论文阅读笔记(七)YOLO
You Only Look Once: Unified, Real-Time Object Detection
Joseph Redmon, CVPR, 2016
1. 之前的目标检测工作将分类器用作检测,而YOLO将检测问题看做回归问题,用一个网络端对端地执行检测任务(包括边界框位置和相应的类别概率预测),这使得YOLO可以直接对检测的表现进行优化。
2. YOLO具有如下优点:
速度快且mAP高,YOLO45帧每秒,fast YOLO 155帧每秒(两倍于其他实时检测系统的mAP)
对背景的假阳性预测更少,但边界框位置的精度不高
习得特征的通用性更高,可移植性好(比如从自然景物到艺术画作的移植)
3. 快速准确的目标检测算法有很高的应用价值,如自动驾驶,机器人系统等。
4. 目前的检测系统将分类器用作检测,其原理是在测试图像的不同位置,不同尺寸对其进行分类评估。如DPM系统就是将一张图像等间隔地分成不同的块,在这些块上滑动窗口进行分类来执行检测的。
5. 最近的检测方法如RCNN先选出一些候选的边界框,然后在这些候选的边界框上执行分类操作,最后应用后处理技术对边界框进行调整。这种分阶段的操作不仅速度慢,达不到实时的要求还难以对其进行优化,因为它的不同阶段是分开训练的。
6. 我们提出的YOLO将检测问题看做回归问题使用一个网络对一张图片端对端地进行检测,一次性得到边界框位置和类别概率。达到看一眼就知道图片上出现了什么物体,以及它的位置在哪的效果。

7. 如图1 所示,YOLO的结构很简单,它只用了一个卷积网络对整张图片不同物体的边界框的位置和其相应的类别概率进行预测。YOLO在整张图片上进行训练,并直接对检测的效果进行优化。这种统一的模型让YOLO比传统的检测方案多了如下的优点:
YOLO的速度极快,因为它的结构简单,并且是对整张图像进行预测。YOLO 45帧每秒,fast YOLO 超过150帧每秒。应用于实时视频检测时延迟低于25毫秒。不仅快,mAP还是其他实时检测方案的两倍以上。
YOLO对整张图片进行全局预测,不像滑动窗口和边界框提议方案,YOLO的训练和预测都是在整张图片上进行的,这让他能隐式地编码物体类别及其外观的上下文信息。顶级的目标检测算法如fast RCNN会将背景标记为其他物体,这种现象的原因是其看到的上下文信息很少。而YOLO的背景标识错误比Fast RCNN的一半还少。
YOLO习得目标特征的通用性更好,在自然景物图像上训练的YOLO可用于艺术图像的预测,其检测效果远高于顶尖的检测算法如DPM和RCNN。正因为YOLO的通用性好,所以当把YOLO应用于新的领域,或输入不符合预期的图像时,它仍能稳健地运行。
8. YOLO的缺点在于,其精度落后于当前最先进的目标检测系统,尽管YOLO能快速地识别出图片中的物体,但它很难对一些物体,尤其是小物体进行精确的定位。我们在实验中研究识别速度与定位精度存在的这种制约关系。
2. Unified Detection
9. 我们将检测任务中分离的组件统一为一个神经网络。我们的网络使用来自整张图片的特征对每个边界框进行预测。它还同时对一张图片上所有物体的类别和相应的边界框进行预测。这意味着我们的网络是对整张图片和其上的所有物体进行全局推理的。YOLO的这种设计使得在保证较高的平均精度的前提下,端对端训练和实时检测的速度成为可能。
