python爬虫笔记之爬取足球比赛赛程
目标:爬取某网站比赛赛程,动态网页,则需找到对应ajax请求(具体可参考:https://blog.csdn.net/you_are_my_dream/article/details/53399949)
- # -*- coding:utf-8 -*-
- import sys
- import re
- import urllib.request
- link = "https://***"
- r = urllib.request.Request(link)
- r.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36')
- html = urllib.request.urlopen(r,timeout=500).read()
- html = bytes.decode(html,encoding="gbk")
#返回大量json,需提取- #找出返回json中对应正则匹配的字符串
- js = re.findall('"n":"(.*?)"',html)
- i=0
- #循环打印比赛信息
- try:
- while(1):
#将字符串Unicode转化为中文,并输出- print (js[i].encode('utf-8').decode('unicode_escape'),js[i+1].encode('utf-8').decode('unicode_escape'),"VS",js[i+2].encode('utf-8').decode('unicode_escape'))
- i=i+3
#当所有赛程爬取结束时,会报错“IndexError:list index out of range”,所以进行异常处理- except IndexError:
- print ("finished")
总结注意点:
1、python 3 采用这个import urllib.request
因为urllib和urllib2合体了。
2、字符串Unicode转为中文需注意python3与python2的表示方法不同:
python3:print 字符串.encode('utf-8').decode('unicode_escape')
python2:print 字符串.decode('unicode_escape')
3、re.findall()
关于这个函数,他的输出内容规律可以参考我之前写的:http://www.cnblogs.com/4wheel/p/8497121.html
【"n":"(.*?)"】 这个表达式只输出(.*?)这部分(为什么,还是参考我之前写的那篇文章),加上问号就是非贪婪模式,不加就是贪婪模式,顺便实践解释下贪婪模式
example:
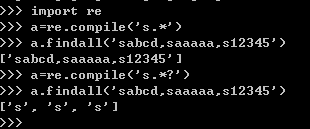
总结:非贪婪模式就是在满足正则表达式的情况下,尽可能少的匹配。
相反,贪婪模式就是在满足正则表达式的情况下,尽可能多的匹配。
so,爬取结果为:

python爬虫笔记之爬取足球比赛赛程的更多相关文章
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
Python爬虫教程-17-ajax爬取实例(豆瓣电影) ajax: 简单的说,就是一段js代码,通过这段代码,可以让页面发送异步的请求,或者向服务器发送一个东西,即和服务器进行交互 对于ajax: ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
随机推荐
- Natively Compiled Code: A Comeback?
RAD Studio and Natively Compiled Code In today's development landscape, natively compiled code is ma ...
- 开源中国的 IT 公司开源软件整理计划介绍
直击现场 <HTML开发MacOSApp教程> http://pan.baidu.com/s/1jG1Q58M 开源中国的 IT 公司开源软件整理计划介绍 oschina 发布于: 20 ...
- QT---Native Wifi functions 应用(WiFi有密码连接)
实现功能 无线网卡列表 无线热点扫面 无线连接(有密码,配置文件连接方式) 无线断开 重命名本地无线名(两种方式) 删除无线配置文件 开启和关闭 ...
- C++实现半透明按钮控件(PNG,GDI+)
http://blog.csdn.net/witch_soya/article/details/6889904
- Gps坐标有效性判定
百科:纬度 是指某点与地球球心的连线和地球赤道面所成的线面角,其数值在0至90度之间.位于赤道以北的点的纬度叫北纬,记为N:位于赤道以南的点的纬度称南纬,记为S. var regex = new Re ...
- reset.css(样式重置)
CSS Reset,意为重置默认样式.HTML中绝大部分标签元素在网页显示中都有一个默认属性值,通常为了避免重复定义元素样式,需要进行重置默认样式(CSS Reset).举几个例子:1.淘宝(CSS ...
- Nginx多种负载均衡策略搭建
背景介绍 上篇介绍了利用Nginx反向代理实现负载均衡,本文详细讲述Nginx下的几种负载均衡策略. 轮询 轮询,顾名思义,就是轮流请求,基于上篇文章的介绍,我们将负载均衡策略聚焦于default.c ...
- 你的http需要“爱情”
目的是为了更白话的认识http,面对业内人,还有一些吃瓜的... 故事背景描述: 男猪脚在情人节这天给他女票发送了一条信息,"I love U",女主角收到后很开心,也回复了一条信 ...
- 【实战】SpringBoot + KafKa
1.配置pom包 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId& ...
- HBase 学习之路(五)——HBase常用 Shell 命令
一.基本命令 打开Hbase Shell: # hbase shell 1.1 获取帮助 # 获取帮助 help # 获取命令的详细信息 help 'status' 1.2 查看服务器状态 statu ...