kNN算法:K最近邻(kNN,k-NearestNeighbor)分类算法
一、KNN算法概述
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。Cover和Hart在1968年提出了最初的邻近算法。KNN是一种分类(classification)算法,它输入基于实例的学习(instance-based learning),属于懒惰学习(lazy learning)即KNN没有显式的学习过程,也就是说没有训练阶段,数据集事先已有了分类和特征值,待收到新样本后直接进行处理。与急切学习(eager learning)相对应。
KNN是通过测量不同特征值之间的距离进行分类。
思路是:如果一个样本在特征空间中的k个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
提到KNN,网上最常见的就是下面这个图,可以帮助大家理解。
我们要确定绿点属于哪个颜色(红色或者蓝色),要做的就是选出距离目标点距离最近的k个点,看这k个点的大多数颜色是什么颜色。当k取3的时候,我们可以看出距离最近的三个,分别是红色、红色、蓝色,因此得到目标点为红色。
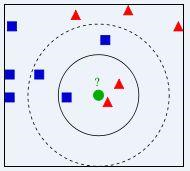
算法的描述:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类
二、关于K的取值
K:临近数,即在预测目标点时取几个临近的点来预测。
K值得选取非常重要,因为:
如果当K的取值过小时,一旦有噪声得成分存在们将会对预测产生比较大影响,例如取K值为1时,一旦最近的一个点是噪声,那么就会出现偏差,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
如果K的值取的过大时,就相当于用较大邻域中的训练实例进行预测,学习的近似误差会增大。这时与输入目标点较远实例也会对预测起作用,使预测发生错误。K值的增大就意味着整体的模型变得简单;
如果K==N的时候,那么就是取全部的实例,即为取实例中某分类下最多的点,就对预测没有什么实际的意义了;
K的取值尽量要取奇数,以保证在计算结果最后会产生一个较多的类别,如果取偶数可能会产生相等的情况,不利于预测。
K的取法:
常用的方法是从k=1开始,使用检验集估计分类器的误差率。重复该过程,每次K增值1,允许增加一个近邻。选取产生最小误差率的K。
一般k的取值不超过20,上限是n的开方,随着数据集的增大,K的值也要增大。
三、关于距离的选取
距离就是平面上两个点的直线距离
关于距离的度量方法,常用的有:欧几里得距离、余弦值(cos), 相关度 (correlation), 曼哈顿距离 (Manhattan distance)或其他。
Euclidean Distance 定义:
两个点或元组P1=(x1,y1)和P2=(x2,y2)的欧几里得距离是
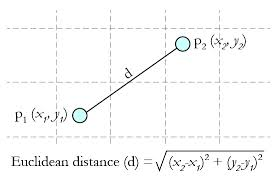
距离公式为:(多个维度的时候是多个维度各自求差)
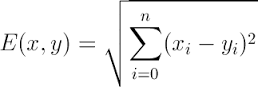
四、总结
KNN算法是最简单有效的分类算法,简单且容易实现。当训练数据集很大时,需要大量的存储空间,而且需要计算待测样本和训练数据集中所有样本的距离,所以非常耗时
KNN对于随机分布的数据集分类效果较差,对于类内间距小,类间间距大的数据集分类效果好,而且对于边界不规则的数据效果好于线性分类器。
KNN对于样本不均衡的数据效果不好,需要进行改进。改进的方法时对k个近邻数据赋予权重,比如距离测试样本越近,权重越大。
KNN很耗时,时间复杂度为O(n),一般适用于样本数较少的数据集,当数据量大时,可以将数据以树的形式呈现,能提高速度,常用的有kd-tree和ball-tree。
(弱小无助。。。根据许多大佬的总结整理的)
五、Python实现
根据算法的步骤,进行kNN的实现,完整代码如下
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: JYRoooy
import csv
import random
import math
import operator # 加载数据集
def loadDataset(filename, split, trainingSet = [], testSet = []):
with open(filename, 'r') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)-1):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random() < split: #将数据集随机划分
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x]) # 计算点之间的距离,多维度的
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length):
distance += pow((instance1[x]-instance2[x]), 2)
return math.sqrt(distance) # 获取k个邻居
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist)) #获取到测试点到其他点的距离
distances.sort(key=operator.itemgetter(1)) #对所有的距离进行排序
neighbors = []
for x in range(k): #获取到距离最近的k个点
neighbors.append(distances[x][0])
return neighbors # 得到这k个邻居的分类中最多的那一类
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0] #获取到票数最多的类别 #计算预测的准确率
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet)))*100.0 def main():
#prepare data
trainingSet = []
testSet = []
split = 0.67
loadDataset(r'irisdata.txt', split, trainingSet, testSet)
print('Trainset: ' + repr(len(trainingSet)))
print('Testset: ' + repr(len(testSet)))
#generate predictions
predictions = []
k = 3
for x in range(len(testSet)):
# trainingsettrainingSet[x]
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print ('predicted=' + repr(result) + ', actual=' + repr(testSet[x][-1]))
print('predictions: ' + repr(predictions))
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: ' + repr(accuracy) + '%') if __name__ == '__main__':
main()
六、sklearn库的应用
我利用了sklearn库来进行了kNN的应用(这个库是真的很方便了,可以借助这个库好好学习一下,我是用KNN算法进行了根据成绩来预测,这里用一个花瓣萼片的实例,因为这篇主要是关于KNN的知识,所以不对sklearn的过多的分析,而且我用的还不深入
kNN算法:K最近邻(kNN,k-NearestNeighbor)分类算法的更多相关文章
- K最近邻(KNN,k-Nearest Neighbor)准确理解
K最近邻(KNN,k-Nearest Neighbor)准确理解 用了之后,发现我用的都是1NN,所以查阅了一下相关文献,才对KNN理解正确了,真是丢人了. 下图中,绿色圆要被决定赋予哪个类,是红色三 ...
