Hadoop_HDFS_02
1. HDFS入门
1.1 HDFS基本概念
HDFS是Hadoop Distribute File System的简称, 意为: Hadoop分布式文件系统. 是Hadoop三大核心组件之一, 作为最底层的分布式存储服务而存在, 是Hadoop领域最基础的部分.
分布式文件系统解决的问题就是大数据存储. 他们是横跨在多台计算机上的存储系统. 分布式系统在大数据时代有着广泛的应用前景, 他们为存储和处理超大规模数据提供所需的扩展能力.
1.2 HDFS设计目标
1) 硬件故障是常态. 故障的检测和自动快速恢复是HDFS的核心架构目标. 例如集群在启动的时候会进入到安全模式监测block块的情况, 进行自我备份修复
2) HDFS被设计成适合批量处理, 而不是用户交互式的. 注重于数据访问的高吞吐量, 可并行读取一个文件.
3) 支持大文件存储, 块存储 (128M) .
4) 大部分HDFS应用对文件的要求是write-one-read-many访问模型, 一次写入多次读取. 一个文件一旦创建, 写入, 关闭之后就不需要修改了.
5) 移动计算的代价比之移动数据的代价低. 一个应用请求的计算, 离他操作的数据越近越高效, 将计算的任务放在数据存放的位置执行.
6) 在异构的硬件和软件平台上的可移植性. 各种应用都可以通过HDFS获取数据.
2. HDFS重要特性
首先,他是一个文件系统, 用于存储文件, 通过统一的命名空间目录树来定位文件.
其次,他是分布式的, 由很多服务器联合起来实现功能, 集群中的服务器有各自的角色.
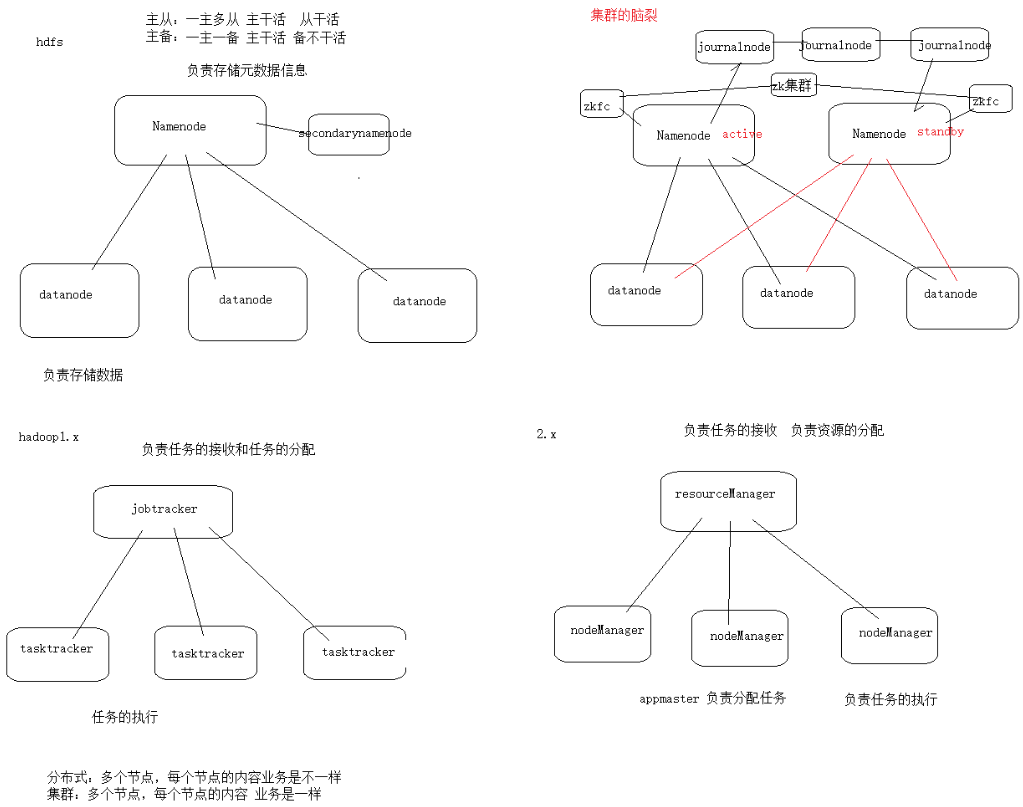
2.1 master / slave架构 (主从架构)
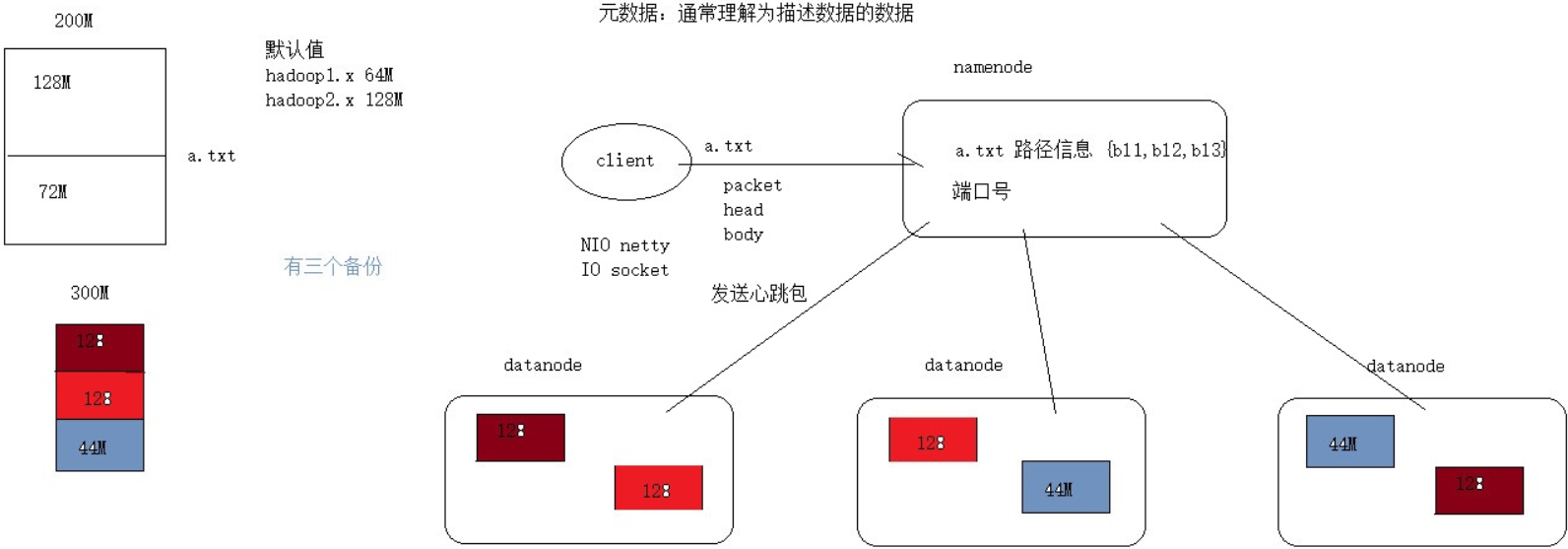
HDFS采用master / slave架构. 一般一个HDFS集群是有一个NameNode和一定数目的DataNode组成. NameNode是集群的主节点. DataNode是集群的从节点. 两种角色各司其职, 共同协调完成分布式的文件存储服务.
2.2 分块存储
HDFS中的文件在物理上是分块存储 (block) 的, 块的大小可以通过配置参数来规定, 默认在Hadoop2.x中是128M.
2.3 名字空间 (NameSpace)
HDFS支持传统的层次型文件组织结构, 对外有统一的文件路径和命名. 用户或者应用程序可以创建目录, 然后将文件保存在这些目录里. 文件系统名字空间的层次结构和大多数现有的文件系统类似: 用户可以创建, 删除, 移动或重命名文件.
