Redis(Windows安装方法与Java调用实例 & 配置文件参数说明 & Java使用Redis所用Jar包 & Redis与Memcached区别 & redis-cli.exe命令及示例)
Windows下Redis的安装使用
0.前言
因为是初次使用,所以是在windows下进行安装和使用,参考了几篇博客,下面整理一下
1.安装Redis
官方网站:http://redis.io/
官方下载:http://redis.io/download 可以根据需要下载不同版本
windows版:https://github.com/MSOpenTech/redis
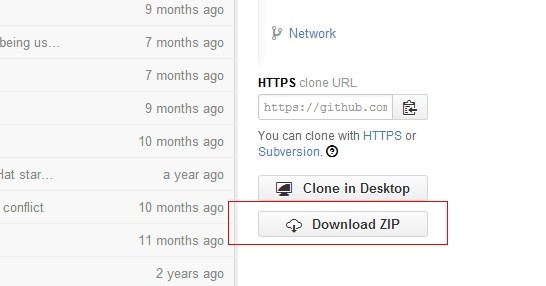
github的资源可以ZIP直接下载的(这个是给不知道的同学友情提示下)
下载完成后 可以右键解压到 某个硬盘下 比如D:\Redis\redis-2.6
在D:\Redis\redis-2.6\bin\release下 有两个zip包 一个32位一个64位
根据自己windows的位数 解压到D:\Redis\redis-2.6 根目录下
2.启动Redis
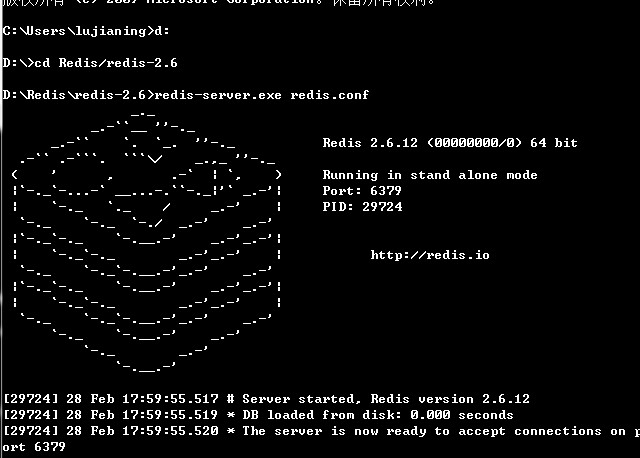
进入redis目录后 开启服务 (注意加上redis.conf)
|
1
|
redis-server.exe redis.conf |
这个窗口要保持开启 关闭时redis服务会自动关闭
redis会自动保存数据到硬盘 所以图中是我第二次开启时 多了一个 DB loaded from disk
3.测试使用

另外开启一个命令行窗口 进入redis目录下 (注意修改自己的ip)
|
1
|
redis-cli.exe -h 192.168.10.61 -p 6379 |
4.Java开发包Jedis
Jedis :http://www.oschina.net/p/jedis (Redis的官方首选Java开发包)
|
1
2
3
4
5
6
7
8
|
<!--Redis --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.0.0</version> <type>jar</type> <scope>compile</scope> </dependency> |
测试例子原帖:http://flychao88.iteye.com/blog/1527163
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
|
package com.lujianing.utils;import org.junit.Before;import org.junit.Test;import redis.clients.jedis.Jedis;import redis.clients.jedis.JedisPool;import redis.clients.jedis.JedisPoolConfig;import java.util.HashMap;import java.util.Iterator;import java.util.List;import java.util.Map;/** * Created by therunningfish on 14-2-28. */public class JedisUtilTest { JedisPool pool; Jedis jedis; @Before public void setUp() { pool = new JedisPool(new JedisPoolConfig(), "192.168.10.61"); jedis = pool.getResource(); // jedis.auth("password"); } @Test public void testGet(){ System.out.println(jedis.get("lu")); } /** * Redis存储初级的字符串 * CRUD */ @Test public void testBasicString(){ //-----添加数据---------- jedis.set("name","minxr");//向key-->name中放入了value-->minxr System.out.println(jedis.get("name"));//执行结果:minxr //-----修改数据----------- //1、在原来基础上修改 jedis.append("name","jarorwar"); //很直观,类似map 将jarorwar append到已经有的value之后 System.out.println(jedis.get("name"));//执行结果:minxrjarorwar //2、直接覆盖原来的数据 jedis.set("name","therunningfish"); System.out.println(jedis.get("name"));//执行结果:therunningfish //删除key对应的记录 jedis.del("name"); System.out.println(jedis.get("name"));//执行结果:null /** * mset相当于 * jedis.set("name","minxr"); * jedis.set("jarorwar","therunningfish"); */ jedis.mset("name","minxr","jarorwar","therunningfish"); System.out.println(jedis.mget("name","jarorwar")); } /** * jedis操作Map */ @Test public void testMap(){ Map<String,String> user=new HashMap<String,String>(); user.put("name","minxr"); user.put("pwd","password"); jedis.hmset("user",user); //取出user中的name,执行结果:[minxr]-->注意结果是一个泛型的List //第一个参数是存入redis中map对象的key,后面跟的是放入map中的对象的key,后面的key可以跟多个,是可变参数 List<String> rsmap = jedis.hmget("user", "name"); System.out.println(rsmap); //删除map中的某个键值// jedis.hdel("user","pwd"); System.out.println(jedis.hmget("user", "pwd")); //因为删除了,所以返回的是null System.out.println(jedis.hlen("user")); //返回key为user的键中存放的值的个数1 System.out.println(jedis.exists("user"));//是否存在key为user的记录 返回true System.out.println(jedis.hkeys("user"));//返回map对象中的所有key [pwd, name] System.out.println(jedis.hvals("user"));//返回map对象中的所有value [minxr, password] Iterator<String> iter=jedis.hkeys("user").iterator(); while (iter.hasNext()){ String key = iter.next(); System.out.println(key+":"+jedis.hmget("user",key)); } } /** * jedis操作List */ @Test public void testList(){ //开始前,先移除所有的内容 jedis.del("java framework"); System.out.println(jedis.lrange("java framework",0,-1)); //先向key java framework中存放三条数据 jedis.lpush("java framework","spring"); jedis.lpush("java framework","struts"); jedis.lpush("java framework","hibernate"); //再取出所有数据jedis.lrange是按范围取出, // 第一个是key,第二个是起始位置,第三个是结束位置,jedis.llen获取长度 -1表示取得所有 System.out.println(jedis.lrange("java framework",0,-1)); } /** * jedis操作Set */ @Test public void testSet(){ //添加 jedis.sadd("sname","minxr"); jedis.sadd("sname","jarorwar"); jedis.sadd("sname","therunningfish"); jedis.sadd("sanme","noname"); //移除noname jedis.srem("sname","noname"); System.out.println(jedis.smembers("sname"));//获取所有加入的value System.out.println(jedis.sismember("sname", "minxr"));//判断 minxr 是否是sname集合的元素 System.out.println(jedis.srandmember("sname")); System.out.println(jedis.scard("sname"));//返回集合的元素个数 } @Test public void test() throws InterruptedException { //keys中传入的可以用通配符 System.out.println(jedis.keys("*")); //返回当前库中所有的key [sose, sanme, name, jarorwar, foo, sname, java framework, user, braand] System.out.println(jedis.keys("*name"));//返回的sname [sname, name] System.out.println(jedis.del("sanmdde"));//删除key为sanmdde的对象 删除成功返回1 删除失败(或者不存在)返回 0 System.out.println(jedis.ttl("sname"));//返回给定key的有效时间,如果是-1则表示永远有效 jedis.setex("timekey", 10, "min");//通过此方法,可以指定key的存活(有效时间) 时间为秒 Thread.sleep(5000);//睡眠5秒后,剩余时间将为<=5 System.out.println(jedis.ttl("timekey")); //输出结果为5 jedis.setex("timekey", 1, "min"); //设为1后,下面再看剩余时间就是1了 System.out.println(jedis.ttl("timekey")); //输出结果为1 System.out.println(jedis.exists("key"));//检查key是否存在 System.out.println(jedis.rename("timekey","time")); System.out.println(jedis.get("timekey"));//因为移除,返回为null System.out.println(jedis.get("time")); //因为将timekey 重命名为time 所以可以取得值 min //jedis 排序 //注意,此处的rpush和lpush是List的操作。是一个双向链表(但从表现来看的) jedis.del("a");//先清除数据,再加入数据进行测试 jedis.rpush("a", "1"); jedis.lpush("a","6"); jedis.lpush("a","3"); jedis.lpush("a","9"); System.out.println(jedis.lrange("a",0,-1));// [9, 3, 6, 1] System.out.println(jedis.sort("a")); //[1, 3, 6, 9] //输入排序后结果 System.out.println(jedis.lrange("a",0,-1)); }} |
Redis会定时 保存数据到硬盘上

=========================================================================================
