Hadoop 数据去重
数据去重这个实例主要是为了读者掌握并利用并行化思想对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问等这些看似庞杂的任务都会涉及数据去重。下面就进入这个实例的MapReduce程序设计。
1.实例描述
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。
样例输入:
file1:
2006-6-9 a
2006-6-10 b
2006-6-11 c
2006-6-12 d
2006-6-13 a
2006-6-14 b
2006-6-15 c
2006-6-11 c
file2:
2006-6-9 b
2006-6-10 a
2006-6-11 b
2006-6-12 d
2006-6-13 a
2006-6-14 c
2006-6-15 d
2006-6-11 c
运行结果:
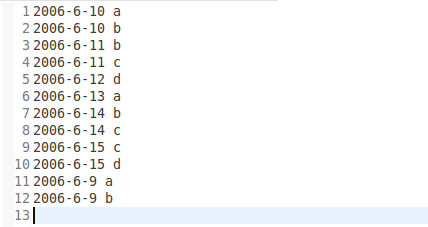
2.设计思路
数据去重实例的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。我们自然而然会想到将同一个数据的所有记录都交给一台Reduce机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是Reduce的输入应该以数据作为key,而对value-list则没有要求。当Reduce接收到一个<key,value-list>时就直接将key复制到输出的key中,并将value设置成空值。在MapReduce流程中,Map的输出<key,value>经过shuffle过程聚集成<key,value-list>后会被交给Reduce。所以从设计好的Reduce输入可以反推出Map输出的key应为数据,而value为任意值。继续反推,Map输出的key为数据。而在这个实例中每个数据代表输入文件中的一行内容,所以Map阶段要完成的任务就是在采用Hadoop默认的作业输入方式之后,将value设置成key,并直接输出(输出中的value任意)。Map中的结果经过shuffle过程之后被交给Reduce。在Reduce阶段不管每个key有多少个value,都直接将输入的key复制为输出的key,并输出就可以了(输出中的value被设置成空)
3.程序代码:
程序代码如下:
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class Dedup { // map 将输入中的value复制到输出数据的key上,并直接输出
public static class Map extends Mapper<Object, Text, Text, Text>{
private static Text line = new Text();
@Override
protected void map(Object key, Text value,Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.map(key, value, context);
line = value;
context.write(line, new Text(""));
}
} // reduce 将输入中的key复制到输出数据的key上,并直接输出
public static class Reduce extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
// super.reduce(arg0, arg1, arg2);
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length!=2){
System.out.println("Usage:Score Avg");
System.exit(2);
}
Job job = new Job(conf,"Data Deduplication");
job.setJarByClass(Dedup.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true)?0:1);
} }
Hadoop 数据去重的更多相关文章
- [Hadoop]-从数据去重认识MapReduce
这学期刚好开了一门大数据的课,就是完完全全简简单单的介绍的那种,然后就接触到这里面最被人熟知的Hadoop了.看了官网的教程[吐槽一下,果然英语还是很重要!],嗯啊,一知半解地搭建了本地和伪分布式的, ...
- hadoop mapreduce实现数据去重
实现原理分析: map函数数将输入的文本按照行读取, 并将Key--每一行的内容 输出 value--空. reduce 会自动统计所有的key,我们让reduce输出key-> ...
- hadoop —— MapReduce例子 (数据去重)
参考:http://eric-gcm.iteye.com/blog/1807468 例子1: 概要:数据去重 描述:将file1.txt.file2.txt中的数据合并到一个文件中的同时去掉重复的内容 ...
- map/reduce实现数据去重
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.co ...
- MapReduce实例(数据去重)
数据去重: 原理(理解):Mapreduce程序首先应该确认<k3,v3>,根据<k3,v3>确定<k2,v2>,原始数据中出现次数超过一次的数据在输出文件中只出现 ...
- 利用MapReduce实现数据去重
数据去重主要是为了利用并行化的思想对数据进行有意义的筛选. 统计大数据集上的数据种类个数.从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重. 示例文件内容: 此处应有示例文件 设计思路 数据 ...
- hadoop数据流转过程分析
hadoop:数据流转图(基于hadoop 0.18.3):通过一个最简单的例子来说明hadoop中的数据流转. hadoop:数据流转图(基于hadoop 0.18.3): 这里使用一个例子说明ha ...
- hadoop数据[Hadoop] 实际应用场景之 - 阿里
上班之余抽点时间出来写写博文,希望对新接触的朋友有帮助.明天在这里和大家一起学习一下hadoop数据 Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处置,例如对日志的分析,也涉及内 ...
- MYSQL数据去重与外表填充
经常要对数据库中的数据进行去重,有时还需要使用外部表填冲数据,本文档记录数据去重与外表填充数据. date:2016/8/17 author:wangxl 1 需求 对user_info1表去重,并添 ...
随机推荐
- 4327: JSOI2012 玄武密码
4327: JSOI2012 玄武密码 Description 在美丽的玄武湖畔,鸡鸣寺边,鸡笼山前,有一块富饶而秀美的土地,人们唤作进香河.相传一日,一缕紫气从天而至,只一瞬间便消失在了进香河中.老 ...
- selenium自动化测试在富文本中输入信息的方法
第一次用selenium+python编写自动测试脚本,因为页面中插入了富文本编辑,开始怎么都无法输入进去,度娘好多方法都无效,分享踩坑的经历一是为了记录一下自己的成长,二是为了给同样摸索seleni ...
- swoole 4种PHP回调函数风格
匿名函数 $server->on('Request', function ($req, $resp) use ($a, $b, $c) { echo "hello world" ...
- Bootstrap-datepicker3官方文档中文翻译---Keyboard support/键盘支持(原文链接 http://bootstrap-datepicker.readthedocs.io/en/latest/index.html)
本日期控件包含了键盘导航. “focused date” 在键盘导航期间一直会被保持追踪并且高亮显示(就想鼠标悬停的时候一样),当一个日期被切换(译者注:选中状态的切换)时或者控件隐藏时清除. up ...
- Python利用os模块批量修改文件名
初学Python.随笔记录自己的小练习. 通过查阅资料os模块中rename和renames都可以做到 他们的区别为.rename:只能修改文件名 renames:可以修改文件名,还可以修改文件上 ...
- MVC Bundle生成的css路径问题
项目是嵌套在主站的一个子站点,结果用CssRewriteUrlTransform来将相对目录路径改成相对网站根目录路径的时候发现少了虚拟目录的路径.最终解决方案: /// <summary> ...
- YOLOv3:训练自己的数据(附优化与问题总结)
环境说明 系统:ubuntu16.04 显卡:Tesla k80 12G显存 python环境: 2.7 && 3.6 前提条件:cuda9.0 cudnn7.0 opencv3.4. ...
- 洛谷 p5020 货币系统 题解
传送门 一个手动枚举能过一半点而且基本靠数学的题目(然而我考试的时候只有25分) 读清题目后发现就是凑数嘛,.... 对啊,就是凑数,怎么凑是重点啊.. 于是就绝望了一小时手动枚举n从1到5的情况 吐 ...
- [R]R语言的module工程化
很遗憾,这还是一个挖坑的问题,解决方案并不是很确定. 需求是,大多数的语言都提供import包或module的功能,避免全部代码写到一个文件中,方便管理与维护. 如常用的database模块,每次写R ...
- VB中StdPicture尺寸(Width,Height)转像素单位
首先获得一个图片对象 Dim spic As StdPicture Set spic = LoadPicture("d:\0.bmp") '从文件获得 Set spic = Cli ...