Python 爬虫(四):Selenium 框架
Selenium 是一个用于测试 Web 应用程序的框架,该框架测试直接在浏览器中运行,就像真实用户操作一样。它支持多种平台:Windows、Linux、Mac,支持多种语言:Python、Perl、PHP、C# 等,支持多种浏览器:Chrome、IE、Firefox、Safari 等。
1 安装
1)安装 Selenium
pip install selenium
2)安装 WebDriver
主要浏览器 WebDriver 地址如下:
Chrome:http://chromedriver.storage.googleapis.com/index.html
Firefox:https://github.com/mozilla/geckodriver/releases/
IE:http://selenium-release.storage.googleapis.com/index.html
本文以 Chrome 为例,本机为 Windows 系统,WebDriver 使用版本 78.0.3904.11,Chrome 浏览器版本为 78.0.3880.4 驱动程序下载好后解压,将 chromedriver.exe 放到 Python 安装目录下即可。
2 操作浏览器
2.1 打开浏览器
1)普通方式
以打开去 163 邮箱为例,使用 Chrome 浏览器
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://mail.163.com/')使用 Firefox 浏览器
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('https://mail.163.com/')使用 IE 浏览器
from selenium import webdriver
browser = webdriver.Ie()
browser.get('https://mail.163.com/')2)加载配置方式
以 Chrome 为例,在 Chrome 浏览器地址栏输入 chrome://version/ 打开,如图所示:
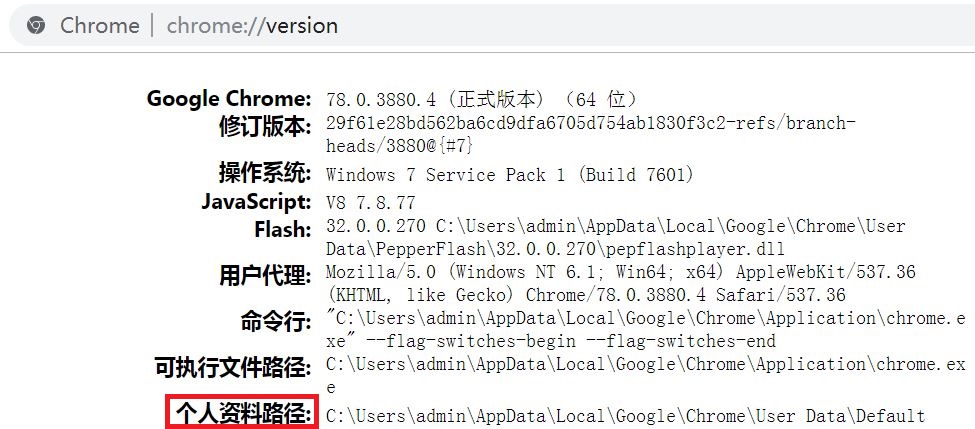
我们可以看到个人资料路径这一项,取到路径:C:\Users\admin\AppData\Local\Google\Chrome\User Data,取到 User Data 使用自己设置的配置,取到 Default 使用默认配置。看下示例:
from selenium import webdriver
option = webdriver.ChromeOptions()
