word2vec概述
既然是概述,那么我也只会在文中谈一点关于 Word2Vec 的思想和大概的方法。对于这个算法,如果一开始学习就深入到算法细节中,反而会陷入局部极值点,最后甚至不知道这个算法是干嘛的。在了解算法大概的思路后,如果有进一步研究的必要,再去深究算法细节,这时一切都是水到渠成的。
先申明,由于我不是做 NLP 相关的,因此本文参考的主要是文末提供的博客,在算法理解上有很多不成熟的地方,还请见谅。
什么是Word2Vec
Word2Vec,顾名思义,就是把一个 word 变成一个 vector。其实,早在 Word2Vec 出来之前,就已经有很多人思考这个问题了。而用的最多的方法大概是 tf-idf 这类基于频率的方法。不过这类方法有什么问题呢?一个很明显的缺陷是,这些方法得到的向量是没有语义的,比如说,对于「苹果」、「香蕉」、「可乐」这三个词来说,「苹果」和「香蕉」表示的向量应该比「可乐」更加相似,这种相似有很多衡量方法(比如「欧式距离」或「余弦相似性」),但用频率的方法是很难体现这种相似性的。而 Word2Vec 就是为了解决这种问题诞生的。
Word2Vec 是 Google 的 Tomas Mikolov 及其团队于 2013 年创造的,正如之前提到的,这个模型是为了让 word 生成的向量能体现语义信息。它是一种基于预测的模型。
基本思想
在了解 Word2Vec 的基本思想之前,我们先思考一个问题:什么是词的语义?这是一个很难回答的问题,因此,我们降低一下难度:如何判断两个词的语义是相似的?好吧,这依然不好回答。那么,我们继续简单点想:两个语义相似的词会有什么特点呢?它们可能词性相同(比如都是名词或形容词),可能在句子中出现的位置很类似等等。
比如,我们看一个例子:「The quick brown fox jumps over the lazy dog.」。现在,我们聚焦到「fox」这个词,如果要把它换成其他词,要怎么做呢?一个最简单的方法是,我们去搜索其他句子,看其他句子中是否也有「brown __ jumps”」这样的格式出现,如果出现了,则下划线代表的词很可能是可以替换「fox」的。而根据常识,会出现在形容词之后和动词之前的词,一般来说是个名词,因此,我们这种替换的思路也是有一定道理的,起码一个名词和「fox」之间的相似性,相比动词或副词会更大一些。这里的替换其实就包含一点语义,只有两个词语义相似,才能相互替换。当然,这种相似显得稍微粗糙了一点(毕竟不同的名词或动词之间也是相差万别),但是,如果语料库足够丰富,我们还是可以进一步学习出不同名词之间的差别的。