对tensorflow 中的attention encoder-decoder模型调试分析
#-*-coding:utf8-*- __author = "buyizhiyou"
__date = "2017-11-21" import random, time, os, decoder
from PIL import Image
import numpy as np
import tensorflow as tf
import pdb
import decoder
import random '''
在汉字ocr项目中,利用基于attention的encoder-decoder(seq2seq)模型进行端对端的训练
单步调试,追踪tensorflow 对 attention-seq2seq模型的实现方式
python 中seq2seq.py的接口:tf.nn.seq2seq.embedding_attention_seq2seq()
把用到的部分取出来单独调试
''' batch_size = 16
dec_seq_len = 8#图片对应的汉字数8
enc_lstm_dim = 256
dec_lstm_dim = 512
vocab_size = 1002
embedding_size = 100
lr = 0.01
global_step = tf.Variable(0) cnn = tf.truncated_normal([16,10,35,64],mean=0,stddev=1.0,dtype=tf.float32)#模拟初始化一个cnn提取特征后的图片
#(batch_size,height,width,channels)(16, 10, 35, 64)
true_labels = []
#随即生成batch中图片对应的序列,无需embedding
for i in range(batch_size):
seq_label = []
for j in range(dec_seq_len):
seq_label.append(random.randint(0,1000))
true_labels.append(seq_label) #编码
def encoder(inp):#inp:shape=(16, 35, 64)
#pdb.set_trace()
enc_init_shape = [batch_size, enc_lstm_dim]#[16,256]
with tf.variable_scope('encoder_rnn'):
with tf.variable_scope('forward'):
lstm_cell_fw = tf.nn.rnn_cell.LSTMCell(enc_lstm_dim)
init_fw = tf.nn.rnn_cell.LSTMStateTuple(\
tf.get_variable("enc_fw_c", enc_init_shape),\
tf.get_variable("enc_fw_h", enc_init_shape)
)
with tf.variable_scope('backward'):
lstm_cell_bw = tf.nn.rnn_cell.LSTMCell(enc_lstm_dim)
init_bw = tf.nn.rnn_cell.LSTMStateTuple(\
tf.get_variable("enc_bw_c", enc_init_shape),\
tf.get_variable("enc_bw_h", enc_init_shape)
)
output, _ = tf.nn.bidirectional_dynamic_rnn(lstm_cell_fw, \
lstm_cell_bw, \
inp, \
sequence_length = tf.fill([batch_size],\
tf.shape(inp)[1]), #(35,35,35...,35,35,35)
initial_state_fw = init_fw, \
initial_state_bw = init_bw \
)#shape=(16, 35, 256)
return tf.concat(2,output)##shape=(16, 35, 512) encoder = tf.make_template('fun', encoder)
# shape is (batch size, rows, columns, features)
# swap axes so rows are first. map splits tensor on first axis, so encoder will be applied to tensors
# of shape (batch_size,time_steps,feat_size)
rows_first = tf.transpose(cnn,[1,0,2,3])#shape=(10, 16, 35, 64)
res = tf.map_fn(encoder, rows_first, dtype=tf.float32)#shape=(10, 16, 35, 512)
encoder_output = tf.transpose(res,[1,0,2,3])#shape=(16, 10, 35, 512) dec_lstm_cell = tf.nn.rnn_cell.LSTMCell(dec_lstm_dim)
dec_init_shape = [batch_size, dec_lstm_dim]
