elasticsearch -- Logstash实现mysql同步数据到elasticsearch
配置
- 安装插件
由于这里是从mysql同步数据到elasticsearch,所以需要安装jdbc的入插件和elasticsearch的出插件:logstash-input-jdbc、logstash-output-elasticsearch
安装效果图如下所示:- 下载mysql连接库
由于logstash是ruby开发的,所以这里要下载mysql的连接库jar包,从官网下载,我这里下载的是:mysql-connector-java-5.1.46.jar
将下载好的mysql-connector-java-5.1.46.jar,放至/usr/local/logstash/config/目录下。- 修改配置文件
在config目录下,创建配置文件(logstash-mysql-es.conf):input {
jdbc {
# mysql相关jdbc配置
jdbc_connection_string => "jdbc:mysql://10.112.76.30:3306/jack_test?useUnicode=true&characterEncoding=utf-8&useSSL=false"
jdbc_user => "root"
jdbc_password => "123456" # jdbc连接mysql驱动的文件目录,可去官网下载:https://dev.mysql.com/downloads/connector/j/
jdbc_driver_library => "./config/mysql-connector-java-5.1.46.jar"
# the name of the driver class for mysql
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => true
jdbc_page_size => "50000" jdbc_default_timezone =>"Asia/Shanghai" # mysql文件, 也可以直接写SQL语句在此处,如下:
# statement => "select * from t_order where update_time >= :sql_last_value"
statement_filepath => "./config/jdbc.sql" # 这里类似crontab,可以定制定时操作,比如每分钟执行一次同步(分 时 天 月 年)
schedule => "* * * * *"
#type => "jdbc" # 是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
#record_last_run => true # 是否需要记录某个column 的值,如果record_last_run为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值.
use_column_value => true # 如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的. 一般是mysql主键
tracking_column => "update_time" tracking_column_type => "timestamp" last_run_metadata_path => "./logstash_capital_bill_last_id" # 是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => false #是否将 字段(column) 名称转小写
lowercase_column_names => false
}
} output {
elasticsearch {
hosts => "10.112.76.31:9200"
index => "mysql_order"
document_id => "%{id}"
template_overwrite => true
} # 这里输出调试,正式运行时可以注释掉
stdout {
codec => json_lines
}
}这里有几个注意点:
(1)jdbc_driver_library
mysql-connector-java-5.1.46.jar的存放目录,这个一定要配置正确,支持全路径和相对路径。如果配置不对,将会报“can ”错误。
(2)sql_last_value
标志目前logstash同步的位置信息(类似offset)。比如id、updatetime。logstash通过这个标志,可以判断目前同步到哪一条数据。
(3)statement、statement_filepath
statement:执行同步的sql语句,可以同步部分数据。
statement_filepath:存储执行同步的sql语句。不和statement同时使用。
(4)schedule
定时器,表示每隔多长时间同步一次数据。格式类似crontab。
(5)tracking_column、tracking_column_type
tracking_column:表示表中哪一列用于判断logstash同步的位置信息。与sql_last_value比较判断是否需要同步这条数据。
tracking_column_type:racking_column指定列的类型。支持两种类型:numeric(默认)、timestamp。注意:如果列是时间字段(比如updateTime),一定要指定这个类型为timestamp。我就踩了这个大坑。。。一直同步不成功!!!
