Hadoop之Flume 记录
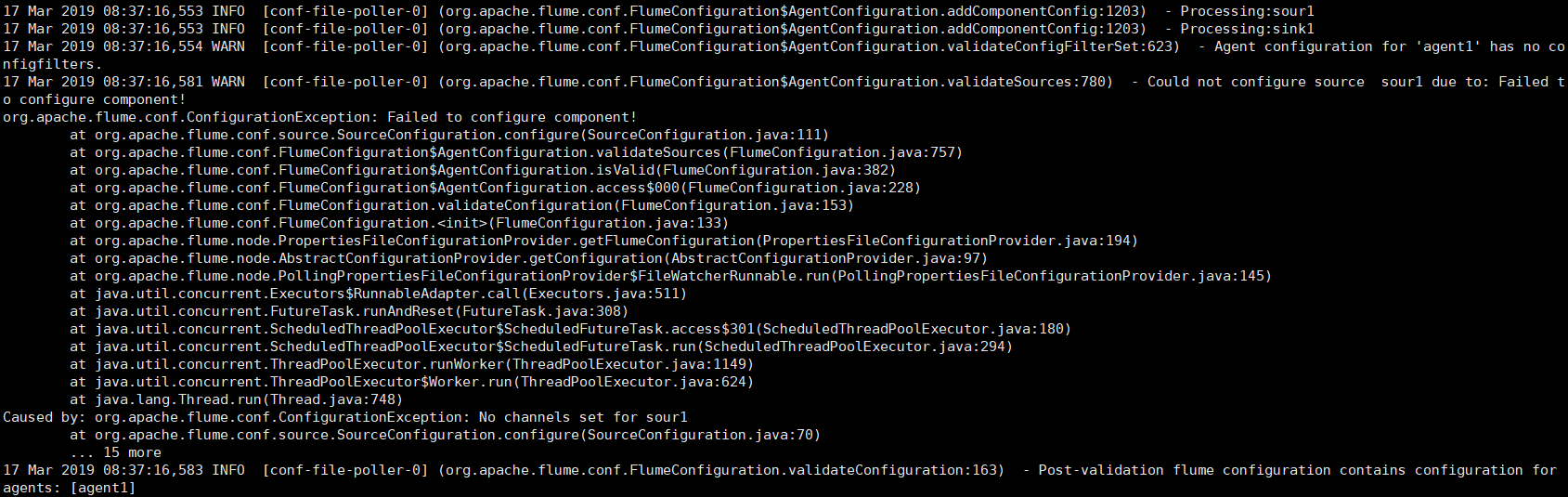
出现这个错误是自己的粗心大意,解决:
在配置flume-conf.properties文件时,source和channel的对应关系是:
myAgentName.sources.mySourceName.channels = myChannelName
myAgentName.sinks.mySinkName.channel = myChannelName
注意其中的后缀,带s和不带s后缀。
这也恰好说明
source可以“流向”多个channel,而sink只能接收一个channel的“流入”。
从channel的角度看:channel既可以接收多个source的“流入”,又可以“流向”多个sink
例如多对多关系:
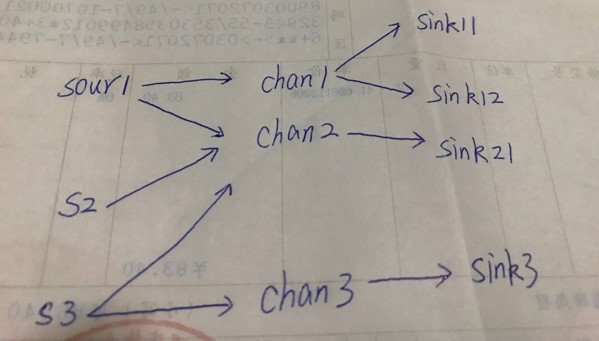
对应的配置如下:
# example.conf: A single-node Flume configuration # Name the components on this agent
agent1.sources=sour1 s2 s3
agent1.sinks=sink1 sink12 sink21 sink3
agent1.channels=chan1 chan2 chan3 # Describe/configure the source
agent1.sources.sour1.type=netcat
agent1.sources.sour1.bind=localhost
agent1.sources.sour1.port=44444 agent1.sources.s2.type=netcat
agent1.sources.s2.bind=localhost
agent1.sources.s2.port=44445 agent1.sources.s3.type=netcat
agent1.sources.s3.bind=localhost
agent1.sources.s3.port=44446 # Describe the sink
agent1.sinks.sink1.type=logger
agent1.sinks.sink12.type=logger
agent1.sinks.sink21.type=logger
agent1.sinks.sink3.type=logger # Use a channel which buffers events in memory
agent1.channels.chan1.type=memory
agent1.channels.chan1.capacity=1000
#agent1.channels.chan1.transactionCapacity=100 agent1.channels.chan2.type=memory
agent1.channels.chan2.capacity=1000 agent1.channels.chan3.type=memory
agent1.channels.chan3.capacity=1000 # Bind the source and sink to the channel
agent1.sources.sour1.channels=chan1 chan2
agent1.sources.s2.channels=chan2
agent1.sources.s3.channels=chan2 chan3 agent1.sinks.sink1.channel=chan1
agent1.sinks.sink12.channel=chan1
agent1.sinks.sink21.channel=chan2
agent1.sinks.sink3.channel=chan3
Hadoop之Flume 记录的更多相关文章
- Hadoop生态圈-Flume的主流source源配置
Hadoop生态圈-Flume的主流source源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Source,想要了解更详细的配置信息请参 ...
