高可用Redis(八):Redis主从复制
1.Redis复制的原理和优化
1.1 Redis单机的问题
1.1.1 机器故障
在一台服务器上部署一个Redis节点,如果机器发生主板损坏,硬盘损坏等问题,不能在短时间修复完成,就不能处理Redis操作了,这就是单机可能存在的问题
同样的,服务器正常运行,但是Redis主进程发生宕机事件,此时只需要重启Redis就可以了。如果不考虑在Redis重启期间的性能损失,可以考虑Redis的单机部署
Redis单机部署出现故障时,把Redis迁移到另一台服务器上,此时需要把发生故障的Redis中的数据同步到新部署的Redis节点,这也需要很高的成本
1.1.2 容量瓶颈
一台服务器有16G内存,此时分配12G内存运行Redis
如果有新需求:Redis需要占用32G或者64G等更多的内存,此时这台服务器就不能满足需求了,此时可以考虑更换一台更大内存的服务器,也可以用多台服务器组成一个Redis集群来满足这个需求
1.1.3 QPS瓶颈
根据Redis官方的说法,单台Redis可以支持10万的QPS,如果现在的业务需要100万的QPS,此时可以考虑使用Redis分布式
2.什么是主从复制
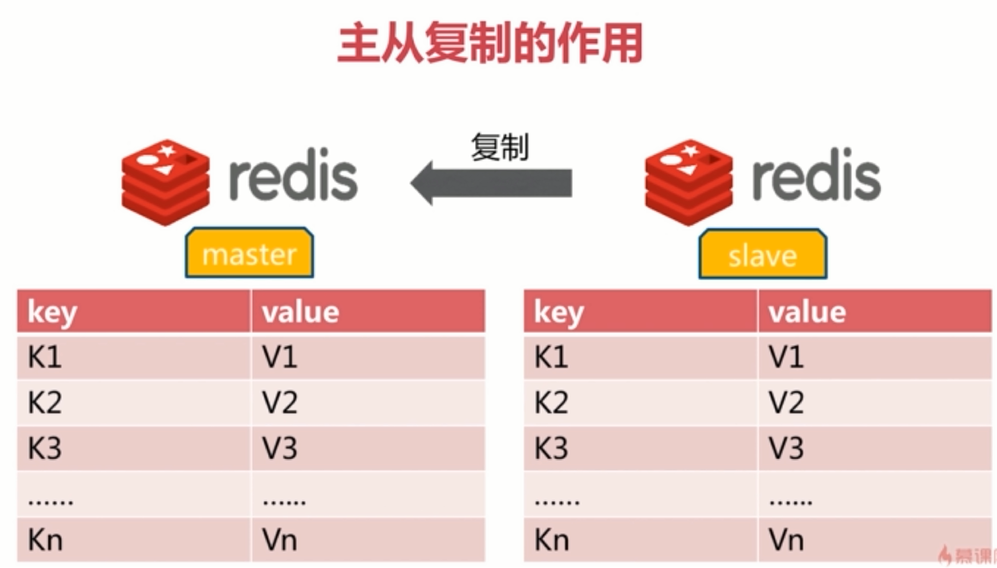
2.1 一主一从模型
一个Redis节点为master节点(主节点),负责对外提供服务。
另一个节点为slave节点(从节点),负责同步主节点的数据,以达到备份的效果。当主节点发生宕机等故障时,从节点也可以对外提供服务
如下图所示
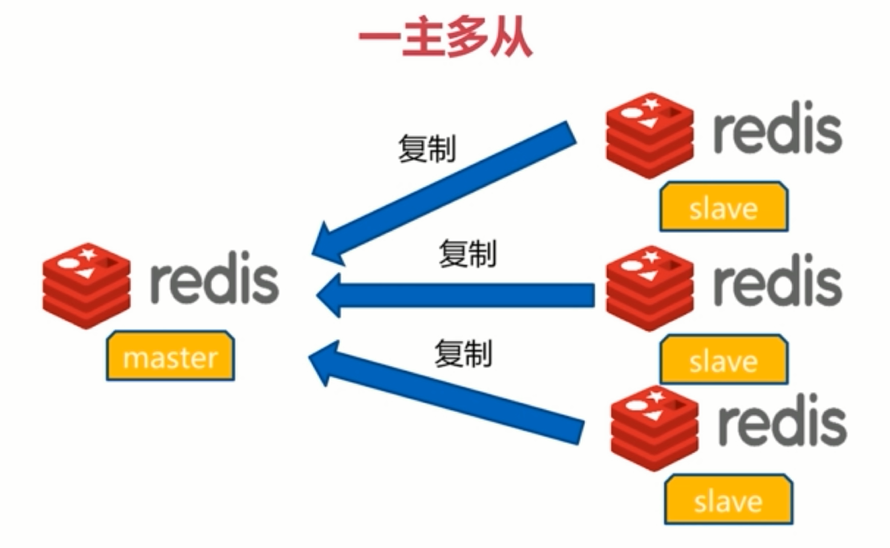
2.2 一主多从模型
一个Redis节点为master节点(主节点),负责对外提供服务。
多个节点为slave节点(从节点)。每个slave都会对主节点中的数据进行备份,以达到更加高可用的效果。这种情况下就算master和一个slave同时发生宕机故障,其余的slave仍然可以对外读提供服务,并保证数据不会丢失
当master有很多读写,达到Redis的极限阀值,可以使用多个slave节点对Redis的读操作进行分流,有效实现流量的分流和负载均衡,所以一主多从也可以做读写分离
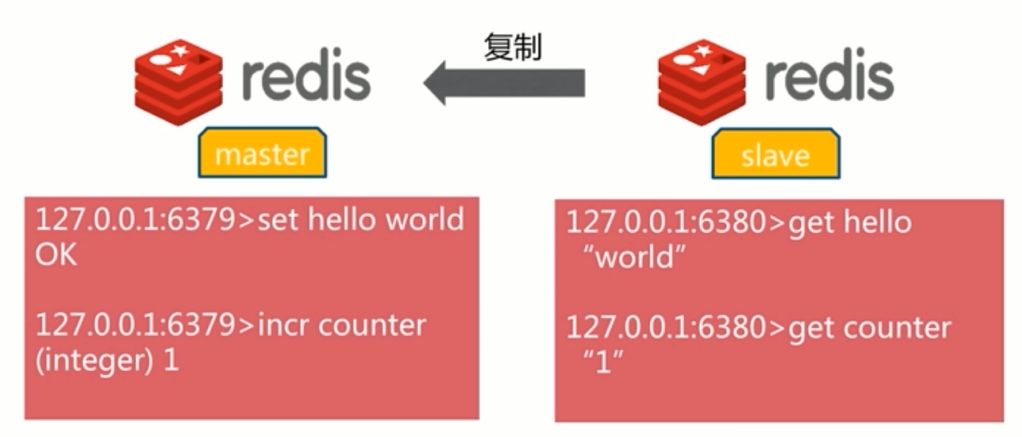
2.3 读写分离模型
master节点负责写数据,同时客户端可以从slave节点读取数据
3.主从复制作用
对数据提供了多个备份,这些备份数据可以大大提高Redis的读性能,是Redis高可用或者分布式的基础
4.主从复制的配置
4.1 slaveof命令
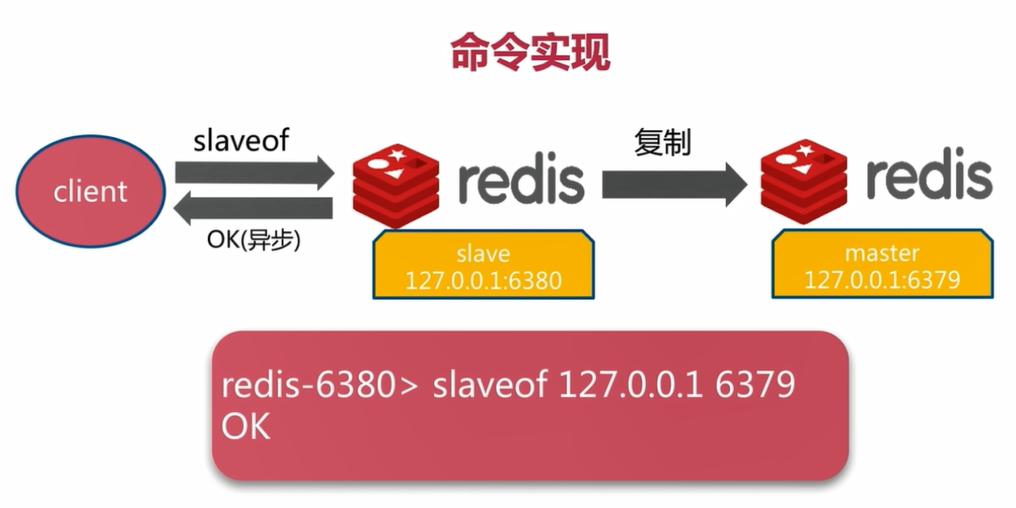
取消复制

4.2 配置文件配置
修改Redis配置文件/etc/redis.conf
slaveof <masterip> <masterport> # masterip为主节点IP地址,masterport为主节点端口
slave-read-only yes # 从节点只做读操作,不做写操作,保证主从设备数据相同
4.3 两种主从配置方式比较
使用命令行配置无需重启Redis,可以实现统一配置
使用配置文件方式配置不变于管理,而且需要重启Redis
4.4 例子
有两台虚拟机,操作系统都是CentOS 7.5
一台虚拟机的IP地址为192.168.81.100,做master
一台虚拟机的IP地址为192.168.81.101,做slave
第一步:在192.168.81.101虚拟机操作
[root@mysql ~]# vi /etc/redis.conf # 修改Redis配置文件
bind 0.0.0.0 # 可以从外部连接Redis服务端
slaveof 192.168.81.100 6379 # 设置master的IP地址和端口
然后保存修改,启动Redis
[root@mysql ~]# systemctl stop firewalld # 关闭firewalld防火墙
[root@mysql ~]# systemctl start redis # 启动slave上的Redis服务端
[root@mysql ~]# ps aux | grep redis-server # 查看redis-server的进程
redis 2319 0.3 0.8 155204 18104 ? Ssl 09:55 0:00 /usr/bin/redis-server 0.0.0.0:6379
