[LeetCode] Serialize and Deserialize N-ary Tree N叉搜索树的序列化和去序列化
Serialization is the process of converting a data structure or object into a sequence of bits so that it can be stored in a file or memory buffer, or transmitted across a network connection link to be reconstructed later in the same or another computer environment.
Design an algorithm to serialize and deserialize an N-ary tree. An N-ary tree is a rooted tree in which each node has no more than N children. There is no restriction on how your serialization/deserialization algorithm should work. You just need to ensure that an N-ary tree can be serialized to a string and this string can be deserialized to the original tree structure.
For example, you may serialize the following 3-ary tree
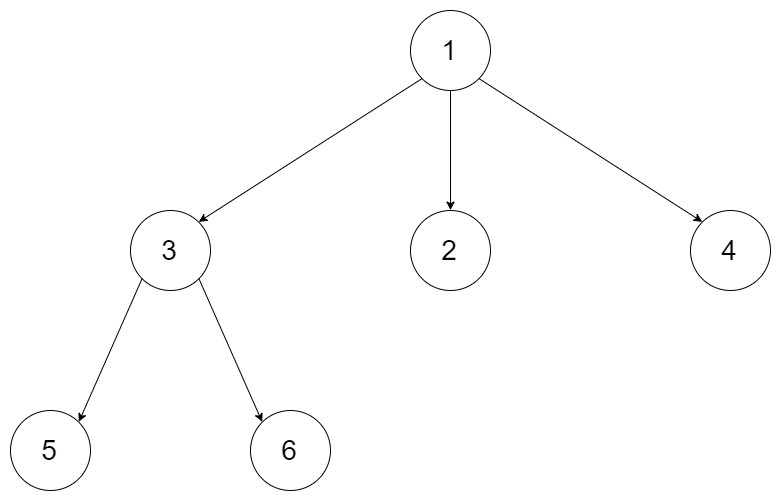
as [1 [3[5 6] 2 4]]. Note that this is just an example, you do not necessarily need to follow this format.
Or you can follow LeetCode's level order traversal serialization format, where each group of children is separated by the null value.
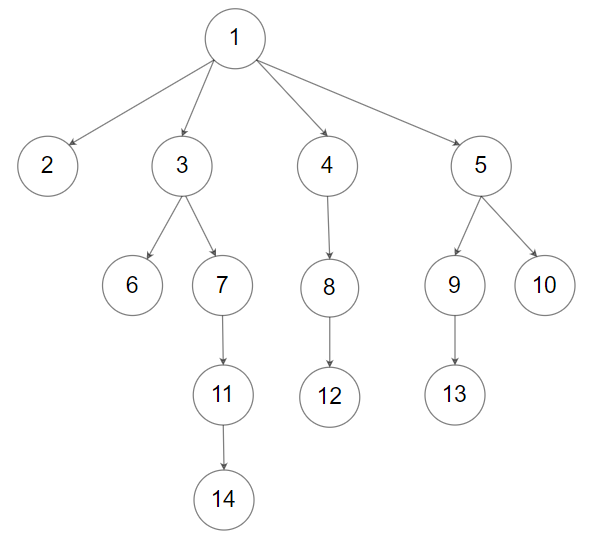
For example, the above tree may be serialized as [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14].
You do not necessarily need to follow the above suggested formats, there are many more different formats that work so please be creative and come up with different approaches yourself.
Constraints:
- The height of the n-ary tree is less than or equal to
1000 - The total number of nodes is between
[0, 10^4] - Do not use class member/global/static variables to store states. Your encode and decode algorithms should be stateless.
