MySQL如何进行索引重建操作?
在MySQL数据库中,没有类似于SQL Server数据库或Oracle数据库中索引重建的语法(ALTER INDEX ... REBUILD),那么在MySQL数据库中,是否有什么方式重建索引呢? 在官方文档中"2.11.10 Rebuilding or Repairing Tables or Indexes"中,提到下面三种方式可以Rebuild Index
· Dump and Reload Method
· ALTER TABLE Method
· REPAIR TABLE Method
另外, OPTIMIZE TABLE也会对索引进行重建,下面我们来简单验证、测试一下,如有不对或不足的地方,敬请指正。
第一种方法(mysqldump导出然后重新导入),相当于重新CREATE INDEXES , 这里就不讨论了。下面我们来看看其它几种方法,那么要判断索引是否REBUILD了呢?我们来测试验证一下吧,新建测试表如下:
CREATE TABLE t1 (
c1 INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
c2 VARCHAR(100),
c3 VARCHAR(100) )
ENGINE=InnoDB;
create index ix_t1_c2 on t1(c2);
DROP INDEX + CREATE INDEX方法
这种方法过于简单,这里不叙说了。其实也没有啥好说的。
ALTER TABLE方法
那么我们能否在MySQL中找到索引的创建或修改时间呢?经过查证,目前而言,MySQL中是没有相关系统表或视图会记录索引的创建时间的,我们可以用间接的方法来间接验证,有些方法不是特别可靠和准确,最准确的方法应该是阅读源码:
1:表的创建时间,可以间接推断索引的创建时间。因为索引的创建时间肯定在表的创建时间之后。
2:对应表的idb文件的修改或创建时间(若文件从创建后不曾修改过则可认为创建时间=修改时间,关于更多详细内容,参考“Linux如何查找文件的创建时间”),当然这种方法不是非常准确。我们知道,对于InnoDB存储引擎的表而言,对应的索引数据存储在ibd文件中,所以文件的创建时间或修改时间是间接判断索引创建时间。如果存储引擎为MyISAM的话,还有专门的索引文件MYI。
注意:show indexes from tablename不会显示索引创建时间
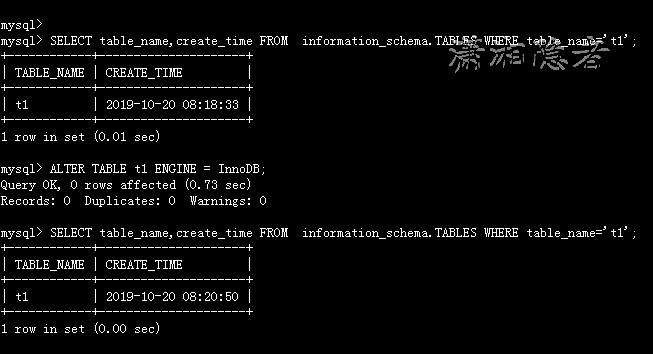
mysql> SELECT table_name,create_time FROM information_schema.TABLES WHERE table_name='t1';
+------------+---------------------+
| TABLE_NAME | CREATE_TIME |
+------------+---------------------+
| t1 | 2019-10-20 08:18:33 |
+------------+---------------------+
1 row in set (0.01 sec)
然后我们对表进行ALTER TABLE t1 ENGINE = InnoDB;进行操作后,然后去验证表的创建时间,如下所示,其实ALTER TABLE xxx ENGINE=InnoDB 其实等价于REBUILD表(REBUILD表就是重建表的意思),所以索引也等价于重新创建了。
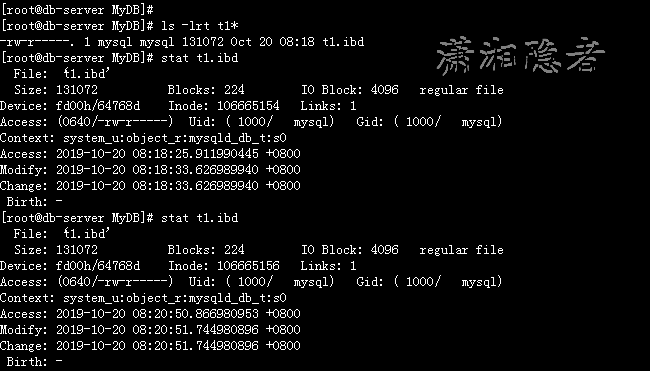
在另外一个窗口,我们对比t1.ibd的创建时间,如下所示,也间接验证了表和索引都REBUILD了。(这里是MySQL 8.0.18 ,如果是之前的版本,还有frm之类的文件。)
[root@db-server MyDB]# ls -lrt t1*
-rw-r-----. 1 mysql mysql 131072 Oct 20 08:18 t1.ibd
[root@db-server MyDB]# stat t1.ibd
File: ‘t1.ibd’
Size: 131072 Blocks: 224 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 106665154 Links: 1
Access: (0640/-rw-r-----) Uid: ( 1000/ mysql) Gid: ( 1000/ mysql)
Context: system_u:object_r:mysqld_db_t:s0
Access: 2019-10-20 08:18:25.911990445 +0800
Modify: 2019-10-20 08:18:33.626989940 +0800
Change: 2019-10-20 08:18:33.626989940 +0800
Birth: -
[root@db-server MyDB]# stat t1.ibd
File: ‘t1.ibd’
Size: 131072 Blocks: 224 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 106665156 Links: 1
Access: (0640/-rw-r-----) Uid: ( 1000/ mysql) Gid: ( 1000/ mysql)
Context: system_u:object_r:mysqld_db_t:s0
Access: 2019-10-20 08:20:50.866980953 +0800
Modify: 2019-10-20 08:20:51.744980896 +0800
Change: 2019-10-20 08:20:51.744980896 +0800
Birth: -
REPAIR TABLE方法
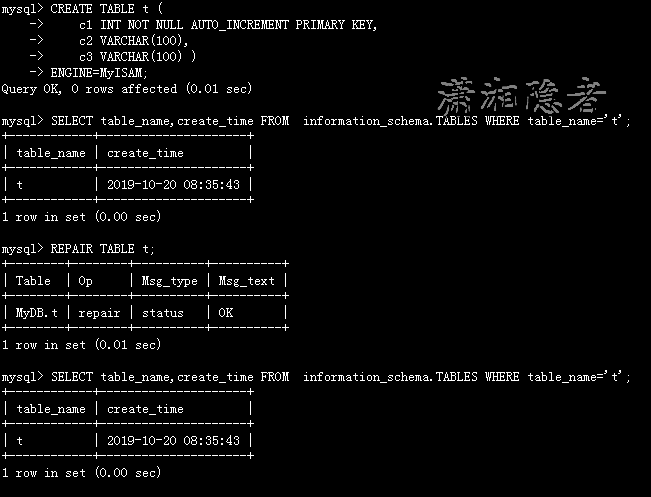
REPAIR TABLE方法用于修复被破坏的表,而且它仅仅能用于MyISAM, ARCHIVE,CSV类型的表。下面的测试环境为MySQL 5.6.41,创建测试表,然后对表进行REPAIR TABLE操作
mysql> CREATE TABLE t (
-> c1 INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> c2 VARCHAR(100),
-> c3 VARCHAR(100) )
-> ENGINE=MyISAM;
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT table_name,create_time FROM information_schema.TABLES WHERE table_name='t';
+------------+---------------------+
| table_name | create_time |
+------------+---------------------+
| t | 2019-10-20 08:35:43 |
+------------+---------------------+
1 row in set (0.00 sec)
然后对表t进行修复操作,发现表的create_time没有变化,如下所示:
mysql> REPAIR TABLE t;
+--------+--------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+--------+--------+----------+----------+
| MyDB.t | repair | status | OK |
+--------+--------+----------+----------+
1 row in set (0.01 sec)
mysql> SELECT table_name,create_time FROM information_schema.TABLES WHERE table_name='t';
+------------+---------------------+
| table_name | create_time |
+------------+---------------------+
| t | 2019-10-20 08:35:43 |
+------------+---------------------+
1 row in set (0.00 sec)
在另外一个窗口,我们发现索引文件t.MYI的修改时间和状态更改时间都变化了,所以判断索引重建(Index Rebuild)了。
[root@testlnx02 MyDB]# ls -lrt t.*
-rw-rw----. 1 mysql mysql 8608 Oct 20 08:35 t.frm
-rw-rw----. 1 mysql mysql 1024 Oct 20 08:35 t.MYI
-rw-rw----. 1 mysql mysql 0 Oct 20 08:35 t.MYD
[root@testlnx02 MyDB]# stat t.MYI
File: `t.MYI'
Size: 1024 Blocks: 8 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 1836747 Links: 1
Access: (0660/-rw-rw----) Uid: ( 27/ mysql) Gid: ( 27/ mysql)
Access: 2019-10-20 08:36:02.395428301 +0800
Modify: 2019-10-20 08:35:43.112562600 +0800
Change: 2019-10-20 08:35:43.112562600 +0800
[root@testlnx02 MyDB]# stat t.MYI
File: `t.MYI'
Size: 1024 Blocks: 8 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 1836747 Links: 1
Access: (0660/-rw-rw----) Uid: ( 27/ mysql) Gid: ( 27/ mysql)
Access: 2019-10-20 08:37:19.686899429 +0800
Modify: 2019-10-20 08:37:10.271475420 +0800
Change: 2019-10-20 08:37:10.271475420 +0800
OPTIMIZE TABLE方法
OPTIMIZE TABLE也可以对索引进行重建,官方文档的介绍如下:
OPTIMIZE TABLE reorganizes the physical storage of table data and associated index data, to reduce storage space and improve I/O efficiency when accessing the table. The exact changes made to each table depend on the storage engine used by that table.
