Java序列化和反序列化,你该知道得更多
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象——百度词条解释。
通俗点的来说,程序运行的时候,会产生很多对象,而对象信息也只是在程序运行的时候才在内存中保持其状态,一旦程序停止,内存释放,对象也就不存在了。怎么能让对象永久的保存下来呢?对象序列化,了解下——
一 入门
在Java的 I/O 类库中,专门给开发人员提供了两个类用于对象的序列化和反序列化操作的流类 ObjectOutputStream 和 ObjectInputStream。有了这两个类的帮助,再依照流的操作步骤一步两步,简单的对象的序列化和反序列化就真的很简单。代码示例:
User类:
public class User implements Serializable {
private static final long serialVersionUID = -1075318199295234057L;
//时间标示
private Date date = new Date();
private String name;
private String password;
private int age;
public User() {
}
public User(String name, String password, int age) {
this.name = name;
this.password = password;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public Date getDate() {
return date;
}
public void setDate(Date date) {
this.date = date;
}
@Override
public String toString() {
return "User{" +
"序列化存储时间:" + date +
", name='" + name + '\'' +
", password='" + password + '\'' +
", age=" + age +
'}';
}
}
测试类:
//序列化和反序列化
public class SerialTest {
public static void main(String[] args) throws InterruptedException { /**
* 基本步骤:
* ① 对象实体类实现Serializable 标记接口
* ② 创建序列化输出流对象ObjectOutputStream,该对象的创建依赖于其它输出流对象,通常我们将对象序列化为文件存储,所以这里用文件相关的输出流对象 FileOutputStream
* ③ 通过ObjectOutputStream 的 writeObject()方法将对象序列化为文件
* ④ 关闭流 这里采用1.7开始的新语法 try-with-resources 而不用自己控制流的关闭
*/
User user = new User("陈本布衣", "123456", 100);
try (ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream("D:\\user"))) {
os.writeObject(user);
} catch (Exception e) {
e.printStackTrace();
} //先睡5秒
TimeUnit.SECONDS.sleep(5); /**
* 基本步骤:
* ① 创建输入流对象ObjectOutputStream。同样依赖于其它输入流对象,这里是文件输入流 FileInputStream
* ② 通过 ObjectInputStream 的 readObject()方法,将文件中的对象读取到内存
* ③ 关闭流 同上
*/
try (ObjectInputStream is = new ObjectInputStream(new FileInputStream("D:\\user"))) {
User o = (User) is.readObject();
System.out.println(o);
System.out.println("当前时间:"+new Date());
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
最终你在控制台上看到应该是符合预期的效果:

我们看到,密码这样的敏感信息也被序列化了,反序列化后这种敏感信息就有暴露的风险,而通常敏感信息我们是不希望保留的,怎么办呢,很简单,给不希望序列化的字段添加 transient 标识,就像这样: private transient String password; 该字段在序列化时就会被忽略,坏人就看不见敏感信息啦——