# 自己的数据目录(需要将复制的路径中的 \ 替换成 / 或进行转义 \\)
# option.add_argument('--user-data-dir=C:/Users/admin/AppData/Local/Google/Chrome/User Data')
option.add_argument('--user-data-dir=C:\\Users\\admin\\AppData\\Local\\Google\\Chrome\\User Data')
browser = webdriver.Chrome(chrome_options=option)
browser.get('https://mail.163.com/')
# 关闭
browser.quit()如果执行时报错没有打开指定页面,可先将浏览器关闭再执行。
3)Headless 方式
前两种方式都是有浏览器界面的方式,Headless 模式是 Chrome 浏览器的无界面形态,可以在不打开浏览器的前提下,使用所有 Chrome 支持的特性运行我们的程序。这种方式更加方便测试 Web 应用、获得网站的截图、做爬虫抓取信息等。看下示例:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
# 使用 headless 无界面浏览器模式
chrome_options.add_argument('--headless')
# 禁用 gpu 加速
chrome_options.add_argument('--disable-gpu')
# 启动浏览器,获取网页源代码
browser = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://mail.163.com/'
browser.get(url)
print('browser text = ',browser.page_source)
browser.quit()2.2 设置浏览器窗口
最大化显示
browser.maximize_window()最小化显示
browser.minimize_window()自定义大小
# 宽 500,高 800
browser.set_window_size(500,800)2.3 前进后退
前进
browser.forward()后退
browser.back()3 元素定位
当我们想要操作一个元素时,首先需要找到它,Selenium 提供了多种元素定位方式,我们以 Chrome 浏览器 Headless 方式为例。看下示例:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
