hive -- 自定义函数和Transform
hive -- 自定义函数和Transform
UDF操作单行数据,
UDAF:聚合函数,接受多行数据,并产生一个输出数据行
UDTF:操作单个数据
使用udf方法:
第一种:
add jar xxx.jar
cteate temporary function 方法名;
注销一个jar方法:drop temporay function 方法名;
第二种:写一个脚本
vi cat hive_init
add jar /home/data/xxx.jar
create temporary fucntion 方法名 as '类的全限定名'
hive -i hive_init
第三种:
自定义UDF注册为hive的内置函数
自定义函数:(UDF)
数据:
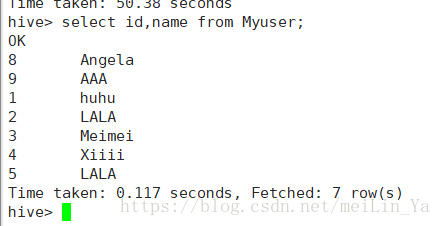
package UDF;
import java.util.HashMap;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
*
* @author huhu_k
*
*/
public class ToLowerCase extends UDF {
public static HashMap<String, String> provinceMap = new HashMap<>();
static {
provinceMap.put("136", "beijing");
provinceMap.put("137", "shanghai");
provinceMap.put("138", "shenzhen");
}
// 必须是public
public String evaluate(String field) {
String lowerCase = field.toLowerCase();
return lowerCase;
}
// 必须是public
public String evaluate(int field) {
String pn = String.valueOf(field);
return provinceMap.get(pn.substring(0, 3)) == null ? "huoxing" : provinceMap.get(pn.substring(0, 3));
}
}1.将name大写变为小写:
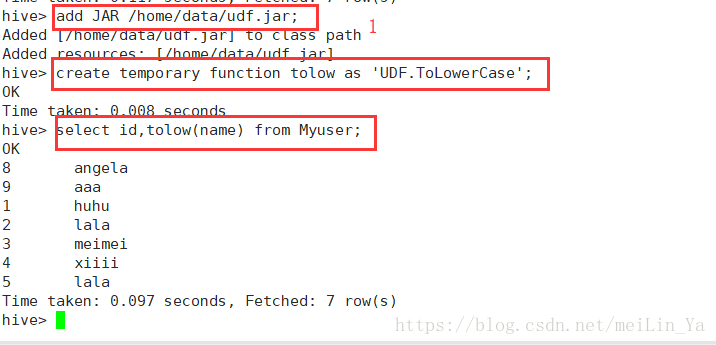
2.数据:

通过手机号获取手机地址:
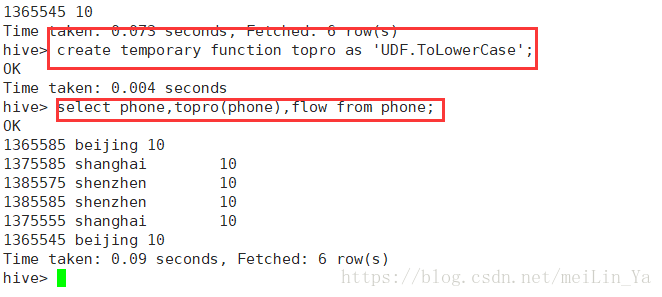
当你在一个类中再次写了方法时,再次导入jar时,要先推出hive,然后在进入hive,然后进行add JAR XXXXX;
3.数据:
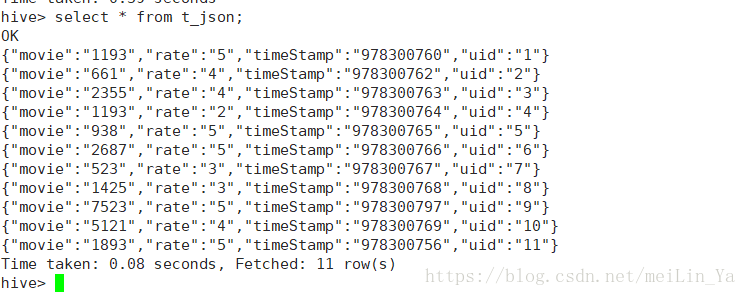
使用json数据
package UDF;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.codehaus.jackson.map.ObjectMapper;
public class JsonParser extends UDF {
public String evaluate(String json) {
ObjectMapper objectMapper = new ObjectMapper();
try {
Moive readValue = objectMapper.readValue(json, Moive.class);
return readValue.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
package UDF;
public class Moive {
private String movie;
private String rate;
private String timeStamp;
private String uid;
public String getMovie() {
return movie;
}
public void setMovie(String movie) {
this.movie = movie;
}
public String getRate() {
return rate;
}
public void setRate(String rate) {
this.rate = rate;
}
public String getTimeStamp() {
return timeStamp;
}
public void setTimeStamp(String timeStamp) {
this.timeStamp = timeStamp;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
@Override
public String toString() {
return movie + "\t" + rate + "\t" + timeStamp + "\t" + uid;
}
}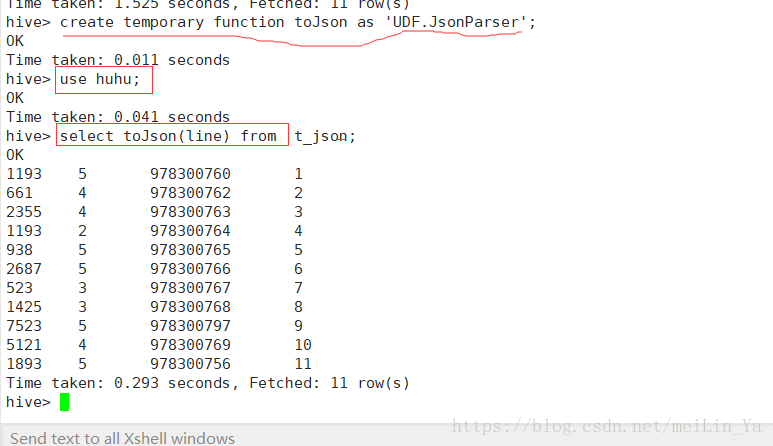
然后将查询出来的数据插入到一张表中
1.使用hive中的自带函数可以解析简单的json数据格式
create table t_json2 as select get_json_object(line,'$.movie')as movie,get_json_object(line,'$.rate')as rate,get_json_object(line,'$.timeStamp')as timeStamps,get_json_object(line,'$.uid')as uid from t_json;
2.使用自定义函数
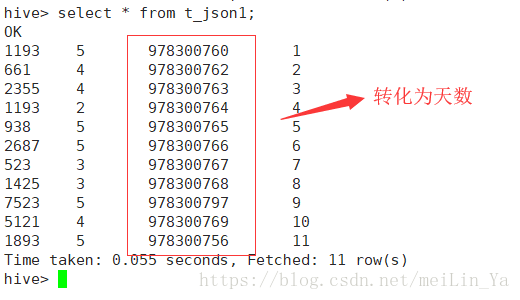
create table t_json1 as select split(toJson(line),'\t')[0]as movieid,split(toJson(line),'\t')[1]as,split(toJson(line),'\t')[2]as timestring,split(toJson(line),'\t')[3]as uid from t_json;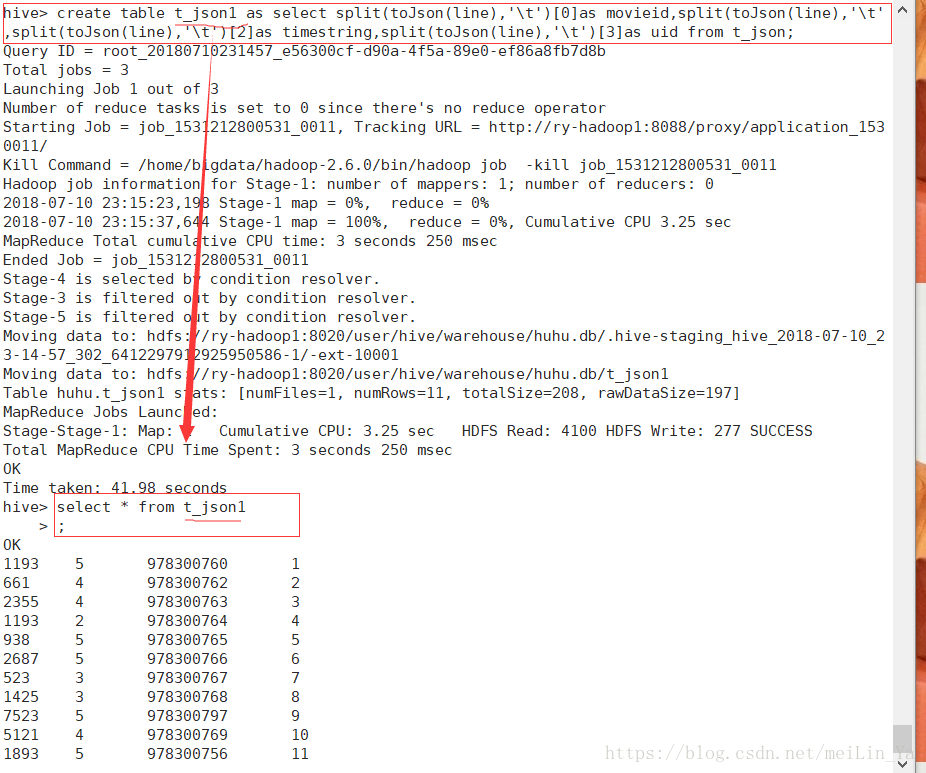
ok!!!
Transform:
Hive的Transform关键字提供了在SQL中调用自写脚本的功能
例子:
先编辑一个python脚本文件
#!/bin/python
import sys
import datetime
for line in sys.stdin:
line = line.strip()
movieid, rating, unixtime,userid = line.split('\t')
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([movieid, rating, str(weekday),userid])将文件加入hive的路径classpath
add file /home/data/weekday_mapper.py;创建一个表:
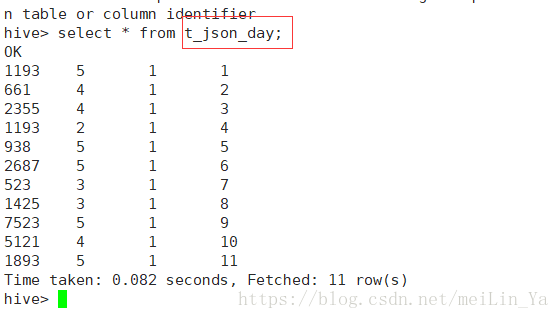
create table t_json_day as select transform (movieid,rate,timestring,uid) using 'python weekday_mapper.py' as (movieid,rate,weekday,uid) from t_json1;
hive -- 自定义函数和Transform的更多相关文章
- Hive自定义函数的学习笔记(1)
前言: hive本身提供了丰富的函数集, 有普通函数(求平方sqrt), 聚合函数(求和sum), 以及表生成函数(explode, json_tuple)等等. 但不是所有的业务需求都能涉及和覆盖到 ...
- hive自定义函数(UDF)
首先什么是UDF,UDF的全称为user-defined function,用户定义函数,为什么有它的存在呢?有的时候 你要写的查询无法轻松地使用Hive提供的内置函数来表示,通过写UDF,Hive就 ...
- hive自定义函数学习
1介绍 Hive自定义函数包括三种UDF.UDAF.UDTF UDF(User-Defined-Function) 一进一出 UDAF(User- Defined Aggregation Funcat ...
