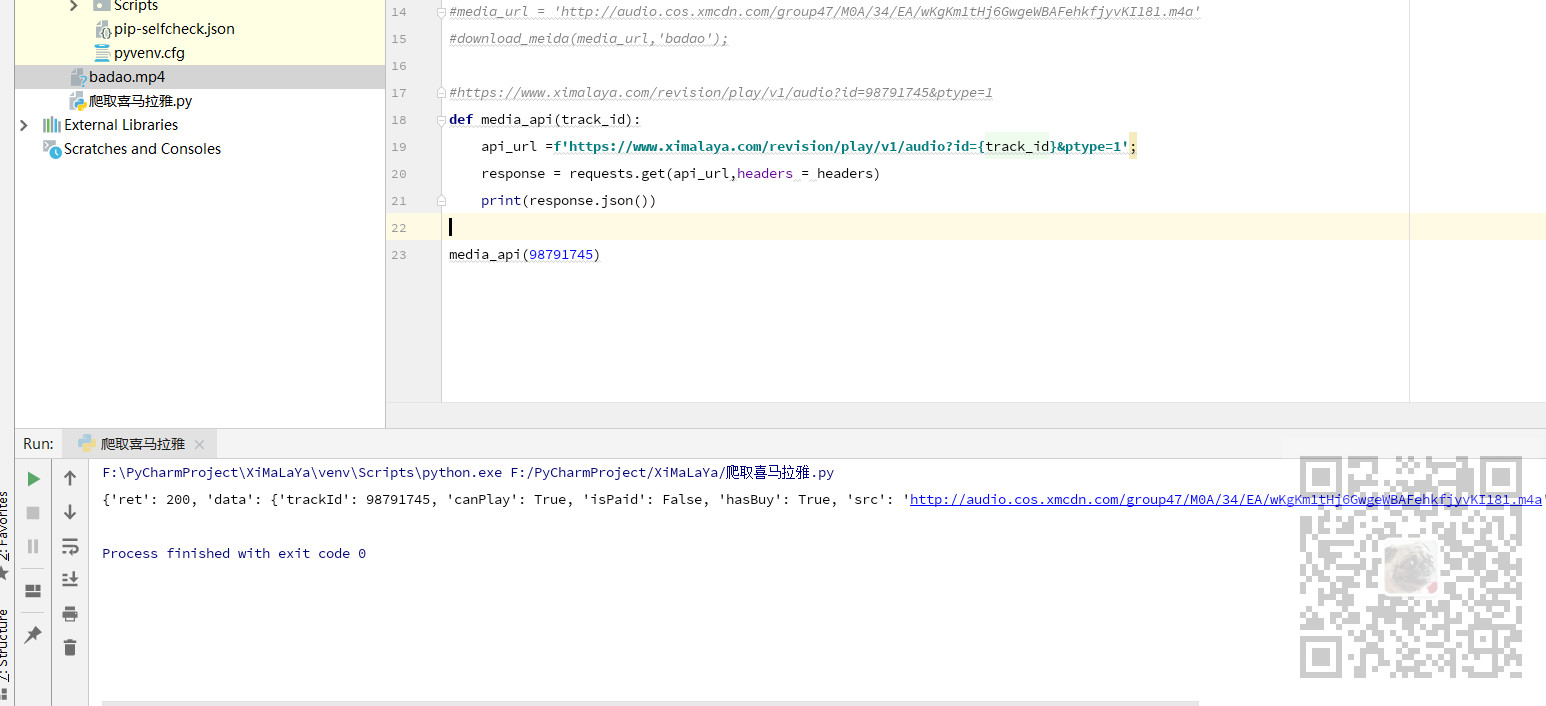
提取下载地址
那么就需要根据传递的id参数通过这个接口返回json数据,并从json数据中提取src对应的url数据
- def media_api(track_id):
api_url=f'https://www.ximalaya.com/revision/play/v1/audio?id={track_id}&ptype=1';- response = requests.get(api_url,headers = headers)
- #print(response.json())
- #json返回字典类型 提取使用[]
- data_json = response.json()
- src = data_json['data']['src']
- return src
- media_api()
这样就能根据id获取每一集的下载地址,然后再将下载地址传递给上面第一步下载的方法中进行下载即可。
接下来就是怎样获取每一集的id。
parsel解析网页获取id
首先需要导入parsel模块
- import parsel
如果没有安装则需要安装
- pip install parsel
我们来到其目录页
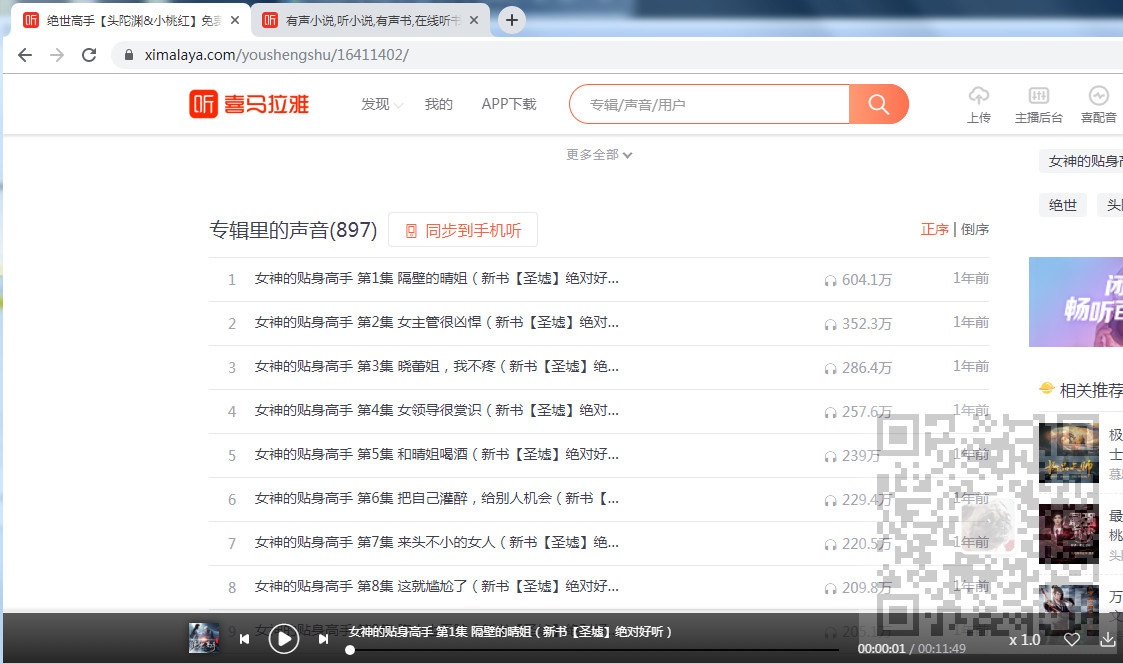
在Elemnts下可以看到每一集是一个a标签,我们获取a标签的href属性中的最后面的id。
我们再定义一个方法,此方法能根据页面的url获取当前页的所有集的id。
- def get_total_page(page_url):
- #请求页面
- response = requests.get(page_url,headers = headers)
- print(response.text)
- #获取页面html的内容
- sel = parsel.Selector(response.text)
- print(sel)
- #通过css选择器找到a标签 .sound-list代表 class属性为sound-list 然后下面的ul 下的li 下的a
- sound_list = sel.css('.sound-list ul li a')
- print(sound_list)
- #只有前30个是页面链接 截取前30个
- for sound in sound_list[:]:
- #extract_first()将对象中的文字提取出来
- #获取a标签的href属性的内容
- media_url = sound.css('a::attr(href)').extract_first()
- #/youshengshu// --只去最后面的id
- media_url = media_url.split('/')[-]
- # 获取a标签的title属性的内容
- media_name = sound.css('a::attr(title)').extract_first()
- #用yield将整个循环的内容返回