配置文件参数说明:
1. Redis默认不是以守护进程的方式运行,可以通过该配置项修改,使用yes启用守护进程
daemonize no
2. 当Redis以守护进程方式运行时,Redis默认会把pid写入/var/run/redis.pid文件,可以通过pidfile指定
pidfile /var/run/redis.pid
3. 指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
port 6379
4. 绑定的主机地址
bind 127.0.0.1
5.当 客户端闲置多长时间后关闭连接,如果指定为0,表示关闭该功能
timeout 300
6. 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
loglevel verbose
7. 日志记录方式,默认为标准输出,如果配置Redis为守护进程方式运行,而这里又配置为日志记录方式为标准输出,则日志将会发送给/dev/null
logfile stdout
8. 设置数据库的数量,默认数据库为0,可以使用SELECT <dbid>命令在连接上指定数据库id
databases 16
9. 指定在多长时间内,有多少次更新操作,就将数据同步到数据文件,可以多个条件配合
save <seconds> <changes>
Redis默认配置文件中提供了三个条件:
save 900 1
save 300 10
save 60 10000
分别表示900秒(15分钟)内有1个更改,300秒(5分钟)内有10个更改以及60秒内有10000个更改。
10. 指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
rdbcompression yes
11. 指定本地数据库文件名,默认值为dump.rdb
dbfilename dump.rdb
12. 指定本地数据库存放目录
dir ./
13. 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
slaveof <masterip> <masterport>
14. 当master服务设置了密码保护时,slav服务连接master的密码
masterauth <master-password>
15. 设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过AUTH <password>命令提供密码,默认关闭
requirepass foobared
16. 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
maxclients 128
17. 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
maxmemory <bytes>
18. 指定是否在每次更新操作后进行日志记录,Redis在默认情况下是异步的把数据写入磁盘,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为 redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认为no
appendonly no
19. 指定更新日志文件名,默认为appendonly.aof
appendfilename appendonly.aof
20. 指定更新日志条件,共有3个可选值:
no:表示等操作系统进行数据缓存同步到磁盘(快)
always:表示每次更新操作后手动调用fsync()将数据写到磁盘(慢,安全)
everysec:表示每秒同步一次(折衷,默认值)
appendfsync everysec
21. 指定是否启用虚拟内存机制,默认值为no,简单的介绍一下,VM机制将数据分页存放,由Redis将访问量较少的页即冷数据swap到磁盘上,访问多的页面由磁盘自动换出到内存中(在后面的文章我会仔细分析Redis的VM机制)
vm-enabled no
22. 虚拟内存文件路径,默认值为/tmp/redis.swap,不可多个Redis实例共享
vm-swap-file /tmp/redis.swap
23. 将所有大于vm-max-memory的数据存入虚拟内存,无论vm-max-memory设置多小,所有索引数据都是内存存储的(Redis的索引数据 就是keys),也就是说,当vm-max-memory设置为0的时候,其实是所有value都存在于磁盘。默认值为0
vm-max-memory 0
24. Redis swap文件分成了很多的page,一个对象可以保存在多个page上面,但一个page上不能被多个对象共享,vm-page-size是要根据存储的 数据大小来设定的,作者建议如果存储很多小对象,page大小最好设置为32或者64bytes;如果存储很大大对象,则可以使用更大的page,如果不 确定,就使用默认值
vm-page-size 32
25. 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。
vm-pages 134217728
26. 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4
27. 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
glueoutputbuf yes
28. 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
29. 指定是否激活重置哈希,默认为开启(后面在介绍Redis的哈希算法时具体介绍)
activerehashing yes
30. 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件
include /path/to/local.conf
Java使用Redis所用Jar包
Redis与Memcached的区别
比较Redis与Memcached的区别,大多数都会得到以下观点:
1 Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2 Redis支持数据的备份,即master-slave模式的数据备份。
