Hive 系列(七)—— Hive 常用 DML 操作
一、加载文件数据到表
1.1 语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE]
INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]LOCAL关键字代表从本地文件系统加载文件,省略则代表从 HDFS 上加载文件:从本地文件系统加载文件时,
filepath可以是绝对路径也可以是相对路径 (建议使用绝对路径);从 HDFS 加载文件时候,
filepath为文件完整的 URL 地址:如hdfs://namenode:port/user/hive/project/ data1filepath可以是文件路径 (在这种情况下 Hive 会将文件移动到表中),也可以目录路径 (在这种情况下,Hive 会将该目录中的所有文件移动到表中);如果使用 OVERWRITE 关键字,则将删除目标表(或分区)的内容,使用新的数据填充;不使用此关键字,则数据以追加的方式加入;
加载的目标可以是表或分区。如果是分区表,则必须指定加载数据的分区;
加载文件的格式必须与建表时使用
STORED AS指定的存储格式相同。
使用建议:
不论是本地路径还是 URL 都建议使用完整的。虽然可以使用不完整的 URL 地址,此时 Hive 将使用 hadoop 中的 fs.default.name 配置来推断地址,但是为避免不必要的错误,建议使用完整的本地路径或 URL 地址;
加载对象是分区表时建议显示指定分区。在 Hive 3.0 之后,内部将加载 (LOAD) 重写为 INSERT AS SELECT,此时如果不指定分区,INSERT AS SELECT 将假设最后一组列是分区列,如果该列不是表定义的分区,它将抛出错误。为避免错误,还是建议显示指定分区。
1.2 示例
新建分区表:
CREATE TABLE emp_ptn(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
PARTITIONED BY (deptno INT) -- 按照部门编号进行分区
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";从 HDFS 上加载数据到分区表:
LOAD DATA INPATH "hdfs://hadoop001:8020/mydir/emp.txt" OVERWRITE INTO TABLE emp_ptn PARTITION (deptno=20);emp.txt 文件可在本仓库的 resources 目录中下载
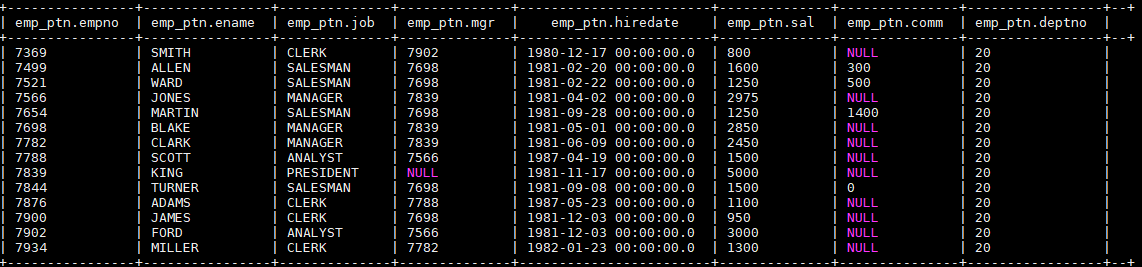
加载后表中数据如下,分区列 deptno 全部赋值成 20:
二、查询结果插入到表
2.1 语法
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]]
select_statement1 FROM from_statement;
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)]
select_statement1 FROM from_statement;Hive 0.13.0 开始,建表时可以通过使用 TBLPROPERTIES(“immutable”=“true”)来创建不可变表 (immutable table) ,如果不可以变表中存在数据,则 INSERT INTO 失败。(注:INSERT OVERWRITE 的语句不受
immutable属性的影响);可以对表或分区执行插入操作。如果表已分区,则必须通过指定所有分区列的值来指定表的特定分区;
从 Hive 1.1.0 开始,TABLE 关键字是可选的;
从 Hive 1.2.0 开始 ,可以采用 INSERT INTO tablename(z,x,c1) 指明插入列;
可以将 SELECT 语句的查询结果插入多个表(或分区),称为多表插入。语法如下:
FROM from_statement INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 [INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2] [INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2] ...;
2.2 动态插入分区
INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...)