root 2335 0.0 0.0 112664 968 pts/2 R+ 09:56 0:00 grep --color=auto redis
[root@mysql ~]# redis-cli # 启动Redis客户端
127.0.0.1:6379> info replication # 查看Redis的复制信息 查看192.168.81.101机器上的Redis的info
# Replication
role:slave # 角色为slave
master_host:192.168.81.100 # 主节点IP为192.168.81.100
master_port:6379 # 主节点端口为6379
master_link_status:up
master_last_io_seconds_ago:5
master_sync_in_progress:0
slave_repl_offset:155
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
第二步:在192.168.81.100虚拟机上操作
[root@localhost ~]# systemctl stop firewalld # 关闭firewalld防火墙
[root@localhost ~]# vi /etc/redis.conf # 修改Redis配置文件
bind 0.0.0.0
然后保存修改,启动Redis
[root@localhost ~]# systemctl start redis # 启动master上的Redis
[root@localhost ~]# ps aux | grep redis-server # 查看redis-server进程
redis 2529 0.2 1.8 155192 18192 ? Ssl 17:55 0:00 /usr/bin/redis-server 0.0.0.0:6379
root 2536 0.0 0.0 112648 960 pts/2 R+ 17:56 0:00 grep --color=auto redis
[root@localhost ~]# redis-cli # 启动master上的redis-cli客户端
127.0.0.1:6379> info replication # 查看192.168.81.100机器上Redis的信息
# Replication
role:master # 角色为主节点
connected_slaves:1 # 连接一个从节点
slave0:ip=192.168.81.101,port=6379,state=online,offset=141,lag=2 # 从节点的信息
master_repl_offset:141
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:140
127.0.0.1:6379> set hello world # 向主节点写入数据
OK
127.0.0.1:6379> info server
# Server
redis_version:3.2.10
redis_git_sha1:00000000
redis_git_dirty:0
redis_build_id:c8b45a0ec7dc67c6
redis_mode:standalone
os:Linux 3.10.0-514.el7.x86_64 x86_64
arch_bits:64
multiplexing_api:epoll
gcc_version:4.8.5
process_id:2529
run_id:7091f874c7c3eeadae873d3e6704e67637d8772b # 注意这个run_id
tcp_port:6379
uptime_in_seconds:488
uptime_in_days:0
hz:10
lru_clock:12784741
executable:/usr/bin/redis-server
config_file:/etc/redis.conf
第三步:回到192.168.81.101这台从节点上操作
127.0.0.1:6379> get hello # 获取'hello'的值,可以获取到
"world"
127.0.0.1:6379> set a b # 向192.168.81.101从节点写入数据,失败
(error) READONLY You can't write against a read only slave.