二 进阶
以上只是很简单的入门示例,实际开发中我们还要面对很多复杂的业务场景。比如模型对象持有其它对象的引用怎么处理,引用类型如果是复杂些的集合类型怎么处理?进阶的部分,一起来探索一下。
关于第一个问题,其实仔细分析上面的基础示例已经很明显了,我们User类中本来就持有Date,String类的引用,不是一样的被序列化和反序列化了吗?如果是我们自己定义的类,是不是一样的效果呢?给用户添加菜单(Menu)来尝试一下
public class Menu {
private Integer id;
private String name;
private String url;
public Menu() {
}
public Menu(Integer id,String name, String url) {
this.id = id;
this.name = name;
this.url = url;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
@Override
public String toString() {
return "Menu{" +
"id=" + id +
", name='" + name + '\'' +
", url='" + url + '\'' +
'}';
}
}
public class User implements Serializable {
private static final long serialVersionUID = -1075318199295234057L;
//时间标示
private Date date = new Date();
private String name;
private Menu menu;
private transient String password;
private int age;
public User() {
}
public User(String name, String password, int age) {
this.name = name;
this.password = password;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public Date getDate() {
return date;
}
public void setDate(Date date) {
this.date = date;
}
public Menu getMenu() {
return menu;
}
public void setMenu(Menu menu) {
this.menu = menu;
}
@Override
public String toString() {
return "User{" +
"序列化存储时间:" + date +
", name='" + name + '\'' +
", 菜单:" + menu +
", password='" + password + '\'' +
", age=" + age +
'}';
}
}
测试代码:
public class SerialTest {
public static void main(String[] args) throws InterruptedException {
//序列化
User user = new User("陈本布衣", "123456", 100);
Menu menu = new Menu(1,"菜单1","/menu1");
user.setMenu(menu);
try (ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream("D:\\user"))) {
os.writeObject(user);
} catch (Exception e) {
e.printStackTrace();
}
//先睡5秒
TimeUnit.SECONDS.sleep(5);
//反序列化
try (ObjectInputStream is = new ObjectInputStream(new FileInputStream("D:\\user"))) {
User o = (User) is.readObject();
System.out.println(o);
System.out.println("当前时间:"+new Date());
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
