推荐系统| ① Movies概述
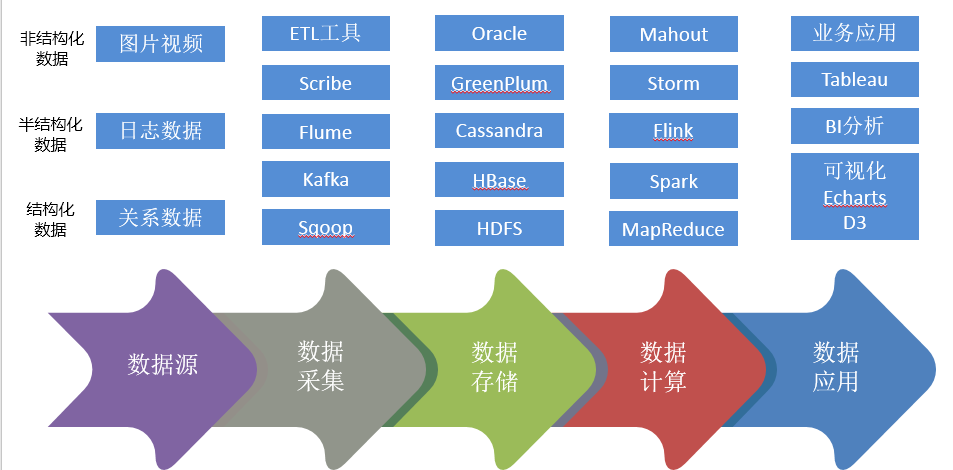
数据生命周期
项目系统架构
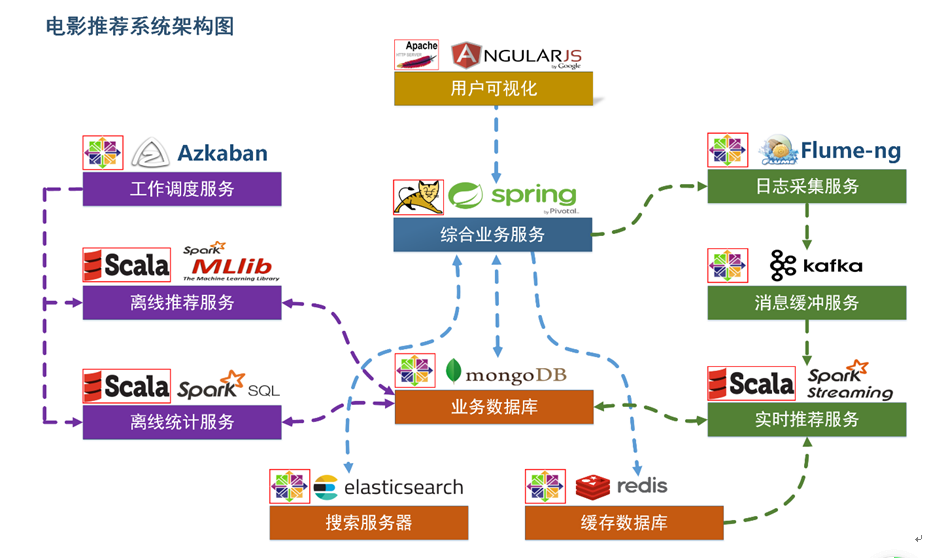
用户可视化:主要负责实现和用户的交互以及业务数据的展示,主体采用AngularJS2进行实现,部署在Apache服务上。
综合业务服务:主要实现JavaEE层面整体的业务逻辑,通过Spring进行构建,对接业务需求。部署在Tomcat上。
【数据存储部分】
业务数据库:项目采用广泛应用的文档数据库MongDB作为主数据库,主要负责平台业务逻辑数据的存储。
搜索服务器:项目爱用ElasticSearch作为模糊检索服务器,通过利用ES强大的匹配查询能力实现基于内容的推荐服务。
缓存数据库:项目采用Redis作为缓存数据库,主要用来支撑实时推荐系统部分对于数据的高速获取需求。
【离线推荐部分】
离线统计服务:批处理统计性业务采用Spark Core + Spark SQL进行实现,实现对指标类数据的统计任务。
离线推荐服务:离线推荐业务采用Spark Core + Spark MLlib进行实现,采用ALS算法进行实现。
工作调度服务:对于离线推荐部分需要以一定的时间频率对算法进行调度,采用Azkaban进行任务的调度。
【实时推荐部分】
日志采集服务:通过利用Flume-ng对业务平台中用户对于电影的一次评分行为进行采集,实时发送到Kafka集群。
消息缓冲服务:项目采用Kafka作为流式数据的缓存组件,接受来自Flume的数据采集请求。并将数据推送到项目的实时推荐系统部分。
实时推荐服务:项目采用Spark Streaming作为实时推荐系统,通过接收Kafka中缓存的数据,通过设计的推荐算法实现对实时推荐的数据处理,并将结构合并更新到MongoDB数据库。
项目数据流程
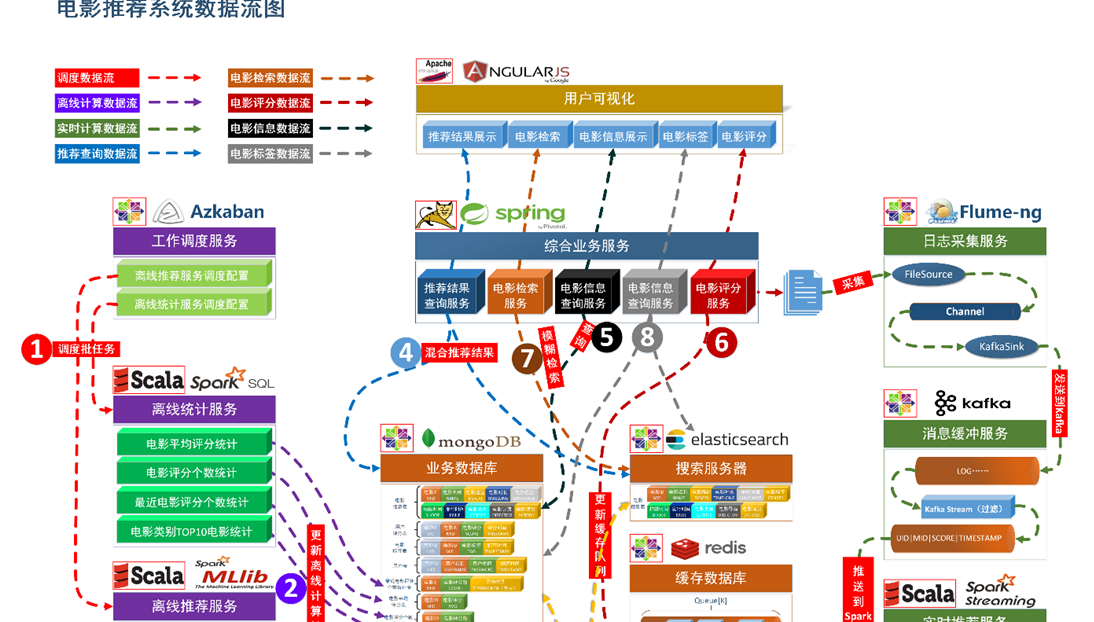
【系统初始化部分】
- 通过Spark SQL将系统初始化数据加载到MongoDB和ElasticSearch中。
【离线推荐部分】
