scrapy框架安装配置
scrapy介绍
Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方
式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API
所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异
步)的代码来实现并发。整体架构大致如下

1.引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
2.调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个
要抓取的网址是什么, 同时去除重复的网址
3.下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
4.爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
5.项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
6.下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的
响应response,你可用该中间件做以下几件事
1. process a request just before it is sent to the Downloader (i.e. right before Scrapy sends the request to the website);
2. change received response before passing it to a spider;
3. send a new Request instead of passing received response to a spider;
4. pass response to a spider without fetching a web page;
5. silently drop some requests.
7.爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
scrapy安装(win)
安装
1.pip insatll wheel #支持本地安装的模块
pip install lxml
pip install pyopenssl
2.下载合适的版本的twisted:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
3.安装twisted,到同一个目录,然后pip install
4.pip install pywin32
5.pip intstall scrapy
如果:在终端输入scrapy没有问题就是安装成功了
命令行常用指令
#创建工程
scrapy startproject name
#创建爬虫文件
scrapy genspider spiderName www.xxx.com
#执行爬虫任务
scrapy crawl 工程名字
其他命令
#查看帮助
scrapy -h
scrapy <command> -h
#有两种命令:其中Project-only必须切到项目文件夹下才能执行,而Global的命令则不需要
Global commands:
startproject #创建项目
genspider #创建爬虫程序
settings #如果是在项目目录下,则得到的是该项目的配置
runspider #运行一个独立的python文件,不必创建项目
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求
version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本
Project-only commands:
crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False
check #检测项目中有无语法错误
list #列出项目中所包含的爬虫名
爬虫文件信息
# -*- coding: utf-8 -*-
import scrapy
class ZxSpider(scrapy.Spider):
#工程名称,唯一标志
name = 'zx'
#允许爬取的域名(一般不用)
# allowed_domains = ['www.baidu.com']
#起始爬取的url,可以是多个
start_urls = ['http://www.baidu.com/',"https://docs.python.org/zh-cn/3/library/index.html#library-index"]
#回调函数,返回请求回来的信息
def parse(self, response):
print(response)
配置文件修改(setting.py)
修改UA和是否遵守爬虫协议 添加日志打印等级
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'zx_spider (+http://www.yourdomain.com)'
# Obey robots.txt rules,君子协议不遵守
ROBOTSTXT_OBEY = True
LOG_LEVEL='ERROR'
最后测试下配置成功没有
简单案例(爬段子)
# -*- coding: utf-8 -*-
import scrapy
class DuanziSpider(scrapy.Spider):
name = 'duanzi'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://duanziwang.com/']
def parse(self, response):
div_list=response.xpath('//main/article')
for i in div_list:
title=i.xpath('.//h1/a/text()').extract_first()
#xpath返回的是存放selector对象的列表,想要拿到数据需要调用extract()函数取出内容,如果列表长度为1可以使用extract_first()
content=i.xpath('./div[@class="post-content"]/p/text()').extract_first()
print(title)
print(content)
执行流程
五大核心组件
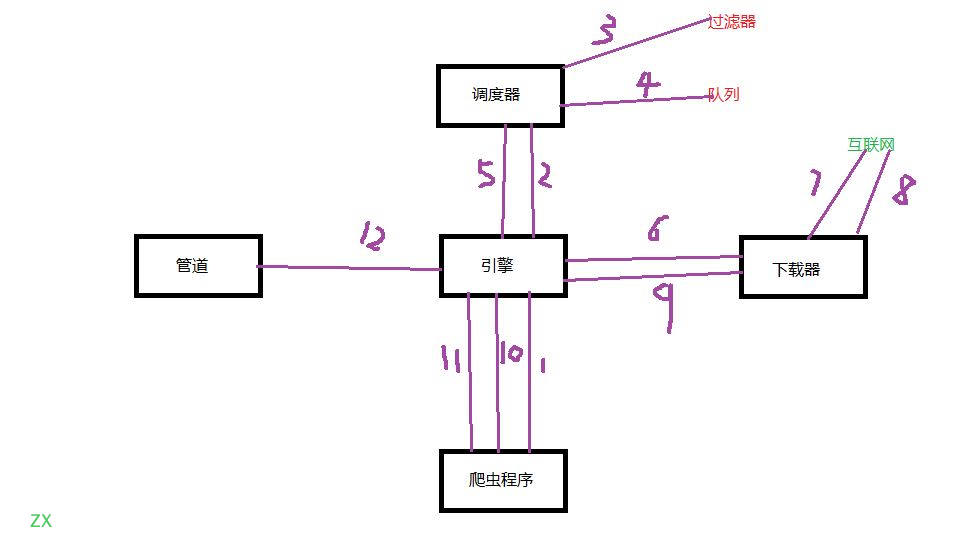
引擎(Scrapy)
(创建对象,根据数据调度方法等)
用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
执行流程
1.爬虫程序将url封装后发送给引擎
2.引擎拿到url后,把它给调度器
3.调度器首先过滤重复的url
4.将过滤好的url压入队列
5.将队列发给引擎
6.引擎将队列发给下载器
7.下载器向互联网请求数据
8.获取数据
9.将数据response发给引擎
10.引擎将数据发给爬虫程序的回调
11.数据处理好,在此发给引擎
12.引擎将数据发给管道,由管道进行数据的持久化存储
配置run文件启动项目
1.新建run.py
2.