OPTIMIZE TABLE uses online DDL for regular and partitioned InnoDB tables, which reduces downtime for concurrent DML operations. The table rebuild triggered by OPTIMIZE TABLE and performed under the cover by ALTER TABLE ... FORCE is completed in place. An exclusive table lock is only taken briefly during the prepare phase and the commit phase of the operation. During the prepare phase, metadata is updated and an intermediate table is created. During the commit phase, table metadata changes are committed.
OPTIMIZE TABLE rebuilds the table using the table copy method under the following conditions:
·
· When the old_alter_table system variable is enabled.
·
· When the server is started with the --skip-new option.
OPTIMIZE TABLE using online DDL is not supported for InnoDB tables that contain FULLTEXT indexes. The table copy method is used instead.
简单来说,OPTIMIZE TABLE操作使用Online DDL模式修改Innodb普通表和分区表,
该方式会在prepare阶段和commit阶段持有表级锁:在prepare阶段修改表的元数据并且创建一个中间表,在commit阶段提交元数据的修改。
由于prepare阶段和commit阶段在整个事务中的时间比例非常小,可以认为该OPTIMIZE TABLE的过程中不影响表的其他并发操作。
测试验证如下,对表t1做了OPTIMIZE TABLE后, 表的创建时间变成了2019-10-20 08:41:57
mysql> OPTIMIZE TABLE t1;
+---------+----------+----------+-------------------------------------------------------------------+
| Table | Op | Msg_type | Msg_text |
+---------+----------+----------+-------------------------------------------------------------------+
| MyDB.t1 | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| MyDB.t1 | optimize | status | OK |
+---------+----------+----------+-------------------------------------------------------------------+
2 rows in set (0.67 sec)
mysql> SELECT table_name,create_time FROM information_schema.TABLES WHERE table_name='t1';
+------------+---------------------+
| TABLE_NAME | CREATE_TIME |
+------------+---------------------+
| t1 | 2019-10-20 08:41:57 |
+------------+---------------------+
1 row in set (0.00 sec)
另外,网上有种说法ANALYZE TABLE方法也可以重建索引,其实ANALYZE TABLE是不会对索引进行重建的。测试验证的话,你会发现ibd文件没有变化,表的修改时间/状态更改时间也没有变化。
总结:
测试完后,还是感觉MySQL索引重建的方式怪怪的,可能是有先入为主的观念。总结一下MySQL索引重建的方法:
1: DROP INDEX + RECREATE INDEX.
2: ALTER TABLE方法
3: REPAIR TABLE方法,这种方法对于InnoDB存储引擎的表无效。
4: OPTIMIZE TABLE方法
参考资料:
https://dev.mysql.com/doc/refman/8.0/en/rebuilding-tables.html
https://docs.oracle.com/cd/E17952_01/mysql-5.6-en/rebuilding-tables.html
MySQL如何进行索引重建操作?的更多相关文章
- mysql之对索引的操作
1. 为什么使用索引? 数据库对象索引与书的目录非常类似,主要是为了提高从表中检索数据的速度.由于数据储存在数据库表中,所以索引是创建在数据库表对象之上的,由表中的一个字段或多个字段生成的键组成,这些 ...