- yield media_url,media_name
下载一页的音频
我们在main方法中调用获取当前页所有的集的id和名字,然后循环将拿到的id去请求api获取下载的地址,然后将下载地址传递给下载的方法去下载
- if __name__ == '__main__':
- meidas = get_total_page('https://www.ximalaya.com/youshengshu/16411402/')
- for media_id,media_name in meidas:
- #print(media_url, media_name)
- media_url = media_api(media_id)
- download_meida(media_url, media_name)
运行程序将一页下载完
下载所有页
我们点击第二页看到url中追加了一个p2,依次类推,p+相应的页数。
这样就可以将页面url改造成传参的
- if __name__ == '__main__':
- #循环页数下载 range代表下载的页数范围
- for page in range(,):
- meidas = get_total_page(f'https://www.ximalaya.com/youshengshu/16411402/p{page}')
- for media_id,media_name in meidas:
- #print(media_url, media_name)
- media_url = media_api(media_id)
- download_meida(media_url, media_name)
那么在range中就可以输入要下载的页数的范围。
如果输入(1,31)就是下载所有的30页,这里只下载第二页,所以range是(2,3)
代码下载
关注公众号:
霸道的程序猿
回复:
爬取喜马拉雅
Python中使用requests和parsel爬取喜马拉雅电台音频的更多相关文章
- 在Python中使用BeautifulSoup进行网页爬取
目录 什么是网页抓取? 为什么我们要从互联网上抓取数据? 网站采集合法吗? HTTP请求/响应模型 创建网络爬虫 步骤1:浏览并检查网站/网页 步骤2:创建用户代理 步骤3:导入请求库 检查状态码 步 ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- 整理requests和正则表达式爬取猫眼Top100中遇到的问题及解决方案
最近看崔庆才老师的爬虫课程,第一个实战课程是requests和正则表达式爬取猫眼电影Top100榜单.虽然理解崔老师每一步代码的实现过程,但自己敲代码的时候还是遇到了不少问题: 问题1:获取respo ...
- Python爬虫:爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一 ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- requests+xpath+map爬取百度贴吧
