DEX: Deep EXpectation of apparent age from a single image 论文阅读
来自:IMDB-WIKI - 500k+ face images with age and gender labels https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/
该论文提出了Deep EXpectation(DEX)的表面年龄估计,该方法在2015年获得了ChaLearn LAP表面年龄估计的第一名。
作者提出了将年龄的回归问题转化为分类问题,这样可以用深度学习的cnn方法来训练,训练方法是用ImageNet训练好的VGG-16网络进行初始化,然后用IMDB-WIKI数据集进行finetune,最后再用LAP数据集再次进行finetune。
一、具体实现过程如下:
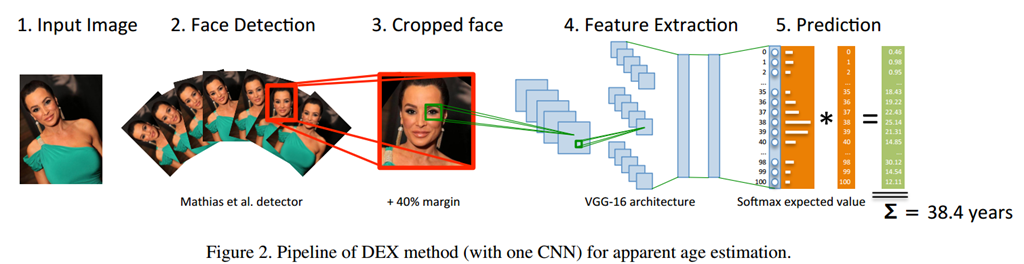
1、输入包含人物的图像;
2、对图片进行人脸检测,对于每张图片从-60°到+60°,以5°为步进进行旋转,另外也对图片旋转至-90°、90°、180°进行人脸检测;
3、将检测到的人脸区域上下左右向外扩展40%,将扩展后的区域裁切出来,最终图片尺寸压缩为256x256;
4、将所有裁切好的以及标注好的数据集放入VGG-16网络结构进行训练;
5、最终输出为101个类,即0~100岁,softmax输出,输出为每个年龄的概率,概率越大表示为这个年龄的可能性越大。
二、数据集
1、IMDB上获得461,871张,WIKI上获得62,359张,共524,230张,最后为了去除各年龄数据的不均衡,最终得到260,282张图片用于训练;
2、LAP数据集有4699张人脸图片,该数据集划分为三个部分,2476张用于训练,1136张用于验证,1087张用于测试。LAP数据集可http://chalearnlap.cvc.uab.es/dataset/18/description/下载。
三、评估方法
1、MAE(The standard mean absolute error):平均绝对误差;
2、ε-error:每张图片的检测错误率,定义如下:
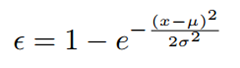
end
DEX: Deep EXpectation of apparent age from a single image 论文阅读的更多相关文章
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 【医学图像】3D Deep Leaky Noisy-or Network 论文阅读(转)
文章来源:https://blog.csdn.net/u013058162/article/details/80470426 3D Deep Leaky Noisy-or Network 论文阅读 原 ...
- 论文阅读:Face Recognition: From Traditional to Deep Learning Methods 《人脸识别综述:从传统方法到深度学习》
论文阅读:Face Recognition: From Traditional to Deep Learning Methods <人脸识别综述:从传统方法到深度学习> 一.引 ...
- 【论文阅读】Deep Mutual Learning
文章:Deep Mutual Learning 出自CVPR2017(18年最佳学生论文) 文章链接:https://arxiv.org/abs/1706.00384 代码链接:https://git ...
- [论文阅读笔记] Structural Deep Network Embedding
[论文阅读笔记] Structural Deep Network Embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 现有的表示学习方法大多采用浅层模型,这可能不能 ...
- 《3-D Deep Learning Approach for Remote Sensing Image Classification》论文笔记
论文题目<3-D Deep Learning Approach for Remote Sensing Image Classification> 论文作者:Amina Ben Hamida ...
- 论文阅读(Weilin Huang——【AAAI2016】Reading Scene Text in Deep Convolutional Sequences)
Weilin Huang--[AAAI2016]Reading Scene Text in Deep Convolutional Sequences 目录 作者和相关链接 方法概括 创新点和贡献 方法 ...
- Deep Learning 23:dropout理解_之读论文“Improving neural networks by preventing co-adaptation of feature detectors”
理论知识:Deep learning:四十一(Dropout简单理解).深度学习(二十二)Dropout浅层理解与实现.“Improving neural networks by preventing ...
随机推荐
- 安装mavlink遇到的问题(future找不到)
从官网下载mavlink(git clone https://github.com/mavlink/mavlink.git) 然后进入mavlink 目录执行 git submodule update ...
- python 函数返回值(总结)
关键字:return 没有返回值的叫过程 def test1(): msg="我是一个过程" print(msg) 有return的叫函数 def test02(): msg=&q ...
- 20165214 2018-2019-2 《网络对抗技术》Exp5 MSF基础应用 Week8
<网络对抗技术>Exp5 MSF基础应用 Week8 一.实验目标与内容 1.实践内容(3.5分) 本实践目标是掌握metasploit的基本应用方式,重点常用的三种攻击方式的思路.具体我 ...
- PyQt5 -pycharm 环境搭建
1.安装PyQt5 在CMD窗口执行命令: pip3 install PyQt5 安装 pyqt_toools pip3 install PyQt5-tools 2.配置PyCharm 1)打开PyC ...
- java第七周----json
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式.它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于 ...
- Labview笔记-创建自定义控件
labview中的控件种类很多,但是样式或者外观有时不能满足我们的需求.如何制作一个好看酷酷的自定义控件呢? 以开关为例,我们先添加一个labview中自带的确定开关控件 之后右键该控件--高级--自 ...
- fabric一些资料网站,长期更新
nodejs的入门教程 http://nqdeng.github.io/7-days-nodejs/#1.2 http://blog.fens.me/series-nodejs/ fabric的知识博 ...
- wxPython制作跑monkey工具(python3)-带显示设备列表界面
一. wxPython制作跑monkey工具(python3)-带显示设备列表界面 源代码 Run Monkey.py #!/usr/bin/env python import wx import ...
- C#自定义事件模拟风吹草摇摆
这是一个自定义事件的例子.C#.WinForm.Visual Studio 2017.在HoverTreeForm中画一块草地,上面有许多草(模拟).HewenqiTianyi类模拟天气,会引发“风” ...
- ssh操作服务器
# -*- coding: utf-8 -*- """ Created on Wed Mar 20 10:15:16 2019 @author: Kuma 1. ssh连 ...