- 给MySQL字段添加索引的操作
1.添加PRIMARY KEY(主键索引): ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` ) 2.添加UNIQUE(唯一索引) : ALTE ...
- 优化、分析Mysql表读写、索引等操作的sql语句效率优化问题
为什么要优化: 随着实际项目的启动,数据库经过一段时间的运行,最初的数据库设置,会与实际数据库运行性能会有一些差异,这时我们 就需要做一个优化调整. 数据库优化这个课题较大,可分为四大类: >主 ...
- Python操作MySQL以及数据库索引
目录 python操作MySQL 安装 使用 SQL注入问题 MySQL的索引 为什么使用索引 索引的种类 主键索引 唯一索引 普通索引 索引优缺点 不会命中索引的情况 explain 索引覆盖 My ...
- MySQL全文索引 FULLTEXT索引和like的区别
1.概要 InnoDB引擎对FULLTEXT索引的支持是MySQL5.6新引入的特性,之前只有MyISAM引擎支持FULLTEXT索引.对于FULLTEXT索引的内容可以使用MATCH()-AGAIN ...
- 数据库索引使用数据结构及算法, 及MySQL不同引擎索引实现
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- MySQL笔记(5)---索引与算法
1.前言 本章记录MySQL中的索引机制,了解索引可以让数据库更快.索引太多会造成性能损耗,索引太少肯定查询效率不高. 2.InnoDB存储引擎所有概述 InnoDB中常见的索引有: B+树索引 全文 ...
- MySQL建立高性能索引策略
索引永远是最好的查询解决方案嘛? 索引并不总是最好的工具.总的来说,只有当索引帮助存储引擎快速查找到记录带来的好处大于其带来的额外工作(比如插入操作后索引的维护)时,索引才是高效的. 对于非常小的表: ...
- MySQL 深入理解索引B+树存储 (转载))
出处:http://blog.codinglabs.org/articles/theory-of-mysql-index.html 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一 ...
随机推荐
- 解决Git报错:error: You have not concluded your merge (MERGE_HEAD exists).
Git fetch和git pull的区别, 解决Git报错:error: You have not concluded your merge (MERGE_HEAD exists). 2017年02 ...
- jquery 全选,反选
<?php foreach ($contents as $item) { ?> <tr> <td><input name="qx" val ...
- java中不创建使用第三方变量,交换两个数的值
1.直接使用算术运算法交换 先把两个数的和赋值给其中一个,然后做减法.例如num1=num1+num2; 此时num2(交换之后)就等于num1减去num2:废话不多说,直接上代码 public cl ...
- Cocos2d-x入门之旅[1]场景
在游戏开发过程中,你可能需要一个主菜单,几个关卡和一个END的界面,如何组织管理这些东西呢? 和其他游戏引擎类似,Cocos也使用了场景(Scene) 这个概念 试想象一部电影或是番剧,你不难发现它是 ...
- 题解:2018级算法第二次上机 Zexal的流水线问题
题目描述: 样例: 实现解释: 最基础的流水线调度问题,甚至没有开始和结束的值 实现方法即得出状态转移方程后完善即可,设a[][i]存储着第一二条线上各家的时间花费,t[][i]存储着i处进行线路切换 ...
- 异常:微信小程序tabBar不生效
app.json全局tabBar设置tabBar不显示 由于小程序的机制问题,首页的tabBar第一个导航必须是首页 "pages": [ "pages/index/in ...
- Jmeter结构体系及运行顺序
一:jmeter运行原理: jmeter时以线程的方式来运行的(由于jmeter是java开发的所以是运行在JVM虚拟机上的,java也是支持多线程的) 二:jmeter结构体系 1.取样器smapl ...
- Cocos2d-x 学习笔记(10) ActionInstant
1.概述 ActionInstant的子类都是立即完成的动作,即一帧就完成了,不像ActionInterval的子类动作需要定义动作总时间. Action类的继承关系图: 2.具体 ActionIns ...
- 深入理解Transformer及其源码解读
深度学习广泛应用于各个领域.基于transformer的预训练模型(gpt/bertd等)基本已统治NLP深度学习领域,可见transformer的重要性.本文结合<Attention is a ...
- C#详解类型,变量与对象
本节内容: 1.什么是类型(Type) 2.类型在C#语言中的作用 3.C#语言的类型系统 4.变量.对象与内存 1.什么是类型(type) 类型又名数据类型(Date Type),是数据在内存中存储 ...