select_statement FROM from_statement;
INSERT INTO TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...)
select_statement FROM from_statement;在向分区表插入数据时候,分区列名是必须的,但是列值是可选的。如果给出了分区列值,我们将其称为静态分区,否则它是动态分区。动态分区列必须在 SELECT 语句的列中最后指定,并且与它们在 PARTITION() 子句中出现的顺序相同。
注意:Hive 0.9.0 之前的版本动态分区插入是默认禁用的,而 0.9.0 之后的版本则默认启用。以下是动态分区的相关配置:
| 配置 | 默认值 | 说明 |
|---|---|---|
hive.exec.dynamic.partition |
true |
需要设置为 true 才能启用动态分区插入 |
hive.exec.dynamic.partition.mode |
strict |
在严格模式 (strict) 下,用户必须至少指定一个静态分区,以防用户意外覆盖所有分区,在非严格模式下,允许所有分区都是动态的 |
hive.exec.max.dynamic.partitions.pernode |
100 | 允许在每个 mapper/reducer 节点中创建的最大动态分区数 |
hive.exec.max.dynamic.partitions |
1000 | 允许总共创建的最大动态分区数 |
hive.exec.max.created.files |
100000 | 作业中所有 mapper/reducer 创建的 HDFS 文件的最大数量 |
hive.error.on.empty.partition |
false |
如果动态分区插入生成空结果,是否抛出异常 |
2.3 示例
- 新建 emp 表,作为查询对象表
CREATE TABLE emp(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
-- 加载数据到 emp 表中 这里直接从本地加载
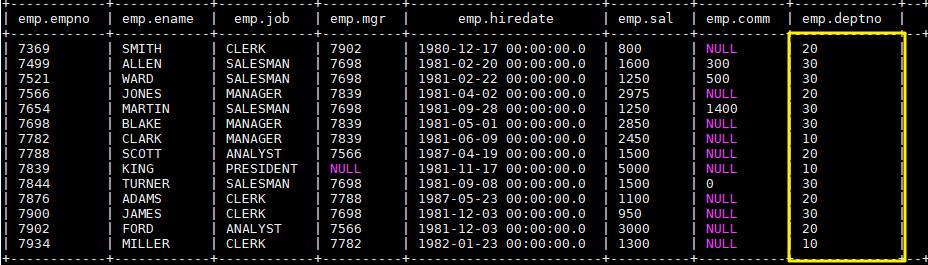
load data local inpath "/usr/file/emp.txt" into table emp; 完成后 emp 表中数据如下:
- 为清晰演示,先清空
emp_ptn表中加载的数据:
TRUNCATE TABLE emp_ptn;- 静态分区演示:从
emp表中查询部门编号为 20 的员工数据,并插入emp_ptn表中,语句如下:
INSERT OVERWRITE TABLE emp_ptn PARTITION (deptno=20)
SELECT empno,ename,job,mgr,hiredate,sal,comm FROM emp WHERE deptno=20; 完成后 emp_ptn 表中数据如下:

- 接着演示动态分区:
-- 由于我们只有一个分区,且还是动态分区,所以需要关闭严格默认。因为在严格模式下,用户必须至少指定一个静态分区
set hive.exec.dynamic.partition.mode=nonstrict;
-- 动态分区 此时查询语句的最后一列为动态分区列,即 deptno
INSERT OVERWRITE TABLE emp_ptn PARTITION (deptno)
SELECT empno,ename,job,mgr,hiredate,sal,comm,deptno FROM emp WHERE deptno=30; 完成后 emp_ptn 表中数据如下:

三、使用SQL语句插入值
INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)]
VALUES ( value [, value ...] )- 使用时必须为表中的每个列都提供值。不支持只向部分列插入值(可以为缺省值的列提供空值来消除这个弊端);
- 如果目标表表支持 ACID 及其事务管理器,则插入后自动提交;
- 不支持支持复杂类型 (array, map, struct, union) 的插入。
四、更新和删除数据
4.1 语法
更新和删除的语法比较简单,和关系型数据库一致。需要注意的是这两个操作都只能在支持 ACID 的表,也就是事务表上才能执行。
-- 更新
