大数据学习之旅2——从零开始搭hadoop完全分布式集群
前言
本文从零开始搭hadoop完全分布式集群,大概花费了一天的时间边搭边写博客,一步一步完成完成集群配置,所以相信大家按照本文一步一步来完全可以搭建成功。需要注意的是本文限于篇幅和时间的限制,也是为了突出重点,一些很基础的操作就不再详细介绍,如果是完全不懂linux,建议先看一下Linux的基础教程,再来进行hadoop配置。同时建议,hadoop安装版本不宜很高。第一次写这么长的博客,希望对大家有所帮助,如果有帮到你,可以在评论区夸夸我哦。哈哈。(原文是在word里编辑的,虽然排版不好看,但是图片都很清晰,重要代码也有背景标注,但是上传到博客里就只剩文字了,图片我一个个复制上去,图片压缩的有些模糊,大家谅解一下)
1 安装linux
篇幅限制,不再介绍,网上很多教程。
2添加一个用户
useradd hduser
passwd *****
2配置用户具有root权限
(1)查看并修改sudoers的文件权限:
首先在root用户下修改 /etc/sudoers 文件权限,将 只读 改为 可以修改
修改权限命令 chmod 777 /etc/sudoers
修改前:

修改后:

(2)修改sudoers配置文件
命令 vim /etc/sudoers
添加 haduer权限信息

(3)将sudosers访问权限恢复440
命令 chmod 440 /etc/sudoers

3创建文件夹module、software
(1)将账户切换为新建用户hduser ,并在/opt目录下创建文件夹module、software文件夹
module文件夹用于存放解压后的文件,software文件夹用于存放原始的压缩文件
命令 su hduser
sudo mkdir module
sudo mkdir software
(2)创建后修改module、software文件夹的所有者为hduser
修改文件或文件夹所有者命令 sudo chown hduser:hduser module/ software/

原有的rh空文件夹可以删掉(也可以不删)
命令 sudo rm -rf rh

4安装JDK
(1)删除原有openJDK(如果有的话)
查询命令 rpm -qa | grep java
卸载命令 sudo rpm -e 软件名称
(我这个机器没发现openJDK就不展示了,但是大多数的linux默认都存在openJDK,需要卸载后再安装Oracle的JDK)
(2)安装JDK
JDK安装有两种方式,一种直接yum安装,方便快捷,前提是连着网。
首先执行查看可安装jdk版本的命令 yum -y list java*
然后选择自己需要的jdk版本进行安装,比如安装JDK1.8,输入命令
yum install -y java-1.8.0-openjdk-devel.x86_64
然后等待安装完成即可,输入java -version查看安装完成后的jdk版本
这个jdk安装目录可以在 usr/lib/jvm下找到
第二种就是手动安装了,也是本文采用的方法
首先在Oracle官网下载jdk,注意下载linux版本,我使用的是jdk-8u144-linux-x64.tar.gz
将jdk复制到Linux中,并将其移动到/opt/software目录下
移动命令sudo mv “当前jdk压缩包的路径” /opt/software


解压到/opt/module目录下
解压命令tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
解压完成后配置jdk环境变量
命令sudo vim /etc/profile
在文件尾部追加jdk路径,并保存
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin

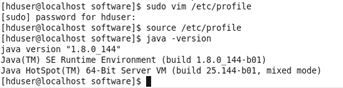
生效配置文件命令 source /etc/profile
输入java -version查看是否成功
5安装hadoop
从官网下载Hadoophttps://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
然后的安装步骤和安装jdk步骤基本一样。
将hadoop-2.7.2.tar.gz复制到Linux中,并移动到/opt/softwate目录下
移动命令sudo mv /hadoop-2.7.2.tar.gz /opt/software/
解压到/opt/module命令 tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
配置hadoop环境变量 sudo vim /etc/profile
在文件末尾添加
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin

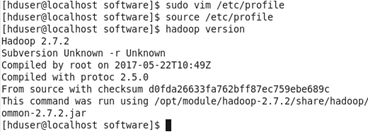
保存退出后,生效配置文件 source /etc/profile
验证是否成功 hadoop version
6修改主机静态IP
(1)命令 vim /etc/udev/rules.d/70-persistent-net.rules

