HBase 相关API操练(三):MapReduce操作HBase
MapReduce 操作 HBase
在 HBase 系统上运行批处理运算,最方便和实用的模型依然是 MapReduce,如下图所示。
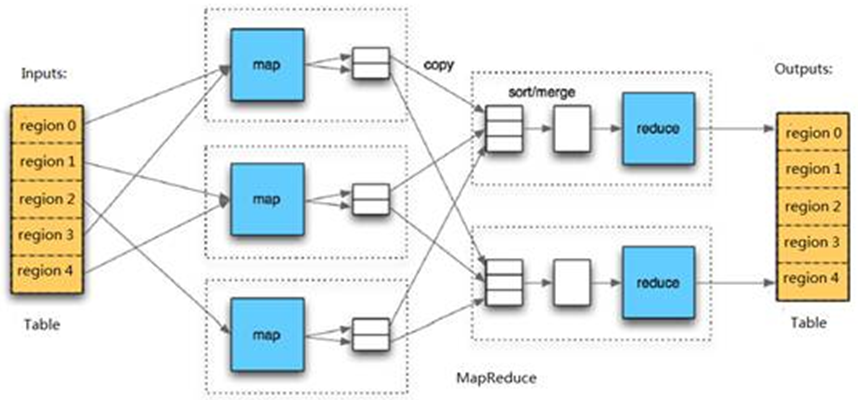
HBase Table 和 Region 的关系类似 HDFS File 和 Block 的关系,HBase提供配套的 TableInputFormat 和 TableOutputFormat API,可以方便地将 HBase Table 作为 Hadoop MapReduce 的Source 和 Sink。对于 MapReduce Job 应用开发人员来说,基本不需要关注 HBase 系统本身的细节。
org.apache.hadoop.hbase.mapreduce 包中的类和工具用来将 HBase 作为 MapReduce 作业的输出
1、 HBaseConfiguration 类
org.apache.hadoop.hbase.HbaseConfiguration
继承了 org.apache.hadoop.conf.Configuration 类, 创建一个 HBaseConfiguration 对象实例,会返回读入 CLASSPATH 下 hbase-site.xml 文件和hbase-default.xml 文件中 HBase 配置信息的一个 Configuration,该Configuration 接下来会用于 创建 HBaseAdmin 和 HTable 实例。
HBaseAdmin 和 HTable 两个类在 org.apache.hadoop.hbase.client 包中,HBaseAdmin 用于管理 HBase 集群、添加和删除表,HTable 用于访问指定的表,Configuration 实例指向了执行这些代码的集群上的这些类。
2、 HtableDescriptor 类和 HColumnDescriptor 类
HBase 中表结构由 HTableDescriptor 描述(包括 HColumnDescriptor),对表的新增、修改、删除操作在接口 HMasterInterface 中定义,而该接口由 HMaster 实现。
HTabledescriptor包含:
1)表名、byte[] 和 String 格式。
2)表的元信息,以Key-Value形式存储。存储信息包括文件最大的大小(默认256MB)、是否只读、Flush 时内存占用大小(默认64MB)、是否 root 或 Meta Region、DEFERRED_LOG_FLUSH。
3)表的各 Family 描述 HColumnDescriptor。
HColumnDescriptor 描述 Column Family 的信息,包括:
1)压缩格式(不压缩或仅压缩 Value、压缩 Block 中的一系列记录)。
2)数据的版本数量。
3)Block 的大小。
4)是否在内存中。
5)是否 Cache Block。
6)是否使用 bloomfilter。
7)Cell 内容的存活时间。
8)是否复制。
当一个 Column Family 创建后,其参数不能修改,除非删除该 Column Family 后新建一个, 但删除 Column Family 也会删除该 Column Family 下的数据。另外,HTableDescriptor 中包含 ROOT_TABLEDESC 和 META_TABLEDESC 两个实例以描述-ROOT- 和 .META 表。
1)ROOT_TABLEDESC 包含一个 info 的 Column Family。
2)META_TABLEDESC 包含一个 info 和 historian,两个 Column Family。
3、 CreateTable 方法
如果指定 Split Key 为该 Table 按指定键初始创建多个 Region,否则仅创建一个 Region,过程如下。
1) 为 Table 创建 HRegionInfo
2) 判断是不是所有的 Meta Region 都 online(由 RegionManager 的 MetaScanner 扫描线程分配 Meta Region)。
3) 判断 ServerManager 是否有足够 Region Server 来创建 table。
从 RegionManager 的 online MetaRegion 查找该 HRegionInfo 应放入哪一个 MetaRegion 中,在 onlineMetaRegion 中查找仅比RegionName 小的 MetaRegion,而RegionName 由 tableName、起始 Key 和 regionId(root 为0,meta 为1,user 当前时间)组成,同时 Master 的 ServerConnection 获取 HRegionInterface 代理连接到该 MetaRegion,并查找对应该 Table 为 Key 的记录是否存在,若存在则报错该表已经存在,由 RegionManager 根据 HRegionInfo 创建新的 user。Region 在 rootDir 目录下 新建以 tableName 为名的目录,在 tableName 目录下新建一个 Region 的目录(经编码后的 RegionName),并新建一个 HRegion 对象。
disable、enable 和 delete 等操作封装在继承自 TableOperation 的类中,该类先获得要操作表的所有 MetaRegion,扫描这些 MetaRegion 中 所有该表的 user Region 信息并做相应处理,最后处理 MetaRegion。
4、 TableInputFormat 类
