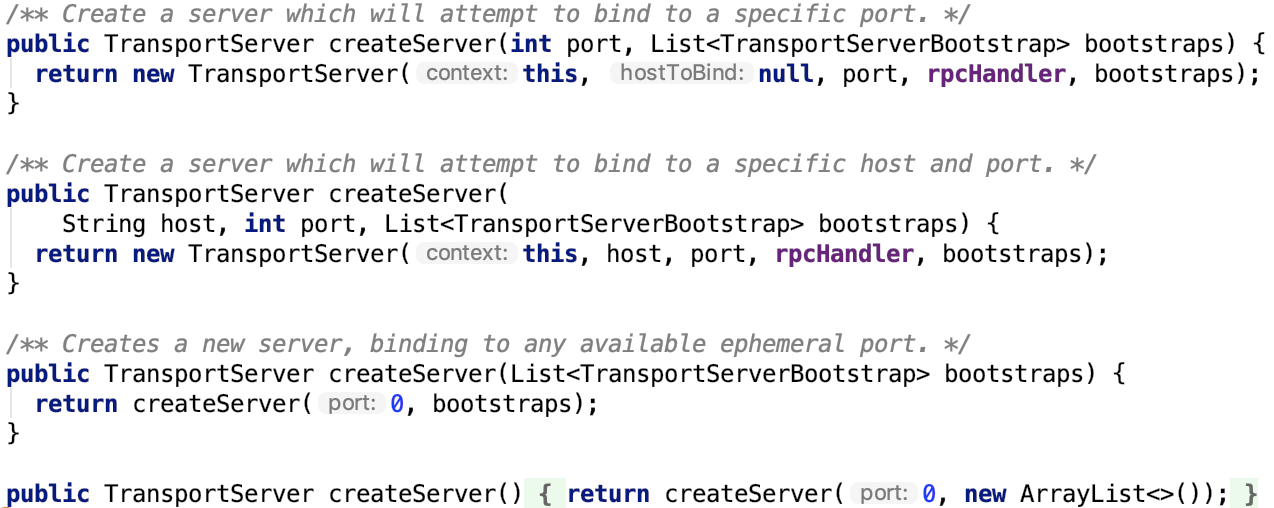
spark 源码分析之八--Spark RPC剖析之TransportContext和TransportClientFactory剖析
spark 源码分析之八--Spark RPC剖析之TransportContext和TransportClientFactory剖析
TransportContext
首先官方文档对TransportContext的说明如下:
Contains the context to create a TransportServer, TransportClientFactory, and to setup Netty Channel pipelines with a TransportChannelHandler. There are two communication protocols that the TransportClient provides, control-plane RPCs and data-plane "chunk fetching". The handling of the RPCs is performed outside of the scope of the TransportContext (i.e., by a user-provided handler), and it is responsible for setting up streams which can be streamed through the data plane in chunks using zero-copy IO. The TransportServer and TransportClientFactory both create a TransportChannelHandler for each channel. As each TransportChannelHandler contains a TransportClient, this enables server processes to send messages back to the client on an existing channel.
首先这个上下文对象是一个创建TransportServer, TransportClientFactory,使用TransportChannelHandler建立netty channel pipeline的上下文,这也是它的三个主要功能。
TransportClient 提供了两种通信协议:控制层面的RPC以及数据层面的 "chunk抓取"。
用户通过构造方法传入的 rpcHandler 负责处理RPC 请求。并且 rpcHandler 负责设置流,这些流可以使用零拷贝IO以数据块的形式流式传输。
TransportServer 和 TransportClientFactory 都为每一个channel创建一个 TransportChannelHandler对象。每一个TransportChannelHandler 包含一个 TransportClient,这使服务器进程能够在现有通道上将消息发送回客户端。
成员变量:
1. logger: 负责打印日志的对象
2. conf:TransportConf对象
3. rpcHandler:RPCHandler的实例
4. closeIdleConnections:空闲时是否关闭连接
5. ENCODER: 网络层数据的加密,MessageEncoder实例
6. DECODER:网络层数据的解密,MessageDecoder实例
三类方法:
1. 创建TransportClientFactory,两个方法如下:

2. 创建TransportServer,四个方法如下:
3. 建立netty channel pipeline,涉及方法以及调用关系如下:

注意:TransportClient就是在 建立netty channel pipeline时候被调用的。整个rpc模块,只有这个方法可以实例化TransportClient对象。
TransportClientFactory
TransportClientFactory
使用 TransportClientFactory 的 createClient 方法创建 TransportClient。这个factory维护到其他主机的连接池,并应为同一远程主机返回相同的TransportClient。所有TransportClients共享一个工作线程池,TransportClients将尽可能重用。
在完成新TransportClient的创建之前,将运行所有给定的TransportClientBootstraps。
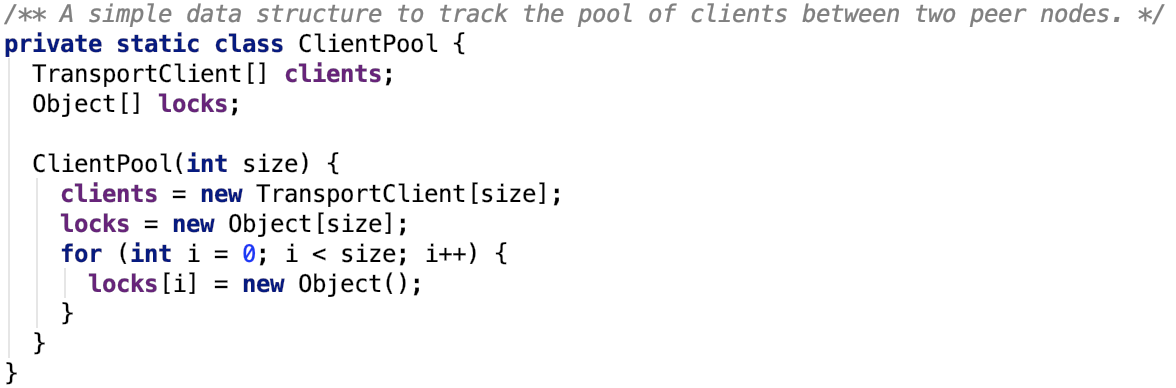
其内部维护了一个连接池,如下:
TransportClientFactory 类图如下:

TransportClientFactory成员变量如下:
1. logger 日志类
2. context 是 TransportContext 实例
3. conf 是 TransportConf 实例
4. clientBootstraps是一个 List<TransportClientBootstrap>实例
5. connectionPool 是一个 ConcurrentHashMap<SocketAddress, ClientPool>实例,维护了 SocketAddress和ClientPool的映射关系,即连接到某台机器某个端口的信息被封装到
6. rand是一个Random 随机器,主要用于在ClientPool中选择TransportClient 实例
7. numConnectionsPerPeer 表示到一个rpcAddress 的连接数
8. socketChannelClass 是一个 Channel 的Class 对象
9. workerGroup 是一个EventLoopGroup 主要是为了注册channel 对象
10. pooledAllocator是一个 PooledByteBufAllocator 对象,负责分配buffer 的11.metrics是一个 NettyMemoryMetrics对象,主要负责从 PooledByteBufAllocator 中收集内存使用metric 信息
其成员方法比较简单,简言之就是几个创建TransportClient的几个方法。
创建受管理的TransportClient,所谓的受管理,其实指的是创建的对象被放入到了connectionPool中:

创建不受管理的TransportClient,新对象创建后不需要放入connectionPool中:

上面的两个方法都调用了核心方法 createClient 方法,其源码如下:

其中Bootstrap类目的是为了让client 更加容易地创建channel。Bootstrap可以认为就是builder模式中的builder。
将复杂的channel初始化过程隐藏在Bootstrap类内部。
至于TransportClient是在初始化channel过程中被初始化的,由于本篇文章长度限制,我们下节剖析。
spark 源码分析之八--Spark RPC剖析之TransportContext和TransportClientFactory剖析的更多相关文章
- spark 源码分析之六--Spark RPC剖析之Dispatcher和Inbox、Outbox剖析
在上篇 spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRPCEnv 中,涉及到了Diapatcher 内容,未做过多的剖析.本篇来剖析一下它的工作原理. Dispatc ...
- Spark源码分析之Spark Shell(下)
继上次的Spark-shell脚本源码分析,还剩下后面半段.由于上次涉及了不少shell的基本内容,因此就把trap和stty放在这篇来讲述. 上篇回顾:Spark源码分析之Spark Shell(上 ...
- spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv
在前面源码剖析介绍中,spark 源码分析之二 -- SparkContext 的初始化过程 中的SparkEnv和 spark 源码分析之四 -- TaskScheduler的创建和启动过程 中的C ...
- Spark源码分析之八:Task运行(二)
在<Spark源码分析之七:Task运行(一)>一文中,我们详细叙述了Task运行的整体流程,最终Task被传输到Executor上,启动一个对应的TaskRunner线程,并且在线程池中 ...
- Spark源码分析之Spark Shell(上)
终于开始看Spark源码了,先从最常用的spark-shell脚本开始吧.不要觉得一个启动脚本有什么东东,其实里面还是有很多知识点的.另外,从启动脚本入手,是寻找代码入口最简单的方法,很多开源框架,其 ...
- spark 源码分析之七--Spark RPC剖析之RpcEndPoint和RpcEndPointRef剖析
RpcEndpoint 文档对RpcEndpoint的解释:An end point for the RPC that defines what functions to trigger given ...
- spark 源码分析之十二 -- Spark内置RPC机制剖析之八Spark RPC总结
在spark 源码分析之五 -- Spark内置RPC机制剖析之一创建NettyRpcEnv中,剖析了NettyRpcEnv的创建过程. Dispatcher.NettyStreamManager.T ...
- Spark 源码分析系列
如下,是 spark 源码分析系列的一些文章汇总,持续更新中...... Spark RPC spark 源码分析之五--Spark RPC剖析之创建NettyRpcEnv spark 源码分析之六- ...
- spark 源码分析之十一--Spark RPC剖析之TransportClient、TransportServer剖析
TransportClient类说明 先来看,官方文档给出的说明: Client for fetching consecutive chunks of a pre-negotiated stream. ...
随机推荐
- Python连载9-setup环境变量&os模块
一.timeit包(上接连载9) 1.我们对于timeit函数,可采取如下例子: h = ''' def doTt(num1): for i in range(num1): print(i) ''' ...
- ireport使用笔记
近来工作中使用到ireport对打印模板改造,记录下所遇见的问题及解决方式.好记性不如烂笔头~ 关于ireport的基本操作就不作记录了,某度一搜一大把 怎样控制组件是否展示?(若组件需要展示的内容为 ...
- 03- 基本的SQL语句介绍
01 库的操作新增库create database db1 charset utf8; # 由于在my.ini中已经配置了字符集,所以,charset utf8可以不写 查库# 查看当前创建的数据库s ...
- Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块. 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网 ...
- 由django请求生命周期延伸出的知识点大总结
django项目搭建见: https://www.cnblogs.com/dongxixi/p/10981577.html django请求生命周期图: 由浏览器发起请求开始 知识点1: 浏览器与服务 ...
- 拉格朗日乘子法 - KKT条件 - 对偶问题
接下来准备写支持向量机,然而支持向量机和其他算法相比牵涉较多的数学知识,其中首当其冲的就是标题中的拉格朗日乘子法.KKT条件和对偶问题,所以本篇先作个铺垫. 大部分机器学习算法最后都可归结为最优化问题 ...
- 编解码器之战:AV1、HEVC、VP9和VVC
视频Codec专家Jan Ozer在Streaming Media West上主持了一场开放论坛,邀请百余名观众参与热门Codec的各项优势与短板.本文整理了讨论的主要成果,基本代表了AV1.HEVC ...
- Junit4使用详解一:测试失败的两种情况
Junit4最佳实践 1.把测试文件夹和代码文件夹分离,这两者的代码互不干扰,代码目录和测试目录是并列的关系 2.Java代码 3.创建单元测试代码文件 4.运行测试代码 5.查看测试结果 现在的情 ...
- vuex分模块3
nuxt 踩坑之 -- Vuex状态树的模块方式使用 原创 2017年12月20日 11:24:14 标签: vue / nuxt / vuex / 模块化 / 状态管理 874 初次看到这个模块方式 ...
- Asp.net HttpClient Proxy(Fiddler)
<system.net> <defaultProxy> <proxy bypassonlocal="False" usesystemdefault=& ...