url = 'https://xxx.xxx.com/'
browser.get(url)
data = browser.page_source假设访问地址 https://xxx.xxx.com/,返回 data 为如下内容。
<html>
<body>
<form>
<input id="fid" name="fid" type="text" />
<input id="firstName" name="fname" class="fname" type="text" />
<input id="lastName" name="fname" class="fname" type="text" />
<a href="index.html">index</a>
</form>
</body>
<html>1)根据 id 定位
browser.find_element_by_id('fid')2)根据 name 定位
# 返回第一个元素
browser.find_element_by_name('fname')
# 返回所有元素
browser.find_elements_by_name('fname')3)根据 class 定位
# 返回第一个元素
browser.find_element_by_class_name('fname')
# 返回所有元素
browser.find_elements_by_class_name('fname')4)根据标签名定位
# 返回第一个元素
browser.find_element_by_tag_name('input')
# 返回所有元素
browser.find_elements_by_tag_name('input')5)使用 CSS 定位
# 返回第一个元素
browser.find_element_by_css_selector('.fname')
# 返回所有元素
browser.find_elements_by_css_selector('.fname')6)使用链接文本定位超链接
# 返回第一个元素
browser.find_element_by_link_text('index')
# 返回所有元素
browser.find_elements_by_link_text('index')
# 返回第一个元素
browser.find_element_by_partial_link_text('index')
# 返回所有元素
browser.find_elements_by_partial_link_text('index')7)使用 xpath 定位
