spark DAG 笔记
- DAG,有向无环图,Directed Acyclic Graph的缩写,常用于建模。
- Spark中使用DAG对RDD的关系进行建模,描述了RDD的依赖关系,这种关系也被称之为lineage,RDD的依赖关系使用Dependency维护,参考Spark RDD之Dependency,DAG在Spark中的对应的实现为DAGScheduler。
- DAGScheduler
- 作业(Job)调用RDD的一个action,如count,即触发一个Job,spark中对应实现为ActiveJob,DAGScheduler中使用集合activeJobs和jobIdToActiveJob维护Job
调度阶段(Stage ) 代表一个Job的DAG,会在发生shuffle处被切分,切分后每一个部分即为一个Stage,Stage实现分为ShuffleMapStage和ResultStage,一个Job切分的结果是0个或多个ShuffleMapStage加一个ResultStage,
任务(Task ) 最终被发送到Executor执行的任务,和stage的ShuffleMapStage和ResultStage对应,其实现分为ShuffleMapTask和ResultTask
DAG中每个节点是一个RDD
- RDD依赖关系
- 窄依赖 Narrow Dependency:
- 从父RDD角度看:一个父RDD只被一个子RDD分区使用。父RDD的每个分区最多只能被一个Child RDD的一个分区使用
- 从子RDD角度看: 依赖上级RDD的部分分区,精确知道依赖的上级RDD分区,会选择和自己在同一节点的上级RDD分区,没有网络IO开销,高效。如map,flatmap,filter
从父RDD角度看:一个父RDD被多个子RDD分区使用。父RDD的每个分区可以被多个Child RDD分区依赖
- 从子RDD角度看:依赖上级RDD的所有分区 无法精确定位依赖的上级RDD分区,相当于依赖所有分区(例如reduceByKey) 计算就涉及到节点间网络传输
- 需要shuffle
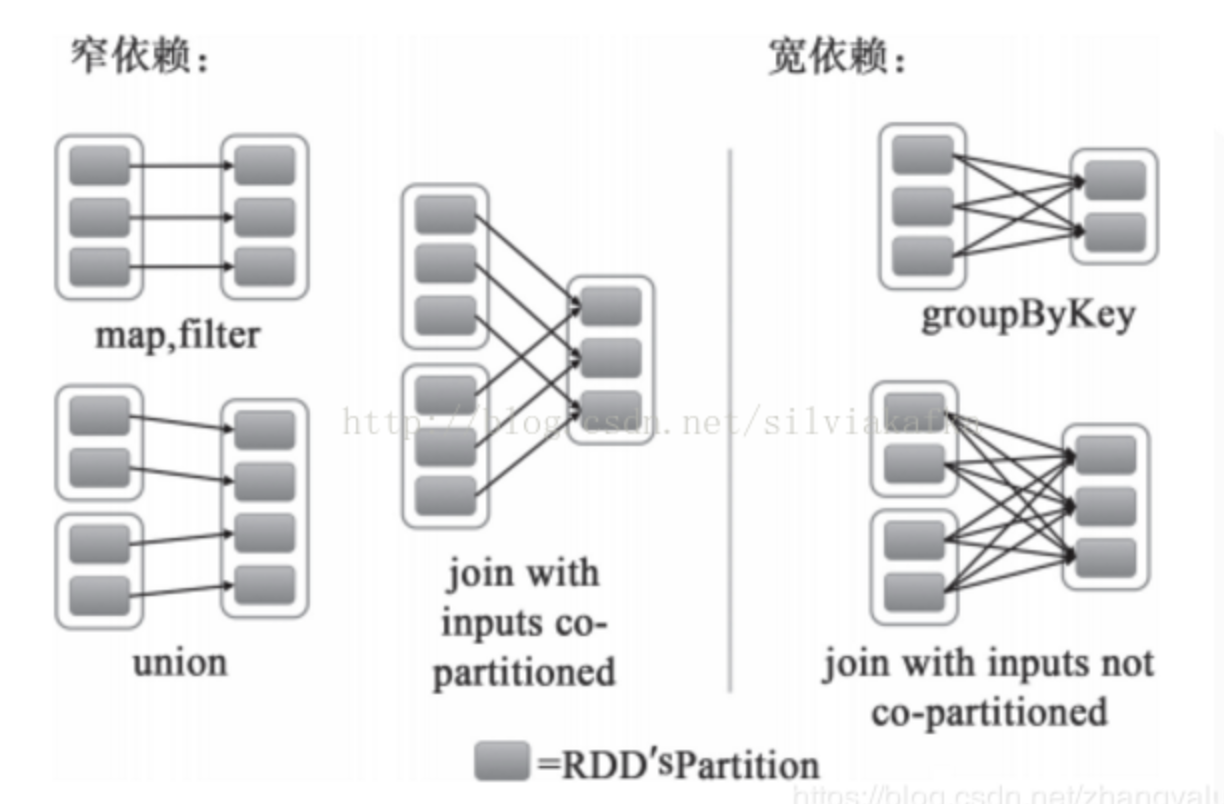
窄依赖可以支持在同一个集群Executor上,以pipeline管道形式顺序执行多条命令,例如在执行了map后,紧接着执行filter。分区内的计算收敛,不需要依赖所有分区的数据,可以并行地在不同节点进行计算。所以它的失败恢复也更有效,因为它只需要重新计算丢失的parent partition即可。
宽依赖需要所有的父分区都是可用的,必须等RDD的parent partition数据全部ready之后才能开始计算,可能还需要调用类似MapReduce之类的操作进行跨节点传递。从失败恢复的角度看,宽依赖牵涉RDD各级的多个parent partition。
宽依赖 Shffule Dependency:
- 窄依赖 Narrow Dependency:
- 划分stage
- 由于宽依赖必须等RDD的parent RDD partition数据全部ready之后才能开始计算,因此spark的设计是让parent RDD将结果写在本地,完全写完之后,通知后面的RDD。后面的RDD则首先去读之前的本地数据作为input,然后进行运算。
- 由于上述特性,将shuffle依赖就必须分为两个阶段(stage)去做
- 第一个阶段(stage)需要把结果shuffle到本地,例如reduceByKey,首先要聚合某个key的所有记录,才能进行下一步的reduce计算,这个汇聚的过程就是shuffle
- 第二个阶段(stage)则读入数据进行处理
对于transformation操作,以宽依赖为分隔,分为不同的Stages。
窄依赖------>tasks会归并在同一个stage中,(相同节点上的task运算可以像pipeline一样顺序执行,不同节点并行计算,互不影响)
宽依赖------>前后拆分为两个stage,前一个stage写完文件后下一个stage才能开始
action操作------>和其他tasks会归并在同一个stage(在没有shuffle依赖的情况下,生成默认的stage,保证至少一个stage)。
job划分原则
每个action函数内会调用runJob,进而调用submitJob,所以每个action会触发一个job。
job间按顺序执行,待前一个job完全成功,才能执行下一个job,所有job执行成功后,本application执行完成
- DAG划分:
- 各个RDD之间存在着依赖关系,这些依赖关系形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG,进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分,DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,在Worker节点上启动task。
- 当RDD触发一个Action操作(如:colllect)后,导致SparkContext.runJob的执行。而在SparkContext的run方法中会调用DAGScheduler的run方法最终调用了DAGScheduler的submit方法:
- 设计:尽量多设计窄依赖,减少宽依赖。最大化本地化处理优势,减少网络IO.
spark DAG 笔记的更多相关文章
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- Spark学习笔记3(IDEA编写scala代码并打包上传集群运行)
Spark学习笔记3 IDEA编写scala代码并打包上传集群运行 我们在IDEA上的maven项目已经搭建完成了,现在可以写一个简单的spark代码并且打成jar包 上传至集群,来检验一下我们的sp ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
随机推荐
- BDD中数据的类型及处理方法(python)
BDD中提供了两种数据类型,table和text,以下是数据的文档介绍,最后有我的两个小例子. 1.class behave.model.Table(headings, line=None, rows ...
- encode和decode区别
在python2 中是这种,编解码格式.在python3 中编码是会转换成byte类型即只显示ASCII码里的,编码会将byte转换成字符串类型.因此在py3中不需要使用,如果想要特定编码,在文件开头 ...
- linux----------fedora 27 如何启用输入法
1.安装完成以后是自带了输入法的,但是需要启用. 一定要放到第一个位置,然后注销或者重启.
- Wed Sep 19 20:48:46 CST 2018 WARN: Establishing SSL connection without server's identity verification is not recommended. According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection mus
Wed Sep 19 20:48:46 CST 2018 WARN: Establishing SSL connection without server's identity verificatio ...
- openFileDialog的Filter属性设置
OpenFileDialog对话框的Filter属性说明: 首先说明一个示例,分析一下Filter属性的构成:“ Excel文件|*.xls ”,前面的“Excel文件”成为标签,是一个可读的字符串, ...
- windows ip路由
windows 20082块网卡,连接远程mysql数据库一直不通,ping正常,telnet 3306端口不正常 route print 路由情况 route add 10.255.2574.XXX ...
- TCP三次握手及TCP连接状态 TCP报文首部格式
建立TCP连接时的TCP三次握手和断开TCP连接时的4次挥手整体过程如下图: 开个玩笑 ACK: TCP协议规定,只有ACK=1时有效,连接建立后所有发送的报文ACK必须为1 SYN(SYNchron ...
- 【003:使用SW4STM32不进入中断的原因】
系统环境: ubuntu 16.04 64bit开发环境:SW4STM32记录时间: 2017年07月01日联系方式: yexiaopeng1992@126.com背景: 在ubuntu下使用ST官方 ...
- python headers missing
系统环境 win7 64 bit,cygwin,Gvim8.1 问题 Gvim通过插件管理器Vundle下载好了YouCompleteMe插件的全部文件. 利用cygwin 进入在YouComplet ...
- laravel5.7 migrate 时报错 Specified key was too long error 解决方案
今天在数据迁移时突然报了 Specified key was too long error 的错,解决掉之后就把这个问题记录下来. 报错原因 Laravel 5.4 + 默认使用 utf8mb4 字 ...