测试结果,抛出了 java.io.NotSerializableException 异常。很明显在告诉我们,Menu没有实现序列化接口。待Menu类实现序列化接口后,成功——

这样的测试很容易让我们举一反三,既然序列化必须要实现标记接口 Serializable,那是不是意味着,我们之前能序列化成功,String、Date等类都实现了该接口呢?很明显,是的,源码会给你佐证——

继续反三,如果要序列化待集合类型的数据,我们的集合类型又是不是都实现了序列化接口呢?查看便知——

以上潦草的贴图充分的说明了举一反三的重要性,我们可以清晰的看到,我们能想到的常用集合类型都实现了 Serializable 接口,于是关于带集合类型的实体类的序列化和反序列化,似乎也很简单明了。先来将实体中的菜单改为集合形式: private List<Menu> menus; 然后进行测试——
public class SerialTest {
public static void main(String[] args) throws InterruptedException {
//序列化
User user = new User("陈本布衣", "123456", 100);
Menu menu = new Menu(1, "菜单1", "/menu1");
Menu menu2 = new Menu(2, "菜单2", "/menu2");
List<Menu> menus = new ArrayList<>();
menus.add(menu);
menus.add(menu2);
user.setMenus(menus);
try (ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream("D:\\user"))) {
os.writeObject(user);
} catch (Exception e) {
e.printStackTrace();
}
//先睡5秒
TimeUnit.SECONDS.sleep(5);
//反序列化
try (ObjectInputStream is = new ObjectInputStream(new FileInputStream("D:\\user"))) {
User o = (User) is.readObject();
System.out.println(o);
System.out.println("当前时间:" + new Date());
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
结果也很符合预期——

三 颠覆
博主也是刚刚发现自己被骗了,真的,不骗你!
上面部分博主说到,各种集合类因为实现了 Serializable 标记接口,所以序列化的时候也不用特殊对待,按照基本步骤就能成功的实现序列化和反序列化;入门的时候博主还说道,如果不想某个字段被序列化,就用 transient 修饰一下,嗯,说的都很有道理,但是如果你有翻看源码的良好习惯的话,对于集合类的源码当然不会陌生。上面贴图,只是说它们都实现了标记接口,但是它们的存储数据的字段是下面这样的:
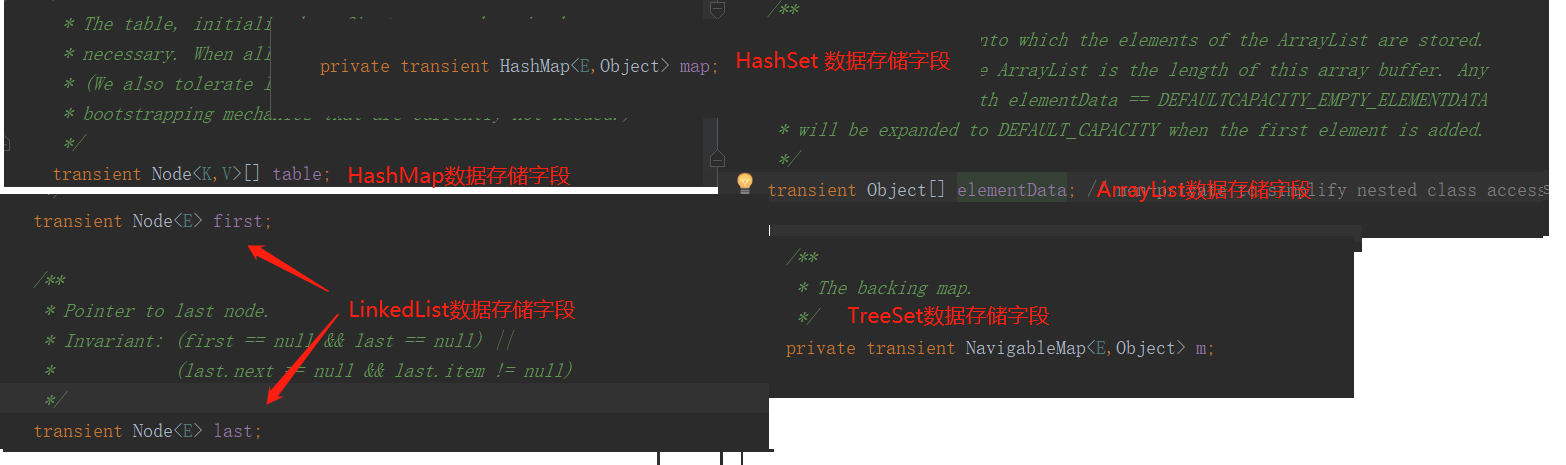
你会发现,几种常用集合类的数据存储字段,竟然都被 transient 修饰了,然而在实际操作中我们用集合类型存储的数据却可以被正常的序列化和反序列化?WHAT,这不是啪啪打脸博主的吗?理论崩塌了,真相在哪里?真相当然还是在源码里。实际上,各个集合类型对于序列化和反序列化是有单独的实现的,并没有采用虚拟机默认的方式。这里以 ArrayList中的序列化和反序列化源码部分为例分析:
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{
int expectedModCount = modCount;
//序列化当前ArrayList中非transient以及非静态字段
s.defaultWriteObject();
//序列化数组实际个数
s.writeInt(size);
// 逐个取出数组中的值进行序列化
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
//防止在并发的情况下对元素的修改
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// 反序列化非transient以及非静态修饰的字段,其中包含序列化时的数组大小 size
s.defaultReadObject();
// 忽略的操作
s.readInt(); // ignored
if (size > 0) {
// 容量计算
