Lucene.Net3.0.3+盘古分词器学习使用
一、Lucene.Net介绍
Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎。开发人员可以基于Lucene.net实现全文检索的功能。
Lucene.net是Apache软件基金会赞助的开源项目,基于Apache License协议。
Lucene.net并不是一个爬行搜索引擎,也不会自动地索引内容。我们得先将要索引的文档中的文本抽取出来,然后再将其加到Lucene.net索引中。标准的步骤是先初始化一个Analyzer、打开一个IndexWriter、然后再将文档一个接一个地加进去。一旦完成这些步骤,索引就可以在关闭前得到优化,同时所做的改变也会生效。这个过程可能比开发者习惯的方式更加手工化一些,但却在数据的索引上给予你更多的灵活性。
二、盘古分词器
盘古分词是一个中英文分词组件。作者eaglet 曾经开发过KTDictSeg 中文分词组件,拥有大量用户。作者基于之前分词组件的开发经验,结合最新的开发技术重新编写了盘古分词组件。主要有以下功能:
1、中文未登陆词识别
2、词频优先
3、一元分词,多元分词
4、中文人名分词
5、繁体中文分词
6、英文分词
7、用户自定义规则(字典管理,动态加载字典,关键词高亮)
......
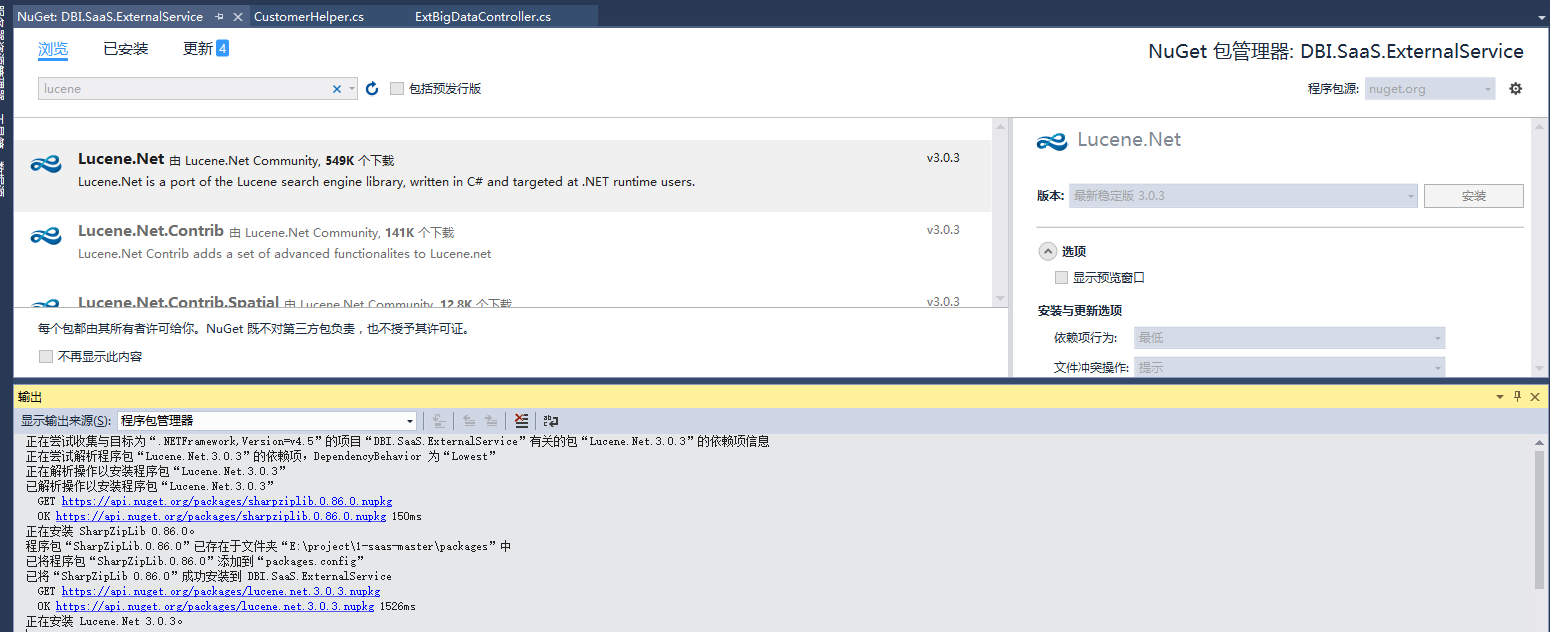
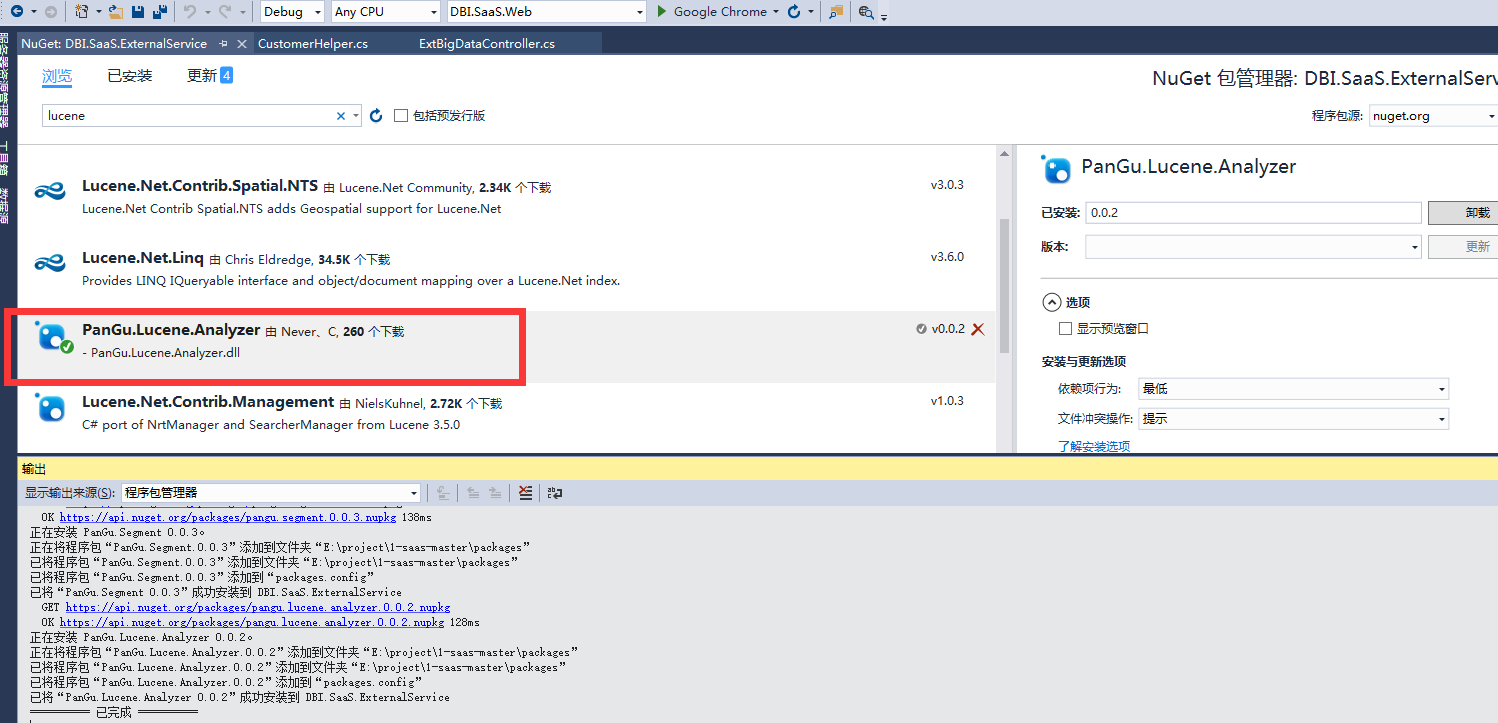
三、安装
四、代码分析
1.初始化盘古分词的xml引用路径
/// <summary>
/// 初始化盘古分词的xml引用路径
/// </summary>
/// <param name="PanGuXmlPath"></param>
public static void InitPanGuXmlPath(string PanGuXmlPath)
{
//定义盘古分词的xml引用路径
PanGu.Segment.Init(PanGuXmlPath);
}
2.创建索引
/// <summary>
/// 创建索引
/// </summary>
/// <param name="IndexDic">目录地址</param>
/// <param name="isCreate">是否重新创建</param>
public static void CreateIndex(string IndexDic, bool isCreate)
{
try
{
//创建索引目录
if (!System.IO.Directory.Exists(IndexDic))
{
System.IO.Directory.CreateDirectory(IndexDic);
}
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(IndexDic), new NativeFSLockFactory());
//IndexReader:对索引库进行读取的类
bool isExist = IndexReader.IndexExists(directory);
//是否存在索引库文件夹以及索引库特征文件
if (isExist)
{
//如果索引目录被锁定(比如索引过程中程序异常退出或另一进程在操作索引库),则解锁
//Q:存在问题 如果一个用户正在对索引库写操作 此时是上锁的 而另一个用户过来操作时 将锁解开了 于是产生冲突 --解决方法后续
if (IndexWriter.IsLocked(directory))
{
IndexWriter.Unlock(directory);
}
}
//IndexWriter第三个参数:true指重新创建索引,false指从当前索引追加....此处为新建索引所以为true
IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), isCreate, Lucene.Net.Index.IndexWriter.MaxFieldLength.LIMITED);
for (int i = ; i < ; i++)
{
//这里是测试数据
AddIndex(writer, "我的标题" + i, i + "标题内容是飞大师傅是地方十大飞啊的飞是 安抚爱上地方 爱上地方" + i, DateTime.Now.AddDays(i).ToString("yyyy-MM-dd"));
AddIndex(writer, "射雕英雄传作者金庸" + i, i + "我是欧阳锋" + i, DateTime.Now.AddDays(i).ToString("yyyy-MM-dd"));
AddIndex(writer, "天龙八部2" + i, i + "慕容废墟,上官静儿,打撒飞艾丝凡爱上,虚竹" + i, DateTime.Now.AddDays(i).ToString("yyyy-MM-dd"));
AddIndex(writer, "倚天屠龙记2" + i, i + "张无忌机" + i, DateTime.Now.AddDays(i).ToString("yyyy-MM-dd"));
AddIndex(writer, "三国演义" + i, i + "刘备,张飞,关羽" + i, DateTime.Now.AddDays(i).ToString("yyyy-MM-dd"));
}
writer.Optimize();
writer.Dispose();
}
catch (Exception ex)
{ throw;
}
}
private static void AddIndex(IndexWriter writer, string title, string content, string date)
{
try
{
Document doc = new Document();
doc.Add(new Field("Title", title, Field.Store.YES, Field.Index.NOT_ANALYZED));//存储且索引
doc.Add(new Field("Content", content, Field.Store.YES, Field.Index.ANALYZED));//存储且索引
doc.Add(new Field("AddTime", date, Field.Store.YES, Field.Index.NOT_ANALYZED));//存储且索引
writer.AddDocument(doc);
}
catch (FileNotFoundException fnfe)
{
throw fnfe;
}
catch (Exception ex)
{
throw ex;
}
}
索引器的构造函数参数说明:
IndexDic是索引存放目录
PanGuAnalyzer是盘古解析器(由于默认的解析器解析能力不强,所以替换为这个)
IsCreate是索引创建方式(true:重新新建索引,false:从旧的索引执行追加)
Lucene.Net.Index.IndexWriter.MaxFieldLength.LIMITED是文件长度是否限制
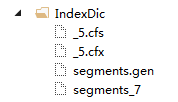
3.索引生成的文件
4.根据关键字搜索
lucene的搜索相当强大,它提供了很多辅助查询类,每个类都继承自Query类,各自完成一种特殊的查询,你可以像搭积木一样将它们任意组合使用,完成一些复杂操 作;另外lucene还提供了Sort类对结果进行排序,提供了Filter类对查询条件进行限制。你或许会不自觉地拿它跟SQL语句进行比 较:“lucene能执行and、or、order by、where、like ‘%xx%’操作吗?”回答是:“当然没问题!”
/// <summary>
/// 从索引搜索结果
/// </summary>
public static List<Article> SearchIndex(string content, string IndexDic)
{
Dictionary<string, string> dic = new Dictionary<string, string>();
try
{
FSDirectory directory = FSDirectory.Open(new DirectoryInfo(IndexDic), new NoLockFactory());
IndexReader reader = IndexReader.Open(directory, true);
IndexSearcher search = new IndexSearcher(reader);
string[] fields = { "Content" }; //创建查询
PerFieldAnalyzerWrapper wrapper = new PerFieldAnalyzerWrapper(new PanGuAnalyzer());
wrapper.AddAnalyzer("Content", new PanGuAnalyzer());
QueryParser parser = new MultiFieldQueryParser(Lucene.Net.Util.Version.LUCENE_30, fields, wrapper);
Query query = parser.Parse(content);
TopScoreDocCollector collector = TopScoreDocCollector.Create(, true);//10--查询条数 search.Search(query, collector);
var hits = collector.TopDocs().ScoreDocs; int numTotalHits = collector.TotalHits;
List<Article> list = new List<Article>();
for (int i = ; i < hits.Length; i++)
{
var hit = hits[i];
Document doc = search.Doc(hit.Doc);
Article model = new Article()
{
Title = doc.Get("Title").ToString(),
Content = doc.Get("Content").ToString(),
AddTime = doc.Get("AddTime").ToString()
};
list.Add(model);
//list.Add(SetHighlighter(dicKeywords, model));
}
return list;
}
catch (Exception ex)
{
throw;
}
}
介绍各种Query
TermQuery: 首先介绍最基本的查询,如果你想执行一个这样的查询:在content字段中查询包含‘刘备的document”,那么你可以用TermQuery
BooleanQuery :如果你想这么查询:在content字段中包含”刘备“并且在title字段包含”三国“的document”,那么你可以建立两个TermQuery并把它们用BooleanQuery连接起来:
WildcardQuery :如果你想对某单词进行通配符查询,你可以用WildcardQuery,通配符包括’?’匹配一个任意字符和’*’匹配零个或多个任意字符,例如你搜索’三国*’,你可能找到’三国演义’或者’三国志’
PhraseQuery :你可能对中日关系比较感兴趣,想查找‘中’和‘日’挨得比较近(5个字的距离内)的文章,超过这个距离的不予考虑,
PrefixQuery :如果你想搜以‘中’开头的词语,你可以用PrefixQuery:
FuzzyQuery :FuzzyQuery用来搜索相似的term,使用Levenshtein算法。
RangeQuery: 另一个常用的Query是RangeQuery,你也许想搜索时间域从20060101到20060130之间的document,你可以用RangeQuery
Lucene.Net3.0.3+盘古分词器学习使用的更多相关文章
- Lucene.Net+盘古分词器(详细介绍)(转)
出处:http://www.cnblogs.com/magicchaiy/archive/2013/06/07/LuceneNet%E7%9B%98%E5%8F%A4%E5%88%86%E8%AF%8 ...
- Lucene.Net+盘古分词器(详细介绍)
本章阅读概要1.Lucenne.Net简介2.介绍盘古分词器3.Lucene.Net实例分析4.结束语(Demo下载)Lucene.Net简介 Lucene.net是Lucene的.net移植版本,是 ...
- 【原创】Lucene.Net+盘古分词器(详细介绍)
本章阅读概要 1.Lucenne.Net简介 2.介绍盘古分词器 3.Lucene.Net实例分析 4.结束语(Demo下载) Lucene.Net简介 Lucene.net是Lucene的.net移 ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- lucene 3.0.2 中文分词
package lia.meetlucene; import java.io.IOException; import java.io.Reader; import java.io.StringRead ...
- Net Core使用Lucene.Net和盘古分词器 实现全文检索
Lucene.net Lucene.net是Lucene的.net移植版本,是一个开源的全文检索引擎开发包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎, ...
- Linux下,非Docker启动Elasticsearch 6.3.0,安装ik分词器插件,以及使用Kibana测试Elasticsearch,
Linux下,非Docker启动Elasticsearch 6.3.0 查看java版本,需要1.8版本 java -version yum -y install java 创建用户,因为elasti ...
- Solr6.5.0配置中文分词器配置
准备工作: solr6.5.0安装成功 1.去官网https://github.com/wks/ik-analyzer下载IK分词器 2.Solr集成IK a)将ik-analyzer-solr6.x ...
随机推荐
- thinkphp 找数据库某个字段为空的数据,PHP 数据调取 空数据
$arr['dingwei'] = array('EXP','is null');
- tensorflow-变量
#计数器 import tensorflow as tf state = tf.Variable(0,name='counter') #设定变量print(state.name) #打印变量one = ...
- Selenium自动化测试插件—Katalon的自述
Katalon-一款好用的selenium自动化测试插件 Selenium 框架是目前使用较广泛的开源自动化框架,一款好的.基于界面的录制工具对于初学者来说可以快速入门:对于老手来说可以提高开发自动化 ...
- [Swift]LeetCode22. 括号生成 | Generate Parentheses
Given n pairs of parentheses, write a function to generate all combinations of well-formed parenthes ...
- [Swift]LeetCode74. 搜索二维矩阵 | Search a 2D Matrix
Write an efficient algorithm that searches for a value in an m x n matrix. This matrix has the follo ...
- [Swift]LeetCode822. 翻转卡片游戏 | Card Flipping Game
On a table are N cards, with a positive integer printed on the front and back of each card (possibly ...
- 注解式controller开发,action找不到controller???
Spring这一列列的 , 配置是真的多,学完我都忘啦 那个配置是干什么的了. 这里我遇到的问题是 我前台 使用action请求controller中的方法时,却找不到 报错404. 首先你路径 ...
- 面试题:合并2个有序数组(leetcode88)
给定两个有序整数数组 nums1 和 nums2,将 nums2 合并到 nums1 中,使得 num1 成为一个有序数组. 说明: 初始化 nums1 和 nums2 的元素数量分别为 m 和 n. ...
- 【机器学习】--线性回归中L1正则和L2正则
一.前述 L1正则,L2正则的出现原因是为了推广模型的泛化能力.相当于一个惩罚系数. 二.原理 L1正则:Lasso Regression L2正则:Ridge Regression 总结: 经验值 ...
- Python内置函数(57)——setattr
英文文档: setattr(object, name, value) This is the counterpart of getattr(). The arguments are an object ...