10. 我们的系统将输入图像分成S×S的栅格,如果一个物体的中心落入一个栅格单元,那么这个栅格单元就负责这个物体的检测。
11. 每个栅格单元预测B个边界框和这些边界框的置信度得分。置信度得分反映了栅格单元内有物体存在的确信程度和边界框预测的准确度。通常我们将置信度定义为:${p_r}(Object) * IOU_{pred}^{truth}$,如果栅格单元中没有物体存在,那么置信度得分为0,否则置信度得分为边界框标签与预测边界框之间的交并比(IOU)。
12. 每个边界框由5个预测值组成:x,y,w,h和confidence。(x,y)代表边界框中心相对删个单元边界的坐标。边界框宽度和高度是相对整张图片预测得出的。confidence代表预测边界框和边界框标签之间的交并比(IOU)。
13. 每个栅格单元同时预测C个类条件概率${P_r}(Clas{s_i}|Object)$,这些概率以栅格单元内包含物体为条件。无论边界框的数目B为多少,我们对每个栅格单元都只预测一组类别概率。
14. 在测试时,我们将类条件概率与每个边界框的置信度得分相乘,得到特定类的每个边界框的置信度得分(C*B个得分/栅格单元):
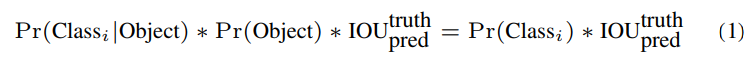
这些得分不仅代表了某一类物体出现在该边界框的概率,还代表了该边界框预测的准确度。
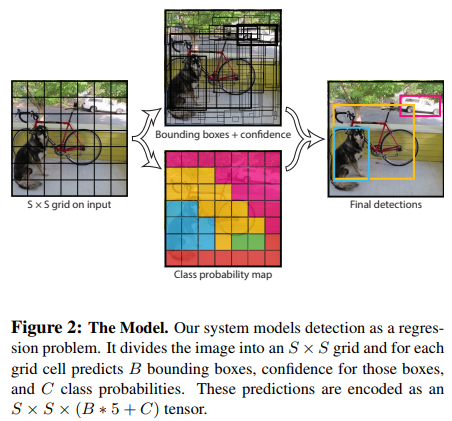
15. 如何对预测结果进行编码:我们的系统将检测问题视作回归问题。它将图片分成S*S个栅格单元,对于每个栅格单元预测B个边界框(5个预测值组成)和相对应的B个置信度得分,以及C个类别概率。这些预测可以由一个S×S×(B*5+C)维的张量表示。
16. 为了在PASCAL VOC上评估YOLO,我们令S=7,B=2,C=20(对应VOC的20个有标签的类)。那么我们最终的预测是一个7×7×(2*5+20)=7×7×30维的张量。
2.1. Network Design
17. 我们用卷积神经网络完成检测工作,并在PASCAL VOC数据集上对它进行评估。初始的卷积层用于图像的特征提取,全连接层用于预测输出概率和坐标。
18. 我们的网络效仿GoogLeNet,由24个卷积层和2个全连接层组成。我们没有使用GoogLeNet的Inception结构,而是使用了一个1×1降维卷积后接3×3卷积的结构。网络整体结构如图3所示。

19. 为了测试快速检测的边界,我们还训练了一个YOLO网络的快速版本。它的卷积层更少(9层相对24层),层内的卷积核更少。除了网络大小不同,训练和测试时使用的参数fast YOLO和YOLO是一样的。
20. 网络的最终输出是一个预测的7×7×30的张量。
2.2. Training
21. 先把图3所示网络的前20层拿出来,和一个平均池化层,一个全连接层拼起来形成一个用于预训练的网络,然后在有1000类标签的ImageNet数据集上训练该网络,该网络在ImageNet-2012验证集上取得了可以匹敌GoogLeNet的88%的精度。该网络的训练和测试使用的深度学习框架均为DarkNet。
22. 然后我们给预训练后的网络加上4个卷积层和2个全连接层用于检测,由于检测往往需要细粒度的视觉信息,因此我们把输入图像的分辨率从224×224提高到448×448.