(6)last_run_metadata_path
存储sql_last_value值的文件名称及位置。
(7)document_id
生成elasticsearch的文档值,尽量使用同步的数据中已有的唯一标识。比如同步订单数据,可以使用订单号。


启动
在根目录下,执行命令:
nohup bin/logstash -f config/logstash-mysql-es.conf > logs/logstash.out &效果图如下:
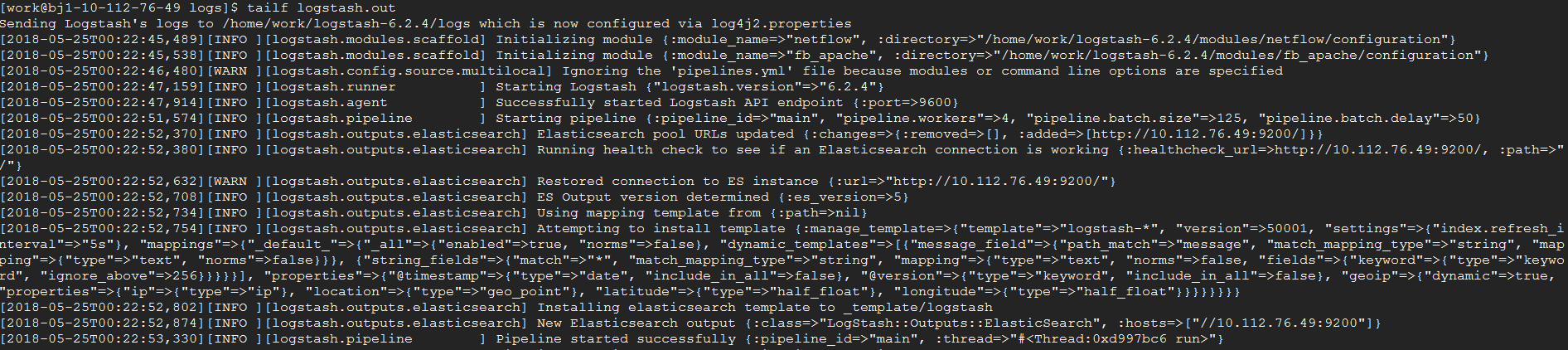
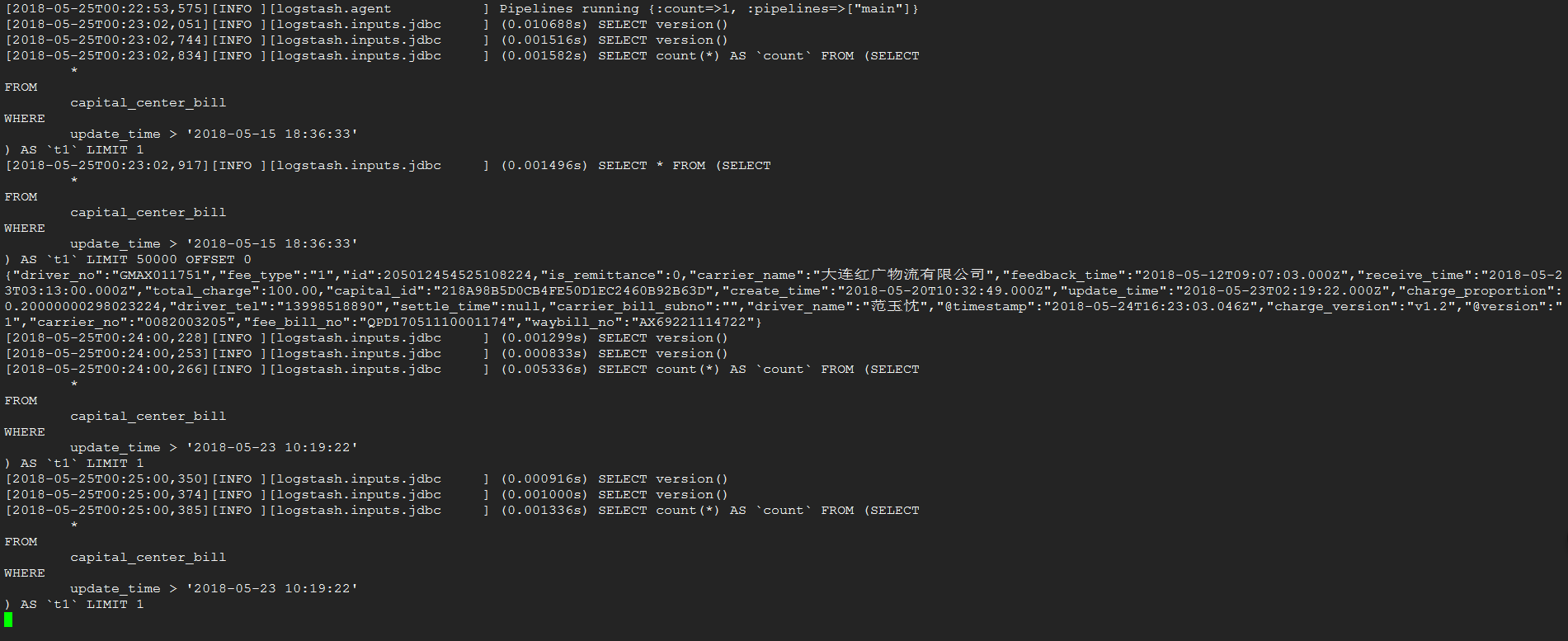
同步
完成了一条数据的同步
elasticsearch -- Logstash实现mysql同步数据到elasticsearch的更多相关文章
- 利用logstash从mysql同步数据到ElasticSearch
前面一篇已经把logstash和logstash-input-jdbc安装好了. 下面就说下具体怎么配置. 1.先在安装目录bin下面(一般都是在bin下面)新建两个文件jdbc.conf和jdbc. ...