127.0.0.1:6379> slaveof no one # 取消从节点设置
OK
127.0.0.1:6379> info replication # 查看192.168.81.101机器,已经不再是从节点,而变成主节点了
# Replication
role:master # 变成主节点了
connected_slaves:0
master_repl_offset:787
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379> dbsize # 查看192.168.81.101上Redis所有数据大小
(integer) 2
第四步:回到192.168.81.100虚拟机
127.0.0.1:6379> mset a b c d e f # 向192.168.81.100上的Redis集合中写入数据
OK
127.0.0.1:6379> dbsize # Redis中数据大小为5
(integer) 5
第五步:查看192.168.81.100虚拟机上Redis的日志
[root@localhost ~]# tail /var/log/redis/redis.log # 查看Redis最后10行日志
2529:M 14 Oct 17:55:09.448 * DB loaded from disk: 0.026 seconds
2529:M 14 Oct 17:55:09.448 * The server is now ready to accept connections on port 6379
2529:M 14 Oct 17:55:10.118 * Slave 192.168.81.101:6379 asks for synchronization
2529:M 14 Oct 17:55:10.118 * Partial resynchronization not accepted: Runid mismatch (Client asked for runid '9f93f85bce758b9c48e72d96a182a2966940cf52', my runid is '7091f874c7c3eeadae873d3e6704e67637d8772b') # 与192.168.81.100设备上通过info命令查看到的run_id相同
2529:M 14 Oct 17:55:10.118 * Starting BGSAVE for SYNC with target: disk # 执行BGSAVE命令成功
2529:M 14 Oct 17:55:10.119 * Background saving started by pid 2532
2532:C 14 Oct 17:55:10.158 * DB saved on disk
2532:C 14 Oct 17:55:10.159 * RDB: 12 MB of memory used by copy-on-write
2529:M 14 Oct 17:55:10.254 * Background saving terminated with success
2529:M 14 Oct 17:55:10.256 * Synchronization with slave 192.168.81.101:6379 succeeded # 向192.168.81.101同步数据成功
第六步:回到192.168.81.101虚拟机
127.0.0.1:6379> slaveof 192.168.81.100 6379 # 把192.168.81.101重新设置为192.168.81.100的从节点
OK
127.0.0.1:6379> dbsize
(integer) 5
127.0.0.1:6379> mget a
1) "b"
第七步:查看192.168.81.101虚拟机上Redis的日志
[root@mysql ~]# tail /var/log/redis/redis.log # 查看Redis最后10行日志
2319:S 14 Oct 09:55:17.625 * MASTER <-> SLAVE sync started
2319:S 14 Oct 09:55:17.625 * Non blocking connect for SYNC fired the event.
2319:S 14 Oct 09:55:17.626 * Master replied to PING, replication can continue...