from scrapy.cmdline import execute
execute(['scrapy','crawl','jd'])
高级设置
修改初始请求
#默认初始请求是这个
start_urls = ['https://www.jd.com']
#重写__init__()函数(qs)
def __init__(self,qs=None,*args,**kwargs):
super(JdSpider,self).__init__(*args,**kwargs)
self.api = "http://list.tmall.com/search_product.htm?"
self.qs = eval(qs)
#重写的start_requests函数
#初始化请求
def start_requests(self):
for q in self.qs:
self.param = {
"q": q,
"totalPage": 1,
'jumpto': 1,
}
url = self.api + urlencode(self.param)
yield scrapy.Request(url=url,callback=self.gettotalpage,dont_filter=True)
#后续请求
def gettotalpage(self, response):
totalpage = response.css('[name="totalPage"]::attr(value)').extract_first()
self.param['totalPage'] = int(totalpage)
for i in range(1,self.param['totalPage']+1):
# for i in range(1,3):
self.param['jumpto'] = i
url = self.api + urlencode(self.param)
yield scrapy.Request(url=url,callback=self.get_info,dont_filter=True)
自定义解析函数
#即对应请求函数的callback函数
def get_info(self,response):
product_list = response.css('.product')
for product in product_list:
title = product.css('.productTitle a::attr(title)').extract_first()
price = product.css('.productPrice em::attr(title)').extract_first()
status = product.css('.productStatus em::text').extract_first()
# print(title,price,status)
item = items.MyxiaopapaItem()
item['title'] = title
item['price'] = price
item['status'] = status
yield item
item使用
1.items.py里面规定可以接收的参数
import scrapy
class MyxiaopapaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
status = scrapy.Field()
2.生成items对象,并返回
from myxiaopapa import items
#解析函数返回item对象
item = items.MyxiaopapaItem()
item['title'] = title
item['price'] = price
item['status'] = status
yield item
pipelines
存储
#yield item之后就会执行pipelines里面的方法
#前提条件是settings里面有配置
#数字为优先级,越小越优先,可以配置多个,一般用于多个存储
#ITEM_PIPELINES = {
# 'zx.pipelines.ZxPipeline': 300,
#}
配置数据库
import pymongo
import json
class MyxiaopapaPipeline(object):
def __init__(self,host,port,db,table):
self.host = host
self.port = port
self.db = db
self.table = table
#优先于__init__()执行
@classmethod
def from_crawler(cls,crawl):
port = crawl.settings.get('PORT')
host = crawl.settings.get('HOST')
db = crawl.settings.get('DB')
table = crawl.settings.get('TABLE')
return cls(host,port,db,table)
#爬虫启动执行,可以用来开启数据库连接
def open_spider(self,crawl):
self.client = pymongo.MongoClient(port=self.port,host=self.host)
db_obj = self.client[self.db]
self.table_obj = db_obj[self.table]
#爬虫结束执行,可以用来关闭数据库连接
def close_spider(self,crawl):
self.client.close()
def process_item(self, item, spider):
self.table_obj.insert(dict(item))
print(item['title'],'存储成功')
return item
配置请求头
#settings里面默认有
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
#如果想要自定义,优先走自定义
# custom_settings = {
# 'NAME':"MAC",
# 'DEFAULT_REQUEST_HEADERS':{
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# "User-Agent": "XXXX"
# }
#
#
# }
DownloaderMiddleware
request
#None
执行下一个中间件的process_request
#Response
执行最后中间件的process_response在往前执行
#Request
请求放到队列重新开始
#异常
执行最后中间件process_exception,在往前执行
Response
#默认response
正常执行
#Response(url)
执行最后中间件的process_response在往前执行
#Request
请求放到队列重新开始
#异常
执行spider的错误执行
代理
def process_request(self, request, spider):
request.meta['Download_timeout'] = 10
request.meta['proxy'] = "http://" + get_proxy()
return None
参考链接
https://www.cnblogs.com/xiaoyuanqujing/protected/articles/11805810.html
scrapy框架安装配置的更多相关文章
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- python爬虫框架(3)--Scrapy框架安装配置
1.安装python并将scripts配置进环境变量中 2.安装pywin32 在windows下,必须安装pywin32,安装地址:http://sourceforge.net/projects/p ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- Scrapy框架安装配置小结
Windows 平台: 系统是 Win7 Python 2.7.7版本 官网文档:http://doc.scrapy.org/en/latest/intro/install.html 1.安装Pyt ...