NameNode负责维护文件系统的名字空间, 任何对文件系统名字空间或属性的修改都会被NameNode记录下来.
HDFS会给客户端提供一个统一的抽象目录树上, 客户端通过路径来访问文件, 形如hdfs://namenode:port/dir-a/dir-b/file.data. 要上传的文件名和要上传的位置, 要下载的文件名和下载的文件路径, 统一规范(简单理解就是我们通过50070能够看到的文件架构) .
2.4 NameNode元数据管理
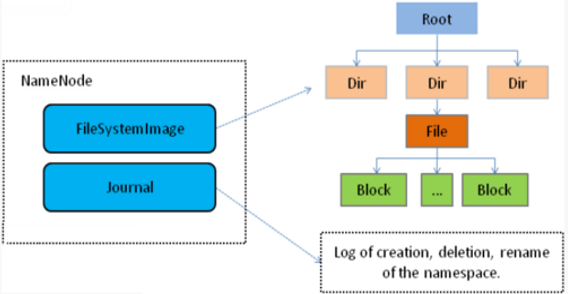
我们把目录结构及文件分块位置信息叫做元数据. 元数据通常可以理解为修饰数据的数据. NameNode负责维护整个HDFS文件系统的目录树结构, 以及每一个文件所对应的block块信息 (block的id, 以及所在的DataNode服务器) .
HDFS存储规则是尽可能不存储小文件, 因为一条元数据理论150B, 例如10W个1KB的小文件存储的硬盘需要100M, 而存储元数据的内存就需要15M.
2.5 DataNode数据存储
文件的各个block的具体存储管理由DataNode节点承担. 每一个block都可以在多个DataNode上. DataNode需要定时向NameNode汇报自己持有的block信息.
存储多个副本 (副本数量可以通过参数设置dfs.replication, 默认是3) .
2.6 副本机制
为了容错, 文件的所有block都会有副本. 每个文件的block大小和副本系数都是可配置的. 应用程序可以指定某个文件的副本数目. 副本系数可以在文件创建的时候指定, 也可以在之后改变.
2.7 一次写入, 多次读出
HDFS是设计成适应一次写入, 多次读出的场景, 且不支持文件的修改.
所以, HDFS适合用来做大数据分析的底层存储服务, 并不适合用来做网盘等应用, 因为修改不方便, 延迟大, 网络开销大, 成本高.
2.8 分块存储和副本备份图
2.9 集群的脑裂
在搭建hadoop的HA集群环境后, 由于两个namenode的状态不一, 当active的namenode由于网络等原因出现假死状态, standby接收不到active的心跳, 因此判断active的namenode宕机, 但实际上active并没有死亡. 此时standby的namenode就会切换成active的状态, 保证服务能够正常使用. 若原来的namenode复活, 此时在整个集群中就出现2个active状态的namenode, 该状态成为脑裂. 脑裂现象可能导致这2个namenode争抢资源. 从节点不知道该连接哪一台namenode, 导致节点的数据不统一, 这在企业生产中是不可以容忍的.
3. HDFS文件限额操作
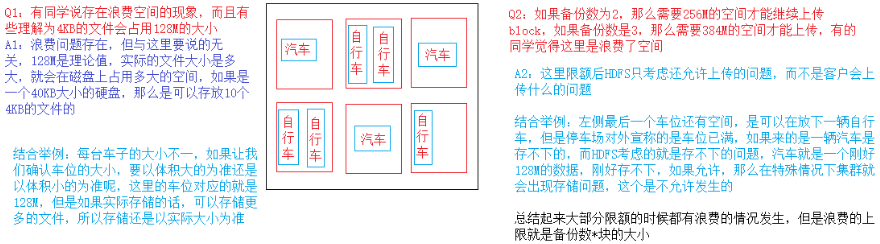
HDFS文件的限额配置允许我们以文件大小或者文件个数来限制在某个目录下上传的文件数量或者文件内容总量, 以便达到类似网盘等限制每个用户允许上传的最大的文件的量
3.1 数量限额
执行以下命令进行文件数量限额
hadoop fs -mkdir -p /user/root/test # 创建hdfs文件夹
hdfs dfsadmin -setOuota 2 test # 给该文件夹下面设置最多上传两个文件, 上传文件, 发现只能上传一个文件
hdfs dfsadmin -clrQuota /user/root/test # 清除文件数量限制
3.2 空间大小限额
执行以下命令进行空间大小限额
hdfs dfsadmin -setSpaceQuota 4k /user/root/test # 限制空间大小4KB, 上传超过4KB的文件提示文件超过限额.