- mysql 同步数据到 ElasticSearch 的方案
MySQL Binlog 要通过 MySQL binlog 将 MySQL 的数据同步给 ES, 我们只能使用 row 模式的 binlog.如果使用 statement 或者 mixed forma ...
- 使用ElasticSearch服务从MySQL同步数据实现搜索即时提示与全文搜索功能
最近用了几天时间为公司项目集成了全文搜索引擎,项目初步目标是用于搜索框的即时提示.数据需要从MySQL中同步过来,因为数据不小,因此需要考虑初次同步后进行持续的增量同步.这里用到的开源服务就是Elas ...
- 使用Logstash同步数据至Elasticsearch,Spring Boot中集成Elasticsearch实现搜索
安装logstash.同步数据至ElasticSearch 为什么使用logstash来同步,CSDN上有一篇文章简要的分析了以下几种同步工具的优缺点:https://blog.csdn.net/la ...
- 安装配置elasticsearch、安装elasticsearch-analysis-ik插件、mysql导入数据到elasticsearch、安装yii2-elasticsearch及使用
一.安装elasticsearch 获取elasticsearch的rpm:wget https://download.elastic.co/elasticsearch/release/org/ela ...
- 如何通过 Docker 部署 Logstash 同步 Mysql 数据库数据到 ElasticSearch
在开发过程中,我们经常会遇到对业务数据进行模糊搜索的需求,例如电商网站对于商品的搜索,以及内容网站对于内容的关键字检索等等.对于这些高级的搜索功能,显然数据库的 Like 是不合适的,通常我们采用 E ...
- ElasticSearch(1)---Mysql同步数据到ElSearch
ElasticSearch同步Mysql 先讲项目需求:对于资讯模块添加搜索功能 这个搜索功能我就是采用ElasticSearch实现的,功能刚实现完,所以写这篇博客做个记录,让自己在记录下整个步骤和 ...
- 关于MySQL导入数据到elasticsearch的小工具logstash
logstash核心配置文件pipelines.yml #注:此处的 - 必须顶格写必须!!! - pipeline.id: invitation #下面路径配置的是你同步数据是的字段映射关系 pat ...
- logstash采集与清洗数据到elasticsearch案例实战
原文地址:https://www.2cto.com/kf/201610/560348.html Logstash的使用 logstash支持把配置写入文件 xxx.conf,然后通过读取配置文件来采集 ...
随机推荐
- vue将网页中的特定部分转成pdf并下载(仅供个人学习记录)
先安装支持 将页面html转换成图片npm install --save html2canvas 将图片生成pdfnpm install jspdf --save 组件引用: import html2 ...
- JS中的一元操作符
表达式 一元操作符 优先级 结合性 运算顺序 表达式是什么? 就是JS 中的一个短语,解释器遇到这个短语以后会把对它进行计算,得到一个结果参与运算,我们把这种要参与到运算中的各种各样的短语称为表达式. ...
- DAY2:数据类型Python3.6
数字 1.int(整型) 2. long(长整型) 3.float(浮点型) 4.complex(复数) 布尔值 1.真或假 1或0表示 字符串 知识补充 字符串转二进制 mes = "北 ...
- Centos6.5 安装 RabbitMQ 3.7.11
RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python.Ruby..NET.Java.JMS.C.PHP.ActionScript.XMPP.STO ...
- 高精度加法——经典题 洛谷p1601
题目背景 无 题目描述 高精度加法,x相当于a+b problem,[b][color=red]不用考虑负数[/color][/b] 输入输出格式 输入格式: 分两行输入a,b<=10^500 ...
- python网络编程(图片传输)
发送端: from socket import * s=socket() s.connect(('127.0.0.1',8888)) f=open('mm.jpg','rb') while True: ...
- [C# 基础知识系列]专题二:委托的本质论 (转载)
引言: 上一个专题已经和大家分享了我理解的——C#中为什么需要委托,专题中简单介绍了下委托是什么以及委托简单的应用的,在这个专题中将对委托做进一步的介绍的,本专题主要对委本质和委托链进行讨论. 一.委 ...
- unity---背景循环滚动
方法一:两张图无缝拼接 float speed = 3; void Update() { transform.Translate(Vector3.right * Time.deltaTime * sp ...
- Spock - Document - 03 - Data Driven Testing
Data Driven Testing Peter Niederwieser, The Spock Framework TeamVersion 1.1 Oftentimes, it is useful ...
- Sails -初级学习配置
新建一个命名为sails的文件夹1.安装 npm -g install sails || cnpm -g install sails 注意:安装必须是全局安装 cnpm install sails - ...