这道题让我们对N叉树进行序列化和去序列化,序列化就是将一个数据结构或物体转化为一个位序列,可以存进一个文件或者内存缓冲器中,然后通过网络连接在相同的或者另一个电脑环境中被还原,还原的过程叫做去序列化。现在让我们来序列化和去序列化一个二叉树,并给了我们例子。由于我们有了之前那道Serialize and Deserialize Binary Tree对二叉树的序列化和去序列化的基础,那么这道N叉树的方法也是大同小异了。首先使用先序遍历的递归解法,递归的写法就十分的简洁了,对于序列化,我们需要一个helper函数,里面首先判断结点,若为空,则结果res加上一个井字符,否则加上当前结点值,跟一个空格,再加上子结点的个数值,再跟一个空格。之后就是遍历子结点了,对每个子结点都调用递归函数即可。去序列函数需要用一个字符串流类来帮助读字符,这个类是按空格来断开字符串的,所以我们在序列化的时候中间都是用的空格。我们同样需要一个helper函数,首先读出结点值,如果读出了井字号,直接返回空。否则继续读出子结点的个数,有了结点值我们就可以新建一个结点了,同时知道了子结点的个数,那么我们就循环调用递归函数相同的次数,将返回的子结点加入子结点数组即可,参见代码如下:
解法一:
class Codec {
public:
// Encodes a tree to a single string.
string serialize(Node* root) {
string res;
serializeHelper(root, res);
return res;
}
void serializeHelper(Node* node, string& res) {
if (!node) res += "#";
else {
res += to_string(node->val) + " " + to_string(node->children.size()) + " ";
for (auto child : node->children) {
serializeHelper(child, res);
}
}
}
// Decodes your encoded data to tree.
Node* deserialize(string data) {
istringstream iss(data);
return deserializeHelper(iss);
}
Node* deserializeHelper(istringstream& iss) {
string val = "", size = "";
iss >> val;
if (val == "#") return NULL;
iss >> size;
Node *node = new Node(stoi(val), {});
for (int i = ; i < stoi(size); ++i) {
node->children.push_back(deserializeHelper(iss));
}
return node;
}
};
我们还可以使用层序遍历的迭代写法,序列化的函数相对来说好一点,还是先判空,若为空,直接返回井字号。否则就使用队列,加入根结点,然后就进行while循环,先取出队首结点,然后res加入结点值,再加入空格,加入子结点个数,再加上空格。之后再把每一个子结点都加入队列中即可。去序列化函数稍稍复杂一些,还是要用字符流类来读取字符,需要用两个队列,分别来保存结点,和子结点个数。首先我们先取出结点值,如果是井字号,直接返回空。否则再取出子结点个数,我们先根据之前取出的结点值新建一个结点,然后加入结点队列,把子结点个数加入个数队列。然后就开始遍历了,首先分别取出结点队列和个数队列的队首元素,然后循环子结点个数次,再取出结点值,和子结点个数,如果其中某个值没取出来,就break掉。根据取出的结点值新建一个结点,然后将结点值加入结点队列,子结点个数加入个数队列,然后将子结点加入子结点数组,参见代码如下:
解法二:
class Codec {
public:
// Encodes a tree to a single string.
string serialize(Node* root) {
if (!root) return "#";
string res;
queue<Node*> q{{root}};
while (!q.empty()) {
Node *t = q.front(); q.pop();
res += to_string(t->val) + " " + to_string(t->children.size()) + " ";
for (Node *child : t->children) {
q.push(child);
}
}
return res;
}
// Decodes your encoded data to tree.
Node* deserialize(string data) {
istringstream iss(data);
queue<Node*> qNode;
queue<int> qSize;
string val = "", size = "";
iss >> val;
if (val == "#") return NULL;
iss >> size;
Node *res = new Node(stoi(val), {}), *cur = res;
qNode.push(cur);
qSize.push(stoi(size));
while (!qNode.empty()) {
Node *t = qNode.front(); qNode.pop();
int len = qSize.front(); qSize.pop();
for (int i = ; i < len; ++i) {
if (!(iss >> val)) break;
if (!(iss >> size)) break;
cur = new Node(stoi(val), {});
qNode.push(cur);
qSize.push(stoi(size));
t->children.push_back(cur);
}
}
return res;
}
};
类似题目:
Serialize and Deserialize Binary Tree
Encode N-ary Tree to Binary Tree
参考资料:
https://leetcode.com/problems/serialize-and-deserialize-n-ary-tree/
https://leetcode.com/problems/serialize-and-deserialize-n-ary-tree
LeetCode All in One 题目讲解汇总(持续更新中...)
