scrapy_redis实现爬虫
1、scrapy_redis的流程
- 在scrapy_redis中,所有的带抓取的对象和去重的指纹都存在所有的服务器公用的redis中
- 所有的服务器公用一个redis中的request对象
- 所有的request对象存入redis前,都会在同一个redis中进行判断,之前是否已经存入过
- 在默认的情况下,所有数据会存放在redis中
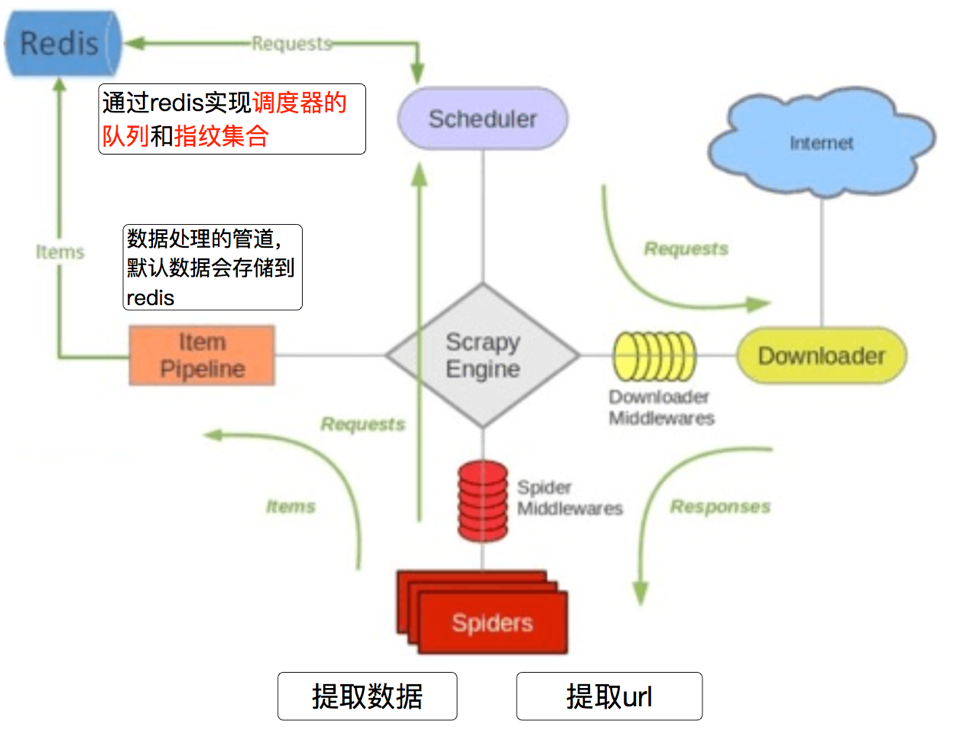
2、scrapy_redis的原理分析
我们从settings.py中的三个配置来进行分析 分别是:
- RedisPipeline
- RFPDupeFilter
- Schedule
2.1、Scrapy_redis之RedisPipeline
RedisPipeline中观察process_item,进行数据的保存,存入了redis中

2.2 Scrapy_redis之RFPDupeFilter
RFPDupeFilter 实现了对request对象的加密

2.3 Scrapy_redis之Scheduler
scrapy_redis调度器的实现了决定什么时候把request对象加入带抓取的队列,同时把请求过的request对象过滤掉

由此可以总结出request对象入队的条件
- request之前没有见过
- request的dont_filter为True,即不过滤
- start_urls中的url地址会入队,因为他们默认是不过滤
scrapy_redis实现爬虫的更多相关文章
- scrapy_redis分布式爬虫
文章来源:https://github.com/rmax/scrapy-redis Scrapy-Redis Documentation: https://scrapy-redis.readthedo ...
- scrapy-redis 分布式爬虫
为什么要学? Scrapy_redis在scrapy的基础上实现了更多,更强大的功能. 有哪些功能体现? request去重.爬虫持久化.实现分布式爬虫.断点续爬(带爬取的request存在redis ...
- 浅析scrapy与scrapy_redis区别
最近在工作中写了很多 scrapy_redis 分布式爬虫,但是回想 scrapy 与 scrapy_redis 两者区别的时候,竟然,思维只是局限在了应用方面,于是乎,搜索了很多相关文章介绍,这才搞 ...
- 爬虫遇到IP访问频率限制的解决方案
背景: 大多数情况下,我们遇到的是访问频率限制.如果你访问太快了,网站就会认为你不是一个人.这种情况下需要设定好频率的阈值,否则有可能误伤.如果大家考过托福,或者在12306上面买过火车票,你应该会有 ...
- ken桑带你读源码 之 scrapy_redis
首先更大家说下 正式部署上线的爬虫会有分布式爬虫的需求 而且原本scrapy 的seen (判断重复url的池 不知道用啥词 已抓url吧 ) 保存在磁盘 url 队列 也是保存在磁盘 (保 ...
- scrapy分布式爬虫scrapy_redis二篇
=============================================================== Scrapy-Redis分布式爬虫框架 ================ ...
- scrapy分布式爬虫scrapy_redis一篇
分布式爬虫原理 首先我们来看一下scrapy的单机架构: 可以看到,scrapy单机模式,通过一个scrapy引擎通过一个调度器,将Requests队列中的request请求发给下载器,进行页 ...
- scrapy爬虫系列之七--scrapy_redis的使用
功能点:如何发送携带cookie访问登录后的页面,如何发送post请求登录 简单介绍: 安装:pip3 install scrapy_redis 在scrapy的基础上实现了更多的功能:如reques ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
随机推荐
- maven历史版本下载地址
http://archive.apache.org/dist/maven/maven-3/
- 爬虫框架 Scrapy
一 介绍 crapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途十分广泛,可用 ...
- Android 基础一 TextView,Style样式,Activity 传值,选择CheckBox 显示密码
1.修改TextView字体 mTextView = (TextView) findViewById(R.id.textview1); mTextView.setText("I am her ...
- matplotlib坐标轴设置-【老鱼学matplotlib】
我们可以对坐标轴进行设置,设置坐标轴的范围,设置坐标轴上的文字描述等. 基本用法 例如: import numpy as np import pandas as pd import matplotli ...
- web服务-3、epoll高效率实现并发服务器
知识点: 之前写的四种方法实现并发服务效率都还是低,早期的服务器采用的是select和poll方式,select这种方式的特点是轮询所有套接字去一个个看有没有事件发生,但是装套接字的列表长度是有限制的 ...
- JS 的骚操作
一.强制类型转换 1.1string强制转换为数字 //可以用*1来转化为数字((实际上是调用.valueOf方法) 然后使用Number.isNaN来判断是否为NaN,或者使用 a !== a 来判 ...
- Handler Looper 解析
文章讲述Looper/MessageQueue/Handler/HandlerThread相关的技能和使用方法. 什么是Looper?Looper有什么作用? Looper是用于给线程(Thread) ...
- Hadoop双namenode配置搭建(HA)
配置双namenode的目的就是为了防错,防止一个namenode挂掉数据丢失,具体原理本文不详细讲解,这里只说明具体的安装过程. Hadoop HA的搭建是基于Zookeeper的,关于Zookee ...
- 更改checkbox样式css
checkbox { width: 20px; height: 20px; background-color: #d6bfa6; border: #d6bfa6; -webkit-border-r ...
- 问题:怎么把mysql的系统时间调整为电脑的时间?(已解决)
我的mysql是5.7版本. 浏览mysql的错误日志的时候,发现时间和电脑时间不一致. 查了一下,知道这个时间和log_timestamps有关, 就在mysql里执行下面一句话: SET GLOB ...