2319:S 14 Oct 09:55:17.626 * Trying a partial resynchronization (request 9f93f85bce758b9c48e72d96a182a2966940cf52:16).
2319:S 14 Oct 09:55:17.628 * Full resync from master: 7091f874c7c3eeadae873d3e6704e67637d8772b:1 # 从master节点全量复制数据
2319:S 14 Oct 09:55:17.629 * Discarding previously cached master state.
2319:S 14 Oct 09:55:17.763 * MASTER <-> SLAVE sync: receiving 366035 bytes from master # 显示从master同步的数据大小
2319:S 14 Oct 09:55:17.765 * MASTER <-> SLAVE sync: Flushing old data # slave清空原来的数据
2319:S 14 Oct 09:55:17.779 * MASTER <-> SLAVE sync: Loading DB in memory # 加载同步过来的RDB文件
2319:S 14 Oct 09:55:17.804 * MASTER <-> SLAVE sync: Finished with success
5.全量复制和部分复制
5.1 全量复制
5.1.1 run_id的概念
Redis每次启动时,都有一个随机ID来标识Redis,这个随机ID就是上面通过info命令查看得到的run_id
查看192.168.81.101虚拟机上的run_id和偏移量
[root@localhost ~]# redis-cli info server |grep run_id
run_id:7e366f6029d3525177392e98604ceb5195980518
[root@localhost ~]# redis-cli info |grep master_repl_offset
master_repl_offset:0
查看192.168.91.100虚拟机上的run_id和偏移量
[root@mysql ~]# redis-cli info server | grep run_id
run_id:7091f874c7c3eeadae873d3e6704e67637d8772b
[root@mysql ~]# redis-cli info | grep master_repl_offset
master_repl_offset:4483
run_id是一个非常重要的标识。
在上面的例子里,192.168.81.101做为slave去复制192.168.81.100这个master上的数据,会获取192.168.81.100机器上对应的run_id在192.168.81.101上做一个标识
当192.168.81.100机器上的Redis的run_id发生改变,意味着192.168.81.100机器上的Redis发生重启操作或者别的重大变化,192.168.81.101就会把192.168.81.100上的数据全部同步到192.168.81.101上,这就是全量复制的概念
5.1.2 offset的概念
偏移量(offset)就是数据写入量的字节数。
在192.168.81.100的Redis上写入数据时,master就会记录写了多少数据,并记录在偏移量中。
在192.168.81.100上的操作,会同步到192.168.81.101机器上,192.168.81.101上的Redis也会记录偏移量。
当两台机器上的偏移量相同时,代表数据同步完成
偏移量是部分复制很重要的依据
查看192.168.81.100机器上Redis的偏移量
127.0.0.1:6379> info replication # 查看复制信息
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.81.101,port=6379,state=online,offset=8602,lag=0
master_repl_offset:8602 # 此时192.168.81.100上的偏移量是8602
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:8601
127.0.0.1:6379> set k1 v1 # 向192.168.81.100写入数据
OK
127.0.0.1:6379> set k2 v2 # 向192.168.81.100写入数据
OK
127.0.0.1:6379> set k3 v3 # 向192.168.81.100写入数据
OK
127.0.0.1:6379> info replication # 查看复制信息
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.81.101,port=6379,state=online,offset=8759,lag=1
master_repl_offset:8759 # 写入数据后192.168.81.100上的偏移量是8759
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
repl_backlog_histlen:8758
查看192.168.81.101机器上Redis的偏移量
127.0.0.1:6379> info replication # 查看复制信息
# Replication
role:slave
master_host:192.168.81.100
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:8602
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0 # 此时192.168.81.101上的偏移量是8602
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379> get k3
"v3"
127.0.0.1:6379> info replication # 查看复制信息
# Replication
role:slave
master_host:192.168.81.100
master_port:6379
master_link_status:up
master_last_io_seconds_ago:7
master_sync_in_progress:0
slave_repl_offset:8759 # 同步数据后192.168.81.101上的偏移量是8759
slave_priority:100
slave_read_only:1
connected_slaves:0
master_repl_offset:0
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
如果主从节点上的offset差距太大,说明从节点没有从主节点同步数据,主从节点之间的连接出现问题:比如网络,阻塞,缓冲区等
5.1.3 全量复制的概念
如果一个主节点上已经写入很多数据,此时从节点不仅同步已经有的数据,同时同步slave在同步期间master上被写入的数据(如果在同步期间master被写入数据),以达到数据完全同步的目的,这就是Redis的全量复制的功能
Redis的master会把当前的RDB文件同步给slave,在此期间master中写入的数据会被写入复制缓冲区(repl_back_buffer)中,当RDB文件同步到slave完成,master通过偏移量的对比,把复制缓冲区(repl_back_buffer)中的数据同步给slave
Redis使用psync命令进行数据全量复制和部分复制
psync命令有两个参数:run_id和偏移量
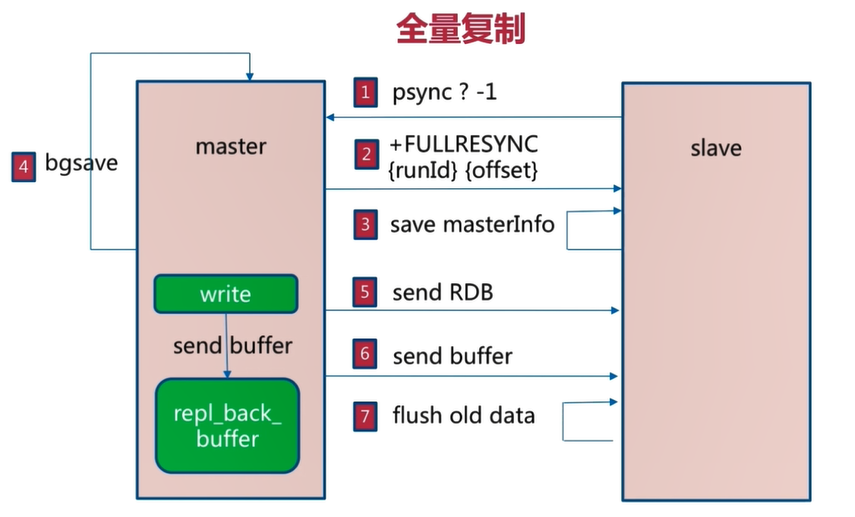
psync命令的步骤:
1.在slave第一次向master同步数据时,不知道master的run_id和offset,使用`psync ? -1`命令向master发起同步请求
2.master接受请求后,知道slave是做全量复制,master就会把run_id和offset响应给slave