# 返回第一个元素
browser.find_elements_by_xpath("//input[@id='fid']")
# 返回所有元素
browser.find_elements_by_xpath("//input[@name='fname']")4 等待事件
Web 应用大多都使用 AJAX 技术进行加载,浏览器载入一个页面时,页面内的元素可能会在不同的时间载入,这会加大定位元素的困难程度,因为元素不在 DOM 里,会抛出 ElementNotVisibleException 异常,使用 Waits,我们就可以解决这个问题。
Selenium WebDriver 提供了显式和隐式两种 Waits 方式,显式的 Waits 会让 WebDriver 在更深一步的执行前等待一个确定的条件触发,隐式的 Waits 则会让 WebDriver 试图定位元素的时候对 DOM 进行指定次数的轮询。
4.1 显示等待
WebDriverWait 配合该类的 until() 和 until_not() 方法,就能够根据判断条件而进行灵活地等待了。它主要流程是:程序每隔 x 秒检查一下,如果条件成立了,则执行下一步操作,否则继续等待,直到超过设置的最长时间,然后抛出 TimeoutException 异常。先看一下方法:
__init__(driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None)
- driver: 传入 WebDriver 实例;
- timeout: 超时时间,单位为秒;
- poll_frequency: 调用 until 或 until_not 中方法的间隔时间,默认是 0.5 秒;
- ignored_exceptions: 忽略的异常,如果在调用 until 或 until_not 的过程中抛出这个元组中的异常,则不中断代码,继续等待,如果抛出的是这个元组外的异常,则中断代码,抛出异常。默认只有 NoSuchElementException。
until(method, message='')
- method: 在等待期间,每隔一段时间(init 中的 poll_frequency)调用这个方法,直到返回值不是 False;
- message: 如果超时,抛出 TimeoutException,将 message 传入异常。
until_not(method, message='')
until 方法是当某条件成立则继续执行,until_not 方法与之相反,它是当某条件不成立则继续执行,参数与 until 方法相同。
以去 163 邮箱为例,看一下示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://mail.163.com/')