hdfs dfsadmin -clrSpaceQuota /user/root/test # 清楚空间限额
3.3 查看HDFS文件限额数量
执行以下命令进行查看HDFS文件限额数量
hdfs dfs -count -p -h /user/root/test
4. HDFS基本原理
4.1 NameNode概述
1) NameNode是HDFS的核心.
2) NameNode也称为Master.
3) NameNode仅存储HDFS的元数据: 文件系统中所有文件的目录树, 并跟踪整个集群中的文件.
4) NameNode不存储实际数据或数据集. 数据本身实际存储在DataNode中.
5) NameNode知道HDFS中任何给定文件的块列表及其位置. 使用此信息NameNode知道如何从块中构建文件.
6) NameNode并不持久化存储每个文件中各个块所在的DataNode的位置信息, 这些信息会在系统启动时从数据节点重建.
7) NameNode对于HDFS至关重要, 当NameNode关闭时, HDFS / Hadoop集群无法访问.
8) NameNode是Hadoop集群中的单点故障.
9) NameNode所在机器通常会配置有大量内存 (RAM) .
4.2 DataNode概述
1) DataNode负责将实际数据存储在HDFS中.
2) DataNode也称为Slave.
3) DataNode和NameNode会保持不断通信.
4) DataNode启动时, 他将自己发布到NameNode并汇报自己负责持有的块列表.
5) 当某个DataNode关闭时, 他不会影响数据或数据集的可用性. NameNode将安排由其他DataNode管理的块进行副本赋值.
6) DataNode所在机器通常配置有大量的硬盘空间. 因为实际数据存储在DataNode中.
7) DataNode会定期 (dfs.heartbeat.interval配置项配置, 默认是3秒) 向NameNode发送心跳, 如果NameNode长时间没有接受到DataNode发送的心跳, NameNode会认为该DataNode失效.
8) block汇报时间间隔取参数dfs.blockreport.intervalMsec, 参数未配置的话默认6小时.
4.3 HDFS工作机制
NameNode负责管理整个文件系统元数据, DataNode负责管理具体文件数据块存储. SecondaryNameNode协助NameNode进行元数据的备份.
HDFS的内部工作机制对客户端保持透明, 客户端请求访问HDFS都是通过向NameNode申请来进行.