复制本机的物理IP地址00:0c:29:8f:28:40
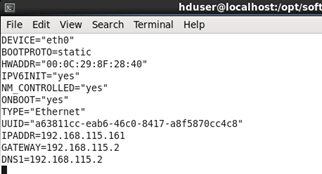
(2)命令sudo vim /etc/sysconfig/network-scripts/ifcfg-eth0 (etho为本机的名字,可以修改,上面的截图最后一个就是这个名字)
将HDADDR的IP改为之前复制的那个IP(如果没这个HDADDR项,那就跳过,不用改了)
将BOOTPROTO项改为static静态获取,将ONBOOT改为yes,那么开机自动生效
添加IPADDR项并设置为192.168.115.161(当然你完全可以设置为其他的静态IP)
添加GATEWAY项并设置为192.168.115.2(这个为网关,根据你的IP设置相应的网关,前三个如:192.168.115和设置的IP前三个要一样,最后一位一般都设为2)
添加DNS1并设置为
7修改主机名称
命令 sudo vim /etc/sysconfig/network
为hadoop201 (你也可以设为其他名字)

保存后,可以输入hostname查看本机的主机名(hostname在重启后生效,当然也有其他生效方式,reboot重启最简单)
8配置hosts文件
配置hosts文件,方便以后的集群操作
输入命令 sudo vim /etc/hosts
在文件末尾追加
192.168.115.161 hadoop201
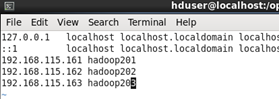
(集群最少要有三个节点,我就顺便把要装的其他的节点也加上了)
9关闭防火墙
关闭防火墙,方便远程操控(不同版本命令有所不同,可以上网百度一下, centos6和centos7命令有些区别)
关闭防火墙命令:systemctl stop firewalld.service
关闭开机启动:systemctl disable firewalld
执行完以上8步骤后可以reboot重启一下,这样基础的准备工作就完成了。
如果使用的是虚拟机的话,就将配置好的一个虚拟机完全克隆一下,克隆2个新节点,克隆完成后只需要修改新节点的静态IP和修改hostname名就行了(使用克隆节点修改静态IP时,注意vim /etc/udev/rules.d/70-persistent-net.rules编辑时要删掉多余的之前的IP设置,并将文件末尾NAME=”eth1”这样的名字改为NAME=”eth0”)
如果是真实主机的话,就重复上述8个步骤,再新建两个节点
有三个节点后,下面开始进行集群配置
10配置集群
建议使用root账号登录
首先在第一台机器上配置
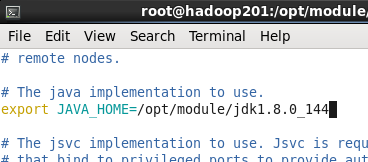
(1)配置hadoop-env.sh
首先进入/opt/module/hadoop-2.7.2目录下 cd /opt/module/hadoop-2.7.2
修改JAVA_HOME路径
命令 vim etc/hadoop/hadoop-env.sh
(2)配置core-site.xml
命令与上面相似vim etc/hadoop/core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
(3)配置hdfs.site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
上述配置在第一台机器上完成后,其他机器暂时不用管
11 SSH无密登录配置
(1)生成公钥私钥
在第一台机器上使用 hduser账号登录
修改配置vim /etc/ssh/sshd_config
找到以下三行,去除注释保存
#RSAAuthentication yes
#PubkeyAuthentication yes
#PermitRootLogin yes
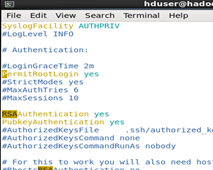
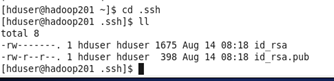
然后在任意目录下输入命令 ssh-keygen -t rsa
回车3次,生成公钥和私钥
(2)将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop201
ssh-copy-id hadoop202
ssh-copy-id hadoop203
(分发密钥过程中需要输入yes和对应目标机器的密码)
hadoop201刚刚使用的是hduser账号生成和分发的密钥,切换账号为root再进行一次生成密钥和分发密钥
同样在即将配置为yarn节点的hadoop202主机采用hduser账号配置无密登录到hadoop201、hadoop202、hadoop203节点
以上操作是为了后续集群群起做铺垫
(3)编写xsync脚本(用于文件同步)
hadoop201上,在在/home/atguigu目录下创建bin目录,并在bin目录下xsync创建文件,
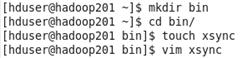
文件内容如下:
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=201; host<204; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
然后修改脚本 xsync 具有执行权限 命令 chmod 777 xsync
12同步文件
首先将xsync脚本文件分发到其他节点
命令 xsync /home/hduser/bin
注意:如果将xsync放到/home/atguigu/bin目录下仍然不能实现全局使用,可以将xsync移动到/usr/local/bin目录下。
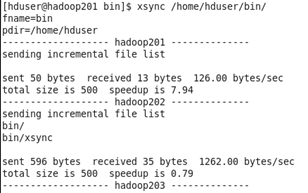
(1)在hadoop201上操作,将hosts文件分发给其他节点(如果是虚拟机克隆的话,hosts里面有节点信息就不用分发了)
xsync /etc/hosts
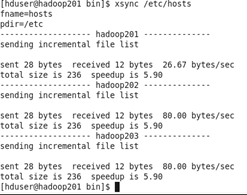
(2)配置slaves
首先进入目录 cd /opt/module/hadoop-2.7.2/ 下
命令 vim etc/hadoop/slaves
在文件中增加下列内容
hadoop102
hadoop103
hadoop104
(注意:slaves文件内不允许有空格,如果有的话会导致一些节点群起失败)
(注意2:配置slaves文件的前提是hosts文件已经有了这些节点的信息)
分发slaves配置文件 xsync etc/hadoop/slaves