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
//检测是否需要对数组扩容操作
ensureCapacityInternal(size);
Object[] a = elementData;
// 按顺序反序列化数组中的值
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
读源码可以知道,ArrayList的序列化和反序列化主要思路就是根据集合中实际存储的元素个数来进行操作,这样做估计是为了避免不必要的空间浪费(因为ArrayList的扩容机制决定了,集合中实际存储的元素个数肯定比集合的可容量要小)。为了验证,我们可以在单元测试序列化和返序列化的时候,在ArrayLIst的两个方法中打上断点,以确认这两个方法在序列化和返序列化的执行流程中(截图为反序列化过程):
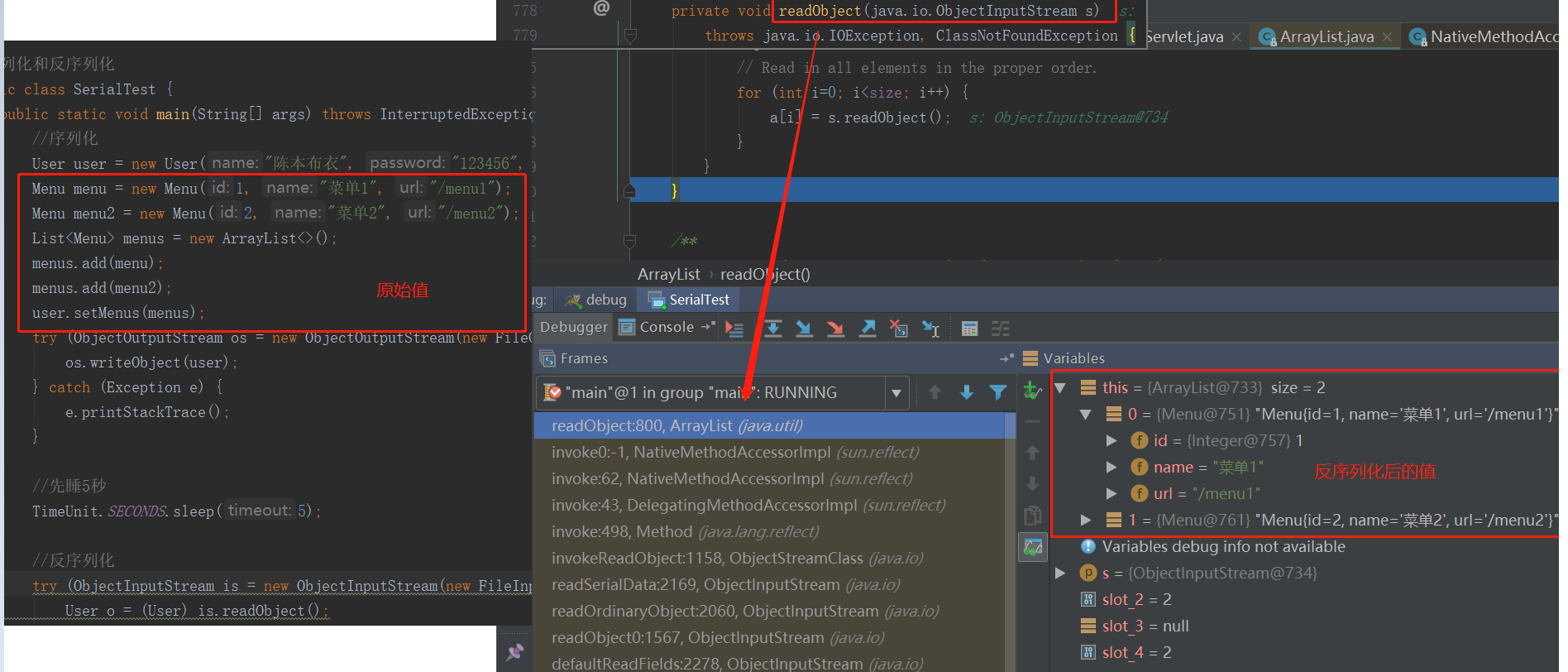
原来,我们之前自以为集合能成功序列化也只是简单的实现了标记接口都只是表象,表象背后有各个集合类有不同的深意。所以,同样的思路,读者朋友可以自己去分析下 HashMap以及其它集合类中自行控制序列化和反序列化的个中门道了,博主就不帮大家分析源码了(zhuang bi hao lei ^ ^)。
四 发散
行文至此,豁然开朗的赶脚有木有?但是,你以为这样就完了吗?不不,以下才是真正的高潮呢。学习的过程中,如果你的思维够发散的话,根据源码,依样画葫芦,其实可以学到很多东西的。上面,我们已经分析了集合中序列化和反序列化的两个方法,然后在查阅各个集合类源码中的序列化和反序列化方法的时候,只因多看了一眼,博主惊讶的发现,它们的方法签名都是相同的。这说明什么?很蹊跷啊各位。同样都是实现了序列化标记接口,那么,我是不是可以在自己的实体类中同样的声明这两个方法呢?结果很nice,当然是可以的(前提是要实现序列化接口),但是这会导致默认的序列化失效,同集合中一样,当你单独声明了 writeObject 和 readObject 方法之后,相当于覆盖了默认的序列化方式——


以上,我们成功的自定义了序列化实现,但这完全不影响上层序列化的代码编写,你只是更改了默认实现而已。最后,你将很惊喜的在JDK文档关于Serializable的描述中,找到之前你可能没啥感觉但现在却体会至深的话:
在序列化和反序列化过程中需要特殊处理的类必须使用下列准确签名来实现特殊方法: private void writeObject(java.io.ObjectOutputStream out) throws IOException
private void readObject(java.io.ObjectInputStream in) throws IOException, ClassNotFoundException;
private void readObjectNoData() throws ObjectStreamException;
更加豁然开朗了,有木有?表面上看,Serializable只是个看似啥都没有的空标接口,但是接口背后,虚拟机做了什么,你未必都看得见。其实,如果要自定义实现的话,我们还可以实现 Serializable 的子接口 Externalizable,重写其中的方法,实现自定义逻辑,不过,用以上的方式,足够你玩的了。 好了,序列化和和反序列化的问题,就此打住。
五 问答
① 实现标记接口后,其中的 serialVersionUID 必须要指定吗?官方文档有如下表述:
如果可序列化类未显式声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值,如“Java(TM) 对象序列化规范”中所述。
不过,强烈建议 所有可序列化类都显式声明 serialVersionUID 值,原因是计算默认的 serialVersionUID 对类的详细信息具有较高的敏感性,根据编译器实现的不同可能千差万别,这样在反序列化过程中可能会导致意外的 InvalidClassException。
因此,为保证 serialVersionUID 值跨不同 java 编译器实现的一致性,序列化类必须声明一个明确的 serialVersionUID 值。还强烈建议使用 private 修饰符显示声明 serialVersionUID(如果可能),原因是这种声明仅应用于直接声明类
-- serialVersionUID 字段作为继承成员没有用处。数组类不能声明一个明确的 serialVersionUID,因此它们总是具有默认的计算值,但是数组类没有匹配 serialVersionUID 值的要求。
所以,尽量显示的声明,这样序列化的类即使有字段的修改,因为 serialVersionUID 的存在,也能保证反序列化成功。
② 难道序列化只有上面的方式?