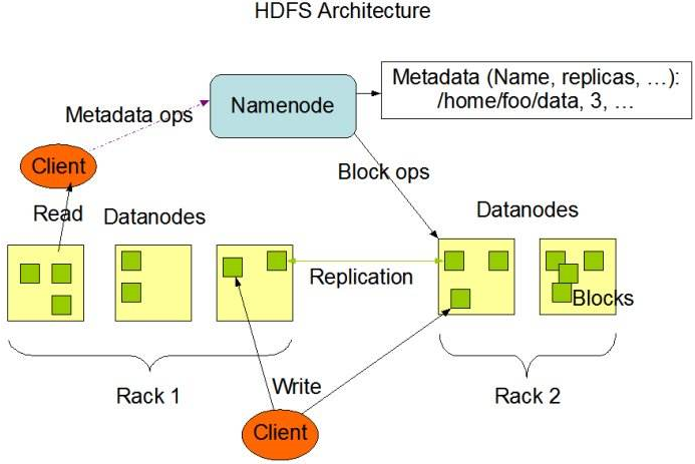
4.4 HDFS写数据流程
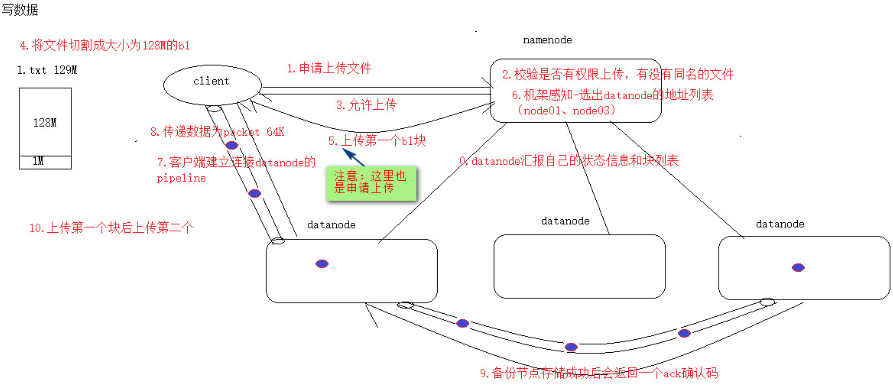
0) DataNode汇报自己的状态信息和块列表
1) 申请上传文件, 通过RPC与NameNode建立通讯
2) NameNode检验是否有权限上传, 父目录是否存在, 有没有同名的文件
3) 返回是否可以上传, 允许上传
4) 将文件切割成大小为128M的block1
5) 开始上传第一个b1
6) NameNode根据配置文件中指定的备份数量及副本放置策略进行文件分配, 返回可用的DataNode的地址, 通过机架感知, 选出DataNode的地址列表, 如node01, node03.
默认存储策略由BlockPlacementPolicyDefault类支持, 也就是日常生活中提到的最经典的3副本策略.
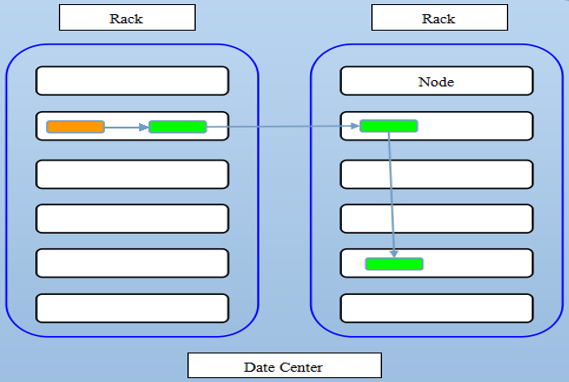
HDFS集群节点非常多. 机架感知 -- 3副本机制
判断客户端所在的位置
1st replica 如果客户端在当前HDFS集群的一台上面, 第一个副本会放在这个客户端所在的机器上.
2nd replica 第二个副本会去找另外一个机架中的一台服务器, 也就是不同于第一个副本的所在的机架.
3rd replica 第三个副本会在第二个副本所在的机架, 第三个副本会再去找一个节点, 属于不同的节点.
7) Client请求2台DataNode中的node01上传数据 (本质上是一个RPC调用, 建立pipeline) , node01收到请求会继续调用node03, 将整个pipeline建立完成, 后逐级返回客户端.
8) Client开始想node01上传第一个block (先从磁盘读取数据放到一个本地内存缓存) , 以packet为单位 (默认64KB) , node01收到一个packet就会传给node03, node01每传一个packet会放入一个应答队列等待应答.
9) 数据被分割成一个个packet数据包在pipeline上一次传输, 在pipeline反方向上, 备份节点存储成功后逐个发送ack正确码, 最终由pipeline中第一个DataNode节点node01将pipeline ack确认码发送给Client.
10) 依次上传b2, b3 ......