比如,对于这样的句子:「The man plays basketball.”」 ,如果要替换「man」这个词,我们发现,由于有「plays basketball」的限制,就不是什么名词都可以派上用场了。同样地,我们扫描其他句子,找出有类似结构「The __ plays basketball」的句子,然后将下划线的词和「man」做对比,这时,我们会发现,这样的词更多的会是一个表示人类的名词,而不在是「cat」等其他名词。因此,只要语料库够大,我们对相似度的判断粒度也会更细。
好了,以上这个例子,其实就是 Word2Vec 的基本思想了。
Word2Vec 主要就是利用上下文信息,或者更具体一点,与一个词前后相邻的若干个词,来提取出这个词的特征向量。
方法
为了利用这种上下文信息,Word2Vec 采用了两种具体的实现方法,分别是 CBOW 和 Skip-grams。这两种方法本质上是一样的,都是利用句子中相邻的词,训练一个神经网络。它们各有优劣,因此各自实现的 Word2Vec 的效果也各有千秋。
需要注意的是,由于语料库是没有任何标记的,因此这种方法是一种无监督学习的方法,而我们训练的这个网络,最终并不是想用它来输出特征,而是将网络的参数作为文本的特征(类似 auto-encoder)。
下面,我分别简单介绍一下 CBOW 和 Skip-grams。
CBOW(Continuous Bag of Words)
CBOW 采用给定上下文信息来预测一个词的战术来训练神经网络。
用一个例子来说明 CBOW 的过程。假设现在我们的语料库只有一句话:"The quick brown fox jumps over the lazy dog"。算法中有一个参数 window,表示依赖的上下文数量,如果 window 设为 1,则只依赖左右一个单词,比如,对于「fox」这个词,对应的上下文就是「brown」和「jumps」,一般来说,这个值越大,准确性越高,计算量也会越大。现在,我们把 window 设为 2,这样,对于上面的句子,可以分解成下面这些训练的样本对:
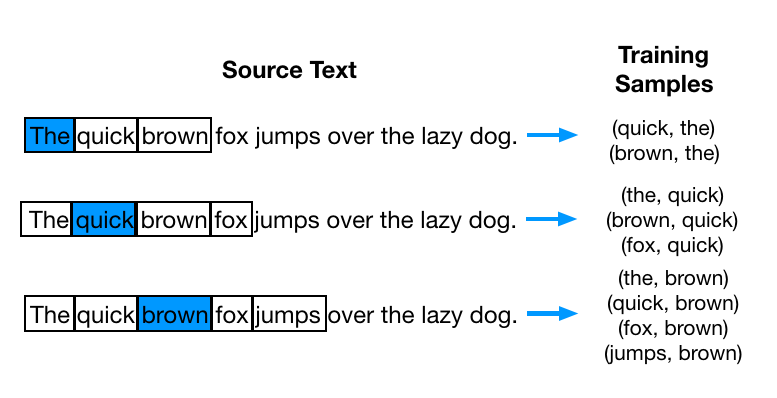
当然,文本是没法直接用于训练的,通常,我们还需要把这些训练的文本向量化。这一步向量化可以采用多种方法,比如直接用 one-hot 向量来表示。这样一来,训练对就变成了向量对,我们输入网络的是左边的向量,输出的则是右边的向量。