3 Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
抛开这些,可以深入到Redis内部构造去观察更加本质的区别,理解Redis的设计。
在Redis中,并不是所有的数据都一直存储在内存中的。这是和Memcached相比一个最大的区别。Redis只会缓存所有的 key的信息,如果Redis发现内存的使用量超过了某一个阀值,将触发swap的操作,Redis根据“swappability = age*log(size_in_memory)”计 算出哪些key对应的value需要swap到磁盘。然后再将这些key对应的value持久化到磁盘中,同时在内存中清除。这种特性使得Redis可以 保持超过其机器本身内存大小的数据。当然,机器本身的内存必须要能够保持所有的key,毕竟这些数据是不会进行swap操作的。同时由于Redis将内存 中的数据swap到磁盘中的时候,提供服务的主线程和进行swap操作的子线程会共享这部分内存,所以如果更新需要swap的数据,Redis将阻塞这个 操作,直到子线程完成swap操作后才可以进行修改。
使用Redis特有内存模型前后的情况对比:
VM off: 300k keys, 4096 bytes values: 1.3G used
VM on: 300k keys, 4096 bytes values: 73M used
VM off: 1 million keys, 256 bytes values: 430.12M used
VM on: 1 million keys, 256 bytes values: 160.09M used
VM on: 1 million keys, values as large as you want, still: 160.09M used
当 从Redis中读取数据的时候,如果读取的key对应的value不在内存中,那么Redis就需要从swap文件中加载相应数据,然后再返回给请求方。 这里就存在一个I/O线程池的问题。在默认的情况下,Redis会出现阻塞,即完成所有的swap文件加载后才会相应。这种策略在客户端的数量较小,进行 批量操作的时候比较合适。但是如果将Redis应用在一个大型的网站应用程序中,这显然是无法满足大并发的情况的。所以Redis运行我们设置I/O线程 池的大小,对需要从swap文件中加载相应数据的读取请求进行并发操作,减少阻塞的时间。
如果希望在海量数据的环境中使用好Redis,我相信理解Redis的内存设计和阻塞的情况是不可缺少的。
补充的知识点:
memcached和redis的比较
1 网络IO模型
Memcached是多线程,非阻塞IO复用的网络模型,分为监听主线程和worker子线程,监听线程监听网络连接,接受请求后,将连接描述字pipe 传递给worker线程,进行读写IO, 网络层使用libevent封装的事件库,多线程模型可以发挥多核作用,但是引入了cache coherency和锁的问题,比如,Memcached最常用的stats 命令,实际Memcached所有操作都要对这个全局变量加锁,进行计数等工作,带来了性能损耗。
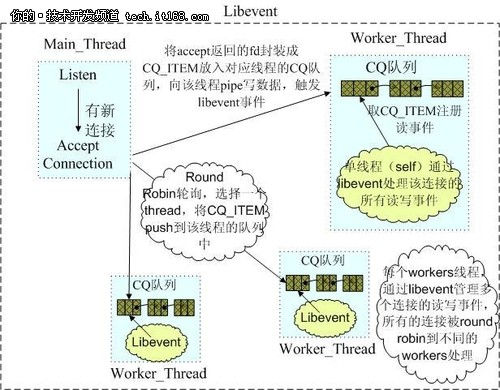
(Memcached网络IO模型)
Redis使用单线程的IO复用模型,自己封装了一个简单的AeEvent事件处理框架,主要实现了epoll、kqueue和select,对于单纯只有IO操作来说,单线程可以将速度优势发挥到最大,但是Redis也提供了一些简单的计算功能,比如排序、聚合等,对于这些操作,单线程模型实际会严重影响整体吞吐量,CPU计算过程中,整个IO调度都是被阻塞住的。
2.内存管理方面
Memcached使用预分配的内存池的方式,使用slab和大小不同的chunk来管理内存,Item根据大小选择合适的chunk存储,内存池的方式可以省去申请/释放内存的开销,并且能减小内存碎片产生,但这种方式也会带来一定程度上的空间浪费,并且在内存仍然有很大空间时,新的数据也可能会被剔除,原因可以参考Timyang的文章:http://timyang.net/data/Memcached-lru-evictions/
Redis使用现场申请内存的方式来存储数据,并且很少使用free-list等方式来优化内存分配,会在一定程度上存在内存碎片,Redis跟据存储命令参数,会把带过期时间的数据单独存放在一起,并把它们称为临时数据,非临时数据是永远不会被剔除的,即便物理内存不够,导致swap也不会剔除任何非临时数据(但会尝试剔除部分临时数据),这点上Redis更适合作为存储而不是cache。
3.数据一致性问题
Memcached提供了cas命令,可以保证多个并发访问操作同一份数据的一致性问题。 Redis没有提供cas 命令,并不能保证这点,不过Redis提供了事务的功能,可以保证一串 命令的原子性,中间不会被任何操作打断。
4.存储方式及其它方面
Memcached基本只支持简单的key-value存储,不支持枚举,不支持持久化和复制等功能
Redis除key/value之外,还支持list,set,sorted set,hash等众多数据结构,提供了KEYS
进行枚举操作,但不能在线上使用,如果需要枚举线上数据,Redis提供了工具可以直接扫描其dump文件,枚举出所有数据,Redis还同时提供了持久化和复制等功能。
5.关于不同语言的客户端支持
在不同语言的客户端方面,Memcached和Redis都有丰富的第三方客户端可供选择,不过因为Memcached发展的时间更久一些,目前看在客户端支持方面,Memcached的很多客户端更加成熟稳定,而Redis由于其协议本身就比Memcached复杂,加上作者不断增加新的功能等,对应第三方客户端跟进速度可能会赶不上,有时可能需要自己在第三方客户端基础上做些修改才能更好的使用。
根据以上比较不难看出,当我们不希望数据被踢出,或者需要除key/value之外的更多数据类型时,或者需要落地功能时,使用Redis比使用Memcached更合适。
关于Redis的一些周边功能
Redis除了作为存储之外还提供了一些其它方面的功能,比如聚合计算、pubsub、scripting等,对于此类功能需要了解其实现原理,清楚地了解到它的局限性后,才能正确的使用,比如pubsub功能,这个实际是没有任何持久化支持的,消费方连接闪断或重连之间过来的消息是会全部丢失的,又比如聚合计算和scripting等功能受Redis单线程模型所限,是不可能达到很高的吞吐量的,需要谨慎使用。
总的来说Redis作者是一位非常勤奋的开发者,可以经常看到作者在尝试着各种不同的新鲜想法和思路,针对这些方面的功能就要求我们需要深入了解后再使用。
总结:
1.Redis使用最佳方式是全部数据in-memory。
2.Redis更多场景是作为Memcached的替代者来使用。
3.当需要除key/value之外的更多数据类型支持时,使用Redis更合适。
4.当存储的数据不能被剔除时,使用Redis更合适。
=========================================================================================
redis-cli.exe命令及示例
Redis提供了丰富的命令(command)对数据库和各种数据类型进行操作,这些command可以在Linux终端使用。在编程时,比如使用Redis 的Java语言包,这些命令都有对应的方法。下面将Redis提供的命令做一总结。
官网命令列表:http://redis.io/commands
1、连接操作相关的命令
quit:关闭连接(connection)
auth:简单密码认证
2、对value操作的命令
exists(key):确认一个key是否存在
del(key):删除一个key
type(key):返回值的类型
keys(pattern):返回满足给定pattern的所有key
randomkey:随机返回key空间的一个key
rename(oldname, newname):将key由oldname重命名为newname,若newname存在则删除newname表示的key
dbsize:返回当前数据库中key的数目
expire:设定一个key的活动时间(s)
ttl:获得一个key的活动时间
select(index):按索引查询
move(key, dbindex):将当前数据库中的key转移到有dbindex索引的数据库
flushdb:删除当前选择数据库中的所有key
flushall:删除所有数据库中的所有key
3、对String操作的命令
set(key, value):给数据库中名称为key的string赋予值value
get(key):返回数据库中名称为key的string的value
getset(key, value):给名称为key的string赋予上一次的value
mget(key1, key2,…, key N):返回库中多个string(它们的名称为key1,key2…)的value
setnx(key, value):如果不存在名称为key的string,则向库中添加string,名称为key,值为value
setex(key, time, value):向库中添加string(名称为key,值为value)同时,设定过期时间time
mset(key1, value1, key2, value2,…key N, value N):同时给多个string赋值,名称为key i的string赋值value i
msetnx(key1, value1, key2, value2,…key N, value N):如果所有名称为key i的string都不存在,则向库中添加string,名称key i赋值为value i
incr(key):名称为key的string增1操作
incrby(key, integer):名称为key的string增加integer
decr(key):名称为key的string减1操作
decrby(key, integer):名称为key的string减少integer
append(key, value):名称为key的string的值附加value
substr(key, start, end):返回名称为key的string的value的子串
4、对List操作的命令
rpush(key, value):在名称为key的list尾添加一个值为value的元素
lpush(key, value):在名称为key的list头添加一个值为value的 元素
llen(key):返回名称为key的list的长度
lrange(key, start, end):返回名称为key的list中start至end之间的元素(下标从0开始,下同)
ltrim(key, start, end):截取名称为key的list,保留start至end之间的元素
lindex(key, index):返回名称为key的list中index位置的元素
lset(key, index, value):给名称为key的list中index位置的元素赋值为value
lrem(key, count, value):删除count个名称为key的list中值为value的元素。count为0,删除所有值为value的元素,count>0从 头至尾删除count个值为value的元素,count<0从尾到头删除|count|个值为value的元素。 lpop(key):返回并删除名称为key的list中的首元素 rpop(key):返回并删除名称为key的list中的尾元素 blpop(key1, key2,… key N, timeout):lpop命令的block版本。即当timeout为0时,若遇到名称为key i的list不存在或该list为空,则命令结束。如果timeout>0,则遇到上述情况时,等待timeout秒,如果问题没有解决,则对 keyi+1开始的list执行pop操作。
brpop(key1, key2,… key N, timeout):rpop的block版本。参考上一命令。
rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
5、对Set操作的命令
sadd(key, member):向名称为key的set中添加元素member
srem(key, member) :删除名称为key的set中的元素member
spop(key) :随机返回并删除名称为key的set中一个元素
smove(srckey, dstkey, member) :将member元素从名称为srckey的集合移到名称为dstkey的集合
scard(key) :返回名称为key的set的基数
sismember(key, member) :测试member是否是名称为key的set的元素
sinter(key1, key2,…key N) :求交集
sinterstore(dstkey, key1, key2,…key N) :求交集并将交集保存到dstkey的集合
sunion(key1, key2,…key N) :求并集
sunionstore(dstkey, key1, key2,…key N) :求并集并将并集保存到dstkey的集合
sdiff(key1, key2,…key N) :求差集
sdiffstore(dstkey, key1, key2,…key N) :求差集并将差集保存到dstkey的集合
smembers(key) :返回名称为key的set的所有元素
srandmember(key) :随机返回名称为key的set的一个元素
6、对zset(sorted set)操作的命令
zadd(key, score, member):向名称为key的zset中添加元素member,score用于排序。如果该元素已经存在,则根据score更新该元素的顺序。
zrem(key, member) :删除名称为key的zset中的元素member
zincrby(key, increment, member) :如果在名称为key的zset中已经存在元素member,则该元素的score增加increment;否则向集合中添加该元素,其score的值为increment
zrank(key, member) :返回名称为key的zset(元素已按score从小到大排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
zrevrank(key, member) :返回名称为key的zset(元素已按score从大到小排序)中member元素的rank(即index,从0开始),若没有member元素,返回“nil”
zrange(key, start, end):返回名称为key的zset(元素已按score从小到大排序)中的index从start到end的所有元素
zrevrange(key, start, end):返回名称为key的zset(元素已按score从大到小排序)中的index从start到end的所有元素
zrangebyscore(key, min, max):返回名称为key的zset中score >= min且score <= max的所有元素 zcard(key):返回名称为key的zset的基数 zscore(key, element):返回名称为key的zset中元素element的score zremrangebyrank(key, min, max):删除名称为key的zset中rank >= min且rank <= max的所有元素 zremrangebyscore(key, min, max) :删除名称为key的zset中score >= min且score <= max的所有元素
zunionstore / zinterstore(dstkeyN, key1,…,keyN, WEIGHTS w1,…wN, AGGREGATE SUM|MIN|MAX):对N个zset求并集和交集,并将最后的集合保存在dstkeyN中。对于集合中每一个元素的score,在进行 AGGREGATE运算前,都要乘以对于的WEIGHT参数。如果没有提供WEIGHT,默认为1。默认的AGGREGATE是SUM,即结果集合中元素 的score是所有集合对应元素进行SUM运算的值,而MIN和MAX是指,结果集合中元素的score是所有集合对应元素中最小值和最大值。
7、对Hash操作的命令
hset(key, field, value):向名称为key的hash中添加元素field<—>value
hget(key, field):返回名称为key的hash中field对应的value
hmget(key, field1, …,field N):返回名称为key的hash中field i对应的value
hmset(key, field1, value1,…,field N, value N):向名称为key的hash中添加元素field i<—>value i
hincrby(key, field, integer):将名称为key的hash中field的value增加integer
hexists(key, field):名称为key的hash中是否存在键为field的域
hdel(key, field):删除名称为key的hash中键为field的域
hlen(key):返回名称为key的hash中元素个数
hkeys(key):返回名称为key的hash中所有键
hvals(key):返回名称为key的hash中所有键对应的value
hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
8、持久化
save:将数据同步保存到磁盘
bgsave:将数据异步保存到磁盘
lastsave:返回上次成功将数据保存到磁盘的Unix时戳
shundown:将数据同步保存到磁盘,然后关闭服务
9、远程服务控制
info:提供服务器的信息和统计
monitor:实时转储收到的请求
slaveof:改变复制策略设置
config:在运行时配置Redis服务器
命令示例
1. KEYS/RENAME/DEL/EXISTS/MOVE/RENAMENX:
#在Shell命令行下启动Redis客户端工具。
/> redis-cli
#清空当前选择的数据库,以便于对后面示例的理解。
redis 127.0.0.1:6379> flushdb
OK
#添加String类型的模拟数据。
redis 127.0.0.1:6379> set mykey 2
OK
redis 127.0.0.1:6379> set mykey2 "hello"
OK
#添加Set类型的模拟数据。
redis 127.0.0.1:6379> sadd mysetkey 1 2 3
(integer) 3
#添加Hash类型的模拟数据。
redis 127.0.0.1:6379> hset mmtest username "stephen"
(integer) 1
#根据参数中的模式,获取当前数据库中符合该模式的所有key,从输出可以看出,该命令在执行时并不区分与Key关联的Value类型。
redis 127.0.0.1:6379> keys my*
1) "mysetkey"
2) "mykey"
3) "mykey2"
#删除了两个Keys。
redis 127.0.0.1:6379> del mykey mykey2
(integer) 2
#查看一下刚刚删除的Key是否还存在,从返回结果看,mykey确实已经删除了。
redis 127.0.0.1:6379> exists mykey
(integer) 0
#查看一下没有删除的Key,以和上面的命令结果进行比较。
redis 127.0.0.1:6379> exists mysetkey
(integer) 1
#将当前数据库中的mysetkey键移入到ID为1的数据库中,从结果可以看出已经移动成功。
redis 127.0.0.1:6379> move mysetkey 1
(integer) 1
#打开ID为1的数据库。
redis 127.0.0.1:6379> select 1
OK
#查看一下刚刚移动过来的Key是否存在,从返回结果看已经存在了。
redis 127.0.0.1:6379[1]> exists mysetkey
(integer) 1
#在重新打开ID为0的缺省数据库。
redis 127.0.0.1:6379[1]> select 0
OK
#查看一下刚刚移走的Key是否已经不存在,从返回结果看已经移走。
redis 127.0.0.1:6379> exists mysetkey
(integer) 0
#准备新的测试数据。
redis 127.0.0.1:6379> set mykey "hello"
OK
#将mykey改名为mykey1
redis 127.0.0.1:6379> rename mykey mykey1
OK
#由于mykey已经被重新命名,再次获取将返回nil。
redis 127.0.0.1:6379> get mykey
(nil)
#通过新的键名获取。
redis 127.0.0.1:6379> get mykey1
"hello"
#由于mykey已经不存在了,所以返回错误信息。
redis 127.0.0.1:6379> rename mykey mykey1
(error) ERR no such key
#为renamenx准备测试key
redis 127.0.0.1:6379> set oldkey "hello"
OK
redis 127.0.0.1:6379> set newkey "world"
OK
#由于newkey已经存在,因此该命令未能成功执行。
redis 127.0.0.1:6379> renamenx oldkey newkey
(integer) 0
#查看newkey的值,发现它也没有被renamenx覆盖。
redis 127.0.0.1:6379> get newkey
"world"
2. PERSIST/EXPIRE/EXPIREAT/TTL:
#为后面的示例准备的测试数据。
redis 127.0.0.1:6379> set mykey "hello"
OK
#将该键的超时设置为100秒。
redis 127.0.0.1:6379> expire mykey 100
(integer) 1
#通过ttl命令查看一下还剩下多少秒。
redis 127.0.0.1:6379> ttl mykey
(integer) 97
#立刻执行persist命令,该存在超时的键变成持久化的键,即将该Key的超时去掉。
redis 127.0.0.1:6379> persist mykey
(integer) 1
#ttl的返回值告诉我们,该键已经没有超时了。
redis 127.0.0.1:6379> ttl mykey
(integer) -1
#为后面的expire命令准备数据。
redis 127.0.0.1:6379> del mykey
(integer) 1
redis 127.0.0.1:6379> set mykey "hello"
OK
#设置该键的超时被100秒。
redis 127.0.0.1:6379> expire mykey 100
(integer) 1
#用ttl命令看一下当前还剩下多少秒,从结果中可以看出还剩下96秒。
redis 127.0.0.1:6379> ttl mykey
(integer) 96
#重新更新该键的超时时间为20秒,从返回值可以看出该命令执行成功。
redis 127.0.0.1:6379> expire mykey 20
(integer) 1
#再用ttl确认一下,从结果中可以看出果然被更新了。
redis 127.0.0.1:6379> ttl mykey
(integer) 17
#立刻更新该键的值,以使其超时无效。
redis 127.0.0.1:6379> set mykey "world"
OK
#从ttl的结果可以看出,在上一条修改该键的命令执行后,该键的超时也无效了。
redis 127.0.0.1:6379> ttl mykey
(integer) -1
3. TYPE/RANDOMKEY/SORT:
#由于mm键在数据库中不存在,因此该命令返回none。
redis 127.0.0.1:6379> type mm
none
#mykey的值是字符串类型,因此返回string。
redis 127.0.0.1:6379> type mykey
string
#准备一个值是set类型的键。
redis 127.0.0.1:6379> sadd mysetkey 1 2
(integer) 2
#mysetkey的键是set,因此返回字符串set。
redis 127.0.0.1:6379> type mysetkey
set
#返回数据库中的任意键。
redis 127.0.0.1:6379> randomkey
"oldkey"
#清空当前打开的数据库。
redis 127.0.0.1:6379> flushdb
OK
#由于没有数据了,因此返回nil。
redis 127.0.0.1:6379> randomkey
(nil)
=========================================================================================
Redis(Windows安装方法与Java调用实例 & 配置文件参数说明 & Java使用Redis所用Jar包 & Redis与Memcached区别 & redis-cli.exe命令及示例)的更多相关文章
- 梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python) http://blog.csdn.net/liulingyuan6/article/details ...
- Redis windows安装配置与Jedis访问数据库
一 Redis概要 Redis是一个开源的使用ANSI C语言编写.遵守BSD协议.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API.它通常被称为数据结构服务器 ...
- Redis Windows 安装
摘自:https://www.cnblogs.com/M-LittleBird/p/5902850.html 一.下载windows版本的Redis 去官网找了很久,发现原来在官网上可以下载的wind ...
- redis windows安装与liunx安装
windows安装redis 2.把安装包放在Linux文件系统下,利用WinSCP工具 3.解压缩 tar -zxf redis-4.0.2.tar.gz 4.切换到解压后的目录 cd redis- ...
- redis windows 安装流程
https://blog.csdn.net/u012343297/article/details/78839063 1,redis官方下载地址:https://redis.io/download,re ...
- redis windows 安装 下载 常用参数
下载地址 https://github.com/ServiceStack/redis-windows/tree/master/downloads 安装可视化工具 RedisDesktopManager ...
- redis windows安装
下载:https://github.com/MicrosoftArchive/redis/releases 命令行启动:redis-server.exe redis.windows.conf 以服务启 ...
- JAVA 调用https接口, java.security.cert.CertificateException
package com.easycare.store.util; import java.security.cert.CertificateException; import java.securit ...
- Java 测试连接Oracle数据库是否成功,ojdbc7.jar包下载
需要用到的jar 包: 链接:https://pan.baidu.com/s/1I1pC2f81IvbphZ6tWpVFOg 密码:uq0u 测试结果: package pkg; import jav ...
随机推荐
- Kyle 的 iOS 面试题
1.简单介绍下你对swizzling方法的了解,一般你什么时候使用. 2.有三个对象 A,B,C..:A retain B, B retain C, C retain B..当 A release B ...
- 【Linux】CentOS7上rpm命令批量卸载删除模糊rpm包名
例如,我要删除如下文件名匹配上wine的所有文件
- UVa11988 Broken Keyboard(练习链表使用)
向量和数组的优势是可以随机的存取元素和在末尾添加删除元素,而当插入元素时,需要移动大量的数据,消耗大量的时间.而链表的优势是可以在O(1)删除和插入数据.所以在频繁移动元素时,可以使用链表. 分析:如 ...
- DELLR720服务器更换硬盘,启动系统报错:there are offline or missing virtual drivers with preserved cache
linux系统启动过程中给出错误: There are offline or missing virtual drives with preserved cache. Please check the ...
- django网站安全学习记录
现在比较流行的网站攻击方式有sql注入,xss跨站脚本攻击,csrf跨站请求伪造,一句话木马等等 django非常强大,对这些攻击都做了防范 sql注入,通过在sql语句中插入非法的sql语句来实现爆 ...
- 速查笔记(Linux Shell编程<上>)
转载自: http://www.cnblogs.com/stephen-liu74/archive/2011/11/01/2202027.html 零.shell中的内部变量: 1. $?: ...
- android-SQLite数据库MVC关联实例源码(三层架构)
前两天布置下了一个期末练习,其中的重点是两个表之间的SQLite关联操作. 拿到题目,首先需要建库和关联表,下面是代码. 我使用简单的表插入,将数据的提交卸载onCreate方法中,这样不会发生写在主 ...
- 开关按钮(ToggleButton&Switch)
开关按钮,很实用的小东西. 下面上实例: -------------------------------我是邪恶的分割线--------------------------------------- ...
- Import CSV into DB using SSIS
Step 1: create a table CREATE TABLE [EmployeeImported]( ,) NOT NULL, [ContactID] [int] NOT NULL, [Ma ...
- 【Excle数据透视表】如何在数据透视表顶部显示列总计数据
解决方案 创建组并修改组名称为“合计” 如下图:原始数据透视表 步骤 选中列标签区域→右键→组合 修改组合的名称为“合计” 此时底部会有一个合计汇总项,只需要单击数据透视表任意单元格→数据透视表工具→ ...