python爬虫学习心得:中国大学排名(附代码)

今天下午花时间学习了python爬虫的中国大学排名实例,颇有心得,于是在博客园与各位分享
首先直接搬代码:
import requests
from bs4 import BeautifulSoup
import bs4 def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "" def fillUnivList(ulist, html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr.find_all('td')
ulist.append([tds[0].string,tds[1].string,tds[3].string]) def printUnivList(ulist,num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校","总分",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288))) def main():
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo,20)
main()
再附上大学排名截图:
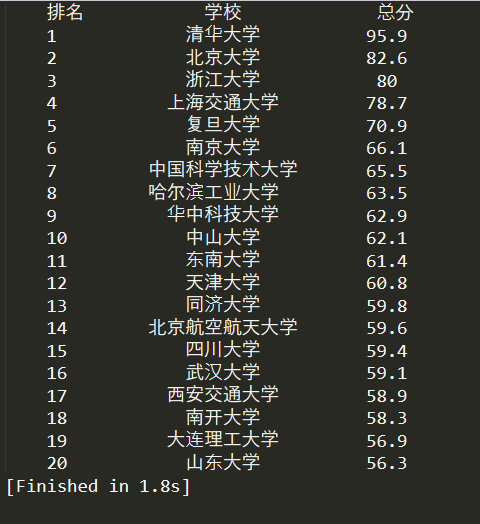
那么,现在开始代码心得讲解:
首先开始分析网页结构:
打开http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html
打开chrome网页分析工具:
可以发现大学排名,学校名称,省市,总分等都处在tbody标签内
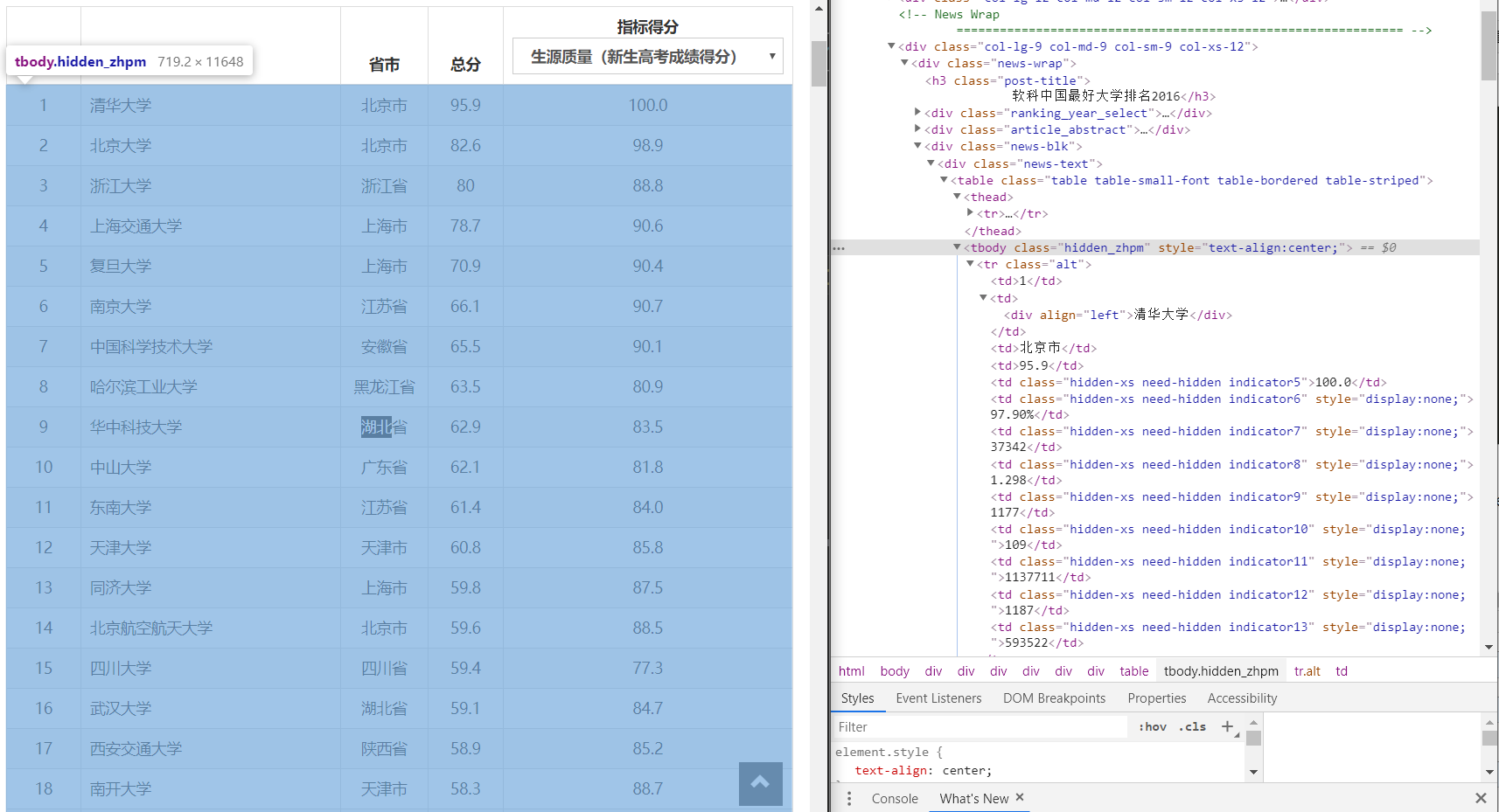
而大学名称、省市等,都处于tr标签内的td中