在正式训练之前,有必要先讲一下 CBOW 的网络结构。
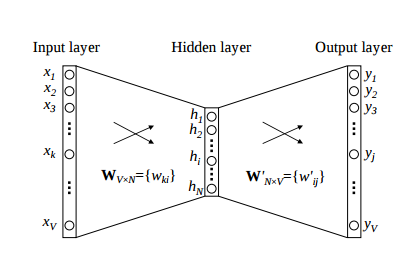
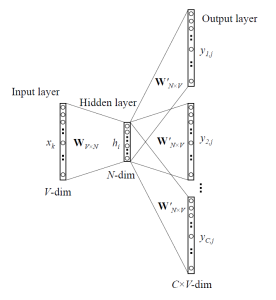
如上图所示,CBOW 的网络结构其实非常简单,Input layer 是训练对中左边的向量。Hidder layer 则是 Input layer 线性组合而成的,换句话说,中间的隐藏层没有激活函数。需要注意的是,Output layer 并不直接就是输出向量,而是经过 Softmax 函数后得到的向量,我们知道,Softmax 得到的向量表示一连串的概率分布,因此,网络要学习的任务,就是让概率最大的位置,对应到输出向量 one-hot 中值为 1 的位置。
再具体一点,假设我们语料库中的词的数目是 \(V\),隐藏层的神经元数目是 \(N\),那么,输入向量就是一个 \([V \times 1]\) 的向量,输入层与隐藏层之间有一个 \([N \times V]\) 的权重矩阵,隐藏层是一个 \([N \times 1]\) 的向量,隐藏层和输出层之间有一个 \([V \times N]\) 的向量,输出层是一个 \([V \times 1]\) 的向量。
对于代价函数而言,由于我们最后的激活层是 Softmax,因此对应的一般用 \(log-likelihood\) 函数作为 cost function:\(-\log{(p())}\),其中 \(p()\) 指的就是 Softmax 函数,它的具体形式这里就不展开了。
好了,讲完 CBOW 的网络结构后,接下来要看看如何用那些 training samples 来训练网络了。
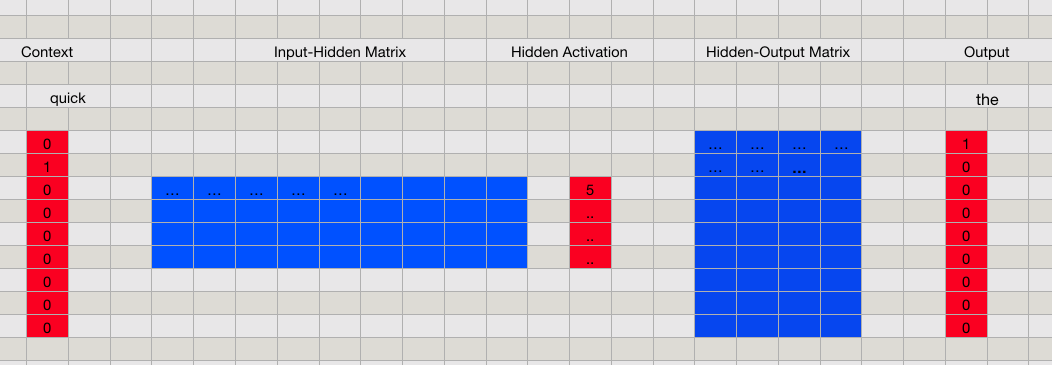
首先要强调一下,CBOW 的目的是要用 context 的内容来预测单词,如果只是简单地把训练样本对「喂」给上面所示的神经网络,那么我们用到的上下文信息只有一个相邻的单词而已。为了更好地利用 context 的内容,CBOW 实际上会把所有的邻居单词都输入到网络中。比如,对于例子中的第二个样本对 \([(the, quick), (brown, quick), (fox, quick)]\),我们是这样输入到网络中的:

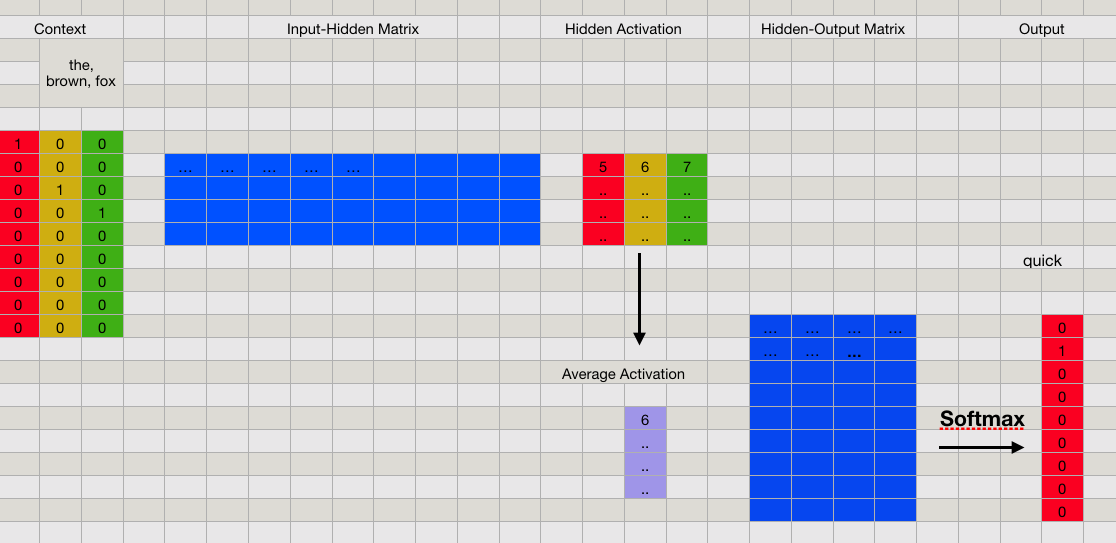
隐藏层那里,我们把三个输入向量前向后得到的隐藏层向量平均了一下,得到最终的隐藏层,之后的步骤和单个输入的情况是一致的。