UPDATE tablename SET column = value [, column = value ...] [WHERE expression]
--删除
DELETE FROM tablename [WHERE expression]4.2 示例
1. 修改配置
首先需要更改 hive-site.xml,添加如下配置,开启事务支持,配置完成后需要重启 Hive 服务。
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.in.test</name>
<value>true</value>
</property>2. 创建测试表
创建用于测试的事务表,建表时候指定属性 transactional = true 则代表该表是事务表。需要注意的是,按照官方文档 的说明,目前 Hive 中的事务表有以下限制:
- 必须是 buckets Table;
- 仅支持 ORC 文件格式;
- 不支持 LOAD DATA ...语句。
CREATE TABLE emp_ts(
empno int,
ename String
)
CLUSTERED BY (empno) INTO 2 BUCKETS STORED AS ORC
TBLPROPERTIES ("transactional"="true");3. 插入测试数据
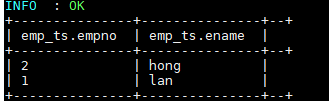
INSERT INTO TABLE emp_ts VALUES (1,"ming"),(2,"hong");插入数据依靠的是 MapReduce 作业,执行成功后数据如下:
4. 测试更新和删除
--更新数据
UPDATE emp_ts SET ename = "lan" WHERE empno=1;
--删除数据
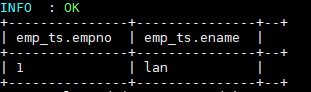
DELETE FROM emp_ts WHERE empno=2;更新和删除数据依靠的也是 MapReduce 作业,执行成功后数据如下:
五、查询结果写出到文件系统
5.1 语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...OVERWRITE 关键字表示输出文件存在时,先删除后再重新写入;
和 Load 语句一样,建议无论是本地路径还是 URL 地址都使用完整的;
写入文件系统的数据被序列化为文本,其中列默认由^A 分隔,行由换行符分隔。如果列不是基本类型,则将其序列化为 JSON 格式。其中行分隔符不允许自定义,但列分隔符可以自定义,如下:
-- 定义列分隔符为'\t' insert overwrite local directory './test-04' row format delimited FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ',' MAP KEYS TERMINATED BY ':' select * from src;
5.2 示例
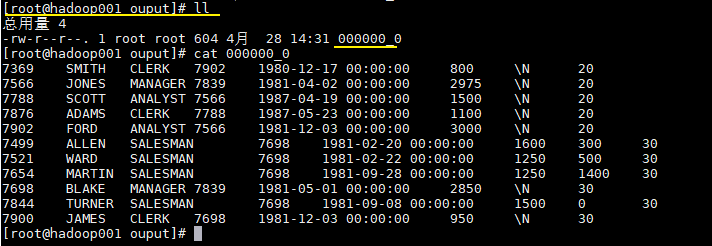
这里我们将上面创建的 emp_ptn 表导出到本地文件系统,语句如下:
INSERT OVERWRITE LOCAL DIRECTORY '/usr/file/ouput'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
SELECT * FROM emp_ptn;导出结果如下:
参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Hive 系列(七)—— Hive 常用 DML 操作的更多相关文章
- 入门大数据---Hive常用DML操作
Hive 常用DML操作 一.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename ...
- Hive 学习之路(七)—— Hive 常用DML操作
一.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (p ...
- Hive扩展功能(七)--Hive On Spark
软件环境: linux系统: CentOS6.7 Hadoop版本: 2.6.5 zookeeper版本: 3.4.8 主机配置: 一共m1, m2, m3这五部机, 每部主机的用户名都为centos ...
- Spring框架系列(七)--Spring常用注解
Spring部分: 1.声明bean的注解: @Component:组件,没有明确的角色 @Service:在业务逻辑层使用(service层) @Repository:在数据访问层使用(dao层) ...
- 23-hadoop-hive的DDL和DML操作
跟mysql类似, hive也有 DDL, 和 DML操作 数据类型: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ ...
- Hive 系列(四)—— Hive 常用 DDL 操作
一.Database 1.1 查看数据列表 show databases; 1.2 使用数据库 USE database_name; 1.3 新建数据库 语法: CREATE (DATABASE|SC ...
- Hive 学习之路(四)—— Hive 常用DDL操作
一.Database 1.1 查看数据列表 show databases; 1.2 使用数据库 USE database_name; 1.3 新建数据库 语法: CREATE (DATABASE|SC ...
- HIVE之 DDL 数据定义 & DML数据操作
DDL数据库定义 创建数据库 1)创建一个数据库,数据库在 HDFS 上的默认存储路径是/user/hive/warehouse/*.db. hive (default)> create dat ...
- Hive 教程(七)-DML基础
DML,Hive Data Manipulation Language,数据操作语言: 通俗理解就是数据库里与数据的操作,如增删改查,统计汇总等: Loading files into tables ...
随机推荐
- 【题解】Unit Fraction Partition-C++
Description给出数字P,Q,A,N,代表将分数P/Q分解成至多N个分数之和,这些分数的分子全为1,且分母的乘积不超过A.例如当输入数据为2 3 120 3时,我们可以得到以下几种分法: In ...
- C语言入门5-键盘的输入和屏幕输出
C程序中的键盘输入和屏幕输出都是通过 调用输入/输出函数 实现的. 一.数据的格式化 屏幕输出 函数printf()的一般格式 (有两种) (1)第一种: printf(格式控制字符串): ...
- C#2.0新增功能05 迭代器
连载目录 [已更新最新开发文章,点击查看详细] 迭代器可用于逐步迭代集合,例如列表和数组. 迭代器方法或 get 访问器可对集合执行自定义迭代. 迭代器方法使用 yield return 语句返 ...
- Linux命令大全(简)
rm--删除文件和目录 -i 删除一个已存在的文件前,提示用户进行确认. -r 递归的删除目录. mkdir--创建目录 cp--复制文件和目录 -i 在覆盖一个已存在的目录前,提示用户进 ...
- kubernetes二进制高可用部署实战
环境: 192.168.30.20 VIP(虚拟) 192.168.30.21 master1 192.168.30.22 master2 192.168.30.23 node1 192.168.30 ...
- Spring 整合 ibatis
是的,真的是那个不好用的ibatis,不是好用的mybatis. 由于工作需要用到ibatis需要自己搭建环境,遇到了不少的坑,做一下记录. 一.环境配置 Maven JDK1.6 (非常重要,使用S ...
- Java编程思想,初学者推荐看看
这是一本介绍Java编程思想,如何从面向过程的编程思想转换为面向对象的编程思想.我个人是比较建议新手看一下的,思想掌握了,学起来自然也就会方便很多的,我还有一些Java基础的数,有需要的可以找我要,都 ...
- springBoot数据校验与统一异常处理
概念 异常,在程序中经常发生,如果发生异常怎样给用户一个良好的反馈体验就是我们需要处理的问题.以前处理异常信息,经常都是给前端一个统一的响应,如数据错误,程序崩溃等等.没办法指出哪里出错了,这是一种对 ...
- 常用服务部署脚本(nodejs,pyenv,go,redis,)
根据工作总结的常用安装脚本,要求linux-64系统 #!/bin/bash path=/usr/local/src node () { cd $path #wget https://nodejs.o ...
- 【python-Django开发】Django 配置MySQL数据库讲解!!!
官方文档请阅读:https://docs.djangoproject.com/en/1.11/ref/databases/#mysql-db-api-drivers 配置MySQL数据库 1. 新建M ...