try:
# 超时时间为 5 秒
data = WebDriverWait(browser,5).until(
EC.presence_of_element_located((By.ID,'lbNormal'))
)
print(data)
finally:
browser.quit()示例中代码会等待 5 秒,如果 5 秒内找到元素则立即返回,否则会抛出 TimeoutException 异常,WebDriverWait 默认每 0.5 秒调用一下 ExpectedCondition 直到它返回成功为止。
4.2 隐式等待
当我们要找一个或者一些不能立即可用的元素的时候,隐式 Waits 会告诉 WebDriver 轮询 DOM 指定的次数,默认设置是 0 次,一旦设定,WebDriver 对象实例的整个生命周期的隐式调用也就设定好了。看一下方法:
implicitly_wait(time_to_wait)
隐式等待是设置了一个最长等待时间 time_to_wait,该时间是针对全局设置的,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步。看到了这里,我们会感觉有点像 time.sleep(),它们的区别是:time.sleep() 必须等待指定时间后才能继续执行, time_to_wait 是在指定的时间范围加载完成即执行,time_to_wait 比 time.sleep() 更灵活一些。
看下示例:
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(5)
browser.get('https://mail.163.com/')
data = browser.find_element_by_id('lbNormal')
print(data)
browser.quit()5 登录 163 邮箱
最后,我们用 Selenium 来做个登录 163 邮箱的实战例子。
5.1 方式一
我们通过地址 https://email2.163.com/ 登录,如图所示:
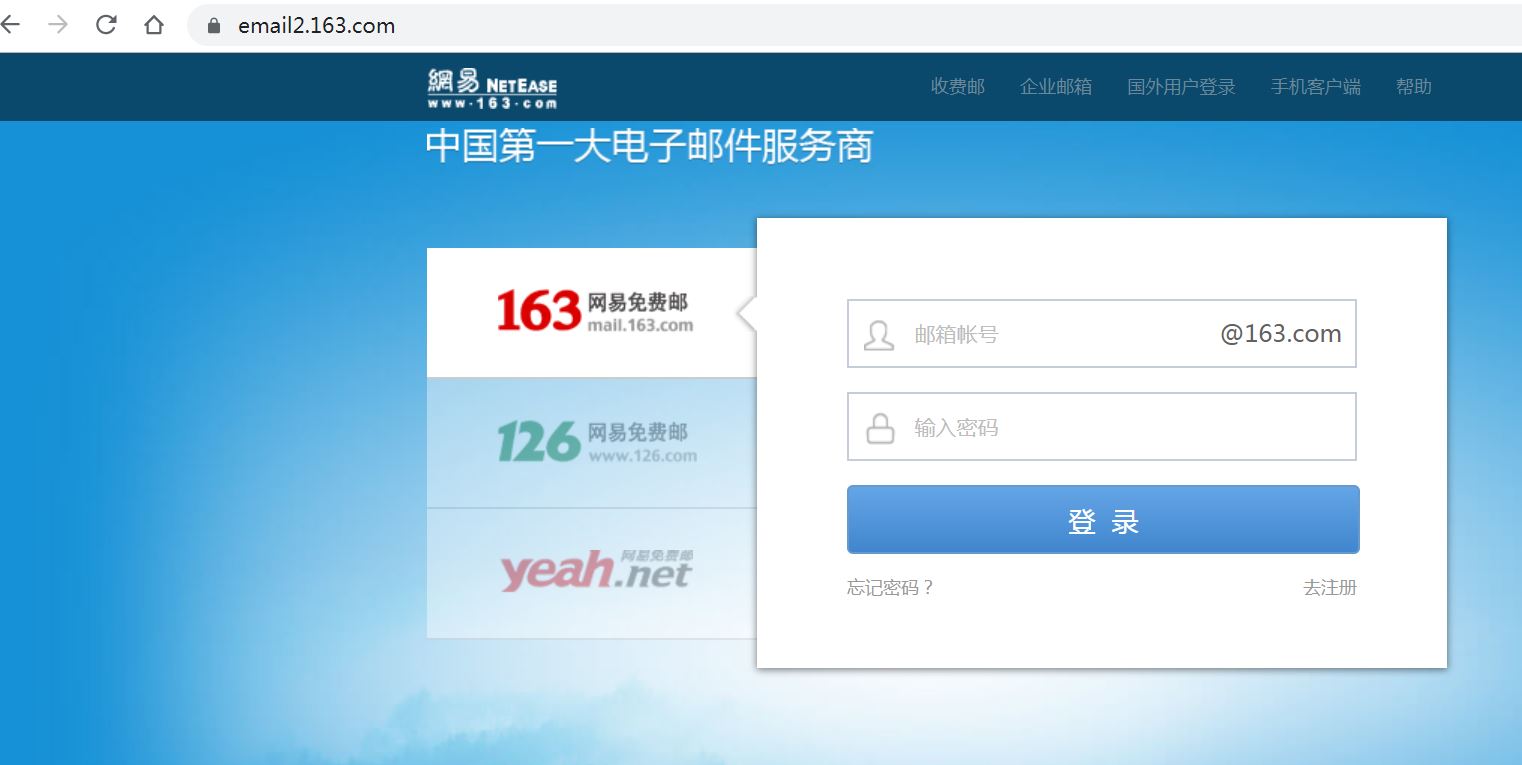
从图中我们发现直接进了 163 邮箱用户名、密码登录页,我们直接输入用户名、密码,点击登录按钮即可。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(2)
browser.get('https://email2.163.com/')