- 通过Azkaban实现对于离线统计服务以离线推荐服务的调度,通过设定的运行时间完成对任务的触发执行。
- 离线统计服务从MongoDB中加载数据,将【电影平均评分统计】、【电影评分个数统计】、【最近电影评分个数统计】三个统计算法进行运行实现,并将计算结果回写到MongoDB中;离线推荐服务从MongoDB中加载数据,通过ALS算法分别将【用户推荐结果矩阵】、【影片相似度矩阵】回写到MongoDB中。
【实时推荐部分】
- Flume从综合业务服务的运行日志中读取日志更新,并将更新的日志实时推送到Kafka中;Kafka在收到这些日志之后,通过kafkaStream程序对获取的日志信息进行过滤处理,获取用户评分数据流【UID|MID|SCORE|TIMESTAMP】,并发送到另外一个Kafka队列;Spark Streaming监听Kafka队列,实时获取Kafka过滤出来的用户评分数据流,融合存储在Redis中的用户最近评分队列数据,提交给实时推荐算法,完成对用户新的推荐结果计算;计算完成之后,将新的推荐结构和MongDB数据库中的推荐结果进行合并。
【业务系统部分】
- 推荐结果展示部分,从MongoDB、ElasticSearch中将离线推荐结果、实时推荐结果、内容推荐结果进行混合,综合给出相对应的数据。
- 电影信息查询服务通过对接MongoDB实现对电影信息的查询操作。
- 电影评分部分,获取用户通过UI给出的评分动作,后台服务进行数据库记录后,一方面将数据推动到Redis群中,另一方面,通过预设的日志框架输出到Tomcat中的日志中。
- 项目通过ElasticSearch实现对电影的模糊检索。
- 电影标签部分,项目提供用户对电影打标签服务。
加载数据
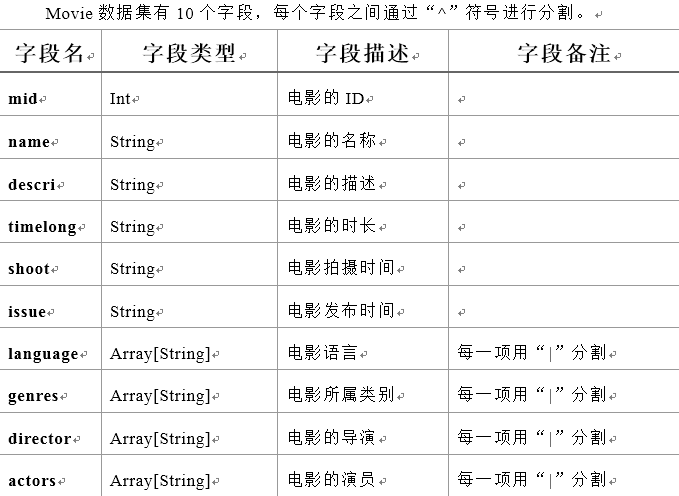
Movies数据集 电影数据表
数据格式:
- mid,name,descri,timelong,issue,shoot,language,genres,actors,directors
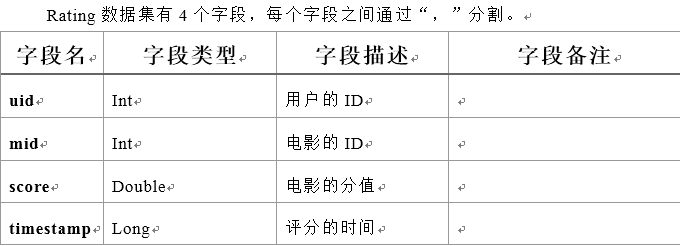
Ratings数据集 用户评分表
数据格式:
- userId,movieId,rating,timestamp