dec_init_state = tf.nn.rnn_cell.LSTMStateTuple( tf.truncated_normal(dec_init_shape),\
tf.truncated_normal(dec_init_shape) ) init_words = np.zeros([batch_size,1,vocab_size])#(16, 1, 1002) #pdb.set_trace()
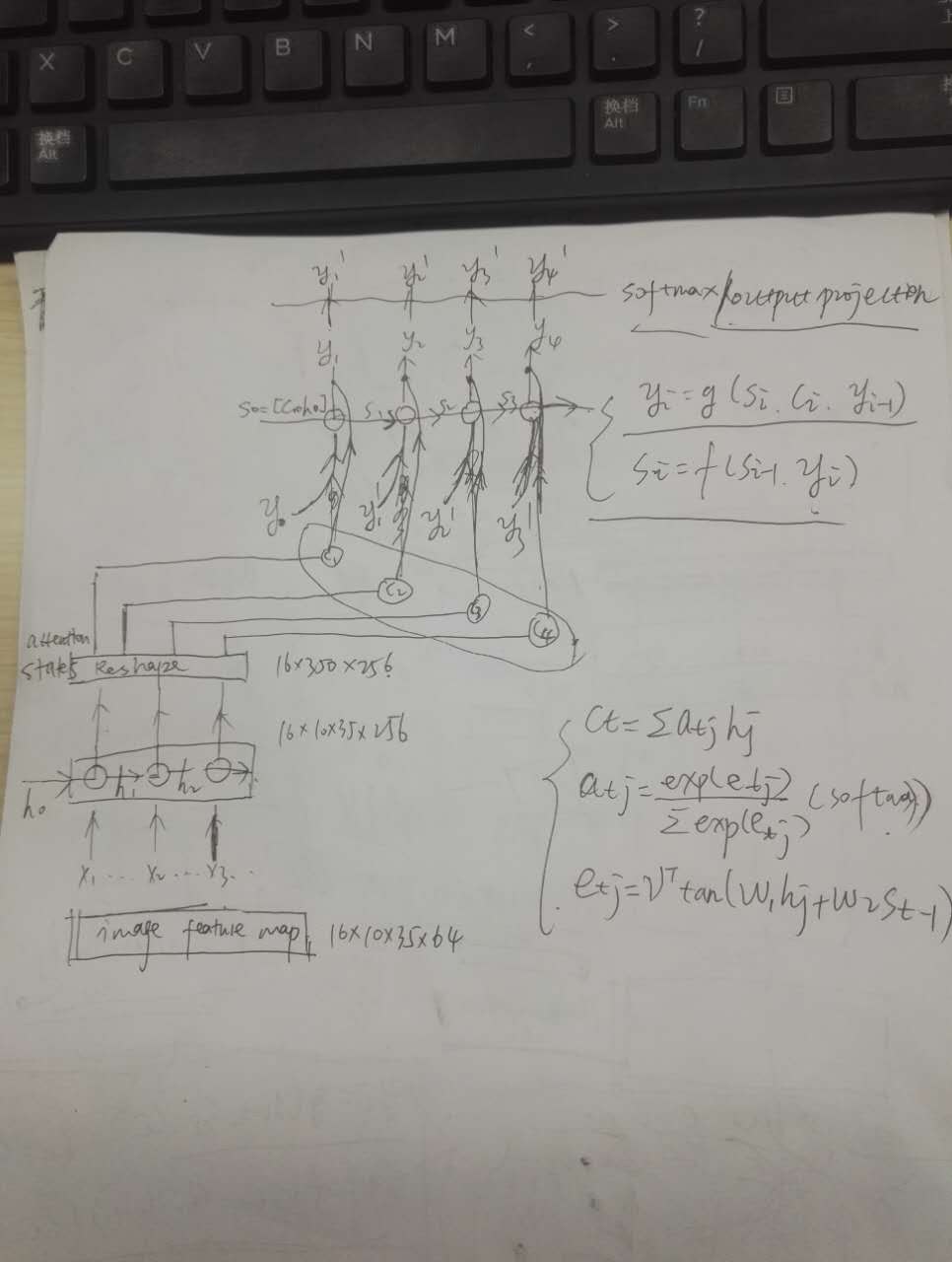
(output,state) = decoder.embedding_attention_decoder(dec_init_state,#[16, 512]第一个解码cell的state=[c,h]
tf.reshape(encoder_output,[batch_size, -1,2*enc_lstm_dim]),
#encoder输出reshape为 attention states作为attention模块的输入 shape=(16,350,512)
dec_lstm_cell,#lstm单元,作为解码层
vocab_size,#
dec_seq_len,#
batch_size,#
embedding_size,#
feed_previous=True)#dec_seq_len = num_words = time_steps
pdb.set_trace()
cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(output,true_labels))
learning_rate = tf.train.exponential_decay(lr, global_step, 50, 0.9)
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy,global_step=global_step)
correct_prediction = tf.equal(tf.to_int32(tf.argmax( output, 2)), true_labels)
decode.py
#-*-coding:utf8-*- """
截取自tensorflow seq2seq.py 文件
"""
import numpy as np
import tensorflow as tf
import pdb
from tensorflow.python import shape
from tensorflow.python.framework import dtypes
from tensorflow.python.framework import ops
from tensorflow.python.ops import array_ops
from tensorflow.python.ops import control_flow_ops
from tensorflow.python.ops import embedding_ops
from tensorflow.python.ops import math_ops
from tensorflow.python.ops import nn_ops
from tensorflow.python.ops import rnn
from tensorflow.python.ops import rnn_cell
from tensorflow.python.ops import variable_scope
from tensorflow.python.util import nest linear = rnn_cell._linear # pylint: disable=protected-access def attention_decoder(initial_state,#(16, 512)
attention_states,#shape=(16, 350, 512)
cell,
vocab_size,#
time_steps,#num_words,8
batch_size,#
output_size=None,#
loop_function=None,
dtype=None,
scope=None):
pdb.set_trace()
if attention_states.get_shape()[2].value is None:#tf 张量 get_shape()方法获取size
raise ValueError("Shape[2] of attention_states must be known: %s"
% attention_states.get_shape())
if output_size is None:
output_size = cell.output_size# with variable_scope.variable_scope(scope or "attention_decoder", dtype=dtype) as scope:
dtype = scope.dtype attn_length = attention_states.get_shape()[1].value #
if attn_length is None:
attn_length = shape(attention_states)[1]
attn_size = attention_states.get_shape()[2].value# # To calculate W1 * h_t we use a 1-by-1 convolution, need to reshape before.