这样不断训练优化参数后,最后得到的网络就可以根据输入的上下文信息,猜出对应的单词是哪个了。而我们要的 vector 向量其实就是隐藏层和输出层之间的权重矩阵 Hidden-Ouput Matrix。这是一个 \(V \times N\) 的矩阵,矩阵的每一行代表的就是一个词的 vector,这个 vector 的维度是 \(N\),刚好就是我们定义的隐藏层神经元的数目。你也可以把这个矩阵当作一个词典
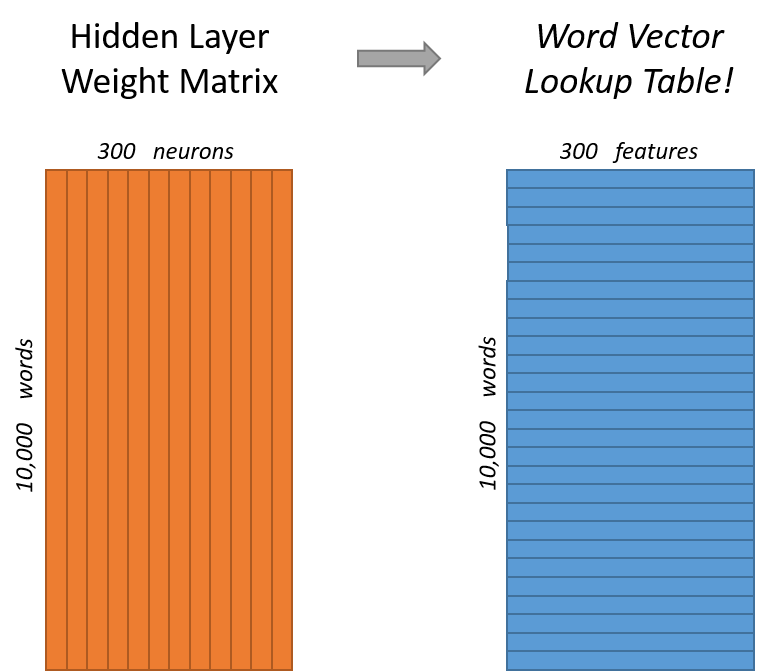
根据输出层对应的 one-hot 编码,在词典对应的行中找到特征向量即可。比如,如果要找「fox」的特征,由于它的 one-hot 为:\([0, 0, 0, 1, 0, 0, 0, 0, 0]\),因此,词典中第四行对应的向量就是「fox」的特征向量。
好了,我们已经把最简单版本的 CBOW 讲完了,它最主要的思想,其实就是把上下文的向量平均一下(上面例子中的 \(Average\ Activation\)),再用这个向量去预测出输出向量(即在 \(Hidden-Output\ Matrix\) 中 match 一个特定的行向量,使得到的概率值最大)。因此,我们可以认为,一个词最终得到的向量,其实是它所有上下文向量的平均效果。比如,对于「Apple」这个词来说,由于它既可以是一种水果,也可以是一个公司,因此,「Apple」这个词对应的向量可能会在水果和公司这些词向量的聚类集合之间。
Skip-grams
与 CBOW 相反,Skip-grams 采用给定一个词来预测上下文的战术来训练神经网络。
假如还是之前的例子 "The quick brown fox jumps over the lazy dog"。同样将 window 的值设为 2,这次我们会分解出下面这些训练的样本对:
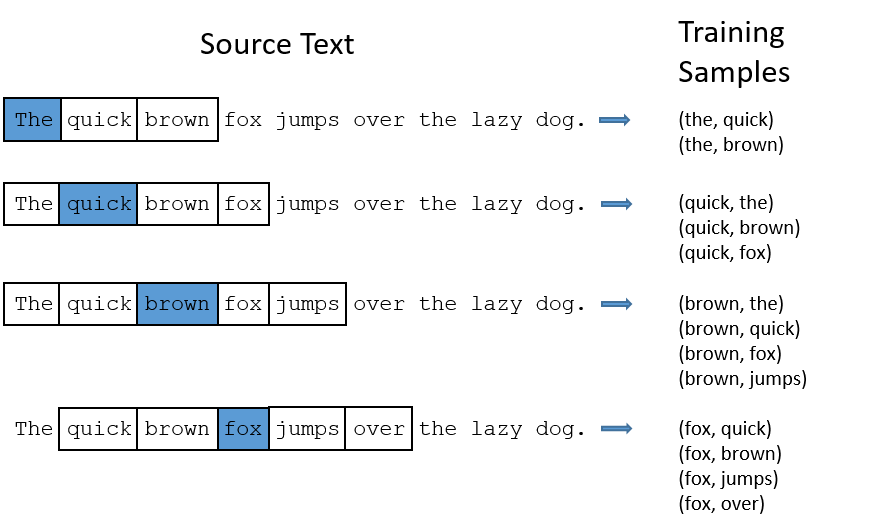
和 CBOW 很类似,只不过训练样本中,输入和输出对调了位置。
Skip-grams 的网络结构和 CBOW 是一样的,只不过训练的时候,我们输入的是一个向量,而输出则对应多个向量:
我们再次用矩阵的形式看看这个过程(这里偷个懒,我就直接盗参考链接的图了):
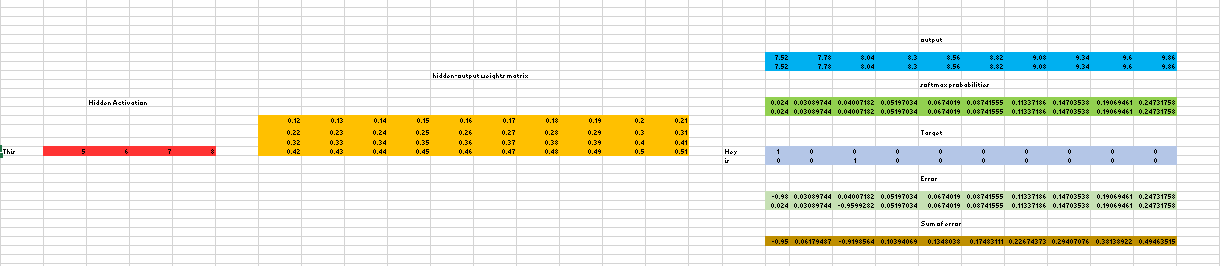
这个图里只包括了隐藏层到输出层的部分,前面输出层到隐藏层的部分和一般的网络是一样的。
注意到,我们这里同样将隐藏层的神经元数目设为 4。
