(三)ORB特征匹配
ORBSLAM2匹配方法流程
在基于特征点的视觉SLAM系统中,特征匹配是数据关联最重要的方法。特征匹配为后端优化提供初值信息,也为前端提供较好的里程计信息,可见,若特征匹配出现问题,则整个视觉SLAM系统必然会崩掉。因此,本系列将特征匹配独立成一讲进行分析。
ORBSLAM2中的匹配流程如下所述:
1. 计算当前帧描述子对应的BOW向量;
2. 设置匹配阈值;
3. 进行BOW特征向量匹配确定最优匹配;
4. 统计匹配描述子角度偏差并筛选,确定最终匹配。
接下来,我们一起再细细分析一下,每一步它具体是怎么做的。
1. 词袋模型
在进入正题之前,需要给大家普及一下,什么叫BOW。BOW就是Bag of Word,是词袋模型中的词汇组合而成的向量。
到这里,大家肯定又会有疑惑,什么叫词袋模型?
从字面上非常直观的意思就是:装着很多词汇的袋子。那么,这个袋子里面的词袋究竟是什么?怎么来的呢?
我们知道,一帧图像中,可以提取到很多的特征点,每一个特征点都是一个图像局部块的描述,那么相似场景下的特征点,其描述应该是比较接近的。如果我们将这些常见场景的相似特征进行聚类,下一次再遇到相似的特征,能不能直接用我们聚类的结果来表示这个特征呢?显然是可以的。也就是说,我们把所有相似的特征描述都进行统一化,最终得到一个唯一的描述。而词袋模型就是将所有常见场景的特征描述子按照树状图进行分层聚类,最终得到的一系列聚类中心——统一化的特征描述。
为了让大家更加直观的理解我所说的东西,我为大家提供了一个分层聚类的树结构图:
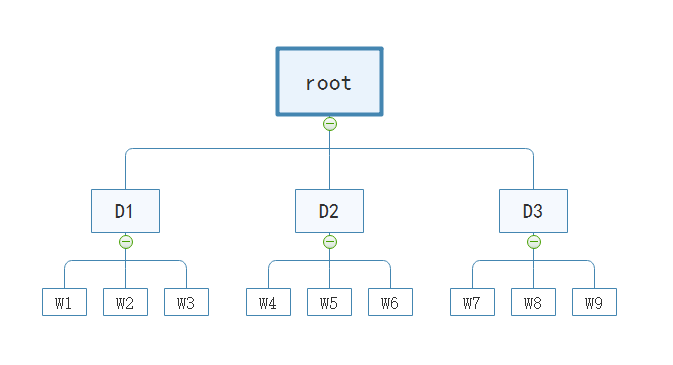
如图所示,上述树结构是一个聚类中心K为3,深度D为2的词汇树,共计产生KD也就是9个词汇。
比如我有10帧图像,每帧图像提取了500个特征点,那么总共有5000个特征点。首先将其聚成3类,作为粗略的筛选。在这三个聚类中心的基础上,每个大类下的特征点再进一步聚成三类。所以我们将5000个特征点分成了9大类,即9个词汇,对于属于词汇W5的描述子,其最终表示是[ 0 0 0 0 1 0 0 0 0 ],对于每一个词汇,都存储着其对应的权重。对于任意一张输入图像,所有特征点通过词袋模型转换以后变成 [ 50 50 100 0 0 50 50 100 100 ],即输入图像中的所有特征点直接转换成了一个9维的向量,在图像检索时非常高效。
但是,上述的词袋模型对于我们的问题来说,实在是太小了。因此,ORBSLAM中回环检测里采用的词袋模型,是从一些常用场景的大量图像中提取了特征点后进行上述基于树结构的聚类。当然,其树结构肯定是更大更深的,比如,聚类中心K为10,深度D为5的词汇树,共计产生十万个词汇。这个庞大的词汇树可以让不那么相似的特征分开,使得BOW向量更加具有区分度。
2. 转换成BOW向量
对于输入图像的所有特征点,我们通过词袋模型转换成对应词汇,在树结构庞大的情况下,我们不能在一个向量中包含所有词汇,一方面是考虑内存,另一方面考虑检索效率。因此,我们只保存非0的词汇,即 I = { (W1, 0.01), (W5,0.02), ..., (W300,0.05) },花括号里(A,B),A表示词汇ID,B表示权重。需要注意的是,这里的权重是我随机写的,只是为了方便大家理解,实际的权重必须是根据统计结果算出来的。
以上述的树结构为例,对于任意一个特征点,我们从root节点出发,与第一层聚类中心进行粗匹配,选择匹配分数最高的一个聚类中心。接着,继续与其子类进行特征匹配,找到最优的匹配,直到叶子为止,这个叶子就是我们之前所说的词汇。假设最终找到的词汇是W3,则这个描述子对应的BOW就是(W3,0.02),通过将所有特征点进行相同的操作,我们可以得到一系列词汇ID和权重,将其串起来就得到了我们要的BOW向量了。
