Python 学习 第17篇:从SQL Server数据库读写数据
在Python语言中,从SQL Server数据库读写数据,通常情况下,都是使用sqlalchemy 包和 pymssql 包的组合,这是因为大多数数据处理程序都需要用到DataFrame对象,它内置了从数据库中读和写数据的函数:read_sql()和to_sql(),这两个函数支持的连接类型是由sqlalchemy和pymssql构成的,因此,掌握这两个包对于查询SQL Server数据库十分必要。
SQLAlchemy的架构
在Python语言环境中,当需要和关系型数据进行交互时,SQLAlchemy是事实上的标准包。SQLAlchemy由两个截然不同的组件组成,称为Core和ORM(Object Relational Mapper,对象关系映射器),Core是功能齐全的数据库工具包,使用SQL 脚本来查询数据库;ORM是基于Core的可选包,把数据库对象抽象成表、列、关系等实体。但是SQLAlchemy本身无法操作数据库,需要pymsql等第三方数据库API(Database API ),简写为 DBAPI,根据数据库类型而调用不同的数据库API。
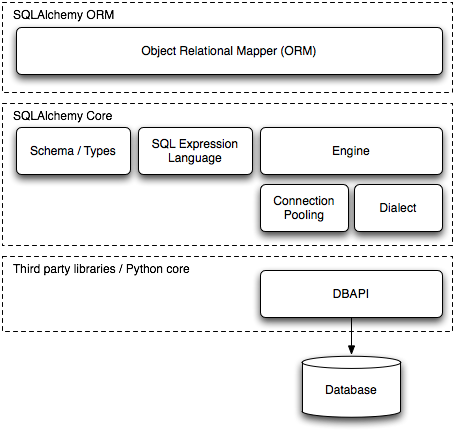
从上图可以看出,SQLAlchemy的Core组件使用DBAPI来和数据库进行交互,当使用SQL脚本对数据库执行查询和修改操作时,必须用到SQLAlchemy的 Engine 和 Connection 对象。
一,SQLAlchemy的Engine和Connection
使用SQLAlchemy从数据库中读写数据的基本用法:通过SQL 语句更新数据,通过DataFrame的read_sql()函数从数据库中读取数据,通过to_sql()函数把数据写入到数据表中。
1,创建Engine
在对数据库执行读写操作之前,必须连接到数据库。SQLAlchemy通过 create_engine () 函数创建Engine,使用Engine管理DBAPI的连接,DBAPI的连接仅仅表示一种连接资源。应用Engine最有效率的方式是在模块级别创建一次,而不是按照对象或函数来调用。
import pymssql
import sqlalchemy
from sqlalchemy import create_engine connection_format = 'mssql+pymssql://{0}:{1}@{2}/{3}?charset=utf8'
connection_str = connection_format.format(db_user,db_password,db_host,db_name)
engine = create_engine(connection_str,echo=False)
连接字符串的URL格式是:
dialect[+driver]://user:password@host/dbname?charset=utf8
其中,dialect 代表数据库类型,比如 mssql、mysql等,driver 代表DBAPI的类型,比如 psycopg2、pymysql等。
当echo参数为True时,会显示执行的SQL语句,推荐把echo设置False,关闭日记功能。
Engine对象可以直接用于向数据库发送SQL 脚本,调用Engine.execute()函数执行SQL脚本:
2,Engine和Connection
最通用的方法是通过Engine.connect()方法获得连接资源,connection 是Connection的一个实例,是DBAPI连接的一个代理对象。
connection = engine.connect()
result = connection.execute("select username from users")
for row in result:
print("username:", row['username'])
connection.close()
result是ResultProxy的一个实例,该实例引用DBAPI的cursor。如果执行SELECT命令,当把所有的数据行都返回时,ResultProxy将自动关闭DBAPI的游标。如果执行UPDATE命令,不返回任何数据行,在命令执行之后,游标立即释放资源。
当connection显式调用close()函数时,应用的DBAPI 连接会被释放到连接池(connection pool)。
可以使用Engine对象的execute()函数,以一种简单的方式执行上述过程:
result = engine.execute("select username from users")
for row in result:
print("username:", row['username'])
二,显式使用事务
Connection对象提供begin()函数显式开始一个事务(Transaction)对象,该对象通常用于try/except代码块中,以保证调用Transaction.rollback() 或 Transaction.commit()。
connection = engine.connect()
tran = connection.begin()
try:
connection.execute('sql statement')
tran.commit()
except:
tran.rollback()
raise
或者使用上下文管理器编写更简单的代码:
with connection.begin() as tran:
connection.execute('sql statement')
三,自动提交事务
SQLAlchemy 实现了autocommit 功能,在当前没有显式开启事务的情况下,如果SQLAlchemy 检测(Detect)到执行的数据修改命令(比如 INSERT、UPDATE、DELETE)或数据定义命令(比如,CREATE TABLE, ALTER TABLE),那么Connection对象会自动提交事务。
conn = engine.connect()
conn.execute("INSERT INTO users VALUES (1, 'john')") # autocommits
如果设置选项autocommit=True(默认为True),那么检测会自动进行。如果执行的纯文本的SQL语句,并且语句中包含数据修改和数据定义命令,那么自动提交事务。
可以使用Connection.execution_options()方法来设置autocommit选项,实现自动提交的完全控制:
engine.execute(text("SELECT my_mutating_procedure()").execution_options(autocommit=True))
四,执行SELECT查询
使用Engine 或 Connection的execute()函数执行select查询,返回游标变量。游标标量是一个迭代器,每次迭代返回的结果都是一个数据行,数据行是由字段构成的元组:
>>> cursor = engine.execute(' select * from dbo.vic_test')
>>> for row in cursor:
... do_something
也可以使用DataFrame对象的read_sql()函数,把数据读取到DataFrame对象中,或者调用DataFrame对象的to_sql()函数,把DataFrame对象中的数据写入到关系表中。
五,使用原始的DBAPI连接
在某些情况下,SQLAlchemy 无法提供访问某些DBAPI函数的通用方法,例如,调用存储以及处理多个结果集,在这种情况下,直接使用原始DBAPI的连接。
dbapi_conn = engine.raw_connection()
该dbapi_conn是一种代理形式,当调用dbapi的close()方法时,实际上并没有关闭DBAPI的连接,而是把其释放会连接池:
dbapi_conn.close()
例如,使用DBAPI的原始连接来调用存储过程,通过DBAPI级别的callpro()函数来执行存储过程:
connection = engine.raw_connection()
try:
cursor = connection.cursor()
cursor.callproc("my_procedure", ['x', 'y', 'z'])
results = list(cursor.fetchall())
cursor.close()
connection.commit()
finally:
connection.close()
pymssql 包
pymssql包是Python语言用于连接SQL Server数据库的驱动程序(或者称作DBAPI),它是最终和数据库进行交互的工具。SQLAlchemy包就是利用pymssql包实现和SQL Server数据库交互的功能的。
按照惯例,使用pymssql包查询数据库之前,首先创建连接:
import pymssql
conn = pymssql.connect(host='host',database='db_name',user='user',password='pwd',charset='utf8')
通过连接创建游标,通过游标执行SQL语句,查询数据或对数据进行更新操作:
cursor = conn.cursor()
cursor.execute("sql statement")
如果执行的是修改操作,需要提交事务;如果执行的是查询操作,不需要提交:
conn.commit()
在查询完成之后,关闭连接
conn.close()
六,使用游标查询数据
游标cursor是由连接创建的对象,可以在游标中执行查询,并设置数据返回的格式。
当执行select语句获取数据时,返回的数据行有两种格式:元组和字典,行的默认格式是元组。
cursor = conn.cursor(as_dict=True)
pymssql返回的数据集的格式是在创建游标时设置的,当参数 as_dict为True时,返回的行是字典格式,该参数的默认值是False,因此,默认的行格式是元组。
由于游标是一个迭代器,因此,可以使用for语句以迭代方式逐行处理查询的结果集。
for row in cursor:
1,以元组方式返回数据行
默认情况下,游标返回的每一个数据行,都是一个元组结构:
cursor=connect.cursor()
cursor.execute('SELECT * FROM persons WHERE salesrep=%s', 'John Doe')
for row in cursor:
print('row = %r' % (row,))
2,以字典方式返回数据行
当设置游标以字典格式返回数据时,每一行都是一个字典结构:
cursor = conn.cursor(as_dict=True)