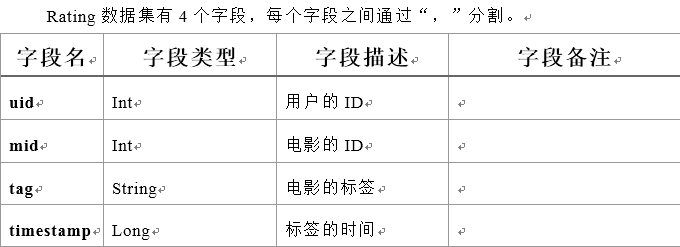
Tag数据集 电影标签表
数据格式:
- userId,movieId,tag,timestamp
日志管理配置文件
log4j对日志的管理,需要通过配置文件来生效。在src/main/resources下新建配置文件log4j.properties,写入以下内容:
- log4j.rootLogger=info, stdout
- log4j.appender.stdout=org.apache.log4j.ConsoleAppender
- log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
- log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n
数据初始化到MongoDB、ElasticSearch
数据加载程序主体:
为原始数据定义几个样例类,通过SparkContext的textFile方法从文件中读取数据,并转换成DataFrame,再利用Spark SQL提供的write方法进行数据的分布式插入。
在DataLoader/src/main/scala下新建package;
将数据写入MongoDB 写入ElasticSearch
接下来,实现storeDataInMongo方法,将数据写入mongodb中:
同样主要通过Spark SQL提供的write方法进行数据的分布式插入,实现storeDataInES方法:
\MovieRecommendSystem\recommender\DataLoader\src\main\scala\com\xxx\DataLoader\DataLoader.scala
推荐系统| ① Movies概述的更多相关文章
- 【机器学习实战】第14章 利用SVD简化数据
第14章 利用SVD简化数据 SVD 概述 奇异值分解(SVD, Singular Value Decomposition): 提取信息的一种方法,可以把 SVD 看成是从噪声数据中抽取相关特征.从生 ...