3.slave保存master发送过来的run_id和offset
4.master响应slave后,执行BGSAVE命令把当前所有数据生成RDB文件,然后将RDB文件同步给slave
5.Redis中的repl_back_buffer复制缓冲区可以记录生成RDB文件之后到同步完成这个时间段时写入的数据,然后把这些数据也同步给slave
6.slave执行flushall命令清空slave中原有的数据,然后从RDB文件读取所有的数据,保证slave与master中数据的同步
如下图所示:
5.1.4 全量复制的开销
- 全量复制的开销非常大
- master执行BGSAVE命令会消耗一定时间
- BGSAVE命令会fork子进程,对CPU,内存和硬盘都有一个消耗
- master将RDB文件传输给slave的时间,传输过程中也会占用一定的网络带宽
- slave清除原有数据的时间,如果slave中原有数据比较多,清空原有数据也会消耗一定的时间
- slave加载RDB文件会消耗一定时间
- 可能的AOF文件重写的时间:RDB文件加载完成,如果slave节点的AOF功能开启,则会执行AOF重写操作,保证AOF文件中保存最新的数据
5.4 全量复制的问题
除了上面提到的开销,如果master和slave之间的网络出现问题,则在一段时间内slave上同步的数据就会丢失
解决这个问题的最好办法就是再做一次全量复制,同步master中所有数据
Redis 2.8版本中添加了部分复制的功能,如果发生master和slave之间的网络出现问题时,使用部分复制尽可能的减少丢失数据的可能,而不用全部复制
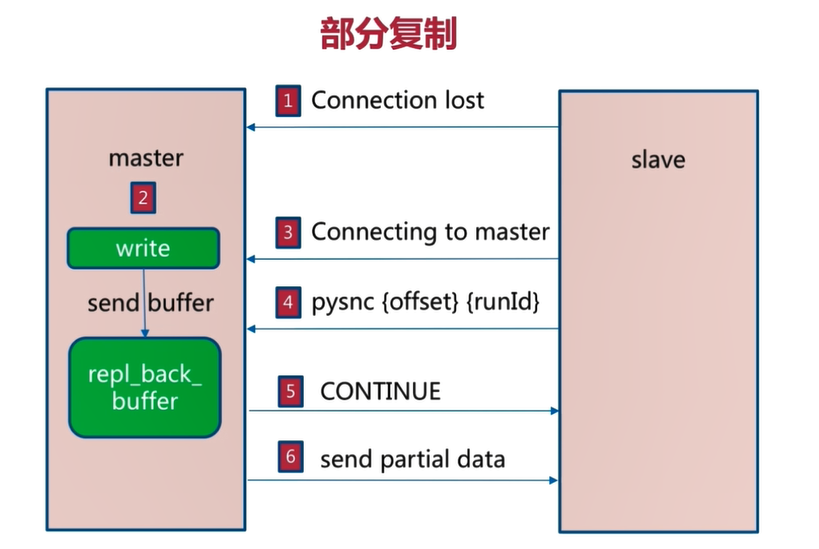
5.2 部分复制
当master与slave之间的连接断开时,master在写入数据同时也会把写入的数据保存到repl_back_buffer复制缓冲区中
当master与slave之间的网络连通后,slave会执行psync {offset} {run_id}命令,offset是slave节点上的偏移量
master接收到slave传输的偏移量,会与repl_back_buffer复制缓冲区中的offset做对比,
如果接收到的offset小于repl_back_buffer中记录的偏移量,master就会把两个偏移量之间的数据发送给slave,slave同步完成,slave中的数据就与master中的数据一致
如下图所示
6. 主从复制故障
6.1 slave宕机
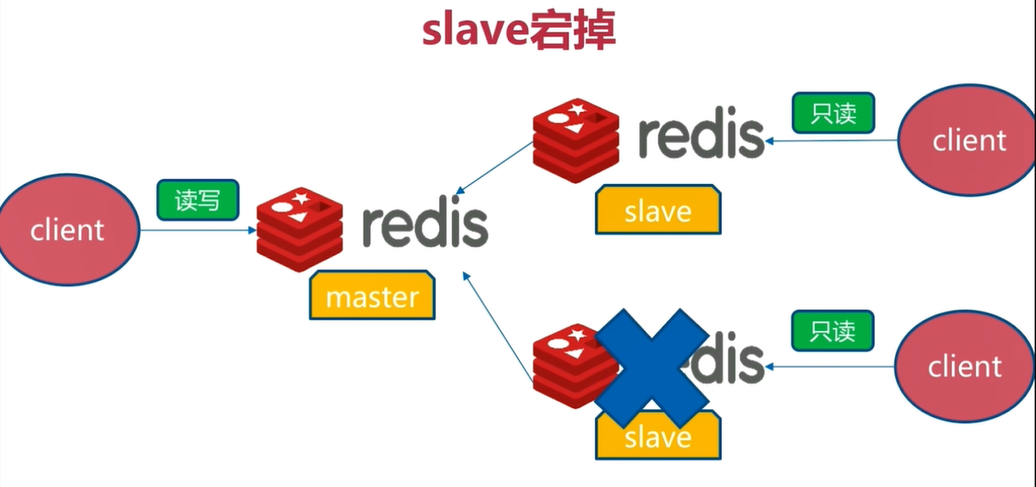
这种架构读写分离情况下,宕机的slave无法从master中同步数据
6.2 master宕机
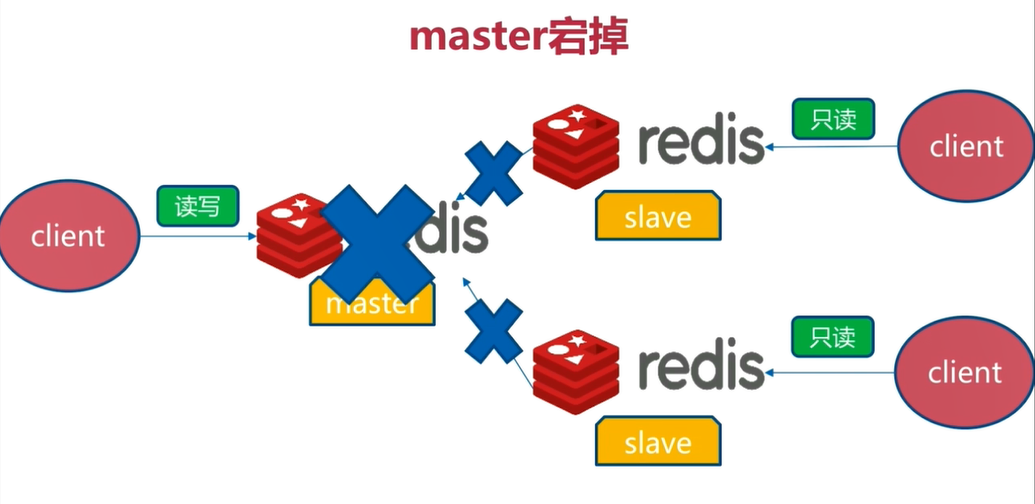
Redis的master就无法提供服务了,只有slave可以提供数据读取服务
解决方法:把其中一个slave为成master,以提供写入数据功能,另外一台slave重新做为新的master的从节点,提供读取数据功能,这种解决方法依然需要手动完成
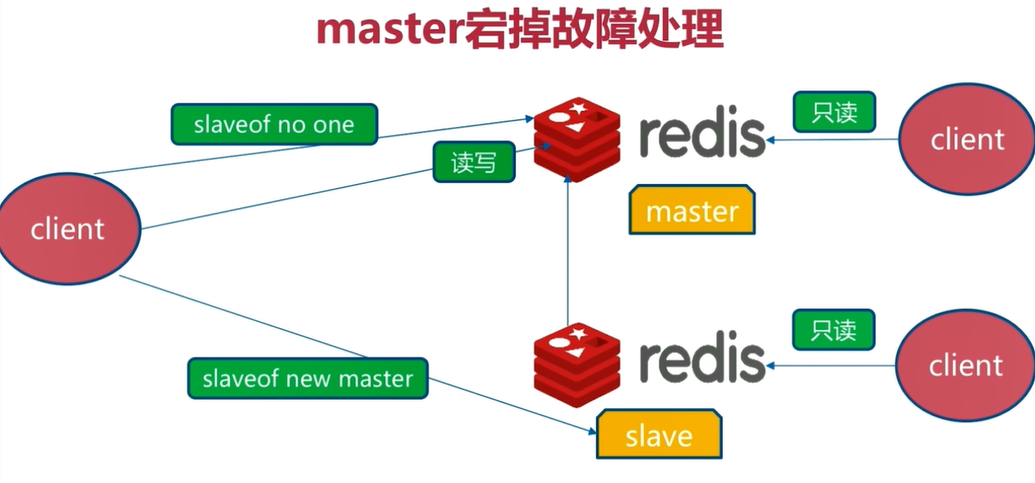
主从模式没有实现故障的自动转移,这就是Redis的sentinel的作用了
7.开发运维常见的问题
7.1 读写分离
读写分离:master负责写入数据,把读取数据的流量分摊到slave节点
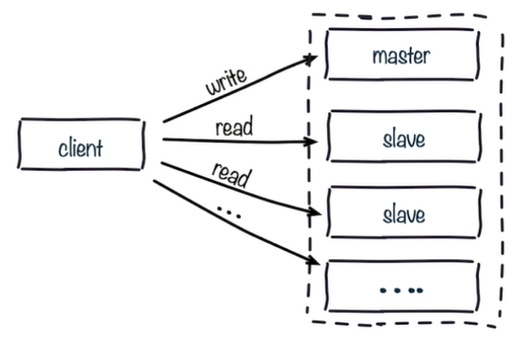
读写分离一方面可以减轻master的压力,另一方面又扩展了读取数据的能力
读写分离可以遇到的问题:
7.1.1 复制数据延迟
大多数情况下,master采用异步方式将数据同步给slave,在这个过程中会有一个时间差
当slave遇到阻塞时,接收数据会有一定延迟,在这个时间段内从slave读取数据可能会出现数据不一致的情况
可以对master和slave的offset值进行监控,当offset值相差过多时,可以把读流量转换到master上,但是这种方式有一定的成本
7.1.2 读到过期数据
Redis删除过期数据的方式
方式一:懒惰策略