- Python3 爬虫之 Scrapy 框架安装配置(一)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的爬虫实现过程请参照本人的另一篇博客:Python3 爬虫之 Scr ...
- scrapy框架中间件配置代理
scrapy框架中间件配置代理import random#代理池PROXY_http = [ '106.240.254.138:80', '211.24.102.168:80',]PROXY_http ...
- drf框架安装配置及其功能概述
0902自我总结 drf框架安装配置及其功能概述 一.安装 pip3 install djangorestframework 二.配置 # 注册drf app NSTALLED_APPS = [ # ...
- Scrapy 框架 安装 五大核心组件 settings 配置 管道存储
scrapy 框架的使用 博客: https://www.cnblogs.com/bobo-zhang/p/10561617.html 安装: pip install wheel 下载 Twisted ...
随机推荐
- Ubuntu 18.04 下安装pip3及pygame模块
1.Ubuntu下pip3的安装.升级.卸载 安装pip3 sudo apt-get install python3-pip 升级pip3 sudo pip3 install --upgrade pi ...
- [考试反思]1017csp-s模拟测试77(lrd day1) :反抗
说在前面:强烈谴责AK神Mr_zkt没有丝毫素质RP-- 然而我也想没素质一次,但是我没机会AK一套除了B组题以外的题... 太菜了,没权力.人家AK了人家就是牛逼你没话说 达哥的题必须好好写反思. ...
- [考试反思]0920csp-s模拟测试48:弱小
注:T1全场46个人里42个AC了. %%%zkt也AK了呢越来越强啊 我是真的越来越弱了吗? 我到底在干什么... 在难度递增的题里分数递增... 考试过程大体还好,但是如此快速地WA掉T1也真是蠢 ...
- CSPS模拟 81
Z哥的题,真是见题如见人啊.. T1 实际状态数没有那么多,不要被数字吓倒就是了. 另外为什么吧轮廓线给忘了啊 T3 觉得自己是正解但是被hack了? 考试的时候想到了复杂度对的的解法,但是 spfa ...
- LeetCode刷题总结-数组篇(下)
本期讲O(n)类型问题,共14题.3道简单题,9道中等题,2道困难题.数组篇共归纳总结了50题,本篇是数组篇的最后一篇.其他三个篇章可参考: LeetCode刷题总结-数组篇(上),子数组问题(共17 ...
- P2893 [USACO08FEB]修路
直入主题. 农夫约翰想改造一条路,原来的路的每一段海拔是Ai,修理后是Bi花费|A_i–B_i|.我们要求修好的路是单调不升或者单调不降的.求最小花费. 数据范围:n<=2000,0≤ Ai ≤ ...
- Python基本数据结构之文件操作
用word操作一个文件的流程如下: 1.找到文件,双击打开 2.读或修改 3.保存&关闭 用python操作文件也差不多: f=open(filename) # 打开文件 f.write(&q ...
- php memcache 缓存与memcached 客户端的详细步骤
缓存服务器有Memcache.Redis,我主要介绍了PHP中的Memcache,从Memcache简介开始,详细讲解了如Memcache和memcached的区别.PHP的 Memcache所有操作 ...
- 从 DevOps 到 Serverless:通过“不用做”的方式解决“如何更高效做”的问题
作者 | 徐进茂(罗离) JAVA 开发工程师 导读:近年来,Serverless 一词越来越热,它已经逐渐成为了一种新型的软件设计架构.和 DevOps 概念提倡的是通过一系列工具和自动化的技术来 ...
- 在VMware环境下安装CentOS7
1. 软件准备: 推荐使用VMware,在这里我使用的是VMware15 映像:可以去官网下载,没有的话也可以在下方链接里下载 链接:https://pan.baidu.com/s/1r_7K-UI0 ...