- 深度召回模型在QQ看点推荐中的应用实践
本文由云+社区发表 作者:腾讯技术工程 导语:最近几年来,深度学习在推荐系统领域中取得了不少成果,相比传统的推荐方法,深度学习有着自己独到的优势.我们团队在QQ看点的图文推荐中也尝试了一些深度学习方法 ...
- 转】用Mahout构建职位推荐引擎
原博文出自于: http://blog.fens.me/hadoop-mahout-recommend-job/ 感谢! 用Mahout构建职位推荐引擎 Hadoop家族系列文章,主要介绍Hadoop ...
- 大数据入门第十九天——推荐系统与mahout(一)入门与概述
一.推荐系统概述 为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统.其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录 ...
- 用 Mahout 和 Elasticsearch 实现推荐系统
原文地址 本文内容 软件 步骤 控制相关性 总结 参考资料 本文介绍如何用带 Apache Mahout 的 MapR Sandbox for Hadoop 和 Elasticsearch 搭建推荐引 ...
- "淘宝推荐系统简介"分享总结
概述: 此分享是关于淘宝推荐系统简介 1.推荐引擎就是:如何找到用户感兴趣的东西和以什么形式告诉用户:2.推荐引擎的作用:提高用户忠诚度,提高成交转化率和提高网站交叉销售能力:3.推荐系统核心:产品, ...
- 基于Mahout的电影推荐系统
基于Mahout的电影推荐系统 1.Mahout 简介 Apache Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域 ...
- Sparklyr与Docker的推荐系统实战
作者:Harry Zhu 链接:https://zhuanlan.zhihu.com/p/21574497 来源:知乎 著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 相关内容: ...
- 第三篇:一个Spark推荐系统引擎的实现
前言 经过2节对MovieLens数据集的学习,想必读者对MovieLens数据集认识的不错了:同时也顺带回顾了些Spark编程技巧,Python数据分析技巧. 本节将是让人兴奋的一节,它将实现一个基 ...
随机推荐
- 使用aop切面编写日志模块
我们先自定义一个注解(一个有关自定义注解的LJ文章 https://www.cnblogs.com/guomie/p/10824973.html) /** * * 自定义日志注解 * Retentio ...
- python学习-pandas
import pandas as pd # DataForm 二维数据# print(pd.read_excel("datas.xlsx")) # 多行数据 - 加载表单s = p ...
- android studio 项目生成的apk变小的原因
问题:感觉直接在apk文件夹下面拷出来的apk不能安装使用,而且apk比较小,可能就是这个问题引起的 Android Studio版本升级到2.3后,增加了instant run功能,对项目的buil ...
- 使用Portainer集中管理多地域内网运行的Docker实例
1. 单机运行的Docker 容器化部署是现在进行时,开源应用大多数支持容器化部署 在少量机器的场景下往往采用docker cli 和 docker-compose管理,进行"单机式管理&q ...
- 【搞定Jvm面试】 JDK监控和故障处理工具揭秘
本文已经收录自笔者开源的 JavaGuide: https://github.com/Snailclimb ([Java学习+面试指南] 一份涵盖大部分Java程序员所需要掌握的核心知识)如果觉得不错 ...
- 面试连环炮系列(二十三): StringBuffer与StringBuild的区别
StringBuffer与StringBuild的区别 频繁修改字符串时,建议使用StringBuffer和StringBuilder类.StringBuilder相较于StringBuffer有速度 ...
- Python爬虫入门CentOS环境安装
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:梦想橡皮擦 CentOS环境安装-简介你好,当你打开这个文档的时候,我知 ...
- 一起学MyBatis之入门篇(2)
概述 本文主要讲解MyBatis中类型转换的功能,其实在MyBatis中,提供了默认的数据类型之间的转换,但只是基本数据类型的转换,如果跨类型进行转换,则需要自定义转换类,如java中是boolean ...
- Java基础语法09-面向对象下-内部类
九.内部类 将一个类A定义在另一个类B里面,里面的那个类A就称为内部类,B则称为外部类. (1)成员内部类:声明在外部类中方法外 静态成员内部类 非静态成员内部类 (2)局部内部类:声明在外部类的方法 ...
- python安装pymssql等包时出现microsoft visual c++ 14.0 is required问题无需下载visualcppbuildtools的解决办法
如题,在练习python安装一些包时,出现了microsoft visual c++ 14.0 is required问题.网上有很多资料:一是下载对应的.whl文件,然后pip install安装: ...