hidden = array_ops.reshape(attention_states, [-1, attn_length, 1, attn_size])#shape=(16, 350, 1, 512)
attention_vec_size = attn_size # Size of query vectors for attention. 512
k = variable_scope.get_variable("AttnW",[1, 1, attn_size, attention_vec_size])#shape=(1,1,512,512)
hidden_features = nn_ops.conv2d(hidden, k, [1, 1, 1, 1], "SAME")#(16 ,350, 1, 512) w_1*h_j
v = variable_scope.get_variable("AttnV", [attention_vec_size]) def attention(query):
#LSTMStateTuple(c= shape=(16, 512) dtype=float32>, h=< shape=16, 512) dtype=float32>)
"""Put attention masks on hidden using hidden_features and query."""
if nest.is_sequence(query): # If the query is a tuple, flatten it.
query_list = nest.flatten(query) #[c,h],第一个随即初始化,以后调用之前计算的
for q in query_list: # Check that ndims == 2 if specified.
ndims = q.get_shape().ndims
if ndims:
assert ndims == 2
query = array_ops.concat(1, query_list)# shape=(16, 1024)
with variable_scope.variable_scope("Attention_0"):
y = linear(query, attention_vec_size, True)# shape=(16, 512) w_2*s_t
y = array_ops.reshape(y, [-1, 1, 1, attention_vec_size]) # shape=(16, 1, 1, 512)
s = math_ops.reduce_sum(
v * math_ops.tanh(hidden_features + y), [2, 3]) #!!!!!!!!!!!公式(3)shape=(16, 350)
a = nn_ops.softmax(s)# 公式(2)shape=(16, 350)
# Now calculate the attention-weighted vector d.
d = math_ops.reduce_sum(
array_ops.reshape(a, [-1, attn_length, 1, 1]) * hidden,#公式(1)
[1, 2])#shape=(16, 512)
ds = array_ops.reshape(d, [-1, attn_size])#shape=(16, 512) #!!!!!!!!!!!!以上是attention model中三个关键公式的实现
return ds
#pdb.set_trace()
prev = array_ops.zeros([batch_size,output_size])# shape=(16, 512) cell层第一个cell启动计算所需输入,
#随机初始化,以后的cell调用之前的计算结果
batch_attn_size = array_ops.pack([batch_size, attn_size]) #(2,?)
attn = array_ops.zeros(batch_attn_size, dtype=dtype)#shape=(16, 512)
attn.set_shape([None, attn_size])#(16,512) def cond(time_step, prev_o_t, prev_softmax_input, state_c, state_h, outputs2):
return time_step < time_steps def body(time_step, prev_o_t, prev_softmax_input, state_c, state_h, outputs2):#prev_o_t=prev:shape=(16,512)
#outputs:shape=(16, ?, 1002) prev_softmax_input=init_word:shape=(16, 1002)
state = tf.nn.rnn_cell.LSTMStateTuple(state_c,state_h)#第一次随机初始状态,之后调用之前的
pdb.set_trace()
with variable_scope.variable_scope("loop_function", reuse=True):
inp = loop_function(prev_softmax_input, time_step)#shape=(16,100) inp用来做什么 作为每个cell单元从下而
#来的输入??而prev_o_t则为从左而来的输入??而且Inp和上一个cell单元的softmax_input(最终进softmax之前的cell输出)有关(prev_softmax_input) input_size = inp.get_shape().with_rank(2)[1]#
if input_size.value is None:
raise ValueError("Could not infer input size from input: %s" % inp.name)
x = tf.concat(1,[inp,prev_o_t])#shape=(16, 612) 这个地方inp ,prev_o_t = loop_function(softmax_output),output
# Run the RNN.
cell_output, state = cell(x, state)#decoder层512个lstm单元 cell_output:shape=(16, 512) state:shape=(16, 512)
# Run the attention mechanism.
attn = attention(state)#shape=(16, 512) attenion模块的输出,C_i with variable_scope.variable_scope("AttnOutputProjection"):
output = math_ops.tanh(linear([cell_output, attn], output_size, False))#shape=(16, 512) y_i = f(C_i,S_i)
with variable_scope.variable_scope("FinalSoftmax"):
softmax_input = linear(output,vocab_size,False)#shape=(16, 1002) #decoder层后加一层softmax??作为softmax_input new_outputs = tf.concat(1, [outputs2,tf.expand_dims(softmax_input,1)])#shape=(16, ?, 1002)[,...y_t-1,y_t,...]
return (time_step + tf.constant(1, dtype=tf.int32),\
output, softmax_input, state.c, state.h, new_outputs)#既是输出,又是下一轮的输入 time_step = tf.constant(0, dtype=tf.int32)
shape_invariants = [time_step.get_shape(),\
prev.get_shape(),\
tf.TensorShape([batch_size, vocab_size]),\
tf.TensorShape([batch_size,512]),\
tf.TensorShape([batch_size,512]),\
tf.TensorShape([batch_size, None, vocab_size])] # START keyword is 0
init_word = np.zeros([batch_size, vocab_size])#shape=(16,1002) loop_vars = [time_step,\
prev,\
tf.constant(init_word, dtype=tf.float32),\
initial_state.c,initial_state.h,\
tf.zeros([batch_size,1,vocab_size])] outputs = tf.while_loop(cond, body, loop_vars, shape_invariants)##shape=(16, ?, 1002)
'''
loop_vars = [...]
while cond(*loop_vars):
loop_vars = body(*loop_vars)
''' return outputs[-1][:,1:], tf.nn.rnn_cell.LSTMStateTuple(outputs[-3],outputs[-2]) def embedding_attention_decoder(initial_state,#shape=(16, 512)
attention_states,# shape=(16, 350, 512)
cell,#定义的lstm单元
num_symbols,#
time_steps,
batch_size,#
embedding_size,#
output_size=None,#
output_projection=None,
feed_previous=False,#True
update_embedding_for_previous=True,
dtype=None,
scope=None):
if output_size is None:
output_size = cell.output_size#
if output_projection is not None:
proj_biases = ops.convert_to_tensor(output_projection[1], dtype=dtype)
proj_biases.get_shape().assert_is_compatible_with([num_symbols]) with variable_scope.variable_scope(scope or "embedding_attention_decoder", dtype=dtype) as scope:
embedding = variable_scope.get_variable("embedding",[num_symbols, embedding_size])
loop_function = tf.nn.seq2seq._extract_argmax_and_embed(embedding,
output_projection,update_embedding_for_previous) if feed_previous else None
#(16,1002)==>(16,100)找argmax,然后embedding
return attention_decoder(
initial_state,
attention_states,
cell,
num_symbols,#
time_steps,#
batch_size,
output_size=output_size,#
loop_function=loop_function)
关于embedding接口:
测试如下:
#-*-coding:utf8-*- __author = "buyizhiyou"
__date = "2017-11-21" import tensorflow as tf
import numpy as np '''
测试embedding接口
'''
embedding = tf.Variable(np.identity(5,dtype=np.int32))
inputs = tf.placeholder(dtype=tf.int32,shape=[None])
input_embedding = tf.nn.embedding_lookup(embedding,inputs) with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(embedding))
'''
[[1 0 0 0 0]
[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]
[0 0 0 0 1]]
'''
print(sess.run(input_embedding,feed_dict={inputs:[1,2,3,0,3,2,1]}))
'''
[[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]
[1 0 0 0 0]
[0 0 0 1 0]
[0 0 1 0 0]
[0 1 0 0 0]]
'''
对tensorflow 中的attention encoder-decoder模型调试分析的更多相关文章
- 以lstm+ctc对汉字识别为例对tensorflow 中的lstm,ctc loss的调试
#-*-coding:utf8-*- __author = "buyizhiyou" __date = "2017-11-21" ''' 单步调试,结合汉字的识 ...
