通过ZipKin整理调用链路
缘由
思路
Zipkin的相关了解
一、Zipkin的由来
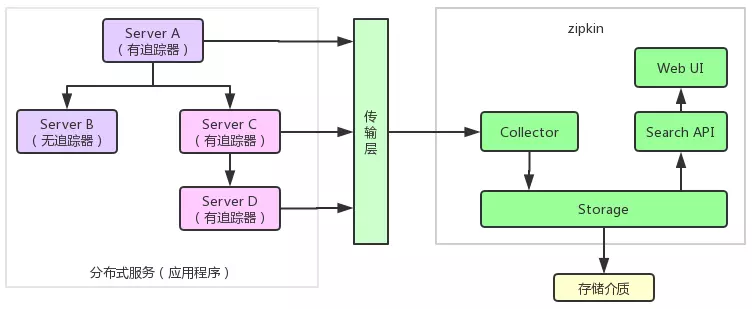
二、什么是ZipKin

curl http://localhost:9411/api/v2/trace/2e0d4019eb7aae31
curl http://localhost:9411/api/v2/services
[
{
"traceId": "string", // 追踪链路ID
"name": "string", // span名称,一般为方法名称
"parentId": "string", // 调用者ID
"id": "string", // spanID
"kind": "CLIENT", // 替代zipkin v1的注解中的四个核心状态,详细介绍见下文
"timestamp": , // 时间戳,调用时间
"duration": , // 持续时间-调用的服务所消耗的时间
"debug": true,
"shared": true,
"localEndpoint": { // 本地网络节点上下文
"serviceName": "string",
"ipv4": "string",
"ipv6": "string",
"port":
},
"remoteEndpoint": { // 远端网络节点上下文
"serviceName": "string",
"ipv4": "string",
"ipv6": "string",
"port":
},
"annotations": [ // value通常是缩写代码,对应的时间戳表示代码标记事件的时间
{
"timestamp": ,
"value": "string"
}
],
"tags": { // span的上下文信息,比如:http.method、http.path
"additionalProp1": "string",
"additionalProp2": "string",
"additionalProp3": "string"
}
}
]

cqlsh 172.10.0.5
cqlsh> describe keyspaces;
cqlsh> use zipkin2;
cqlsh> describe tables;
#查询前得对查询列建立索引
cqlsh:zipkin2> create index on span(trace_id);
cqlsh:zipkin2> select * from trace_by_service_span where trace_id='f81a638649326474';
通过ZipKin整理调用链路的更多相关文章
- spring cloud 入门系列八:使用spring cloud sleuth整合zipkin进行服务链路追踪
好久没有写博客了,主要是最近有些忙,今天忙里偷闲来一篇. =======我是华丽的分割线========== 微服务架构是一种分布式架构,微服务系统按照业务划分服务单元,一个微服务往往会有很多个服务单 ...
- Net和Java基于zipkin的全链路追踪
在各大厂分布式链路跟踪系统架构对比 中已经介绍了几大框架的对比,如果想用免费的可以用zipkin和pinpoint还有一个忘了介绍:SkyWalking,具体介绍可参考:https://github. ...
- Zipkin — 微服务链路跟踪.
一.Zipkin 介绍 Zipkin 是什么? Zipkin的官方介绍:https://zipkin.apache.org/ Zipkin是一款开源的分布式实时数据追踪系统(Distributed ...
- 跟我学SpringCloud | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
SpringCloud系列教程 | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪 Springboot: 2.1.6.RELEASE SpringCloud: ...
- Spring Cloud Sleuth+ZipKin+ELK服务链路追踪(七)
序言 sleuth是spring cloud的分布式跟踪工具,主要记录链路调用数据,本身只支持内存存储,在业务量大的场景下,为拉提升系统性能也可通过http传输数据,也可换做rabbit或者kafka ...
- 个推基于 Zipkin 的分布式链路追踪实践
作者:个推应用平台基础架构高级研发工程师 阿飞 01业务背景 随着微服务架构的流行,系统变得越来越复杂,单体的系统被拆成很多个模块,各个模块通过轻量级的通信协议进行通讯,相互协作,共同实现系统 ...
- net core 微服务框架 Viper 调用链路追踪
1.Viper是什么? Viper 是.NET平台下的Anno微服务框架的一个示例项目.入门简单.安全.稳定.高可用.全平台可监控.底层通讯可以随意切换thrift grpc. 自带服务发现.调用链追 ...
- Springboot+Dubbo使用Zipkin进行接口调用链路追踪
Zipkin介绍: Zipkin是一个分布式链路跟踪系统,可以采集时序数据来协助定位延迟等相关问题.数据可以存储在cassandra,MySQL,ES,mem中.分布式链路跟踪是个老话题,国内也有类似 ...
- zipkin:调用链显示分析
为什么使用了httpclient,客户端没有向zipkin server发送日志? 因为我实在main方法中调用的,完事后这个线程就没了:httpclient用的还是异步的发送日志方式:所以没发日志. ...
随机推荐
- Devexpress的DateEdit控件中DateTime与EditValue异同
相同: 两者值相同,改变一个值都会引起另一个值做出相应改变. 不同: 1:在界面上对控件的编辑框进行操作时,EditValueChanged事件先响应,DateTimeChanged事件后响应. 2: ...
- Linux监控
第三十次课 Linux监控 目录 一. Linux监控平台介绍 二. zabbix监控介绍 三. 安装zabbix 四. 忘记Admin密码如何做 五. 主动模式和被动模式 六. 添加监控主机 七. ...
- 初识Hibernate框架,进行简单的增删改查操作
Hibernate的优势 优秀的Java 持久化层解决方案 (DAO) 主流的对象—关系映射工具产品 简化了JDBC 繁琐的编码 将数据库的连接信息都存放在配置文件 自己的ORM框架 一定要手动实现 ...
- hello2 Source Analisis
hello2应用程序是一个web模块,它使用Java Servlet技术来显示问候和响应.此应用程序的源代码位于 _tut-install_/examples/web/servlet/hello2/目 ...
- java集合(一)
- 20165214 2018-2019-2 《网络对抗技术》Exp2 后门原理与实践 Week4
<网络对抗技术>Exp2 PC平台逆向破解之"MAL_简单后门" Week4 一.实验内容 本次实验对象为名为pwn1的pwn1的linux可执行文件.程序正常执行流程 ...
- ElementUI - Table 表头排序
ElementUI - Table 表头自带排序功能,和排序事件,但是目前只是对当前界面的数据进行排序. 项目需求: 点击表头排序的时候,对所有数据进行排序. 初步方案: 在点击排序按钮的时,在排序事 ...
- 一道笔试题来理顺Java中的值传递和引用传递
题目如下: private static void change(StringBuffer str11, StringBuffer str12) { str12 = str11; str11 = ...
- Linux中使用sed命令替换字符串小结
sed替换的基本语法为: sed 's/原字符串/替换字符串/' 单引号里面,s表示替换,三根斜线中间是替换的样式,特殊字符需要使用反斜线”\”进行转义,但是单引号”‘”是没有办法用反斜线”\”转义的 ...
- vlookup使用
数据处理过程中,需要excel进行简单的操作,比如vlookup,摸索之后,总结如下: