Kubernetes基本功能
说明
目前kubernetes的资料介绍很多也很深刻,本文只是做一个针对自己学习k8s过程的介绍,仅仅是学习笔记的记录。
一、基本使用
1. 命令行
- 集群信息
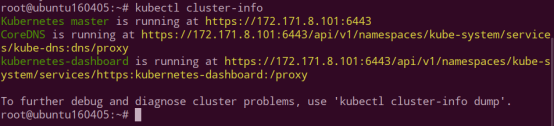
- Namespace 信息

- Controller 信息
Deployment 控制器

Replicaset 控制器

Statefulset 控制器

Daemonset 控制器

Job 控制器

- Service

- Pod

- 参数
-o wide 查看更多信息,Pod 可以查看到 ip 地址,node 节点。Service 可以查看到选择器,控制器可以看到镜像,选择器等。

--all-namespaces 查看所有 namespace 下的资源
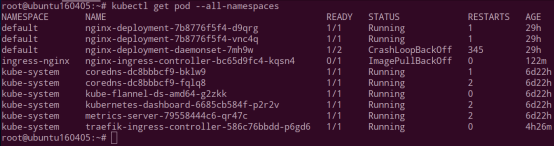
K8s 出错排查三大步:
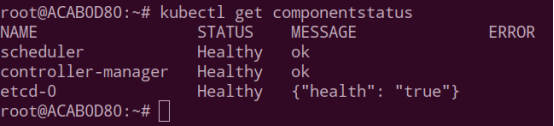
kubectl get componentstatus
查看 scheduler/controller-manager/etcd 等组件 Healthy
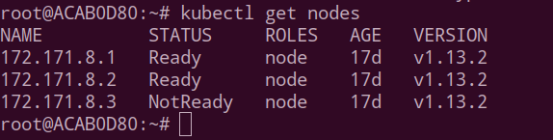
Kubectl get nodes
查看节点的状态,判断是不是有出错的节点
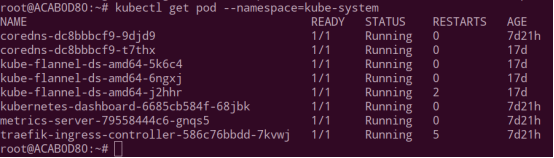
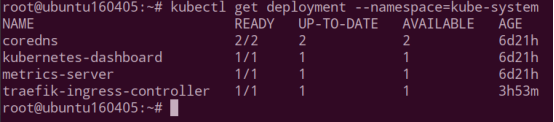
Kubectl get pod --namespace=kube-system
查看系统命名空间 kube-system 里组件的状态
2.Dashboard
- 集群信息
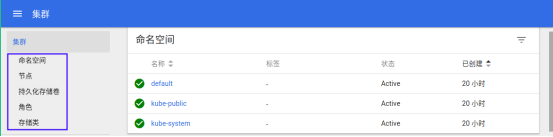
Namespace 所有信息
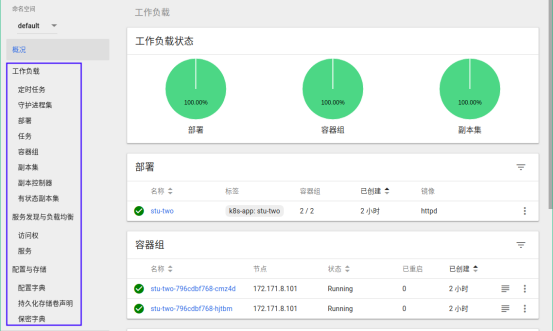
应用信息
容器信息
副本信息
服务信息
二、架构分析
1. 资源架构
Kubernetes 资源架构图:
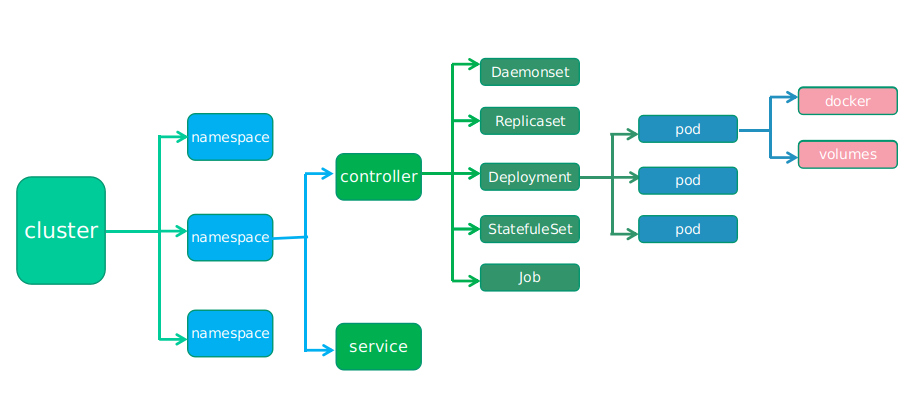
资源分析
Cluster
Cluster 是计算、存储和网络资源的集合,Kubernetes 利用这些资源运行各种基于容器的应用。
Master
Master 是 Cluster 的大脑,它的主要职责是调度,即决定将应用放在哪里运行。Master 运行 Linux 操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个 Master。
Node
Node 的职责是运行容器应用。Node 由 Master 管理,Node 负责监控并汇报容器的状态,并根据 Master 的要求管理容器的生命周期。Node 运行在 Linux 操作系统,可以是物理机或者是虚拟机。
Namespace
Namespace 可以将一个物理的 Cluster 逻辑上划分成多个虚拟 Cluster,每个 Cluster 就是一个 Namespace。不同 Namespace 里的资源是完全隔离的。
Controller
Kubernetes 通常不会直接创建 Pod,而是通过 Controller 来管理 Pod 的。Controller 中定义了 Pod 的部署特性,比如有几个副本,在什么样的 Node 上运行等。为了满足不同的业务场景,Kubernetes 提供了多种 Controller,包括 Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job 等。
1.Deployment 是最常用的 Controller,Deployment 可以管理 Pod 的多个副本,并确保 Pod 按照期望的状态运行。
2.ReplicaSet 实现了 Pod 的多副本管理。使用 Deployment 时会自动创建 ReplicaSet,也就是说 Deployment 是通过 ReplicaSet 来管理 Pod 的多个副本,通常不需要直接使用 ReplicaSet。
3.DaemonSet 用于每个 Node 最多只运行一个 Pod 副本的场景。DaemonSet 通常用于运行守护进程的服务。
4.StatefuleSet 能够保证 Pod 的每个副本在整个生命周期中名称是不变的。而其他 Controller 不提供这个功能,当某个 Pod 发生故障需要删除并重新启动时,Pod 的名称会发生变化。同时 StatefuleSet 会保证副本按照固定的顺序启动、更新或者删除。
5.Job 用于运行结束就删除的应用。而其他 Controller 中的 Pod 通常是长期持续运行。
Service
Kubernetes Service 定义了外界访问一组特定 Pod 的方式。Service 有自己的 IP 和端口,为 Pod 的访问提供了负载均衡。
Pod
Pod 是 Kubernetes 的最小工作单元。每个 Pod 包含一个或多个容器。Kubernetes 管理的也是 Pod 而不是直接管理容器。Pod 中的容器会作为一个整体被 Master 调度到一个 Node 上运行。Pod 的设计理念是支持多个容器在一个 Pod 中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。
Pod 有两种使用方式:
(1) 运行单一容器。
one-container-per-Pod 是 Kubernetes 最常见的模型,这种情况下,只是将单个容器简单封装成 Pod,即便是只有一个容器。
(2) 运行多个容器。
这些容器联系必须非常紧密,而且需要直接共享资源。
Volume
存储卷是 Kubernetes 集群中的存储解决方案,主要用于两个方面:1. 当 pod 中容器故障重建之后,之前写入容器的文件丢失;2. 同一个 Pod 中的多个容器之间共享文件。Docker 有存储卷的概念卷,但 Docker 中存储卷只是磁盘的或另一个容器中的目录,并没有对其生命周期进行管理。Kubernetes 的存储卷有自己的生命周期,它的生命周期与使用的它 Pod 生命周期一致。因此,相比于在 Pod 中运行的容器来说,存储卷的存在时间会比的其中的任何容器都长,并且在容器重新启动时会保留数据。当然,当 Pod 停止存在时,存储卷也将不再存在。
Kubernetes 支持非常多的存储卷类型,特别的,支持多种公有云平台的存储,包括 AWS,Google 和 Azure 云;支持多种分布式存储包括 GlusterFS 和 Ceph;也支持较容易使用的主机本地目录 hostPath 和 NFS。Kubernetes 还支持使用 Persistent Volume Claim 即 PVC 这种逻辑存储,使用这种存储,使得存储的使用者可以忽略后台的实际存储技术(例如 AWS,Google 或 GlusterFS 和 Ceph),而将有关存储实际技术的配置交给存储管理员通过 Persistent Volume 来配置。
用户帐户(User Account)和服务帐户(Service Account)
用户帐户为人提供账户标识,而服务账户为计算机进程和 Kubernetes 集群中运行的 Pod 提供账户标识。用户帐户和服务帐户的一个区别是作用范围;用户帐户对应的是人的身份,人的身份与服务的 namespace 无关,所以用户账户是跨 namespace 的;而服务帐户对应的是一个运行中程序的身份,与特定 namespace 是相关的。
RBAC 访问授权
Kubernetes 使用基于角色的访问控制(Role-based Access Control,RBAC)的授权模式。相对于基于属性的访问控制(Attribute-based Access Control,ABAC),RBAC 主要是引入了角色(Role)和角色绑定(RoleBinding)的抽象概念。在 ABAC 中,Kubernetes 集群中的访问策略只能跟用户直接关联;而在 RBAC 中,访问策略可以跟某个角色关联,具体的用户在跟一个或多个角色相关联。
2. 系统架构
Kubernetes 系统架构图
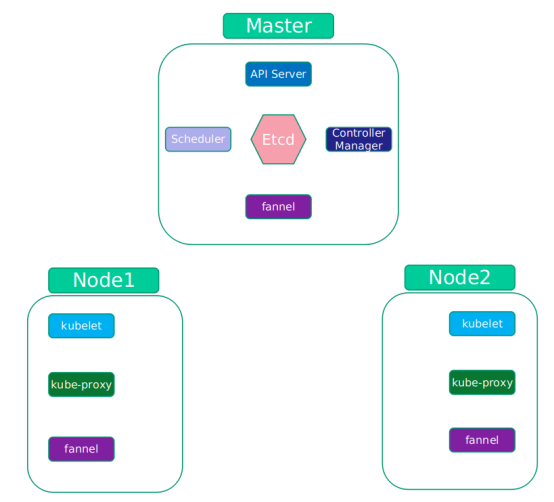
在 Master 节点上运行的服务有:
API Server:提供 Restful api。
apiserver 提供集群管理的 REST API 接口,包括认证授权、数据校验以及集群状态变更等。
只有 API Server 才直接操作 etcd,其他模块通过 API Server 查询或修改数据。apiserver 是提供其他模块之间的数据交互和通信的枢纽。Scheduler:调度服务,决定将容器创建在哪个 Node 上。
scheduler 负责分配调度 Pod 到集群内的 node 节点,监听 apiserver。查询还未分配 Node 的 Pod,根据调度策略为这些 Pod 分配节点。Controller Manager:管理系统中各种资源,保证资源处于预期的状态。
Controller-manager 由一系列的控制器组成,它通过 apiserver 监控整个集群的状态,并确保集群处于预期的工作状态。Etcd: 保存系统的配置信息和各种资源的状态信息。
etcd 是一个高可用的分布式键值 (key-value) 数据库。etcd 内部采用 raft 协议作为一致性算法。etcd 基于 Go 语言实现,用于持久化存储集群中所有的资源对象,如 Node、Service、Pod、RC、Namespace 等;API Server 提供了操作 etcd 的封装接口 API,这些 API 基本上都是集群中资源对象的增删改查及监听资源变化的接口。Pod 网络:提供资源之间互相访问的网络。可以是 macvlan、flannel、weave、calico 等其中的一种。
Node 节点的服务:
kubelet:接收 Master 节点发来的创建请求信息,并向 Master 报告运行状态。
负责 Node 节点上 Pod 的创建、修改、监控、删除等全生命周期的管理定时上报本 Node 的状态信息给 API Server。kube-proxy:访问控制。
Proxy 是为了解决外部网络能够访问跨机器集群中容器提供的应用服务而设计的,运行在每个 Node 上。Proxy 提供 TCP/UDP sockets 的 proxy,每创建一种 Service,Proxy 主要从 etcd 获取 Services 和 Endpoints 的配置信息,然后根据配置信息在 Node 节点上上启动一个 Proxy 的进程并监听相应的服务端口,当外部请求发生时,Proxy 会根据 Load Balancer 将请求分发到后端正确的容器处理。Pod 网络:提供资源之间互相访问的网络。可以是 macvlan、flannel、weave、calico 等其中的一种。
创建资源工作流程:
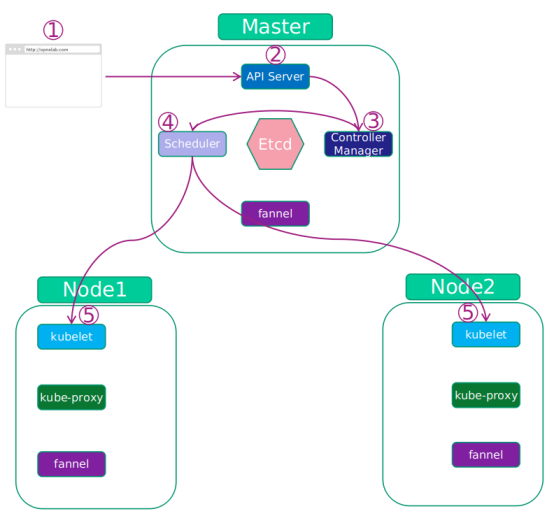
各组件配合流程:
- 客户端发出创建 Deployment 请求
- API Server 接收到客户端的调用
- API Server 通知 Controller Manager 创建一个 deployment 资源。
- Scheduler 执行调度任务,将两个副本 Pod 分发到 node1 和 node2。
- node1 和 node2 上的 kubelet 在各自的节点上创建并运行 Pod。
除了以上核心组件之外,Kubernetes 系统还有一些推荐的组件:
- kube-dns 负责为整个集群提供 DNS 服务。在 1.13 中,CoreDNS 现在将 kube-dns 替换为 Kubernetes 的默认 DNS 服务器。
- Ingress Controller 为服务提供外网入口
- Heapster 提供资源监控
- Dashboard 提供 GUI
- Federation 提供跨可用区的集群
- Fluentd-elasticsearch 提供集群日志采集、存储与查询
三、集群创建
详见 Kubernetes 部署博客
四、部署应用
Kubernetes 部署应用的方式有多种,如:命令行,dashboard,客户端等。以命令行的形式为例子来说明应用的部署。命令行有两种方式能够创建资源,一是使用 kubectl 命令,二是使用 yaml 文件。两种创建创建方式的特点对比:
基于命令的方式:
- 简单直观快捷,上手快。
- 适合临时测试或实验。
基于 yaml 配置文件的方式:
1.所见即所得,配置文件描述的即应用最终要达到的状态。
2.配置文件提供了创建资源的模板,能够重复部署。
3.可以像管理代码一样管理部署。
4.适合正式的、跨环境的、规模化部署。
5.要求熟悉 yaml 配置文件的语法。
1.Kubectl 命令
Kubectl 使用规则:
kubectl run NAME --image=image [--env="key=value"] [--port=port] [--replicas=replicas] [--dry-run=bool] [--overrides=inline-json] [--command] -- [COMMAND] [args...] [options]
最简单的创建应用的命令只需要指定应用的名字和使用的镜像即可,默认创建 deployment 的资源
kubectl run NAME --image=image
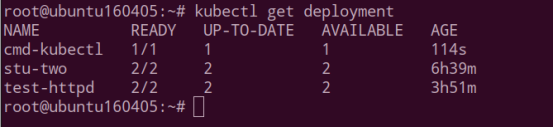
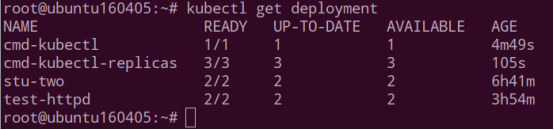
Kubectl run cmd-kubectl --image=nginx

查看创建资源
指定创建的应用的副本为 3 个,镜像使用 nginx
kubectl run cmd-kubectl-replicas --image=nginx --replicas=3

查看创建资源,副本为 3 个
2.YAML 文件部署
YAML 是专门用来写配置文件的语言,非常简洁和强大,使用比 json 更方便。它实质上是一种通用的数据串行化格式。
YAML 语法规则:
- 大小写敏感
- 使用缩进表示层级关系
- 缩进时不允许使用 Table 键,只允许使用空格
- 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
- ”#” 表示注释,从这个字符一直到行尾,都会被解析器忽略
在 Kubernetes 中,只需要知道两种结构类型:Lists 和 Maps。
Map 顾名思义指的是字典,即一个 Key:Value 的键值对信息
apiVersion: v1
kind: Pod
即 {apiVersion:v1,kind:Pod}
List 即列表,可以理解为是数组
args
-beijing
-shanghai
-shenzhen
-guangzhou
即 args:[‘beijing’,’shanghai’,’shenzhen’,’guangzhou’]
经典 Yaml 模板文件:
Kubernetes 的官方文档中并没有对 apiVersion 的详细解释,而且因为 K8S 本身版本也在快速迭代,有些资源在低版本还在 beta 阶段,到了高版本就变成了 stable。
Alpha(第一版)
- 该软件可能包含错误。启用一个功能可能会导致 bug
- 随时可能会丢弃对该功能的支持,恕不另行通知
Beta(测试版)
- 软件经过很好的测试。启用功能被认为是安全的。
- 默认情况下功能是开启的
- 细节可能会改变,但功能在后续版本不会被删除
Stable(稳定版)
- 该版本名称命名方式:vX 这里 X 是一个整数
- 稳定版本、放心使用
- 将出现在后续发布的软件版本中
v1
Kubernetes API 的稳定版本,包含很多核心对象:pod、service 等
apps/v1beta2
在 kubernetes1.8 版本中,新增加了 apps/v1beta2 的概念,apps/v1beta1 同理
DaemonSet,Deployment,ReplicaSet 和 StatefulSet 的当时版本迁入 apps/v1beta2,兼容原有的 extensions/v1beta1
apps/v1
apps/v1 代表:包含一些通用的应用层的 api 组合,如:Deployments, RollingUpdates, and ReplicaSets
batch/v1
代表 job 相关的 api 组合
在 kubernetes1.8 版本中,新增了 batch/v1beta1,后 CronJob 已经迁移到了 batch/v1beta1,然后再迁入 batch/v1
使用 yaml 文件创建应用
Kubectl create -f nginx.yaml

3. 五种 Controller 使用
1.Deployment
Deployment 中文意思为部署、调度。通过在 Deployment yaml 文件中描述所期望的集群状态,Deployment 会将现在的集群状态在一个可控的速度下逐步更新成所期望的集群状态。即定义了一个期望的场景,Pod 的副本数量在任意时刻都符合某个预期值。Deployment 将 Pod 和 ReplicaSet 的实际状态改变到目标状态,减少了系统管理员在传统 IT 环境中需要完成的许多手工运维工作(如主机监控、应用监控和故障恢复等)。
ReplicationController 是早期 Kubernetes 版本中主要使用的一项技术,简称 RC。在较新版本中,RC 的功能已经逐渐被功能更强大的 ReplicaSet 和 Deployment 的组合所替代。
Deployment 功能:
- 确保 Pod 数量
它会确保 Kubernetes 中有指定数量的 Pod 在运行。如果少于指定数量的 Pod,deployment 会创建新的,反之则会删除掉多余的以保证 Pod 数量不变。 - 确保 Pod 健康
当 Pod 不健康,运行出错或者无法提供服务时,deployment 会销毁不健康的 Pod,重新创建新的。 弹性伸缩
在业务高峰或者低峰期的时候,可以通过 deployment 动态的调整 Pod 的数量来提高资源的利用率。同时,配置相应的监控功能(Hroizontal Pod Autoscaler),会定时自动从监控平台获取 deployment 关联 Pod 的整体资源使用情况,做到自动伸缩。
- 滚动升级
滚动升级为一种平滑的升级方式,通过逐步替换的策略,保证整体系统的稳定,在初始化升级的时候就可以及时发现和解决问题,避免问题不断扩大。
kubectl rolling-update my-nginx -f nginx-rc.yaml - 事件和状态查看
可以查看 Deployment 的升级详细进度和状态。 - 版本记录
每一次对 Deployment 的操作,都能保存下来,给予后续可能的回滚使用。 回滚
当升级 Pod 镜像或者相关参数的时候发现问题,可以使用回滚操作回滚到上一个稳定的版本或者指定的版本。
1.创建 deploment 时增加加 --recorder,记录版本


2.第二个版本


3.第三个版本
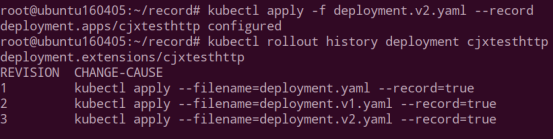
查看当前 http 的版本,为第三个 yaml 文件定义的 1.4.18

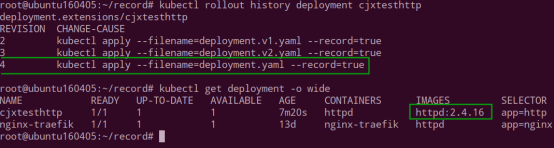
4.回滚到第一个版本

查看当前 http 的版本为 2.4.16,是第一个版本。回滚成功
- 暂停和启动
对于每一次升级,都能够随时暂停和启动。 - 多种升级方案
(1)Recreate:删除所有已存在的 Pod, 重新创建新的;
(2)RollingUpdate:滚动升级,逐步替换的策略,同时滚动升级时,支持更多的附加参数,例如设置最大不可用 Pod 数量,最小升级间隔时间等等;
2.ReplicaSet
ReplicaSet 代替用户创建指定数量的 Pod 副本数量,确保 Pod 副本数量符合预期状态,并且支持滚动式自动扩容和缩容功能。ReplicaSets 能够确保在某个时间点上,一定数量的 Pod 在运行。ReplicaSet 主要三个组件组成:
(1) 用户期望的 Pod 副本数量
(2) 标签选择器,判断哪个 Pod 归自己管理
(3) 当现存的 Pod 数量不足,会根据 Pod 资源模板进行新建
从操作规范上来讲 RelicaSet 不是直接使用的控制器,而是使用 Deployment。Deployment 是 ReplicaSets 更高一层的抽象,用于更新 Pods 以及其他一些特性。ReplicaSet 主要作用是协调 Deployment 创建、删除和更新 Pods。
查看 deployment 和 replicaset,可以看到 replicaset 的名字是 deployment 名字之后的延伸。
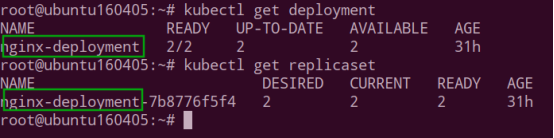
虽然 ReplicaSets 可以独立使用,建议使用 Deployment 而不是直接使用 ReplicaSets。
3.StatefulSet
StatefulSet 是 Kubernetes 提供的管理有状态应用的负载管理控制器 API。在 Pods 管理的基础上,保证 Pods 的顺序和一致性。StatefulSet 创建的 Pods 在生命周期中会保持持久的标记(例如 Pod Name,动态创建和销毁的过程中 Pod Name 也是不断变化)。
现实中很多服务是有状态的,如 MySQL 集群、kafka 集群、ZooKeeper 集群等,这些应用集群有以下特点:
(1) 每个节点都有固定的身份 ID,通过这个 ID,集群中的成员可以相互发现和通信;
(2) 集群的规模是相对固定的,且不能随意变动;
(3) 集群里每个节点都是有状态的,通常会持久化数据到永久存储中;
(4) 如果磁盘损坏导致集群里某个节点无法正常运行,则集群功能会部分受损;
StatefulSet 是 Deployment/RC 的一个特殊变种,有如下特性:
(1)StatefulSet 里每个 Pod 都有稳定、唯一的网络标识,可以用来发现集群内其他成员。假设 StatefulSet 名字叫 kafka,那么第 1 个 Pod 会命名为 kafka-0,第 2 个 Pod 叫 kafka-1,以此类推。
(2)StatefulSet 控制的 Pod 副本的启停顺序是受控的,操作第 n 个 Pod 时,前 n-1 个 Pod 已经是运行且准备好的状态。
(3)StatefulSet 里的 Pod 采用稳定的持久化存储卷,通过 PV/PVC 实现,删除 Pod 时默认不会删除与 StatefulSet 相关的存储卷。
(4)StatefulSet 需要与 Headless Service 配合使用,需要在每个 StatefulSet 的定义中声明它属于哪个 Headless Service(一种特殊的 Service)。
StatefulSet 适用于具有以下特点的应用:
- 具有固定的网络标记(主机名)
- 具有持久化存储
- 需要按顺序部署和扩展
- 需要按顺序终止及删除
- 需要按顺序滚动更新
部署模板

4.Deamonset
DaemonSet 确保集群中每个 node 中运行一份 Pod 副本,副本覆盖整个集群。当 node 加入集群时创建 Pod,当 node 离开集群时回收 Pod。如果删除 DaemonSet,其创建的所有 Pod 也被删除,当需要在集群内每个 node 运行同一个 Pod,使用 DaemonSet 是有价值的,以下是典型使用场景:
(1) 运行集群存储守护进程,如 glusterd、ceph。
(2) 运行集群日志收集守护进程,如 fluentd、logstash。
(3) 运行节点监控守护进程,如 Prometheus Node Exporter, collectd, Datadog agent, New Relic agent, or Ganglia gmond。
部署模板

5.Job
Job 负责处理仅执行一次的任务。在有些场景下要运行一些容器执行某种特定的任务,任务一旦执行完成,容器也就没有存在的必要了。在这种场景下,创建 Pod 就显得不那么合适。于是就是了 Job,Job 指的就是那些一次性任务。通过 Job 运行一个容器,当其任务执行完以后,就自动退出,集群也不再重新将其唤醒。
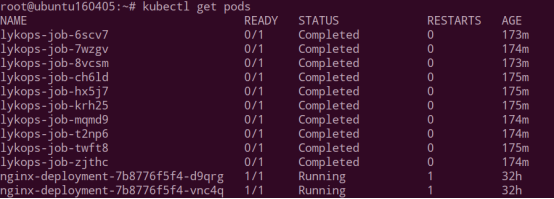
从程序的运行形态上来区分,可以将 Pod 分为两类:长时运行服务(jboss、mysql 等)和一次性任务(数据计算、测试)。Deployment 创建的 Pod 都是长时运行的服务,Job 多用于执行一次性任务、批处理工作等,执行完成后便会停止,Pods 状态从 Running 变为 Completed。
重启策略
支持两种重启策略:
- OnFailure: 在出现故障时其内部重启容器,而不是创建。
- Never: 会在出现故障时创建新的,且故障 job 不会消失。
并行
- spec.completions:这个 job 运行 Pod 的总次数
- spec.parallelism:并发数,每次同时运行多少个 Pod
当 completions 少于 parallelism,parallelism 的值为 completions
部署模板

五、访问应用
Kubernetes 访问应用使用的是 Service 资源,而不是直接使用 ip 地址或者域名。假设 Pod 中的容器很可能因为各种原因发生故障而死掉, 每个 Pod 都有自己的 IP 地址。当 Controller 用新 Pod 替代发生故障的 Pod 时,新 Pod 会分配到新的 IP 地址,服务的 ip 地址就发生了变化。Service 资源用于解决 IP 地址动态变化的问题。
1.Service 概念
Service:拥有固定 IP 的服务,从逻辑上代表了一组 Pod。Pod 的 IP 地址会变化,但是 Service 的 IP 是不变的。客户端只需要访问 Service 的 IP,Kubernetes 则负责建立和维护 Service 与 Pod 的映射关系。无论后端 Pod 如何变化,Service IP 不会变,对客户端就不会有任何影响。
Service 通过标签来选取服务后端,一般配合 Controller 来保证后端容器的正常运行。拥有标签的 Pods 的 ip 和端口组成 endpoints,由 kube-proxy 负责将 Service IP 负载均衡到这些 endpoints 上。
根据访问应用的来源不同,可以分为内部访问和外部访问。Service 的类型有如下两种:
ClusterIP 内部访问
NodePort 外部访问
2.ClusterIP
1.Service 通过集群内部的 IP 对外提供服务,只有集群内的节点和 Pod 可访问,这是默认的 Service 类型。使用场景:
(1) 使用 Kubernetes proxy 来访问服务:
(2) 调试服务,或者是因为某些原因需要从电脑直接连接服务;
(3) 允许内部流量,显示内部仪表盘等。
创建 Service 的 yaml 文件
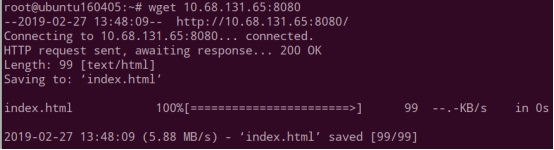
创建好 Service 之后,使用 Service 的 ip + 端口号即 10.68.131.65:8080,可以访问对应的 Pod。

Node 节点中访问
使用 10.68.213.112:8080 可以访问到 Service nginx 指向的一组 Pod 的 80 端口
Service 工作流程图:
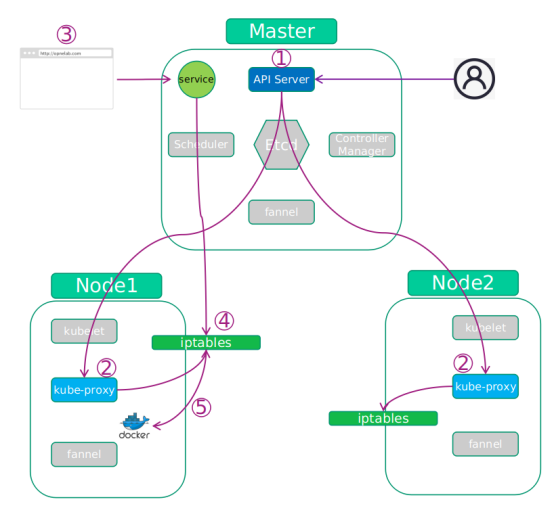
Service 使用流程分析:
- 管理员或用户创建 Service。
2.Kube-proxy 监听到 Service 变化,创建相应的 iptables 规则,同步到所有 Node 节点上。 - 用户访问 Service 的 ip 和端口号,Service 将流量转向 Node 节点的 Pod 的端口。
4.Node 节点根据 iptables 规则,转发流量到 Pod 的端口上。 - 流量转到 Pod 里的 docker 中
域名访问
除了使用 ip:8080 可以访问到应用外,在 Pod 中还允许使用域名的方式访问服务,即 Service name:8080 的方式。如下在 Pod 中使用 wget 访问。
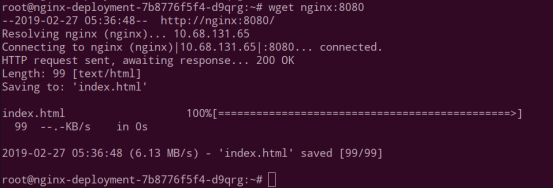
环境部署时会默认安装 coredns 组件,该组件提供 Service name 到 ip 的域名映射。
域名访问原理:
coredns 是一个 DNS 服务器,运行在 kube-system 命名空间下的 Pod,使用 deployment 控制器管理。每当有新的 Service 被创建,coredns 会添加该 Service 的 DNS 记录。Cluster 中的 Pod 可以通过 . 访问 Service。

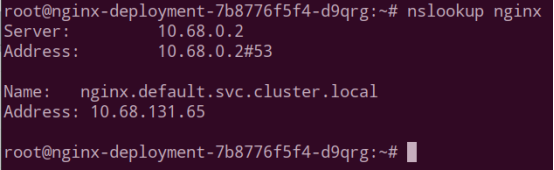
解析 dns 域名。使用 nslookup 解析 nginx 的 ip 地址,ip 为 10.68.131.65
使用对比:
使用域名访问更加安全。因为 Service 是一个 Pod,也可能会发生故障和重建,所以 ip 地址会可能发生变化,但是 Service 重建名称也不会变化,重建过程中 coredns 会重新记录域名和 ip 的对应关系。所以名称不会变,就能找到 Service 的 ip。
3.NodePort
Service 通过集群节点的静态端口对外提供服务。集群外部可以通过 NodeIP:NodePort 访问 Service。通过每个 Node 上的 IP 和静态端口(NodePort)暴露服务。NodePort 服务会路由到 ClusterIP 服务, ClusterIP 服务会自动创建,并转发流量到相应的 Pod。通过请求 NodeIP:NodePort,可以从集群的外部访问一个 NodePort 服务。
创建 NodePort 的 yaml 文件
创建好的 NodePort,24945 为直接访问的端口,8080 为 ClusterIP 端口。

PORT(S) 为 8080:32312。8080 是 ClusterIP 监听的端口,24945 则是节点上监听的端口。Kubernetes 会从 20000-32767 中分配一个可用的端口,每个节点都会监听此端口并将请求转发给 Service。
从浏览器请求:
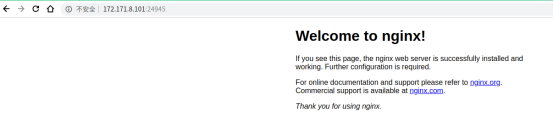
NodePort 默认是随机选择,不过我们可以用 nodePort 指定某个特定端口。

配置文件中 3 个 port 说明:
(1) nodePort 是节点上监听的端口。
(2) port 是 ClusterIP 上监听的端口。
(3) targetPort 是 Pod 监听的端口。
NodePort 方式有存在的不足之处:
(1) 一个端口只能供一个服务使用;
(2) 只能使用 30000–32767 的端口(安装时可自定义端口范围);
(3) 如果节点 / 虚拟机的 IP 地址发生变化,需要进行处理。
(4) 暴露服务较多时,端口管理复杂。
4.LoadBalancer
Service 利用云提供商特有的 load balancer 对外提供服务,云提供商负责将 load balancer 的流量导向 Service。目前支持的 cloud provider 有 GCP、AWS、Azur、阿里云 等。
阿里云负载均衡架构:
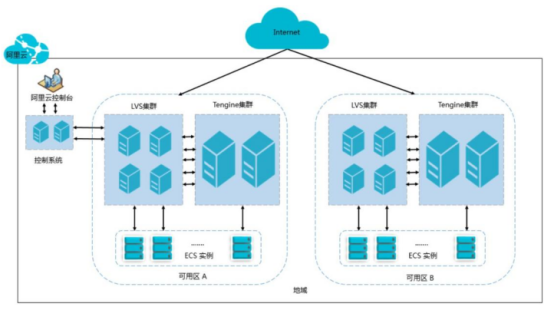
阿里云负载均衡服务主要有三个核心概念:
- 负载均衡实例 ( Server Load Balancer instances)
一个云负载均衡实例是一个运行的负载均衡服务,用来接收流量并将其分配给后端服务
器。要使用云负载均衡服务,您必须创建一个云负载均衡实例,并至少添加一个监听和两台云服务器实例。 - 监听 ( Listeners)
监听用来检查客户端请求并将请求转发给后端服务器。监听也会对后端服务器进行健康
检查。 - 后端服务器( Backend Servers)
一组接收前端请求的 ECS 实例。 您可以单独添加 ECS 实例到服务器池, 也可以通过虚
拟服务器组或主备服务器组来批量添加和管理。
六、负载均衡
Kubernetes 实现负载均衡的方式目前有三种:
- Nodeport,kube-proxy 支持
- LoadBalancer, 需要云供应商支持,或者本地 F5 设备支持
- Ingress,Kubernetes 一种管理入口流量资源
1.Nodeport
Kube-proxy 实现系统负载均衡。每个 Node 上都会运行一个 kube-proxy 服务进程,这个进程可以看做 Service 的透明代理和负载均衡器。其核心功能是将某个 Service 的访问请求转发到后端的某个 Pod 上。
Kube-proxy 的工作原理:
- kube-proxy 通过查询和监听 API server 中 Service 和 endpoint 的变化, 为每个 Service 都建立了一个服务代理对象, 并自动同步到所有节点的 kube-proxy 服务中。
- 服务代理对象是 proxy 程序内部的一种数据结构,它包括一个 socketserver,用于监听服务请求。socketserver 的端口是随机选择的一个本地空闲端口,也可以在创建服务时指定端口。
- kube-proxy 内部创建了一个负载均衡器 - LoadBalancer,LoadBalancer 上保存的是 Service 到对应的后端 endpoint 列表的动态转发路由表。
- 对于每一条的具体的路由选择则取决于负载均衡算法(即 LB 创建的路由表)及 Service 的 session 会话保持这两个特性。
以 NodePort 为例,说明 kube-proxy 的工作原理
NodePort 的 yaml 文件
Service 创建,端口号 22539

查看 Service 的 endpoint,后端有两个 Pod。
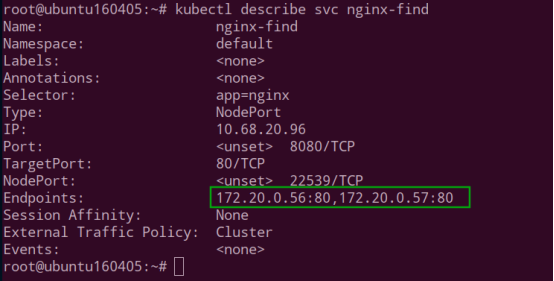
后端两个 Pod 的 ip 地址

Node 节点的 iptables 规则:
接收请求端口是 22539 的信息,将发送 22539 的请求转发给链 KUBE-SEP-N4C7F2OUBSWH2BFP 处理
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx-find:" -m tcp --dport 22539 -j KUBE-MARK-MASQ
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx-find:" -m tcp --dport 22539 -j KUBE-SVC-YGGX3UAZ364BFXUW
-A: 指定链名
-p: 指定协议类型
-j: 指定处理动作
该链有两条规则,意思是将 50% 的流量发送链 KUBE-SEP-N4C7F2OUBSWH2BFP,剩余 50% 发送 KUBE-SEP-JQYCFTO6ARVB4ENP。
--probability 0.50000000000 参数的意思是 处理 50% 的流量
-A KUBE-SVC-YGGX3UAZ364BFXUW -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-N4C7F2OUBSWH2BFP
-A KUBE-SVC-YGGX3UAZ364BFXUW -j KUBE-SEP-JQYCFTO6ARVB4ENP
***该链将流量发送 172.20.0.56:80 端口,即 Pod 的端口
-A KUBE-SEP-N4C7F2OUBSWH2BFP -p tcp -m tcp -j DNAT --to-destination 172.20.0.56:80
***
该链将流量发送 172.20.0.57 端口,即 Pod 的端口
-A KUBE-SEP-JQYCFTO6ARVB4ENP -p tcp -m tcp -j DNAT --to-destination 172.20.0.57:80
***
2.LoadBlancer Service
LoadBlancer Service 是 Kubernetes 结合云平台的组件,如国外 GCE、AWS、国内阿里云等等,使用它向使用的底层云平台申请创建负载均衡器来实现,有局限性,对于使用云平台的集群比较方便。
3.Ingress
Ingress 是 Kubernetes 中的 API 对象, Ingress 定义了管理对外服务到集群内服务之间规则的集合,它定义规则来允许进入集群的请求被转发到集群中对应服务上,从来实现服务暴漏。Ingress 能把集群内 Service 配置成外网能够访问的 URL,流量负载均衡,终止 SSL,提供基于域名访问的虚拟主机等等
以 Nginx 为例,Nginx 对后端运行的服务(Service1、Service2)提供反向代理,在配置文件中配置了域名与后端服务 Endpoints 的对应关系。客户端通过使用 DNS 服务或者直接配置本地的 hosts 文件,将域名都映射到 Nginx 代理服务器。当客户端访问 Service1.com 时,浏览器会把包含域名的请求发送给 nginx 服务器,nginx 服务器根据传来的域名,选择对应的 Service,这里就是选择 Service 1 后端服务,然后根据一定的负载均衡策略,选择 Service1 中的某个容器接收来自客户端的请求并作出响应。Ingress 的工作就是根据配置文件,修改 nginx.conf, 让 Nginx 灵活指向不同 Service。
Ingress 一般有三个组件组成:
1)Ingress 是 Kubernetes 的一个资源对象,用于编写定义规则。
2)反向代理负载均衡器,通常以 Service 的 Port 方式运行,接收并按照 Ingress 定义的规则进行转发,通常为 nginx,haproxy,traefik 等。
3)Ingress-Controller,监听 apiserver,获取服务新增,删除等变化,并结合 Ingress 规则动态更新到反向代理负载均衡器上,并重载配置使其生效。
工作原理图:
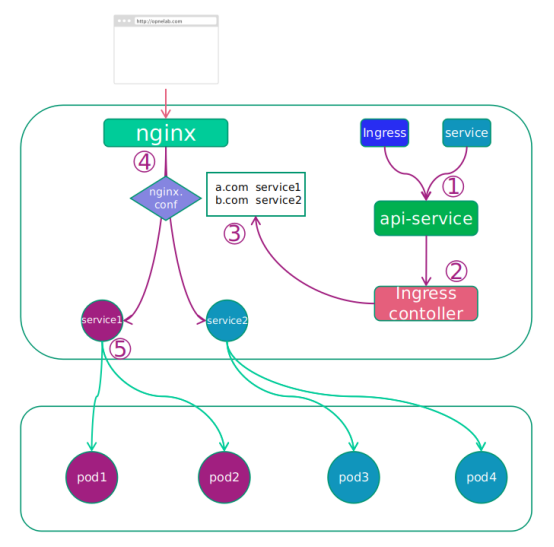
工作原理:
- Service 变化。Service 的创建和 Ingress 规则创建。
- 感知变化。Ingress Controller 通过和 Kubernetes api 交互,动态的去感知集群中 Ingress 规则变化。
- 定义规则。按照定义的规则,规则就是写明了哪个域名对应哪个 Service,生成一段 nginx 配置。更新规则。将规则写到 nginx-Ingress-controll 的 Pod 里。该 Pod 运行着一个反向代理负载均衡器(Nginx,haproxy,traefik)服务。以 nginx 为例,控制器会把生成的 nginx 配置写入 / etc/nginx.conf 文件中,然后 reload 一下使配置生效。以此达到域名分配置和动态更新的问题。
- 访问路由。客户端访问域名时,nginx 根据 nginx.conf 配置,将流量转向到对应的 Service 中。
- Service 根据标签将流量送往对相应的 Pod。
Kubernetes基本功能的更多相关文章
- k8s 核心功能 - 每天5分钟玩转 Docker 容器技术(116)
本节带领大家快速体验 k8s 的核心功能:应用部署.访问.Scale Up/Down 以及滚动更新. 部署应用 执行命令: kubectl run kubernetes-bootcamp \ --im ...