当Redis操作这个数据时,才会去看这个数据是否过期,如果数据已经过期,会返回一个-2给客户端,表示查询的数据已经过期
方式二:
每隔一个周期,Redis会采集一部分key,看这些key是否过期
如果过期key非常多或者采样速度慢于key过期速度时,就会有很多过期key没有被删除
此时slave会同步包括过期key在内的master上的所有数据
由于slave没有删除数据的权限,此时基于读写分离的模式,客户端会从slave中读取一些过期的数据,也即脏数据
7.1.3 从节点故障
在图9中,slave宕机,从slave节点迁移为master节点的成本很高
在考虑使用读写分离之前,首先要考虑优化master节点的问题
Redis的性能很高,可以满足大部分场景,可以优化一些内存的配置参数或者AOF的策略,也可以考虑使用Redis分布式
7.2 主从配置不一致
第一种情况是:例如maxmemory不一致:丢失数据
如master节点分配的内存为4G,而slave节点分配的内存只有2G时,此时虽然可以进行正常的主从复制
但当slave从master同步的数据大于2G时,slave不会抛出异常,但会触发slave节点的maxmemory-policy策略,对同步的数据进行一部分的淘汰,此时slave中的数据已经不完整了,造成丢失数据的情况
另一种主从配置不一致的情况是:对master节点进行数据结构优化,但是没有对slave做同样的优化,会造成master和slave的内存不一致
7.3 规避全量复制
7.3.1 全量复制的开销是非常大的
第一次为一个master配置一个slave时,slave中没有任何数据,进行全量复制不可避免
解决方法:主从节点的maxmemory不要设置过大,则传输和加载RDB文件的速度会很快,开销相对会小一些,也可以在用户访问量比较低时进行全量复制
7.3.2 节点run_id不匹配
当master重启时,master的run_id会发生变化。slave在同步数据时发现之前保存的master的run_id与现在的run_id不匹配,会认为当前master不安全
解决方法:
做一次全量复制,当master发生故障时,slave转换为master提供数据写入,或者使用Redis哨兵和集群
Redis4.0版本中提供新的方法:当master的run_id发生改变时,做故障转移可以避免做全量复制
7.3.3 复制缓冲区不足
复制缓冲区的作用是把新的命令写入到缓冲区中
复制缓冲区实际是一个队列,默认大小为1MB,即复制缓冲区只能保存1MB大小的数据
如果slave与master的网络断开,master就会把新写入的数据保存到复制缓冲区中
当写入到复制缓冲区内的数据小于1MB时,就可以做部分复制,避免全量复制的问题
如果新写入的数据大于1MB时,就只能做全量复制了
在配置文件中修改rel_backlog_size选项来加大复制缓冲区的大小,来减少全量复制的情况出现
7.4 规避复制风暴
主从架构中,master节点重启时,则master的run_id会发生变化,所有的slave节点都会进行主从复制
master生成RDB文件,然后所有slave节点都会同步RDB文件,在这个过程中对master节点的CPU,内存,硬盘有很大的开销,这就是复制风暴
单主节点复制风暴解决方法
更换复制拓朴

单机多部署复制风暴
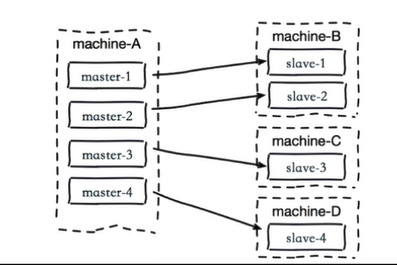
一台服务器上的所有节点都是master,如果这台服务器系统发生重启,则所有的slave节点都从这台服务器进行全量复制,会对服务器造成很大的压力
主节点分散多机器
将master分配到不同的服务器上
Redis的主从模式简单总结
一个master可以有多个slave
一个slave还可以有slave
一个slave只能有一个master
数据流向是单向的,只能从master到slave高可用Redis(八):Redis主从复制的更多相关文章
- Redis高可用(持久化、主从复制、哨兵、集群)
Redis高可用(持久化.主从复制.哨兵.集群) 目录 Redis高可用(持久化.主从复制.哨兵.集群) 一.Redis高可用 1. Redis高可用概述 2. Redis高可用策略 二.Redis持 ...