4.5 HDFS读数据流程

1) Client向NameNode发起RPC请求, 来确定请求文件block所在的位置
2) NameNode会视情况返回文件的部分或者全部block列表, 对于每个block, NameNode都会返回含有该block副本的DataNode地址.
3) 这些返回的DataNode地址, 会按照集群拓扑结构得出DataNode与客户端的距离, 然后进行排序, 排序两个规则: 网络拓扑结构中距离Client近的排靠前, 心跳机制中超时汇报的DataNode状态为STALE, 这样的排靠后.
4) Client选取排靠前的DataNode来读取block, 如果客户端本身就是DataNode, 那么将从本地直接获取数据.
5) 底层上本质是建立Socket Stream (FSDataInputStream) , 重复的调用父类DataInputStream的read方法, 直到这个块上的数据读取完毕.
6) 当读完列表的block后, 若文件读取还没有结束, 客户端会继续向NameNode获取下一批的block列表.
7) 读取完一个block都会进行checksum验证, 如果读取DataNode时出现错误, Client会通知NameNode, 然后再从下一个拥有该block副本的DataNode继续读取.
8) read方法是并行的读取block信息, 不是一块一块的读取. NameNode只是返回Client请求包含块的DataNode地址, 并不是返回请求块的数据.
9) 最终读取来所有的block会合并成一个完整的最终文件.
Hadoop_HDFS_02的更多相关文章
随机推荐
- Python的import机制
模块与包 在了解 import 之前,有两个概念必须提一下: 模块: 一个 .py 文件就是一个模块(module) 包: __init__.py 文件所在目录就是包(package) 当然,这只是极 ...
- scikit-learn文本特征提取之TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术. TF-IDF是一种统计方法,用以评估一字词对于一个文件集 ...
- sed和awk的简单使用
sed是一个很好的文件处理工具,本身是一个管道命令,主要是以 行 为单位进行处理,可以将数据行进行替换.删除.新增.选取等特定工作,下面先了解一下sed的用法. 语法: sed [-nefri] ‘ ...
- day20191104笔记
MyBatis笔记: 一.MyBatis半自动ORM映射框架, 将数据库中的数据和程序中的数据进行自动映射的前提条件 1. 数据库中的字段必须和程序中的属性保持一致 2. 程序中属性的数据类型必须是基 ...
- 使用python删除指定文件夹及子文件,保留多少
python版本为:2.7 import os,time,shutil,datetime def rmdir(deldir,N): dellist=os.listdir(deldir) deldate ...
- Nginx负载均衡、SSL原理、生成SSL密钥对、Nginx配置SSL
6月12日任务 12.17 Nginx负载均衡12.18 ssl原理12.19 生成ssl密钥对12.20 Nginx配置ssl扩展 针对请求的uri来代理 http://ask.apelearn.c ...
- Kafka topic Schema version mismatch error - org.apache.kafka.common.protocol.types.SchemaException
Problem description: There is error messge when run spark app using spark streaming Kafka version 0. ...
- fsockopen与HTTP 1.1/HTTP 1.0
在前面的例子中,HTTP请求信息头有些指定了 HTTP 1.1,有些指定了 HTTP/1.0,有些又没有指定,那么他们之间有什么区别呢? 关于HTTP 1.1与HTTP 1.0的一些基本情况,可以参考 ...
- luogu P1336 最佳课题选择 |背包dp
题目描述 Matrix67要在下个月交给老师n篇论文,论文的内容可以从m个课题中选择.由于课题数有限,Matrix67不得不重复选择一些课题.完成不同课题的论文所花的时间不同.具体地说,对于某个课题i ...
- luogu P1972 [SDOI2009]HH的项链 |树状数组 或 莫队
题目描述 HH 有一串由各种漂亮的贝壳组成的项链.HH 相信不同的贝壳会带来好运,所以每次散步完后,他都会随意取出一段贝壳,思考它们所表达的含义.HH 不断地收集新的贝壳,因此,他的项链变得越来越长. ...