在 Output 的时候,根据输入单词对应的上下文单词数量,我们对应的要输出相同数量的向量,上图中,输出的向量个数是 2。当然,在一次前向中,这两个输出向量是相同的,不过,我们要的其实是用于反向传播的误差。比如,这两个输出向量对应的词是不同的,因此,对应的 Target 向量(也就是 one-hot)也是不同的,这样,用各自对应的 Target 向量减去 Softmax 得到的向量,我们可以得到两个不同的误差,然后,把这两个误差加起来作为总的误差,再反向传播回去。
这个过程和 CBOW 有相似之处,在 CBOW 中,我们平均的是上下文向量的隐藏层,而 Skip-grams 平均的是上下文向量的误差。所以,我们可以简单地想,Skip-grams 其实也是在平均上下文向量,并依此得到我们要的词向量。
对应的,Skip-grams 的词典是输入层和隐藏层之间的权重矩阵,和 CBOW 完全反着来。
总结
写到最后,我发现这篇文章其实主要是在讲 CBOW 和 Skip-grams 的思想,稍稍有点偏题了。
其实,重要的还是这两个方法中用到的基于上下文预测语义的思想,这一点和 Word2Vec 是一致的。当然啦,由于我并没有很深入地去了解这两个算法,所以也只能草草讲一下大概的思路,有一些具体的优化策略和实现方法都没有提及,比如,如何改进 one-hot 这种很耗内存的表示方法,如何减少网络参数等,这些内容也是算法的精髓。不过,如果已经知道算法的总体战略思想,对于这些具体的战术,多看几篇文章应该也不是什么问题。
废话到此为止~囧~
参考
- Word2Vec Tutorial - The Skip-Gram Model
- Word2Vec Tutorial Part 2 - Negative Sampling
- An Intuitive Understanding of Word Embeddings: From Count Vectors to Word2Vec
- Word2vec
word2vec概述的更多相关文章
- Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树
Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树 目录 Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树 0x00 摘要 0x01 背景概念 1.1 词向量基础 ...