通过设置 conf.set(TableInputFormat.INPUT_TABLE,"tableName") 设定 HBase 的输入表,tableName 为表名。
设置 conf.set(TableInputFormat.SCAN,TableMRUtil.convertScanToString(scan)),设定对 HBase 输入表的 scan 方式。
setTable(new HTable(new Configuration(conf),tableName));
通过 TableInputFormat.setConf(Configuration conf) 方法初始化 scan 对象;scan 对象是从 Job 中设置的对象,以字符串的形式传给 TableInputFormat,在 TableInputFormat 内部将 scan 字符串转换为 scan 对象,操作如下。
scan = TableMapReduceUtil.convertStringtoScan(conf.get(SCAN))
TableInputFormat 继承 TableInputFormatBase 实现了 InputFormat 抽象类的两个抽象方法 getSplits() 和 createRecordReader()。
getSplits() 判定输入对象的切分原则,原则是对于 TableInputFormatBase,会遍历HBase 相应表的所有 HRegion,每一个 HRegion 都会被切分成一个 Split,所以切分的块数与表中 HRegion 的数目是相同的,代码如下。
InputSplit split = new TableSplit(table.getTableName(),splitStart,splitStop,regionLocation);
在 Split 中只会记载 HRegion 的起始 Row Key 和 结束Row Key,具体去读取这片区域的数据是 createRecordReader() 实现的。
对于一个 Map 任务,JobTracker 会考虑 TaskTracker 的网络位置,并选取一个距离其输入分片文件的最近的 TaskTracker。在理想情况下,任务是数据本地化的(data-local), 也就是任务运行在输入分片所在的节点上。同样,任务也可能是机器本地化的;任务和输入分片在同一个机架,但不在同一个节点上。
对于Reduce 任务,JobTracker 简单地从待运行的 Reduce 任务列表中选取下一个来运行,用不着考虑数据段本地化。
createRecordReader() 按照必然格式读取响应数据,接受 Split 块,返回读取记录的结果,操作代码如下。
public RecordReader< ImmutableBytesWritable,Result> createRecordReader(InputSplit split,TaskAttemptContext context){
Scan scan = new Scan(this.scan);
scan.setStartRow(tableSplit.getStartRow());
scan.setStopRow(tableSplit.getEndRow());
tableRecorderReader.setScan(scan);
tableRecorderReader.setHTable(table);
tableRecorderReader.init();
return tableRecorderReader;
}
tableRecorderReader.init() 返回的是这个分块的起始 Row Key 的记录;RecordReader 将一个 Split 解析成 < Key, Value> 的形式 提供给 map 函数,Key 就是Row Key,Value 就是对应的一行数据。
RecorderReader 用于在划分中读取 < Key,Value> 对。RecorderReader 有5 个虚方法,下面分别进行介绍。
1、initialize:初始化,输入参数包括该 Reader 工作的数据划分 InputSplit 和 Job 的上下文 context。
2、nextKey:得到输入的下一个 Key,如果数据划分已经没有新的记录,返回空。
3、nextValue:得到 Key 对应的 Value,必须在调用 nextKey 后调用。
4、 getProgress:得到现在的进度。
5、close:来自 java.io 的Closeable 接口,用于清理 RecorderReader。
在 MapReduce 驱动中调用 TableInputFormat 的类:
job.setInputFormatClass(TableInputFormat.class);
使用以下方法就不需要再单独定义。
tableMapReduceUtil.initTableReducerJob("daily_result", DailyReduce.class, job);
initTableReducerJob() 方法完成一系列操作。
1) job.setOutputFormatClass(TableOutputFormat.class);设置输出格式。
2)conf.set(TableOutputFormat.OUTPUT_TABLE,table);设置输出表。
3) 初始化 partition。
向 HBase 中写入数据
本节介绍利用 MapReduce 操作 HBase,首先介绍如何上传数据,借助最熟悉的 WordCount 案例,将 WordCount 的结果存储到 HBase 而不是 HDFS。
输入文件 test.txt 的内容为:
hello hadoop