3. 特征匹配
通过上述的方法,我们将待匹配图像的特征点转换成BOW向量,在匹配时我们查找两帧BOW向量中相同ID的词汇,特征匹配只在有相同ID的词汇中进行。显然,这个过程限定了匹配范围,可以提高匹配的速度。当然,匹配的精度跟词汇树的大小和深度有关系。

假设在图像1中,ID为3的词汇中包含6个特征点,同理,图像2中包含3个特征点。则对图像1中的每个特征点都与图像2中的每个特征点计算匹配分数,通过最近邻比例法,结合阈值条件筛选出最优的匹配对。值得注意的是,在图像2中已经匹配过的特征点,图像1其余特征点就不再与之匹配了。
形象一点说:图像1中有6名男士,图像2中有3名女士,自由牵手组合。当图像1中的一名男士与图像2中的所有女士进行交流后(特征匹配),有其中一位好感度比较高(匹配分数高于匹配阈值),那么就牵手成功了。这时,图像1中剩余5名男士自然无法匹配已经被选择的那名女士。相反,如果所有女士都对其好感度较低(匹配分数低于匹配阈值),则说明牵手失败。(即匹配失败)
4. 确定最优匹配
ORBSLAM2中将360°分成30个bin,每个bin的范围是12°。对于图像1和图像2任意两个对应匹配特征,我们计算其二者主方向的夹角。根据夹角的大小确定在哪个角度范围里,并将特征索引存入对应bin中。
我们统计每个bin中保存的索引数量,取数量最多的前三个bin作为最终的匹配对结果。其他的匹配对全部予以删除。至此,我们的最优匹配就全部确定了。
不过,值得注意的是,我们实际上匹配的点只是一部分,另一部分没有匹配到的,在后面会通过共试图关键帧以及局部地图重投影进行进一步匹配,我们会在后续的内容中讲解。
总结:
本文主要介绍了ORBSLA2中的匹配方案,以及词袋模型的生成方法。本文在文末提供了一些参考文献,欢迎大家查阅。
(为了让大家能更直观的了解ORBSLAM2的图像匹配,本文后续会提供图像匹配的源码。。。)
下一讲,我将为大家介绍ORBSLAM2的运动估计模块。
参考文献:
[1] A Fast and incremental method for loop-closure detection using bags of visual words
[2] 视觉SLAM十四讲
PS:
如果您觉得我的博客对您有所帮助,欢迎关注我的博客。此外,欢迎转载我的文章,但请注明出处链接。
对本文有任何问题可以在留言区进行评论,也可以在泡泡机器人论坛:http://paopaorobot.org/bbs/index.php?c=cate&fid=1中的SLAM技术交流模块发帖提问。
我的github链接是:https://github.com/yepeichu123/orbslam2_learn。
(三)ORB特征匹配的更多相关文章
- 第十六节、基于ORB的特征检测和特征匹配
之前我们已经介绍了SIFT算法,以及SURF算法,但是由于计算速度较慢的原因.人们提出了使用ORB来替代SIFT和SURF.与前两者相比,ORB有更快的速度.ORB在2011年才首次发布.在前面小节中 ...
- 特征提取(Detect)、特征描述(Descriptor)、特征匹配(Match)的通俗解释
特征匹配(Feature Match)是计算机视觉中很多应用的基础,比如说图像配准,摄像机跟踪,三维重建,物体识别,人脸识别,所以花一些时间去深入理解这个概念是不为过的.本文希望通过一种通俗易懂的方式 ...