当然不是。根据序列化的定义,不管通过什么方式,只要你能把内存中的对象转换成能存储或传输的方式,又能反过来恢复它,其实都可以称为序列化。因此,我们常用的 Fastjson、Jackson等第三方类库将对象转成Json格式文件,也可以算是一种序列化,用JAXB实现XML格式文件输出,也可以算是序列化。所以,千万不要被思维局限,其实现实当中我们进行了很多序列化和反序列化的操作,涉及不同的形态、数据格式等。
③ 说一两个实际场景呢?
最典型的,在Tom猫中,tomcat服务正常关闭会把session对象序列化到SESSIONS.ser文件中,等下次启动的时候再把这些session再加载到内存;Socket套接字通信中,将对象在客户端和服务端之间传输。示例代码:
public class SocketClient {
public static void main(String[] args) {
System.out.println("Socket 客户端");
Socket client = null;
try {
// 与服务端建立连接
client = new Socket("127.0.0.1", 9527);
ObjectOutputStream os = new ObjectOutputStream(client.getOutputStream());
User user = new User("陈本布衣", "123456", 100);
Menu menu = new Menu(1, "菜单1", "/menu1");
Menu menu2 = new Menu(2, "菜单2", "/menu2");
List<Menu> menus = new ArrayList<>();
menus.add(menu);
menus.add(menu2);
user.setMenus(menus);
// 往服务写数据
os.writeObject(user);
} catch (Exception e) {
e.printStackTrace();
}
}
}
/*****************************************/
public class SocketServer {
public static void main(String[] args) {
System.out.println("Socket 服务端");
ServerSocket server;
try {
//服务端监听端口
server = new ServerSocket(9527);
Socket socket = server.accept();
ObjectInputStream is = new ObjectInputStream(socket.getInputStream());
Object o = is.readObject();
System.out.println("传过来的内容,请收下:"+o);
} catch (Exception e) {
e.printStackTrace();
}
}
}
④ 对象序列化中的持久存储,和将对象数据保存到数据库的持久化不是一样的吗?
这其实还是要区别看待的。因为我们保存数据库的方式叫对象(关系)映射,重点在于映射两个字,也就是说只是将我内存对象和真实的数据库数据表中的数据进行了映射绑定,并不是直接将对象存进了数据库。
⑤ 对象发序列话后,和原来的对象是同一个对象吗?
序列化只是对原对象的一个拷贝,保持了原对象各个字段的状态值,但肯定不是同一个对象了。你想,你把对象序列化出去,N久了,你虚拟机都关十次八次了,两个对象怎么可能相同?
⑥ 你很帅是吗?
是。
Java序列化和反序列化,你该知道得更多的更多相关文章
- Java序列化与反序列化
Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java序列化与反序列化?本文围绕这些问题进行了探讨. 1.Java序列化与反序列化 Java序列化是指把Java对象转换为字节序列 ...
- [转] Java序列化与反序列化
原文地址:http://blog.csdn.net/wangloveall/article/details/7992448 Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java ...