cursor.execute('SELECT * FROM persons WHERE salesrep=%s', 'John Doe')
for row in cursor:
print("ID=%d, Name=%s" % (row['id'], row['name']))
七,使用游标更新数据
在执行update、delete或insert命令对数据进行更新时,需要显式提交事务。
1,执行单条语句修改数据
当需要更新数据时,调用游标的execute()函数执行SQL命令来实现,可以以参数化的方式来执行,参数化类似于python的string.format()函数,通过格式化的字符串、占位符和参数来生成TSQL脚本。
cursor.execute(operation)
cursor.execute(operation, params)
通过游标的execute()函数来执行TSQL语句,调用 commit() 来提交事务
cursor.execute("""
sql statement
""")
conn.commit()
或者以参数化的方式来执行:
cursor.execute("update id=1 FROM persons WHERE salesrep='%s'", 'John Doe')
conn.commit()
2,执行数据的多行插入
如果要在一个事务中执行多条SQL命令,可以调用游标的executemany()函数:
cursor.executemany(operation, params_seq)
如果需要插入多条记录,可以使用游标的executemany()函数,该函数包含模板SQL 命令和一个格式化的参数列表,用于在一条事务中插入多条记录:
args=[(1, 'John Smith', 'John Doe'),
(2, 'Jane Doe', 'Joe Dog'),
(3, 'Mike T.', 'Sarah H.')] cursor.executemany("INSERT INTO persons VALUES (%d, %s, %s)", args )
conn.commit()
八,关闭连接
在一个连接中,用户可以提交多个事务,执行多个操作。当查询完成之后,一定要关闭连接:
conn.close()
通常情况下,使用with来自动关闭连接:
with pymssql.connect(host='host',database='db_name', user='user', password='pwd',charset='utf8') as conn:
with conn.cursor(as_dict=True) as cursor:
cursor.execute('SELECT * FROM persons WHERE salesrep=%s', 'John Doe')
for row in cursor:
print("ID=%d, Name=%s" % (row['id'], row['name']))
九,调用存储过程
从pymssql 2.0.0开始,可以使用callproc函数来执行存储过程,callproc()函数的语法是:
result_args = cursor.callproc(proc_name, args=())
args参数是一个序列,对于存储过程的每一个参数,都需要传递值。对于OUT参数,也必须传递值,通常传递0。
callproc()函数返回的是输入args的修改之后的副本,IN参数在result_args中不变,OUT参数在result_args中代表存储过程输出的值。
举个例子,对于存储add_num,有两个IN参数,一个OUT参数:
CREATE PROCEDURE add_num(IN num1 INT, IN num2 INT, OUT sum INT)
调用callproc()函数的格式是:
result_args = (5, 6, 0) # 0 is to hold value of the OUT parameter sum
cursor.callproc('add_num', result_args)
以下示例代码,使用上下文管理器来调用callproc()执行存储过程:
with pymssql.connect(server, user, password, "tempdb") as conn:
with conn.cursor(as_dict=True) as cursor:
cursor.callproc('sp_name', ('arg1',))
for row in cursor:
print("ID=%d, Name=%s" % (row['id'], row['name']))
参考文档:
Working with Engines and Connections
Python 学习 第17篇:从SQL Server数据库读写数据的更多相关文章
- 如何用asp.net MVC框架、highChart库从sql server数据库获取数据动态生成柱状图
如何用asp.net MVC框架.highChart库从sql server数据库获取数据动态生成柱状图?效果大概是这样的,如图: 请问大侠这个这么实现呢?
- 01. SQL Server 如何读写数据
原文:01. SQL Server 如何读写数据 一. 数据读写流程简要SQL Server作为一个关系型数据库,自然也维持了事务的ACID特性,数据库的读写冲突由事务隔离级别控制.无论有没有显示开启 ...