13集群配置
还是在hadoop201上操作,然后把文件分发给其他节点,以减少工作量
(1)集群部署规划
|
Hadoop201 |
Hadoop202 |
Hadoop203 |
|
|
HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
(2)配置集群
首先 cd /opt/module/hadoop-2.7.2/ 进入hadoop安装目录下
配置core-site.xml
命令 vim etc/hadoop/core-site.xml
在文件中编写如下配置
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop201:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
配置hadoop-env.sh
命令 vim etc/hadoop/hadoop-env.sh
修改JAVA_HONE路径 export JAVA_HOME=/opt/module/jdk1.8.0_144 (较详细操作看第10小节)
配置hdfs-site.xml
命令 vim etc/hadoop/hdfs-site.xml
在文件中编写如下配置
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop203:50070</value>
</property>
配置yarn-env.sh
命令vim etc/hadoop/yarn-env.sh
修改JAVA_HOME目录(去掉注释修改目录)
export JAVA_HOME=/opt/module/jdk1.8.0_144 (详情参考第10小节)
配置yarn-site.xml
命令vim etc/hadoop/yarn-site.xml
在文件中增加下列配置
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop202</value>
</property>
配置mapred-env.sh
(参考第10小节)
配置mapred-site.xml
首先修改文件名称 cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
再进行配置命令vim etc/hadoop/mapred-site.xml
在文件中加入下列配置
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(3)集群文件配置好后分发配置文件
命令xsync /opt/module/hadoop-2.7.2/
14集群群起
终于来到了激动人心的环节,集群群起(也就是一下启动整个集群)
(1)如果集群是第一次启动,需要格式化namenode (在格式化前,一定要停止上次启动的所有namenode和datanode进程,然后再删除hadoop安装目录下的data和log数据)
格式化命令 bin/hdfs namenode -format
每个节点都格式化一遍
(注意不要随便格式化集群哦)
(2)启动HDFS
在hadoop201上群起HDFS
群起命令 sbin/start-dfs.sh
查看当前节点启动的项目
命令 jps
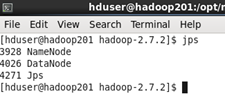
然后在hadoop202上启动yarn
群起命令 sbin/start-yarn.sh
集群完全启动后各节点的状态如下
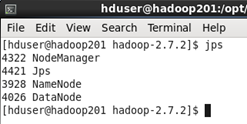