hadoop is easy
1) 编写 Mapper 函数。
public static class WordCountMapperHbase extends Mapper< Object, Text, ImmutableBytesWritable, IntWritable> {
private final static IntWritable one = new IntWritable();
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
//输出到hbase的key类型为ImmutableBytesWritable
context.write(new ImmutableBytesWritable(Bytes.toBytes(word.toString())), one);
}
}
}
2) 编写 Reducer 类。
public class WordCountReducerHbase extends TableReducer< ImmutableBytesWritable, IntWritable, ImmutableBytesWritable> {
private IntWritable result = new IntWritable();
public void reduce(ImmutableBytesWritable key, Iterable< IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = ;
for (IntWritable val : values) {
sum += val.get();
}
Put put = new Put(key.get());//put 实例化 key代表主键,每个单词存一行
//三个参数分别为 列簇为content,列修饰符为count,列值为词频
put.add(Bytes.toBytes("content"), Bytes.toBytes("count"), Bytes.toBytes(String.valueOf(sum)));
context.write(key , put);
}
}
3) 编写驱动类。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
/**
*
* 将hdfs中的数据导入hbase
*
*/
public class MapReduceWriteHbaseDriver {
public static void main(String[] args)throws Exception {
String tableName = "wordcount";//hbase 数据库表名
Configuration conf=HBaseConfiguration.create(); //实例化Configuration
conf.set("hbase.zookeeper.quorum", "dajiangtai");
conf.set("hbase.zookeeper.property.clientPort", "");//端口号 //如果表已经存在就先删除
HBaseAdmin admin = new HBaseAdmin(conf);
if(admin.tableExists(tableName)){
admin.disableTable(tableName);
admin.deleteTable(tableName);
} HTableDescriptor htd = new HTableDescriptor(tableName);
HColumnDescriptor hcd = new HColumnDescriptor("content");
htd.addFamily(hcd);//创建列簇
admin.createTable(htd);//创建表 Job job=new Job(conf,"import from hdfs to hbase");
job.setJarByClass(MapReduceWriteHbaseDriver.class); job.setMapperClass(WordCountMapperHbase.class); //设置插入hbase时的相关操作
TableMapReduceUtil.initTableReducerJob(tableName, WordCountReducerHbase.class, job, null, null, null, null, false); job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(ImmutableBytesWritable.class);
job.setOutputValueClass(Put.class); FileInputFormat.addInputPaths(job, "hdfs://master:9000/handoop/test/test.txt");
System.exit(job.waitForCompletion(true) ? : ); }
}
从hbase读取数据,输出到hdfs的数据如下所示。
easy
hadoop
hello
is
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
HBase 相关API操练(三):MapReduce操作HBase的更多相关文章
- HBase 相关API操练(一):Shell操作
HBase 为用户提供了一个非常方便的使用方式, 我们称之为“HBase Shell”. HBase Shell 提供了大多数的 HBase 命令, 通过 HBase Shell 用户可以方便地创建. ...