好,分析完成,开始构建函数架构:

主要思想为:获取网页html文本,得到需求数据,并将需求数据转化为列表,最后将列表输出
下一步:开始补充getHTMLText()部分的代码:

这里我用try except形式编写代码:
首先获取网页url,时限为30s,j接着运用 r.raise_for_status()(如果 HTTP 请求返回了不成功的状态码, r.raise_for_status() 会抛出一个 HTTPError异常)
然后将网页转码为r.apparent_encoding
返回一个r.text
这里代码运行中如果出现错误,则会return "",返回一个空字符串
接下来开始编写fillUnivList()部分代码

我们先做一锅汤,定义为soup,然后在这锅汤中遍历tr的孩子,这里每一个tr都对应一所大学的信息
而且我们需要滤掉非标签类型的其他信息,所以运用isinstance对函数类型做一个判断
if isinstance(tr,bs4.element.Tag):
这行代码就是检测标签类型,如果标签不是bs4库定义的类型,将过滤掉,同时为了运用这个方法,我们也就需要引入bs4库
由于tr标签已经被解析出来,接下来就需要对tr标签中的td标签做查询
if isinstance(tr,bs4.element.Tag):
tds = tr.find_all('td')
这里把查询到的td标签存入tds列表中
再然后在ulist表中增加:排名,大学名和总分的对应字段
ulist.append([tds[0].string,tds[1].string,tds[3].string])
接着来编写printUnivList()函数
注意:这里的{:^10}表示取10位居中对齐,^是居中对齐,\t是横向制表符。

ok,主要代码完成,希望可以帮到你。
python爬虫学习心得:中国大学排名(附代码)的更多相关文章
- python爬虫学习心得
作为一名python的忠实爱好者,我开始接触爬虫是在2017年4月份,最开始接触它的时候遇到两个梗,一个是对python还不算太了解(当然现在也仍然在努力学习它的有关内容),二是对爬虫心怀一份敬畏之心 ...
- Python爬虫学习第一记 (翻译小助手)
1 # Python爬虫学习第一记 8.24 (代码有点小,请放大看吧) 2 3 #实现有道翻译,模块一: $fanyi.py 4 5 import urllib.request 6 import u ...
- Python之爬虫-中国大学排名
Python之爬虫-中国大学排名 #!/usr/bin/env python # coding: utf-8 import bs4 import requests from bs4 import Be ...
- python网络爬虫-中国大学排名定向爬虫
爬虫定向爬取中国大学排名信息 #!/usr/bin/python3 import requests from bs4 import BeautifulSoup import bs4 #从网络上获取大学 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
随机推荐
- X86架构CPU常识(主频,外频,FSB,cpu位和字长,倍频系数,缓存,CPU扩展指令集,CPU内核和I/O工作电压,制造工艺,指令集,超流水线与超标量)
1.主频 主频也叫时钟频率,单位是MHz,用来表示CPU的运算速度. CPU的主频=外频×倍频系数.很多人认为主频就决定着CPU的运行速度,这不仅是个片面的,而且对于服务器来讲,这个认识也出现了偏差. ...
- Chapter 02—Creating a dataset(Part3-补充材料Stat/Transfer)
Stat/Transfer:在电子表格(worksheet),数据库(database),统计包(statistical package)间进行数据转换,具有简单高效的特点. 资料来源于:http:/ ...
- css实现等边六边形
在平时的页面布局中,我们也会经常碰到蜂窝煤类型的模块: 那么我们把他拆开,就是单个的六边形,如何用css去实现一个六边形呢?下面是我用绘图软件绘制的css实现六边形的步骤: 具体的html代码如下: ...
- php方法注释
注释格式 <?php /** * @method 发送邮件 * @url email/send?token=xxx * @http POST * @param token string [必填] ...
- requests库核心API源码分析
requests库是python爬虫使用频率最高的库,在网络请求中发挥着重要的作用,这边文章浅析requests的API源码. 该库文件结构如图: 提供的核心接口在__init__文件中,如下: fr ...
- 漫谈LiteOS之开发板-串口(基于GD32450i-EVAL)
[摘要] 主要讲解物联网的技术积累,本期我们先带领大家学习漫谈LiteOS之漫谈开发板第一集-串口,本文基于GD32450i-EVAL对串口以及其通信做了一个简要的分析,以及开发过程中遇到的一些技术 ...
- 如何使用pandas分析金融数据
[摘要]pandas是数据分析师分析数据最常用的三方库之一,结合matplotlib,非常强大. 首先我们收集一些数据. 从东方财富客户端导出券商信托板块2018年11月1日的基础行情和财务数据.分别 ...
- base64转图片、图片转base64、图片拼接、加水印(水印角度可设置)
/** * @Description: 将base64编码字符串转换为图片 * @param imgStr * base64编码字符串 * @param path * 图片路径-具体到文件 * @re ...
- 在Eclipse中混合Java和Scala编程
1. 新建项目目录 scala-java-mix 2. 创建 src 目录及子目录: mkdir -p src/main/java mkdir -p src/main/scala 3. 在目录 sca ...
- Django开发登录功能实战
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:凡夫俗子66 Django 如果是定义函数写登录路由,需要判断请求方法 ...