# requests+xpath+map爬取百度贴吧 # 目标内容:跟帖用户名,跟帖内容,跟帖时间 # 分解: # requests获取网页 # xpath提取内容 # map实现多线程爬虫 impo ...
随机推荐
- RobotFramework不同版本优劣势
一.RIDE 1.5.2.1 1. 安装: pip install robotframework-ride==1.5.2.1 2. 优点: 此版本是RIDE发布以来最为稳定的版本,使用性能上也较为流畅 ...
- ASP.NET Core SignalR:基础概述
一.简介 ASP.NET Core SignalR 是一个开源代码库,它简化了向应用添加实时 Web 功能的过程. 实时 Web 功能使服务器端代码能够即时将内容推送到客户端. SignalR 的适用 ...
- spring boot项目记录--日志处理
微信点餐用到的日志框架:slf4j(门面)+logback(框架) @RunWith(SpringRunner.class) @SpringBootTest @Slf4j public class L ...
- 利用Python制作一个只属于和她的聊天器,再也不用担心隐私泄露啦!
------------恢复内容开始------------ 是否担心微信的数据流会被监视?是否担心你和ta聊天的小秘密会被保存到某个数据库里?没关系,现在我们可以用Python做一个只属于你和ta的 ...
- Implement Property Value Validation in Code 在代码中实现属性值验证(XPO)
This lesson explains how to set rules for business classes and their properties. These rules are val ...
- PostgreSQL 表字段起别名
使用Postgreq Sql 表字段起别名时注意要用双引号,使用单引号会出现语法错误,执行结果如图
- 解决npm下载慢的问题
方法一:使用淘宝定制的cnpm命令行工具替代默认安装npm npm install -g cnpm --registry=https://registry.npm.taobao.org 方法二:将np ...
- 031.[转] 从类状态看Java多线程安全并发
从类状态看Java多线程安全并发 pphh发布于2018年9月16日 对于Java开发人员来说,i++的并发不安全是人所共知,但是它真的有那么不安全么? 在开发Java代码时,如何能够避免多线程并发出 ...
- 编译原理之不懂就问-First集
老师PPT: 这条语言实在是..通俗易懂
- SPA项目开发之首页导航左侧菜单栏
1. Mock.js 前后端分离开发开发过程当中,经常会遇到以下几个尴尬的场景: 1. 老大,接口文档还没输出,我的好多活干不下去啊! 2. 后端小哥,接口写好了没,我要测试啊! 前后端分离之后,前端 ...