- Java序列化与反序列化(Serializable)
Java序列化与反序列化(Serializable) 特别注意: 1.要序列化的类必须实现Serializable借口 2.在反序列化(读取对象)的时候必须额外捕获EOFException 3.序列化 ...
- Java基础(五)-Java序列化与反序列化
.output_wrapper pre code { font-family: Consolas, Inconsolata, Courier, monospace; display: block !i ...
- JAVA序列化和反序列化XML
package com.lss.utils; import java.beans.XMLDecoder; import java.beans.XMLEncoder; import java.io.Bu ...
- Java序列化与反序列化(实践)
Java序列化与反序列化(实践) 基本概念:序列化是将对象状态转换为可保持或传输的格式的过程.与序列化相对的是反序列化,它将流转换为对象.这两个过程结合起来,可以轻松地存储和传输数据. 昨天在一本书上 ...
- java序列化与反序列化(转)
Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java序列化与反序列化?本文围绕这些问题进行了探讨. 1.Java序列化与反序列化 Java序列化是指把Java对象转换为字节序列 ...
- Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java序列化与反序列化?
Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java序列化与反序列化?本文围绕这些问题进行了探讨. 1.Java序列化与反序列化 Java序列化是指把Java对象转换为字节 ...
- (记录)Jedis存放对象和读取对象--Java序列化与反序列化
一.理论分析 在学习Redis中的Jedis这一部分的时候,要使用到Protostuff(Protobuf的Java客户端)这一序列化工具.一开始看到序列化这些字眼的时候,感觉到一头雾水.于是,参考了 ...
- Java序列化与反序列化三连问:是什么?为什么要?如何做?
Java序列化与反序列化是什么? Java序列化是指把Java对象转换为字节序列的过程,而Java反序列化是指把字节序列恢复为Java对象的过程: 序列化:对象序列化的最主要的用处就是在传递和保存对象 ...
随机推荐
- Codeforces.765F.Souvenirs(主席树)
题目链接 看题解觉得非常眼熟,总感觉做过非常非常类似的题啊,就是想不起来=v=. 似乎是这道...也好像不是. \(Description\) 给定长为\(n\)的序列\(A_i\).\(m\)次询问 ...
- Cause: java. lang.InstantiationException: tk.mybatis.mapper.provider.base.BaseInsertProvider
相信现在Java Web开发都是用的mybatis吧,而用到mybatis很多人都不会错过通用mapper吧! (纯属瞎扯淡...qwq). 如我上一篇博客所写,目前公司新项目,使用了通用mapper ...
- [CF703D]Mishka and Interesting sum/[BZOJ5476]位运算
[CF703D]Mishka and Interesting sum/[BZOJ5476]位运算 题目大意: 一个长度为\(n(n\le10^6)\)的序列\(A\).\(m(m\le10^6)\)次 ...
- JS区分对象类型
Object.prototype.toString.call() 区分对象类型 在JavaScript中数据类型分为:1.基本类型,2.引用类型 基本类型:Undefined,Boolean,Stri ...
- js 原型链的介绍
对象的原型链:一个对象所拥有的属性不仅仅是它本身拥有的属性,他还会从其他对象中继承一些属性.当js在一个对象中找不到需要的属性时,它会到这个对象的父对象上去找,以此类催,这就构成了对象的原型链. 下面 ...
- 用简单的代码让一组静态图片变成gif动画
比如这组图片: 变成这样的gif动画: 是不是很神奇.... 先看html .样式.很简单,一个div,然后引入图片. <!DOCTYPE html> <html ...
- conda 查看已有环境
conda info -e # conda environments: # dlcv /Users/enzhao/suanec/libs/anaconda2/envs/dlcv py36 /Users ...
- jstl使用中的错误----基于idea
第一:首先正确将jstl.jar和standard.jar导入项目的lib目录下,注意两者的版本信息 第二: <%@ taglib prefix="c" uri=" ...
- Golang Go Go Go part3:数据类型及操作
五.Go 基本类型 1.基本类型种类 布尔值: bool 长度 1字节 取值范围 true, false注意事项:不可用数字代表 true 或 false 整型: int/uint 根据运行平台可能为 ...
- Tensorboard可视化(关于TensorFlow不同版本引起的错误)
# -*- coding: utf-8 -*-"""Created on Sun Nov 5 15:28:50 2017 @author: Administrator&q ...