- Alink漫谈(十七) :Word2Vec源码分析 之 迭代训练
Alink漫谈(十七) :Word2Vec源码分析 之 迭代训练 目录 Alink漫谈(十七) :Word2Vec源码分析 之 迭代训练 0x00 摘要 0x01 前文回顾 1.1 上文总体流程图 1 ...
- 【CS224n-2019学习笔记】Lecture 1: Introduction and Word Vectors
附上斯坦福cs224n-2019链接:https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/ 文章目录 1.课程简单介绍 1.1 本 ...
- [转]word2vec使用指导
word2vec是一个将单词转换成向量形式的工具.可以把对文本内容的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,来表示文本语义上的相似度. 一.理论概述 (主要来源于http://lic ...
- word2vec使用说明补充(google工具包)
[本文转自http://ir.dlut.edu.cn/NewsShow.aspx?ID=253,感谢原作者] word2vec是一个将单词转换成向量形式的工具.可以把对文本内容的处理简化为向量空间中的 ...
- word2vec使用说明
word2vec是一个将单词转换成向量形式的工具.可以把对文本内容的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,来表示文本语义上的相似度. 一.理论概述 (主要来源于http://lic ...
- 一步一步理解word2Vec
一.概述 关于word2vec,首先需要弄清楚它并不是一个模型或者DL算法,而是描述从自然语言到词向量转换的技术.词向量化的方法有很多种,最简单的是one-hot编码,但是one-hot会有维度灾难的 ...
- word2vec c代码使用说明
摘要: 1 分词 将文本语料进行分词,以空格,tab隔开都可以.生成分词后的语料 2 训练 对分词后的语料test.txt 进行训练得到模型文件vectors.bin /word2vec -train ...
- 基于spark和sparkstreaming的word2vec
概述 Word2vec是一款由谷歌发布开源的自然语言处理算法,其目的是把words转换成vectors,从而可以用数学的方法来分析words之间的关系.Spark其该算法进行了封装,并在mllib中实 ...
随机推荐
- Python OpenCV 图像处理初级使用
# -*- coding: utf-8 -*-"""Created on Thu Apr 25 08:11:32 2019 @author: jiangshan" ...
- IDEA 创建包和类及基本操作
创建包和类步骤如下: 1. 展开创建的工程,在源代码目录 src 上,鼠标右键,选择 new->package ,键入包名 com.itheima.demo ,点击确定. 2. 在创建好的包上, ...
- 小程序蓝牙BLE——自动连接设备(手环)
了解小程序蓝牙API: /** *蓝牙API: * 1.初始化蓝牙(判断蓝牙是否可用):openBluetoothAdapter * 2.获取蓝牙设备状态(蓝牙是否打开):getBluetoothAd ...
- C Programming Style 总结
对材料C Programming Style for Engineering Computation的总结. 原文如下: C Programming Style for Engineering Com ...
- CodeForces Round #553 Div2
A. Maxim and Biology 代码: #include <bits/stdc++.h> using namespace std; int N; string s; int mi ...
- Python如何将整数转化成二进制字符串
Python 如何将整数转化成二进制字符串 1.你可以自己写函数采用 %2 的方式来算. >>> binary = lambda n: '' if n==0 else binary( ...
- CodeForces 1151C Problem for Nazar
题目链接:http://codeforces.com/problemset/problem/1151/C 题目大意: 有一个只存奇数的集合A = {1, 3, 5……2*n - 1,……},和只存偶数 ...
- mysqldump 导出
导出单张表数据:mysqldump -h127.0.0.1 -uroot -p database_name table_name > user_action.sql
- nginx(二)nginx的安装
下载 nginx官网下载地址 把源码解压缩之后,在终端里运行如下命令: ./configure make make install 默认情况下,Nginx 会被安装在 /usr/local/nginx ...
- iOS Button添加阴影 和 圆角
用iamgeview 加手势代替 self.headimageview = [[UIImageView alloc] initWithFrame:CGRectMake(IPHONEWIDTH(13), ...