- 分类算法——k最近邻算法(Python实现)(文末附工程源代码)
kNN算法原理 k最近邻(k-Nearest Neighbor)算法是比较简单的机器学习算法.它采用测量不同特征值之间的距离方法进行分类,思想很简单:如果一个样本在特征空间中的k个最近邻(最相似)的样 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- 分类算法-----KNN
摘要: 所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用她最接近的k个邻居来代表.kNN算法的核心思想是如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于 ...
- 数据挖掘之分类算法---knn算法(有matlab例子)
knn算法(k-Nearest Neighbor algorithm).是一种经典的分类算法.注意,不是聚类算法.所以这种分类算法 必然包括了训练过程. 然而和一般性的分类算法不同,knn算法是一种懒 ...
- K近邻(K Nearest Neighbor-KNN)原理讲解及实现
算法原理 K最近邻(k-Nearest Neighbor)算法是比较简单的机器学习算法.它采用测量不同特征值之间的距离方法进行分类.它的思想很简单:如果一个样本在特征空间中的k个最近邻(最相似)的样本 ...
- 基于机器学习和TFIDF的情感分类算法,详解自然语言处理
摘要:这篇文章将详细讲解自然语言处理过程,基于机器学习和TFIDF的情感分类算法,并进行了各种分类算法(SVM.RF.LR.Boosting)对比 本文分享自华为云社区<[Python人工智能] ...
- Mahout 分类算法
实验简介 本次课程学习了Mahout 的 Bayes 分类算法. 一.实验环境说明 1. 环境登录 无需密码自动登录,系统用户名 shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu ...
- 机器学习---K最近邻(k-Nearest Neighbour,KNN)分类算法
K最近邻(k-Nearest Neighbour,KNN)分类算法 1.K最近邻(k-Nearest Neighbour,KNN) K最近邻(k-Nearest Neighbour,KNN)分类算法, ...
随机推荐
- 2016-3-1 安装Hexo过程中遇到的问题
查找问题地址: http://hexo.io/docs/troubleshooting.html 1.通过npm安装hexo运行命令:sudo npm install -g hexo 出现这个 ...
- Android Getting Started
Building Your First App Creating an Android Project 介绍如何Android开发环境,具体是:怎么使用Eclipse工具 Create a Proje ...
- Linux 下redis 集群搭建练习
Redis集群 学习参考:https://blog.csdn.net/jeffleo/article/details/54848428https://my.oschina.net/iyinghui/b ...
- Oracle事务与锁 知识点摘记
事务:事务用于保证数据的一致性,它由一组相关的dml语句组成,该组的dml语句要么全部成功要么全部失败. 说明:一组SQL,一个逻辑工作单位,执行整体修改或者整体回退. 事务的相关概念: 1.事务的提 ...
- json格式的数据及遍历:
代码: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8 ...
- hive求TopN语句
ROW_NUMBER,RANK(),DENSE_RANK() 先了解这三个之间的区别: Rank():1,2,2,4,5(一般用这个较多,不会影响总排名) Dense_rank():1,2,2,3,4 ...
- lvm快照备份数据库(Mysql5.7)
备份的目的 能够防止由于机械故障以及人为误操作带来的数据丢失,例如将数据库文件保存在了其它地方. 备份的分类 以操作过程中服务的可用性分: 冷备份:cold backup mysql服务关闭,mysq ...
- CDN(Content Delivery Network)技术原理概要
简介 CDN(Content Delivery Network)即内容分发网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡.内容分发.调度等功能,使用户就近获取所需内容,提高用户访问响应速度和 ...
- C#转发Post请求,包括参数和文件
/// <summary> /// 转发Post请求 /// </summary> /// <param name="curRequest">要 ...
- [BlueZ] 2、使用bluetoothctl搜索、连接、配对、读写、使能notify蓝牙低功耗设备
星期三, 05. 九月 2018 02:03上午 - beautifulzzzz 1.前言 上一篇讲了如何编译安装BlueZ-5,本篇主要在于玩BlueZ,用命令行去操作BLE设备: [BlueZ] ...