23. 网络的最后一层同时预测出类别概率和边界框坐标。我们用图像的宽和高对边界框的宽和高进行规范化,使其数值落入0,1之间。(x,y)代表边界框中心相对这个栅格单元位置的偏移量,因此它的边界也是0和1 。
24. 网络各层的激活函数为:
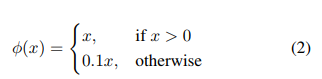
25. 损失函数为均方和误差,因为均方和误差易于优化。但是这和我们想要优化最大平均精度的目标不符,因为首先均方和误差视定位误差和分类误差的权重相同,这不符合实际情况。其次,有很多栅格内并不存在物体,这会导致那些栅格的置信度得分为0,进一步抑制了那些含有物体的栅格梯度的更新。(类别不平衡问题?不含物体的栅格太多,其xywh的均方和淹没了含物体栅格的xywh的均方和)由于训练过程过早发散,这会让模型很不稳定。
26. 为了弥补这两个缺点,我们增加来自模型坐标预测的损失的权重,降低来自不含物体的边界框的置信度得分预测的损失的权重。引入两个参数${\lambda _{coord}}$和${\lambda _{noobj}}$来实现操作,设${\lambda _{coord}} = 5$,${\lambda _{noobj}} = .5$。
27. 均方和误差还视来自大边界框的和来自小边界框的误差权重相同。而我们的评价指标应该反映出在小边界框中的小偏差比在大边界框中的小偏差更重要的性质。为了解决这个问题,我们对w和h的平方根进行预测,而不是直接预测w和h。(因为进行平方根运算后大小边界框宽和高的数值拉近了?)
28. YOLO为每个栅格单元预测多个边界框(B个),在训练期间,我们只想要一个边界框对应一个对象。我们基于哪个预测边界框和标签边界框的交并比(IOU)最大,来配对边界框和对象。这会导致边界框预测的专业化,每个边界框更擅长对具有特定尺寸,类别,纵横比的物体进行预测。
29. 在训练期间,我们对下面的损失函数进行优化:
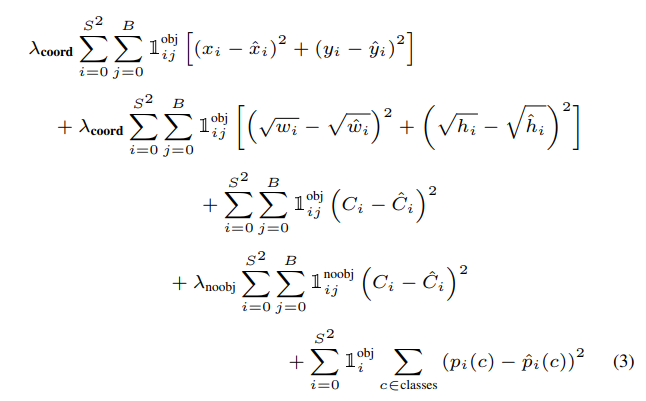
其中$1_i^{obj}$表示如果物体出现在栅格单元i中,$1_{ij}^{obj}$表示栅格单元i中的边界框j对该预测负责。
30. 值得注意的是,该损失函数仅惩罚栅格中有物体的分类误差,也仅惩罚对边界框标签负责的预测边界框的坐标误差(即该栅格中IOU最高的那个预测边界框)。
31. 我们在PASCAL VOC 2007和2012的训练集和验证集上训练网络,迭代135个epochs。在2007和2012的测试集上测试网络。在整个训练过程,使用的batch大小为64,动量为0.9,并以0.0005的速率衰减。
32. 我们学习率的设置策略为:在第一个epoch,学习率从${10^{ - 3}}$缓慢增长到${10^{ - 2}}$,因为如果从较大的学习率开始训练由于梯度不稳定,训练过程会很快发散。我们继续用${10^{ - 2}}$训练75个epochs,然后用${10^{ - 3}}$训练30个epochs,最后用${10^{ - 4}}$训练剩下的30个epochs。
33. 使用droupout和数据扩增来避免过拟合。在第一个连接层后使用rate=0.5的droupout层。数据扩增的方法有放缩,平移,调整图像的曝光和饱和度。
2.3. Inference
34. 和训练过程一样,对测试图片的检测也只需一个网络。在PASCAL VOC上网络对每张图片预测出98个边界框及其对应的类(S*S*B=7*7*2=98,49个栅格,每个栅格预测两个边界框)。由于YOLO仅用一个网络进行预测,所以它的速度很快,是基于分类器的检测方法所不能比的。
35. 栅格的设计实现了边界框预测的空间多样性。通常一个物体落入哪个栅格是很明确的,这种情况下网络为每个物体只预测一个边界框。然鹅,当物体太大或者物体处于多个栅格单元边界附近时,它可以被多个栅格单元很好的定位。非最大值抑制算法用于修复这些多重检测,然而它的效果并不想在DPM和RCNN中那么大,对mAP的提升仅为2%到3%。
2.4. Limitations of YOLO
36. YOLO对边界框预测施加了很强的空间限制,因为每个网格单元格只能预测两个框,并且只能有一个类。这种空间约束限制了我们的模型可以预测的邻近对象的数量。我们的模型对如鸟群这样成群出现的小物体的检测效果不佳。