[LeetCode] Serialize and Deserialize N-ary Tree N叉搜索树的序列化和去序列化的更多相关文章
- [LeetCode] Serialize and Deserialize Binary Tree 二叉树的序列化和去序列化
Serialization is the process of converting a data structure or object into a sequence of bits so tha ...
- [LeetCode] Serialize and Deserialize Binary Tree
Serialize and Deserialize Binary Tree Serialization is the process of converting a data structure or ...
- LeetCode——Serialize and Deserialize Binary Tree
Description: Serialization is the process of converting a data structure or object into a sequence o ...
- [LeetCode] Serialize and Deserialize BST 二叉搜索树的序列化和去序列化
Serialization is the process of converting a data structure or object into a sequence of bits so tha ...
- LeetCode初级算法--树02:验证二叉搜索树
LeetCode初级算法--树02:验证二叉搜索树 搜索微信公众号:'AI-ming3526'或者'计算机视觉这件小事' 获取更多算法.机器学习干货 csdn:https://blog.csdn.ne ...
- Leetcode: Serialize and Deserialize BST
Serialization is the process of converting a data structure or object into a sequence of bits so tha ...
- [LeetCode] Lowest Common Ancestor of a Binary Search Tree 二叉搜索树的最小共同父节点
Given a binary search tree (BST), find the lowest common ancestor (LCA) of two given nodes in the BS ...
- [LeetCode] Insert into a Binary Search Tree 二叉搜索树中插入结点
Given the root node of a binary search tree (BST) and a value to be inserted into the tree, insert t ...
- [LeetCode] Search in a Binary Search Tree 二叉搜索树中搜索
Given the root node of a binary search tree (BST) and a value. You need to find the node in the BST ...
随机推荐
- 利用 /proc/sys/kernel/core_pattern隐藏系统后门
ref:https://xz.aliyun.com/t/1098/ 这里所说的core_pattern 指的是:/proc/sys/kernel/core_pattern. 我们知道在Linux系统中 ...
- Java设计模式之抽象工厂
概述 设计模式(Design Pattern)是一套被反复使用.多数人知晓的.经过分类的.代码设计经验的总结. 使用设计模式的目的:为了代码可重用性.让代码更容易被他人理解.保证代码可靠性. 设计模式 ...
- springMVC中 @RequestParam和@RequestBody的区别
首先,不可以同时传进@RequestParam和@RequestBody,好像可以传进两个@RequestParam 如果不加@requestparam修饰,相当于 加上@requestparam且各 ...
- luogu 4345 Lucas的变形应用
求 sigma i由0-k C(n,i) 利用Lucas定理+整除分块将C(n/p,i/p)利用i/p分块,得到k/p-1个整块(p-1)和一个小块(k%p) 最后得到式子 F(n,k)=F(n/p, ...
- dubbo和zikkeper的使用
1.先来一段异常看看:No provider available for the service 16:05:25.755 [localhost-startStop-1] WARN o.s.w.c.s ...
- html-webpack-template, 一个更好的html web service插件
源代码名称:html-webpack-template 源代码网址:http://www.github.com/jaketrent/html-webpack-template html-webpack ...
- web开发简史与技术选型
视频地址:http://v.youku.com/v_show/id_XMTQxNzM1MzAwOA==.html?firsttime=0&from=y1.4-2
- yum安装软件报错Segmentation fault处理
yum安装软件报错Segmentation fault处理 在使用yum 更新软件时提示:Segmentation fault 中文错误提示: 段错误 [root@CMS-BAK:/usr/local ...
- FM算法(二):工程实现
主要内容: 实现方法 Python实现FM算法 libFM 一.实现方法 1.FM模型函数 变换为线性复杂度的计算公式: 2.FM优化目标 根据不同的应用,FM可以采用不同的损失函数loss fu ...
- JDK 8 函数式编程入门
目录 1. 概述 1.1 函数式编程简介 1.2 Lambda 表达式简介 2. Lambda 表达式 2.1 Lambda 表达式的形式 2.2 闭包 2.3 函数接口 3. 集合处理 3.1 St ...