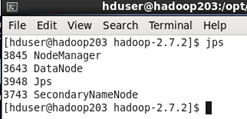
这样整个集群就成功启动了
如果要停止集群
在hadoop201上停止集群的hdfs命令 sbin/stop-dfs.sh
在hadoop202上停止集群yarn命令 sbin/stop-yarn.sh
15浏览器查看集群状态
(前提浏览器那个主机的hosts有这些节点的信息,不然就老老实实输入ip地址,如:把hadoop201替换为192.168.115.161)
在浏览器中输入http://hadoop201:50070查看namenode状态
输入http://hadoop201:50075查看namenode状态
输入http://hadoop203:50075查看secondarynamenode状态
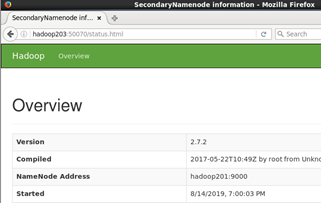
后续:
hadoop集群搭建完后,真正生产环境中还需要同步集群时间,操作集群时一般都是通过远程终端(如xshell、SecureCRT等终端软件ssh登录)操控,这些大家可以查看一下相关博客,还是比较简单的。
如果要转载的话,大家注明一下转载链接即可。
大数据学习之旅2——从零开始搭hadoop完全分布式集群的更多相关文章
- hadoop学习笔记(六):hadoop全分布式集群的环境搭建
本文原创,如需转载,请注明作者以及原文链接! 一.前期准备: 1.jdk安装 不要用centos7自带的openJDK2.hostname 配置 配置位置:/etc/s ...
- 大数据学习笔记03-HDFS-HDFS组件介绍及Java访问HDFS集群
HDFS组件概述 NameNode 存储数据节点信息及元文件,即:分成了多少数据块,每一个数据块存储在哪一个DataNode中,每一个数据块备份到哪些DataNode中 这个集群有哪些DataNode ...
- 新闻网大数据实时分析可视化系统项目——3、Hadoop2.X分布式集群部署
(一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 1.基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进. 2.基于 ...
- hadoop学习第二天-了解HDFS的基本概念&&分布式集群的搭建&&HDFS基本命令的使用
一.HDFS的相关基本概念 1.数据块 1.在HDFS中,文件诶切分成固定大小的数据块,默认大小为64MB(hadoop2.x以后是128M),也可以自己配置. 2.为何数据块如此大,因为数据传输时间 ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- 大数据之Hadoop完全分布式集群搭建
1.准备阶段 1.1.新建三台虚拟机 Hadoop完全分市式集群是典型的主从架构(master-slave),一般需要使用多台服务器来组建.我们准备3台服务器(关闭防火墙.静态IP.主机名称).如果没 ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- hadoop学习通过虚拟机安装hadoop完全分布式集群
要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个had ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
随机推荐
- springboot+redis实现session共享
1.场景描述 因项目访问压力有点大,需要做负载均衡,但是登录使用的是公司统一提供的单点登录系统,需要做session共享,否则假如在A机器登录成功,在B机器上操作就会存在用户未登录情况. 2. 解决方 ...
- Greenplum+mybatis问题解析
1. 问题描述 同事团队在使用springboot+mybatis+Greenplum时,发现通过mybatis数据查询正常,但是执行insert和update执行会报"Cause: org ...
- 每日一问:Android 滑动冲突,你们都是怎样处理的
坚持原创日更,短平快的 Android 进阶系列,敬请直接在微信公众号搜索:nanchen,直接关注并设为星标,精彩不容错过. 在 Android 开发中,滑动冲突总是我们一个无法避免的话题.而对于解 ...
- android_sdcard读写(一)
现在的android手机其实就是一个小小的掌上电脑,平时电脑有的硬件它估计也有了.这次本人研究下了其中充当手机硬盘的角色,就是sdcard.这是一个保存应用程序的好地方. 老规矩,上代码,学习代码才是 ...
- 7月18日刷题记录 二分答案跳石头游戏Getting
通过数:1 明天就要暑假编程集训啦~莫名开心 今天做出了一道 二分答案题(好艰辛鸭) 1049: B13-二分-跳石头游戏(二分答案) 时间限制: 5 Sec 内存限制: 256 MB提交: 30 ...
- vector是序列式容器而set是关联式容器。set包含0个或多个不重复不排序的元素。
1.vector是序列式容器而set是关联式容器.set包含0个或多个不重复不排序的元素.也就是说set能够保证它里面所有的元素都是不重复的.另外对set容器进行插入时可以指定插入位置或者不指定插入位 ...
- GeoPackage - 一个简便轻量的本地地理数据库
GeoPackage(以下简称gpkg),内部使用SQLite实现的一种单文件.与操作系统无关的地理数据库. 当前标准是1.2.1,该版本的html版说明书:https://www.geopackag ...
- Atlassian In Action-Jira之核心插件(三)
目录 BigPicture BigPicture特点介绍 管理员管理菜单 任务列表 任务管理 设置 最佳实践 Jira Misc Workflow Extensions 最佳实践 自动分配 自动化流程 ...
- micropython TPYBoard v201 简易的web服务器的实现过程
转载请注明文章来源,更多教程可自助参考docs.tpyboard.com,QQ技术交流群:157816561,公众号:MicroPython玩家汇 前言 TPYBoard v201开发板上搭载了以太网 ...
- [小米OJ] 7. 第一个缺失正数
思路: 参考这个思路 即:将每个数字放在对应的第几个位置上,比如1放在第1个位置上,2放在第2个位置上. 注意几个点:将每个数放在它正确的位置,前提是该数是正数,并且该数小于序列长度,并且交换的两个数 ...