- HBase 相关API操练(二):Java API
一.HBase Java编程 (1)HBase是用Java语言编写的,它支持Java编程: (2)HBase支持CRUD操作:Create,Read,Update和Delete: (3)Java AP ...
- Mapreduce操作HBase
这个操作和普通的Mapreduce还不太一样,比如普通的Mapreduce输入可以是txt文件等,Mapreduce可以直接读取Hive中的表的数据(能够看见是以类似txt文件形式),但Mapredu ...
- 7.MapReduce操作Hbase
7 HBase的MapReduce HBase中Table和Region的关系,有些类似HDFS中File和Block的关系.由于HBase提供了配套的与MapReduce进行交互的API如 Ta ...
- HBase篇--HBase操作Api和Java操作Hbase相关Api
一.前述. Hbase shell启动命令窗口,然后再Hbase shell中对应的api命令如下. 二.说明 Hbase shell中删除键是空格+Ctrl键. 三.代码 1.封装所有的API pa ...
- Hbase理论&&hbase shell&&python操作hbase&&python通过mapreduce操作hbase
一.Hbase搭建: 二.理论知识介绍: 1Hbase介绍: Hbase是分布式.面向列的开源数据库(其实准确的说是面向列族).HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hb ...
- Hbase第五章 MapReduce操作HBase
容易遇到的坑: 当用mapReducer操作HBase时,运行jar包的过程中如果遇到 java.lang.NoClassDefFoundError 类似的错误时,一般是由于hadoop环境没有hba ...
- MapReduce操作Hbase --table2file
官方手册:http://hbase.apache.org/book.html#mapreduce.example 简单的操作,将hbase表中的数据写入到文件中. RunJob 源码: import ...
- hadoop2的mapreduce操作hbase数据
1.从hbase中取数据,再把计算结果插入hbase中 package com.yeliang; import java.io.IOException; import org.apache.hadoo ...
随机推荐
- 【转】Pro Android学习笔记(五三):调试和分析(1):Debug视图和DDMS视图
目录(?)[-] Debug视图 DDMS视图 查看应用运行状态 进入debug状态 HPROF Thread信息 Method信息 Stop 截图 UI层次架构信息 其它的 Tab中提供的功能 我们 ...
- logback 相关
%logger{36} 表示logger名字最长36个字符,否则按照句点分割. %X{key} to get the value that are stored in the MDC map ${lo ...
- oracle--视图(2)---
Oracle---视图 视图是基于一个表或多个表或视图的逻辑表,本身不包含数据,通过它可以对表里面的数据进行查询和修改.视图基于的表称为基表,Oracle的数据库对象分为五种:表,视图,序列,索引和同 ...
- C#读写.ini文件
转载来源: http://blog.csdn.net/source0573/article/details/49668079 https://www.cnblogs.com/wang726zq/arc ...
- WPF Invoke与BeginInvoke的区别
Control.Invoke 方法 (Delegate) :在拥有此控件的基础窗口句柄的线程上执行指定的委托. Control.BeginInvoke 方法 (Delegate) :在创建控件的基础句 ...
- Ubuntu12.04安装R ,Rstudio, RHive
环境: Ubuntu12.04 R-3.1.0 0.Ubuntu安装R官网的介绍 http://mirrors.ustc.edu.cn/CRAN/ Precise Pangolin (12.04; L ...
- 16、SGE作业调度系统的简介
转载:http://www.zilhua.com/2222.html http://gridscheduler.sourceforge.net/htmlman/ SGE作业调度系统的简介 一.常见的几 ...
- 8、scala面向对象编程之Trait
一.Trait基础 1.将trait作为接口使用 // Scala中的Triat是一种特殊的概念 // 首先我们可以将Trait作为接口来使用,此时的Triat就与Java中的接口非常类似 // 在t ...
- iOS开发,使用CocoaSSDP查找设备时按关键字过滤Device
关于CocoaSSDP的资料有很多,这里就不介绍了. 希望寻找的目标设备,在header中设置了自定义的keyword,虽然通过外围代码也能达到相同目的,但是直接修改CocoaSSDP源码更简便. 导 ...
- Java Synchronized的原理
我们先通过反编译下面的代码来看看Synchronized是如何实现对代码块进行同步的: public class SynchronizedDemo{ public void method(){ syn ...