- TensorFlow Object Detection API中的Faster R-CNN /SSD模型参数调整
关于TensorFlow Object Detection API配置,可以参考之前的文章https://becominghuman.ai/tensorflow-object-detection-ap ...
- 三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署
本文学习笔记参照来源:https://tf.wiki/zh/basic/basic.html 前文:三分钟快速上手TensorFlow 2.0 (上)——前置基础.模型建立与可视化 tf.train. ...
- Deep Learning基础--理解LSTM/RNN中的Attention机制
导读 目前采用编码器-解码器 (Encode-Decode) 结构的模型非常热门,是因为它在许多领域较其他的传统模型方法都取得了更好的结果.这种结构的模型通常将输入序列编码成一个固定长度的向量表示,对 ...
- 深度学习中的Attention机制
1.深度学习的seq2seq模型 从rnn结构说起 根据输出和输入序列不同数量rnn可以有多种不同的结构,不同结构自然就有不同的引用场合.如下图, one to one 结构,仅仅只是简单的给一个输入 ...
- 我用 tensorflow 实现的“一个神经聊天模型”:一个基于深度学习的聊天机器人
概述 这个工作尝试重现这个论文的结果 A Neural Conversational Model (aka the Google chatbot). 它使用了循环神经网络(seq2seq 模型)来进行 ...
- 第二十二节,TensorFlow中的图片分类模型库slim的使用、数据集处理
Google在TensorFlow1.0,之后推出了一个叫slim的库,TF-slim是TensorFlow的一个新的轻量级的高级API接口.这个模块是在16年新推出的,其主要目的是来做所谓的“代码瘦 ...
- 自定义Encoder/Decoder进行对象传递
转载:http://blog.csdn.net/top_code/article/details/50901623 在上一篇文章中,我们使用Netty4本身自带的ObjectDecoder,Objec ...
- 在 TensorFlow 中实现文本分类的卷积神经网络
在TensorFlow中实现文本分类的卷积神经网络 Github提供了完整的代码: https://github.com/dennybritz/cnn-text-classification-tf 在 ...
随机推荐
- hdu 1969 Pie (二分法)
Pie Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submiss ...
- [洛谷P4725]【模板】多项式对数函数
题目大意:给出$n-1$次多项式$A(x)$,求一个 $\bmod{x^n}$下的多项式$B(x)$,满足$B(x) \equiv \ln A(x)$.在$\bmod{998244353}$下进行.保 ...
- [poj] 3068 "Shortest" pair of paths || 最小费用最大流
[原题](http://poj.org/problem?id=3068) 给一个有向带权图,求两条从0-N-1的路径,使它们没有公共点且边权和最小 . //是不是像传纸条啊- 是否可行只要判断最后最大 ...
- BZOJ2631 tree 【LCT】
题目 一棵n个点的树,每个点的初始权值为1.对于这棵树有q个操作,每个操作为以下四种操作之一: + u v c:将u到v的路径上的点的权值都加上自然数c: - u1 v1 u2 v2:将树中原有的边( ...
- 每天一个小算法(Shell Sort1)
希尔排序是1959 年由D.L.Shell 提出来的,相对直接排序有较大的改进.希尔排序又叫缩小增量排序 基本思想: 先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录 ...
- Codeforces Round #522 (Div. 2) C. Playing Piano
C. Playing Piano 题目链接:https://codeforces.com/contest/1079/problem/C 题意: 给出数列{an},现在要求你给出一个数列{bn},满足: ...
- TCP面试题之四次挥手过程
TCP四次挥手过程: 1.第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态: 2.第二次挥手:Server收到FIN后,发 ...
- es6+最佳入门实践(2)
2.解构赋值 2.1.什么是解构赋值? 什么是解构赋值?这里的关键字还是赋值,这是说如何去赋值的问题,这里说的解构可以理解为解散重新构造,所以解构赋值可以理解为解散重新构造后进行赋值,通常是左边一种结 ...
- laravel的elixir和gulp用来对前端施工
使用laravel elixer npm install --global gulp ok 然后在安装好的laravel 下 npm install 以安装 laravel-elixir subli ...
- [ CodeVS冲杯之路 ] P1039
不充钱,你怎么AC? 题目:http://codevs.cn/problem/1039/ 一道赤裸裸的嘲讽型数学题,推出来的话算法代码就3行,没有推出来连暴力都无从入手…… 设 f(n,m) 为整数 ...