browser.switch_to.frame(browser.find_element_by_xpath('//iframe[starts-with(@id,"x-URS")]'))
# 自己的用户名
browser.find_element_by_xpath('//input[@name="email"]').send_keys('xxx')
# 自己的密码
browser.find_element_by_xpath('//input[@name="password"]').send_keys('xxx')
browser.find_element_by_xpath('//*[@id="dologin"]').click()
print(browser.page_source)
# 关闭
browser.quit()5.2 方式二
第二种方式我们使用地址 https://mail.163.com/,先手动打开看一下:
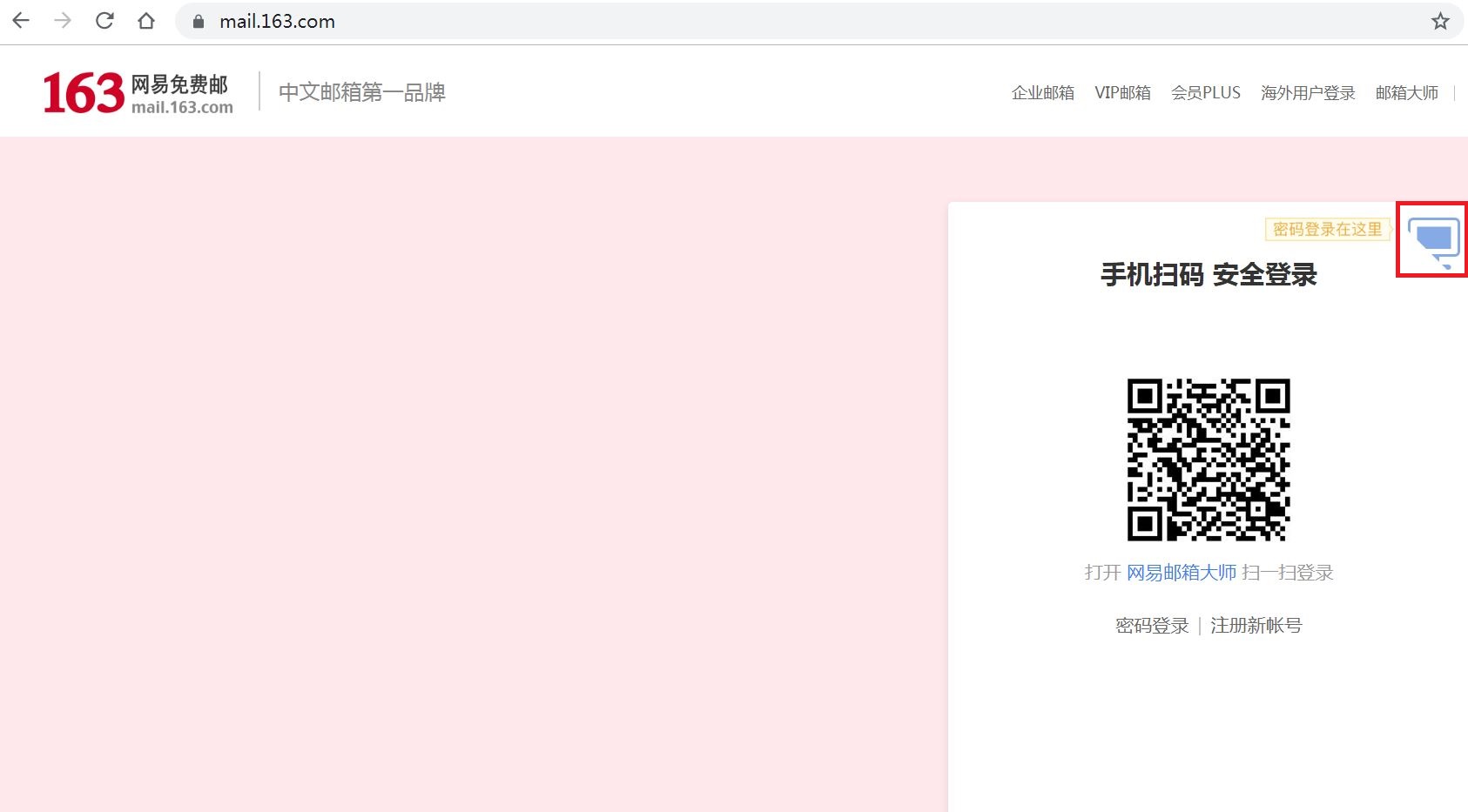
从图中我们会发现,登录页面首先展示的是二维码登录方式,因此我们需要先点击上图红框圈住的位置切换到用户名、密码的登录方式,如图所示:
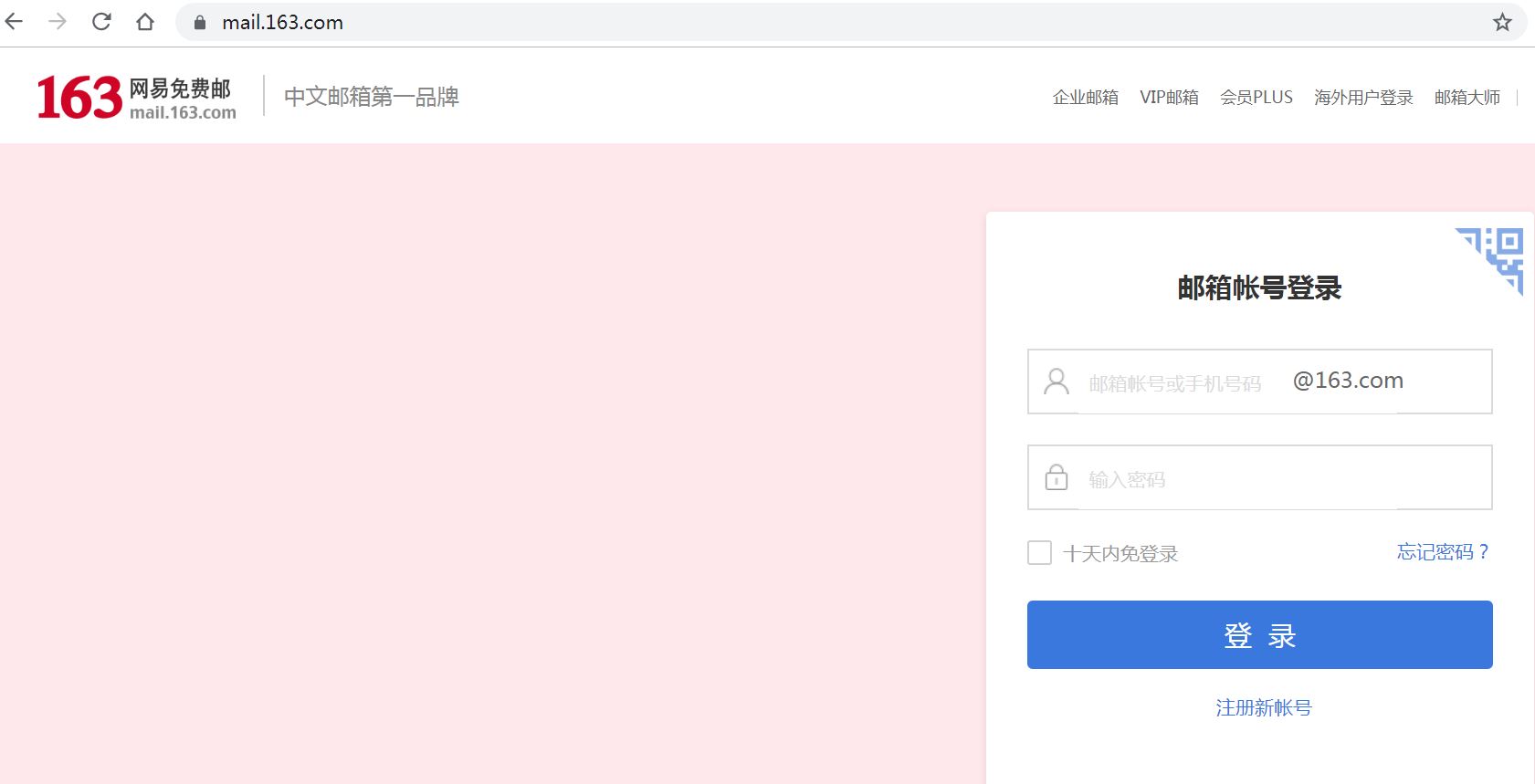
此时,我们先输入用户名、密码,然后点击登录按钮即可。详细代码见如下 GitHub 仓库。
Python 爬虫(四):Selenium 框架的更多相关文章
- Python爬虫之PySpider框架
概述 pyspider 是一个支持任务监控.项目管理.多种数据库,具有 WebUI 的爬虫框架,它采用 Python 语言编写,分布式架构.详细特性如下: 拥有 Web 脚本编辑界面,任务监控器,项目 ...
- [Python爬虫]使用Selenium操作浏览器订购火车票
这个专题主要说的是Python在爬虫方面的应用,包括爬取和处理部分 [Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium) [Python爬虫]使用Python爬取静态网页-斗 ...
- Python 爬虫利器 Selenium 介绍
Python 爬虫利器 Selenium 介绍 转 https://mp.weixin.qq.com/s/YJGjZkUejEos_yJ1ukp5kw 前面几节,我们学习了用 requests 构造页 ...
- Python爬虫之selenium的使用(八)
Python爬虫之selenium的使用 一.简介 二.安装 三.使用 一.简介 Selenium 是自动化测试工具.它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏 ...
- Python爬虫之selenium高级功能
Python爬虫之selenium高级功能 原文地址 表单操作 元素拖拽 页面切换 弹窗处理 表单操作 表单里面会有文本框.密码框.下拉框.登陆框等. 这些涉及与页面的交互,比如输入.删除.点击等. ...
- Python爬虫之selenium库使用详解
Python爬虫之selenium库使用详解 本章内容如下: 什么是Selenium selenium基本使用 声明浏览器对象 访问页面 查找元素 多个元素查找 元素交互操作 交互动作 执行JavaS ...
- 【转】Python爬虫(6)_scrapy框架
官网链接:https://docs.scrapy.org/en/latest/topics/architecture.html 性能相关 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下 ...
- 适合新手练习的Python项目有哪些?Python爬虫用什么框架比较好?
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. Python爬虫一般用什么框架比较好?一般来讲,只有在遇到比较大型的需求时 ...
- python爬虫利器Selenium使用详解
简介: 用pyhon爬取动态页面时普通的urllib2无法实现,例如下面的京东首页,随着滚动条的下拉会加载新的内容,而urllib2就无法抓取这些内容,此时就需要今天的主角selenium. Sele ...
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
随机推荐
- 计蒜客 ACM训练联盟周赛 第一场 Christina式方格取数 思维
助手Christina发明了一种方格取数的新玩法:在n*m的方格棋盘里,每个格子里写一个数.两个人轮流给格子染色,直到所有格子都染了色.在所有格子染色完后,计算双方的分数.对于任意两个相邻(即有公共边 ...
- ☆1003 Dijstra
循环N次 算法分为两部分: 1)找到距离最小的城市,找不到距离更小的城市时退出方法 2)更新距离 实际操作时,先初始化: 更新dis为INF,更新dis[start] = 0: 变种: 找最短路径的条 ...
- C++数据类型(data type)介绍
在编写程序时,数据类型(data type)定义了使用存储空间的(内存)的方式. 程序员通过定义数据类型(data type),告诉特定存储空间这里要存储的数据类型是什么,以及你即将操作他的方式.(注 ...
- react-router url参数更新 但是页面不更新的解决办法
今天发现, 当使用react-router(v4.2.2)时,路由需要传入参数, 但是如果路由跳转时,url仅仅改变的是参数部分,如从hello/1跳转到hello/2,此时虽然参数更新了,但是页面是 ...
- yolo进化史之yolov2
yolov1和当时最好的目标检测系统相比,有很多缺点.比如和Fast R-CNN相比,定位错误更多.和基于区域选择的目标检测方法相比,recall也比较低.yolov2的目标即在保证分类准确度的情况下 ...
- 时间复杂度big-O、Big-Omega和big-Theta
我们有三种曲线: A curve that we know is "above" the running time function when n is large. ( Bi ...
- Could not calculate build plan :lugin org.apache.maven.plugins:maven-resources-plugin:2.6 or one of
eclipse中新建maven项目,出现 Could not calculate build plan :lugin org.apache.maven.plugins:maven-resources- ...
- Unity3D_01_各种寻找GameObject方法
1.GameObject.Find(): 寻找Hierarchy面板中的activie 不为false的游戏对象: 路径如官方事例写法: public class ExampleClass : Mon ...
- NOIP2008复赛 提高组 第一题
描述 笨小猴的词汇量很小,所以每次做英语选择题的时候都很头疼.但是他找到了一种方法,经试验证明,用这种方法去选择选项的时候选对的几率非常大! 这种方法的具体描述如下:假设maxn是单词中出现次数最多的 ...
- Nginx缓存原理及机制
文章原创于公众号:程序猿周先森.本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号. 上篇文章介绍了Nginx一个较为重要的知识点:Nginx实现接口限流.本篇文章将介绍Nginx另一个重要知识点 ...