- Mycat高可用解决方案二(主从复制)
Mycat高可用解决方案二(主从复制) 系统部署规划 名称 IP 主机名称 用户名/密码 配置 mysql主节点 192.168.199.110 mysql-01 root/hadoop 2核/2G ...
- 分布式架构高可用架构篇_07_MySQL主从复制的配置(CentOS-6.7+MySQL-5.6)
参考: 龙果学院http://www.roncoo.com/share.html?hamc=hLPG8QsaaWVOl2Z76wpJHp3JBbZZF%2Bywm5vEfPp9LbLkAjAnB%2B ...
- redis高可用(一)主从复制
主从复制 读写分离 https://blog.csdn.net/u014691098/article/details/82391608
- Redis入门到高可用(八)——list
一.结构 key - value 结构,value是一个有序队列. 可进行左边的添加及弹出,右边的添加及弹出. 可获取列表的长度,删除列表中指定元素,获取列表的子列表,按照索引获取列表的指定元素. 特 ...
- 高可用Mysql架构_Mysql主从复制、Mysql双主热备、Mysql双主双从、Mysql读写分离(Mycat中间件)、Mysql分库分表架构(Mycat中间件)的演变
[Mysql主从复制]解决的问题数据分布:比如一共150台机器,分别往电信.网通.移动各放50台,这样无论在哪个网络访问都很快.其次按照地域,比如国内国外,北方南方,这样地域性访问解决了.负载均衡:M ...
- Redis主从复制、多实例、高可用(三)--技术流ken
Redis主从复制 在开始实现redis的高可用之前,首先来学习一下如何实现redis的主从复制,毕竟高可用也会依赖主从复制的技术. Redis的主从复制,可以实现一个主节点master可以有多个从节 ...
- Redis如何实现高可用【主从复制+哨兵机制+keepalived】
实现redis高可用机制的一些方法: 保证redis高可用机制需要redis主从复制.redis持久化机制.哨兵机制.keepalived等的支持. 主从复制的作用:数据备份.读写分离.分布式集群.实 ...
- Redis主从复制、多实例、高可用
Redis主从复制 在开始实现redis的高可用之前,首先来学习一下如何实现redis的主从复制,毕竟高可用也会依赖主从复制的技术. Redis的主从复制,可以实现一个主节点master可以有多个从节 ...
- redis如何实现高可用【主从复制、哨兵机制】
实现redis高可用机制的一些方法: 保证redis高可用机制需要redis主从复制.redis持久化机制.哨兵机制.keepalived等的支持. 主从复制的作用:数据备份.读写分离.分布式集群.实 ...
随机推荐
- c提高第四课
1.一维数组的初始化 , , }; //3个元素 ] = { , , }; //a[3], a[4]自动初始化为0 ] = { }; //全部元素初始化为0 memset(c, , sizeof(c) ...
- windows无法完成安装,若要在此计算机上安装,请重新启动安装
当出现如上提示的时候,不要重启,按下shift+f10 会打开命令窗口,先输入cd oobe 进入到C:\windows\system32\oobe文件夹,输入msoobe回车然后输入msoobe即可 ...
- 《java核心技术36讲》学习笔记-------杨晓峰(极客时间)
非常荣幸作为晓峰哥的同事,之前就看过这篇文章,重写读一遍,再学习学习. 一.开篇词 初级.中级:java和计算机科学基础.开源框架的使用:高级.专家:java io/nio.并发.虚拟机.底层源码.分 ...
- pandas技巧两则——列内元素统计和列内元素排序
更新:后来忽然发现有个cumcount()函数,支持正排倒排,所以以下说的那些基本都没啥用了. 最近做比赛线上无甚进展,所以先小小地总结遇到的一些困难和解决的方法,以防之后忘记.毕竟总是忙着大步赶路的 ...
- [源码分析]StringBuffer
[源码分析]StringBuffer StringBuffer是继承自AbstractStringBuilder的. 这里附上另外两篇文章的连接: AbstractStringBuilder : ht ...
- HDU - 3035 War(对偶图求最小割+最短路)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3035 题意 给个图,求把s和t分开的最小割. 分析 实际顶点和边非常多,不能用最大流来求解.这道题要用 ...
- localhost 将您重定向的次数过多
localhost 将您重定向的次数过多 问题描述:在项目中,出现 localhost 将您重定向的次数过多 ,有可能是因为设置重定向的时候,自己重定向到自己,或者重定向成环,导致无限的重定向.检查重 ...
- SQL Server TVPs 批量插入数据
在SQL Server 中插入一条数据使用Insert语句,但是如果想要批量插入一堆数据的话,循环使用Insert不仅效率低,而且会导致SQL一系统性能问题.下面介绍SQL Server支持的两种批量 ...
- 命令链接按钮QCommandLinkButton
继承QPushButton 它的用途类似于单选按钮的用途,因为它用于在一组互斥选项之间进行选择,命令链接按钮不应单独使用,而应作为向导和对话框中单选按钮的替代选项,外观通常类似于平面按钮的外观,但除了 ...
- kai linux安装搜狗输入法以及更新源地址
需要去搜狗官网下载linux版的输入法,根据自己的系统选择多少位进行下载. 首先执行如下命令:dpkg -i 输入法包名,这时会报错,会报没有安装依赖包,这时需要执行apt-get install - ...