37. 由于我们的模型从数据中进行学习,所以它很难泛化到对具有不同纵横比或者不同配置的物体的预测任务中。我们的模型用于预测物体边界框使用的特征相对粗糙,因为输入图像在我们的网络结构中经过了数次下采样。
38. 我们用的损失函数对大边界框的误差和小边界框的误差带来的损失不予区别,而显然后者对IOU的影响更大,这导致我们模型的定位不够精准。
论文阅读笔记(七)YOLO的更多相关文章
- 论文阅读笔记七:Structure Inference Network:Object Detection Using Scene-Level Context and Instance-Level Relationships(CVPR2018)
结构推理网络:基于场景级与实例级目标检测 原文链接:https://arxiv.org/abs/1807.00119 代码链接:https://github.com/choasup/SIN Yong ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- [论文阅读笔记] GEMSEC,Graph Embedding with Self Clustering
[论文阅读笔记] GEMSEC: Graph Embedding with Self Clustering 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 已经有一些工作在使用学习 ...
随机推荐
- java学习札记
java学习札记 0x0 学习原因 本来打算大三再去跟着课程去学习java的,但是现在题目越来越偏向java,所以迫于无奈开启了java的学习篇章,同时也正好写个笔记总结下自己学习一门语言的流程. ...
- day 24 面向对象之继承及属性查找顺序
组合 组合:自定义类的对象作为另外一个类的属性 class Teacher: def init(self, name, age): self.name = name self.age = age t1 ...
- 七 Struts2 文件上传和下载
配置文件 <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE struts PUBLIC &qu ...
- 【问题解决方案】AttributeError: module 'pygal' has no attribute 'Worldmap'
<Python编程:从入门到实践>- 16章-16.2.5制作世界地图 import pygal 后报如标题的error 参考CSDN 解决:AttributeError: module ...
- Appium 客户端类库
Appium 支持以下语言的客户端类库: 语言 Ruby Python Java JavaScript PHP C# Objective-C 锁定注意,一些方法类似 endTestCoverage() ...
- linux软连接文件的copy
最近在做项目的时候遇到过一个问题:当copy一个工程模块时发现里面的目录文件有重复定义的情况. 最后查看源文件目录发现是存在软连接造成的. 出现这种情况的原因是:当直接copy文件目录时遇到软连接会把 ...
- Python2和Python3安装教程
当同时安装Python2和Python3后,如何兼容并切换使用详解(比如pip使用) python成了2.7而py成了3.7,呵呵! 当同时安装Python2和Python3后,如何兼容并切换使用详解 ...
- 关于Aop切面中的@Before @Around等操作顺序的说明
[转]http://www.cnblogs.com/softidea/p/6123307.html 话不多说,直接上代码: package com.cdms.aop.aspectImpl; impor ...
- 应用系统如何分析和获取SQL语句的执行代码
大部分开发人员都有这样一个需求,在程序连接数据库执行时,有时需要获取具体的执行语句,以便进行相关分析,这次我向大家介绍一下通用权限管理系统提供的SQL语句执行跟踪记录,直接先看看代码吧:(这个功能我也 ...
- Python并发编程之多线程使用
目录 一 开启线程的两种方式 二 在一个进程下开启多个线程与在一个进程下开启多个子进程的区别 三 练习 四 线程相关的其他方法 五 守护线程 六 Python GIL(Global Interpret ...