- Kubernetes知识小普及
大部分概念Kubernetes官网都有详细介绍,Kubernetes中文官网 https://kubernetes.io/zh/docs/tutorials/kubernetes-basics/ 官网 ...
- Kubernetes一键部署利器:kubeadm
要真正发挥容器技术的实力,你就不能仅仅局限于对 Linux 容器本身的钻研和使用. 这些知识更适合作为你的技术储备,以便在需要的时候可以帮你更快的定位问题,并解决问题. 而更深入的学习容器技术的关键在 ...
- Kubernetes介绍及基本概念
kubernetes介绍 Kubernetes是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,Kubernetes也叫K8S.K8S是Google内部一个叫Borg的容器集 ...
- centos7下kubernetes(1。kubernetes---start)
kubernetes官网:https://kubernetes.io/docs/home/ 也是怀着不情愿的心情,要开始kubernetes了,本身是非常热爱技术,尤其是容器技术,可能是最近有点累和懈 ...
- K8S学习笔记之二进制部署Kubernetes v1.13.4 高可用集群
0x00 概述 本次采用二进制文件方式部署,本文过程写成了更详细更多可选方案的ansible部署方案 https://github.com/zhangguanzhang/Kubernetes-ansi ...
- Docker Kubernetes 介绍 or 工作原理
Kubernetes 介绍 Kubernetes是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,Kubernetes也叫K8S. K8S是Google内部一个叫Borg的容 ...
- Docker集群管理工具 - Kubernetes 部署记录 (运维小结)
一. Kubernetes 介绍 Kubernetes是一个全新的基于容器技术的分布式架构领先方案, 它是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,Kubernete ...
- K8S学习笔记之Kubernetes核心概念
0x00 Kubernetes简介 Kubernetes(K8S)是Google开源的容器集群管理系统,其设计源于Google在容器编排方面积累的丰富经验,并结合社区创新的最佳实践. K8S在Doc ...
随机推荐
- Hadoop Yarn框架原理解析
在说Hadoop Yarn的原理之前,我们先来看看Yarn是怎样出现的.在古老的Hadoop1.0中,MapReduce的JobTracker负责了太多的工作,包括资源调度,管理众多的TaskTrac ...
- powershell-将powershell脚本排到JOB
Program/script下填写“Powershell”,表示这个脚本会在powershell环境下运行 Add arguments(optional)填写脚本绝对路径名称 Start in(Opt ...
- java 根据ip获取地区信息(淘宝和新浪)
package com.test; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStr ...
- 考据:internet 和 Web
我们有时大谈互联网发展趋势,有时讨论Web开发:有时说因特网如何,有时又说万维网怎样.但身处其间我们,有时雾里看花,对有些东西一知半解,这里对internet和Web进行一个简单梳理(很多东西缺少可信 ...
- python开发之路-LuffyCity
阅读目录 一.python基础语法 二.python基础之字符编码 三.python基础之文件操作 四.python基础小练习 五.python之函数基础 六.python之函数对象.函数嵌套.名称空 ...
- nginx正则匹配
1.通用匹配规则 . 匹配除换行符以外的任意字符 \w 匹配字母.数字.下划线.汉字 \s 匹配任意的空白符 \d 匹配数字 ^ 匹配字符串的开始 $ 匹配字符串的结束 ...
- linux-高并发与负载均衡-lvs-功能配置介绍
百度百科: LVS是Linux Virtual Server的简写,意即Linux虚拟服务器,是一个虚拟的服务器集群系统.本项目在1998年5月由章文嵩博士成立,是中国国内最早出现的自由软件项目之一. ...
- C#中的PropertyGrid绑定对象,通过改变某一值而动态设置部分属性的特性
问题:如下,我定义了一个对象,默认设置属性WindowSize ,WindowSize 为不可见,通过改变SaveOnClose的值,动态的改变不可见的属性的显示和隐藏. [DefaultProper ...
- 滴滴 CTO 架构师 业务 技术 战役 时间 赛跑 超前 设计
滴滴打车CTO张博:生死战役,技术和时间赛跑-CSDN.NEThttps://www.csdn.net/article/2015-06-25/2825058-didi 滴滴出行首席架构师李令辉:业务的 ...
- Net包管理NuGet(2)nuget包的生成方法
1,下载NuGetPackageExplorer,可以下载运行源码,也可以直接下载安装包安装安装之后打开 设置好内容之后点击绿色的打钩保存然后操作右边空白处 然后点击File>Save;保存之后 ...