- SQL Server 如何读写数据
01. SQL Server 如何读写数据 一. 数据读写流程简要SQL Server作为一个关系型数据库,自然也维持了事务的ACID特性,数据库的读写冲突由事务隔离级别控制.无论有没有显示开启事 ...
- 漫谈可视化Prefuse(一)---从SQL Server数据库读取数据
上篇<可视化工具solo show-----Prefuse自带例子GraphView讲解>主要介绍了整个Prefuse工具集具有的一些特征.框架的运行流程,分析并展现了官方提供的例子Gra ...
- python:利用pymssql模块操作SQL server数据库
python默认的数据库是 SQLlite,不过它对MySql以及SQL server的支持也可以.这篇博客,介绍下如何在Windows下安装pymssql库并进行连接使用... 环境:Windows ...
- SQL Server数据库读取数据的DateReader类及其相关类
之前学了几天的SQL Server,现在用C#代码连接数据库了. 需要使用C#代码连接数据库,读取数据. 涉及的类有: ConfigurationManage SqlConnection SqlCom ...
- Jmeter—8 连接microsoft sql server数据库取数据
本文以Jmeter 连接microsoft sql server为例. 1 从微软官网下载Microsoft SQL Server JDBC Driver 地址:http://www.microsof ...
- SQL Server数据库读写分离提高并发性
在一些大型的网站或者应用中,单台的SQL Server 服务器可能难以支撑非常大的访问压力.很多人在这时候,第一个想到的就是一个解决性能问题的利器——负载均衡.遗憾的是,SQL Server 的所有版 ...
- 用SQL语句将远程SQL Server数据库中表数据导入到本地数据库相应的表中
一.方法一 访问不同电脑上的数据库(远程访问,只好联好网就一样),如果经常访问或数据量较大,建议用链接服务器方法. 1.创建链接服务器 exec sp_addlinkedserver ‘srv_lnk ...
随机推荐
- java高并发系列 - 第5天:深入理解进程和线程
进程 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础.程序是指令.数据及其组织形式的描述,进程是程序的实体. 进程具有的 ...
- sql server pivot
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE [dbo].[YearSalary]( [year] [int] NULL, ...
- python基础(27):类成员的修饰符、类的特殊成员
1. 类成员的修饰符 类的所有成员在上一步骤中已经做了详细的介绍,对于每一个类的成员而言都有两种形式: 公有成员,在任何地方都能访问 私有成员,只有在类的内部才能方法 私有成员和公有成员的定义不同:私 ...
- android studio 出现找不到R文件的错误
百度知道: 检查是否编译了项目.Android studio有时候没有编译就会报出没有R文件的错误. 检查带代码中包名是否正确.有时候从其他地方复制代码过来时连带了包名,也会报出R文件找不到. 检查布 ...
- JAVA笔记 -- this关键字
this关键字 一. 基本作用 在当前方法内部,获得当前对象的引用.在引用中,调用方法不必使用this.method()这样的形式来说明,因为编译器会自动的添加. 必要情况: 为了将对象本身返回 ja ...
- vue浏览器全屏实现
1.项目中使用的是sreenfull插件,执行命令安装 npm install --save screenfull 2.安装好后,引入项目,用一个按钮进行控制即可,按钮方法如下: toggleFull ...
- 安卓开发笔记(三十四):Material Design框架实现优美的左侧侧滑栏
首先我们先上图: 下面是主页面的代码,activity_main.xml: <?xml version="1.0" encoding="utf-8"?& ...
- Spinner在Dialog中的使用效果
版权声明:本文为xing_star原创文章,转载请注明出处! 本文同步自http://javaexception.com/archives/91 背景: 记得很久以前,碰到一个需求场景,需要在Andr ...
- 一文带你彻底理解Linux的各种终端类型及概念
每天使用Linux每天都要接触到Bash,使用Bash时似乎永远都让人摸不着头脑的概念就是终端,坐在这台运行着Linux的机器的显示器前面,这个显示器就是终端的输出,而插在机器上的USB键盘或者PS/ ...
- CentOS添加用户,管理员权限
原文链接:https://www.linuxidc.com/Linux/2012-03/55629.htm 1.添加普通用户 [root@server ~]# useradd admin ...