- OpenCV探索之路(二十三):特征检测和特征匹配方法汇总
一幅图像中总存在着其独特的像素点,这些点我们可以认为就是这幅图像的特征,成为特征点.计算机视觉领域中的很重要的图像特征匹配就是一特征点为基础而进行的,所以,如何定义和找出一幅图像中的特征点就非常重要. ...
- OpenCV开发笔记(六十五):红胖子8分钟带你深入了解ORB特征点(图文并茂+浅显易懂+程序源码)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- OpenCV特征点检测------ORB特征
OpenCV特征点检测------ORB特征 ORB是是ORiented Brief的简称.ORB的描述在下面文章中: Ethan Rublee and Vincent Rabaud and Kurt ...
- OpenCV2:特征匹配及其优化
在OpenCV2简单的特征匹配中对使用OpenCV2进行特征匹配的步骤做了一个简单的介绍,其匹配出的结果是非常粗糙的,在这篇文章中对使用OpenCV2进行匹配的细化做一个简单的总结.主要包括以下几个内 ...
- OpenCV2简单的特征匹配
特征的匹配大致可以分为3个步骤: 特征的提取 计算特征向量 特征匹配 对于3个步骤,在OpenCV2中都进行了封装.所有的特征提取方法都实现FeatureDetector接口,DescriptorEx ...
- ORB特征点检测
Oriented FAST and Rotated BRIEF www.cnblogs.com/ronny 这篇文章我们将介绍一种新的具有局部不变性的特征 -- ORB特征,从它的名字中可以看出它 ...
- 【AR实验室】mulberryAR:并行提取ORB特征
本文转载请注明出处 —— polobymulberry-博客园 0x00 - 前言 在[AR实验室]mulberryAR : ORBSLAM2+VVSION末尾提及了iPhone5s真机测试结果,其中 ...
随机推荐
- java网络编程基本知识
1.基本概念 网络:一组相互连接的计算机,多台计算机组成,使用物理线路进行连接 网络连接的功能:交换数据.共享资源 网络编程3要素: IP 地址:唯一标识网络上的每一台计算机,两台计算机之间通信的必备 ...
- 随心测试_软测基础_005 <测试人员工作内容>
接上篇:清楚了_测试人员的工作职责范围,那每项 测试活动的具体工作内容有哪些呢? Q1:如何理解测试工程师的工作内容? A1:SX的观点:综合一体化 现如今互联网行业如何哪达,每一项IT职业的工作职责 ...
- postman使用详解
前言: Postman是一款功能强大的网页调试与发送网页HTTP请求的Chrome插件. 接口请求流程 一.get请求 GET请求:点击Params,输入参数及value,可输入多个,即时显示在URL ...
- 云计算openstack共享组件(2)——Memcache 缓存系统
一.缓存系统 在大型海量并发访问网站及openstack等集群中,对于关系型数据库,尤其是大型关系型数据库,如果对其进行每秒上万次的并发访问,并且每次访问都在一个有上亿条记录的数据表中查询某条记录时, ...
- mysql union 与 union all 语法及用法
1.mysql union 语法 mysql union 用于把来自多个select 语句的结果组合到一个结果集合中.语法为: select column,......from tabl ...
- Nginx访问配置
配置HTTP协议(使用80默认端口,非HTTPS配置SSL)访问网站 包括RestAPI的配置和RestAPI文档的配置 例如: server { # 配置为HTTP协议 listen ; serve ...
- Event-Loop In JS
原文:最后一次搞懂 Event Loop 自打 ES 6 推出 Promise 改善了 js 的异步编程之后,eventloop 也越来越多地出现在视野当中.借用大佬们的话:“Event Loop 是 ...
- MT【327】两道不等式题
当$x,y\ge0,x+y=2$时求下面式子的最小值:1)$x+\sqrt{x^2-2x+y^2+1}$2)$\dfrac{1}{5}x+\sqrt{x^2-2x+y^2+1}$ 解:1)$P(x,y ...
- CentOS7防火墙问题
CentOS6关闭防火墙使用以下命令, //临时关闭service iptables stop//禁止开机启动chkconfig iptables off CentOS7中若使用同样的命令会报错, s ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...