- Hadoop生态圈-Flume的组件之自定义拦截器(interceptor)
Hadoop生态圈-Flume的组件之自定义拦截器(interceptor) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是举例了一个自定义拦截器的方法,测试字节传输速 ...
- Hadoop生态圈-Flume的组件之自定义Sink
Hadoop生态圈-Flume的组件之自定义Sink 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客主要介绍sink相关的API使用两个小案例,想要了解更多关于API的小技 ...
- Hadoop生态圈-Flume的组件之sink处理器
Hadoop生态圈-Flume的组件之sink处理器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. 二.
- Hadoop生态圈-Flume的组件之拦截器与选择器
Hadoop生态圈-Flume的组件之拦截器与选择器 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Interceptors,想要了解更详细 ...
- Hadoop生态圈-Flume的主流Channel源配置
Hadoop生态圈-Flume的主流Channel源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一. 二. 三.
- Hadoop生态圈-Flume的主流Sinks源配置
Hadoop生态圈-Flume的主流Sinks源配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客只是配置的是Flume主流的Sinks,想要了解更详细的配置信息请参考官 ...
- Hadoop生态圈-flume日志收集工具完全分布式部署
Hadoop生态圈-flume日志收集工具完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 目前为止,Hadoop的一个主流应用就是对于大规模web日志的分析和处理 ...
- Hadoop运维记录系列
http://slaytanic.blog.51cto.com/2057708/1038676 Hadoop运维记录系列(一) Hadoop运维记录系列(二) Hadoop运维记录系列(三) Hado ...
随机推荐
- BZOJ5019[Snoi2017]遗失的答案——FWT+状压DP
题目描述 小皮球在计算出答案之后,买了一堆皮肤,他心里很开心,但是一不小心,就忘记自己买了哪些皮肤了.==|||万 幸的是,他还记得他把所有皮肤按照1-N来编号,他买来的那些皮肤的编号(他至少买了一款 ...
- crontab语法
* * * * * command minute hour day month week ...
- 树莓派中QT实现PWM
树莓派中QT实现PWM 在QT中实现 PWM 使用的驱动为 wiringPi 之前的博客中已经介绍了 wiringPi , BOARD 管脚, BCM 之间的关系 这次, 就介绍在 wiringPi ...
- 怎么添加在安装好的nvidia-docker上面根据Dockerfile构建自己所需要的运行环境
在已经创建好nvidia-docker环境之后,对于新手小白来说,又有一个问题了,就是如何根据Dockerfile来构建试验所需要的docker环境 主要是以下几个步骤 首先创建一个mydocker文 ...
- maven deploy 指定-DaltDeploymentRepository
运行deploy出现如下错误: deployment failed repository element was not specified in the POM inside distributio ...
- Markdown——入门指南
导语: Markdown 是一种轻量级的「标记语言」,它的优点很多,目前也被越来越多的写作爱好者,撰稿者广泛使用.看到这里请不要被「标记」.「语言」所迷惑,Markdown 的语法十分简单.常用的标记 ...
- netty的简单的应用例子
一.简单的聊天室程序 public class ChatClient { public static void main(String[] args) throws InterruptedExcept ...
- Linux记录-GC值
jmap -heap pid 查看gc情况: jstat -gc PID 刷新频率 jstat -gc 12538 5000 导出堆内存dump 文件: jmap -dump:file=文件名.bin ...
- input表单强制大小写
如题,在HTML页面中常常有遇到强制表单大小写的场景. 在css中设置,HTML页面元素引用就可以了 强制大写: .toUp{ text-transform:uppercase; } 强制小写: .t ...
- Web_0002:关于MongoDB的操作
1,启动moggdb服务端 打开cmd命令窗口进入到MongoDB的安装目录bin文件下: 如: cd /d F:\Program Files\mongodb\bin 执行如下命令(该命令窗口为 ...