- hive自定义函数UDF UDTF UDAF
Hive 自定义函数 UDF UDTF UDAF 1.UDF:用户定义(普通)函数,只对单行数值产生作用: UDF只能实现一进一出的操作. 定义udf 计算两个数最小值 public class Mi ...
- Hive 自定义函数(转)
Hive是一种构建在Hadoop上的数据仓库,Hive把SQL查询转换为一系列在Hadoop集群中运行的MapReduce作业,是MapReduce更高层次的抽象,不用编写具体的MapReduce方法 ...
- Hive 自定义函数
hive 支持自定义UDF,UDTF,UDAF函数 以自定义UDF为例: 使用一个名为evaluate的方法 package com.hive.custom; import org.apache.ha ...
- hive自定义函数——hive streaming
Hadoop Streaming提供了一个便于进行MapReduce编程的工具包,使用它可以基于一些可执行命令.脚本语言或其他编程语言来实现Mapper和 Reducer,Streaming方式是基于 ...
- Hive 自定义函数 UDF UDAF UDTF
1.UDF:用户定义(普通)函数,只对单行数值产生作用: 继承UDF类,添加方法 evaluate() /** * @function 自定义UDF统计最小值 * @author John * */ ...
- Hadoop之Hive自定义函数的陷阱
A left join B, 这个B会连到A. 如<A1,B>, <A2,B>,在处理第一条记录的时候将B.clear(),则第二条记录的B是[]空的这是自定义UDF函数必须注 ...
随机推荐
- 复制ASP.NET的ASHX、aspx文件的注意事项
在复制ashx文件后,需要在夫指出的文件上右键——打开方式——点击“”源代码文本编辑器“” ashx在你新建的时候它已经指定了执行的命名空间你后面再去修改文件名或者里边的类名它的指定也不会变 这是因 ...
- datagridview 查询数据库数据
private void btnsearch_Click(object sender, EventArgs e) { if (txtSearch.Text != "") { thi ...
- 随手记一 2018/04/23 session和cookie的区别
1.cookie存放在客户端的浏览器上,session存放在服务器上 2.cookie安全性不高,可以通过分析存放在本地的cookie并且进行cookie欺骗 3.session会在一定时间内保存在服 ...
- 移动端js调试工具:eruda
通常写前端页面都在Chrome浏览器的开发模式下进行调试,但是写放在移动端的H5页面时,有时候会遇到在Chrome上调试没有问题,但是在手机的浏览器上有问题的情况:或者有些功能只能在特定的容器中才能其 ...
- 获取某个元素第一次出现在数组(json数组)的索引
function firstIndex(arr, text) { // 若元素不存在在数组中返回-1 let firstVal = -1; for (let i = 0; i < arr.len ...
- Tomcat类加载
一.为什么会有类加载 1.在类加载阶段,虚拟机需要完成以下3件事情 1)通过一个全限类定名来获取此类的二进制字节流 2) 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构 3)在内存中生成 ...
- Java基础学习-计算机存储单元和数据类型概述
变量是内存中的小容器,用来存储数据.那么计算机内存是怎么存储数据的呢?无论是内存还是硬盘,计算机存储设备的最小信息单元叫“位(bit)”,我们又称之为“比特位”,通常用小写字母b表示.而计算机最小的存 ...
- iso移动端input的bug解决(vue)
iso中input很奇怪,点击空白地方,键盘也不会消失,影响页面中其他功能 解决办法: 点击的元素不是input或者textarea,那么就让上一个获得焦点的输入框失去焦点. 涉及的代码: <i ...
- 用JS更好的实现响应式布局
响应式布局更加高效的方法: 代码实现 <script> $(function() { (function(){ var $html = $('html'); var $window = $ ...
- Mac连接非22端口linux服务器
Mac连接非22端口linux服务器 原文链接:https://www.cnblogs.com/blog5277/p/9507080.html 原文作者:博客园--曲高终和寡 1:ssh连接 打开终端 ...