weight decay 和正则化caffe
正则化是为了防止过拟合,因为正则化能降低权重
caffe默认L2正则化
代码讲解的地址:http://alanse7en.github.io/caffedai-ma-jie-xi-4/
重要的一个回答:https://stats.stackexchange.com/questions/29130/difference-between-neural-net-weight-decay-and-learning-rate
按照这个答主的说法,正则化损失函数,正则化之后的损失函数如下:

这个损失函数求偏导就变成了:加号前面是原始损失函数求偏导,加号后面就变成了 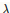 *w,这样梯度更新就变了下式:
*w,这样梯度更新就变了下式:
wi←wi−η∂E∂wi−ηλwi.
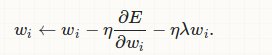
L2正则化的梯度更新公式,与没有加regulization正则化相比,每个参数更新的时候多剪了正则化的值,相当于让每个参数多剪了weight_decay*w原本的值
根据caffe中的代码也可以推断出L1正则化的公式:
把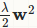 替换成
替换成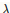 *w的绝对值
*w的绝对值
所以求偏导的时候就变成了,当w大于0为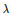 ,当w小于0为-
,当w小于0为-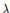
void SGDSolver<Dtype>::Regularize(int param_id) {
const vector<shared_ptr<Blob<Dtype> > >& net_params = this->net_->params();
const vector<float>& net_params_weight_decay =
this->net_->params_weight_decay();
Dtype weight_decay = this->param_.weight_decay();
string regularization_type = this->param_.regularization_type();
Dtype local_decay = weight_decay * net_params_weight_decay[param_id];
switch (Caffe::mode()) {
case Caffe::CPU: {
if (local_decay) {
if (regularization_type == "L2") {
// add weight decay
caffe_axpy(net_params[param_id]->count(),
local_decay,
net_params[param_id]->cpu_data(),
net_params[param_id]->mutable_cpu_diff());
} else if (regularization_type == "L1") {
caffe_cpu_sign(net_params[param_id]->count(),
net_params[param_id]->cpu_data(),
temp_[param_id]->mutable_cpu_data());
caffe_axpy(net_params[param_id]->count(),
local_decay,
temp_[param_id]->cpu_data(),
net_params[param_id]->mutable_cpu_diff());
} else {
LOG(FATAL) << "Unknown regularization type: " << regularization_type;
}
}
break;
}
caffe_axpy的实现在util下的math_functions.cpp里,实现的功能是y = a*x + y,也就是相当于把梯度更新值和weight_decay*w加起来了
caffe_sign的实现在util下的math_functions.hpp里,通过一个宏定义生成了caffe_cpu_sign这个函数,函数实现的功能是当value>0返回1,<0返回-1
weight decay 和正则化caffe的更多相关文章
- PyTorch 中 weight decay 的设置
先介绍一下 Caffe 和 TensorFlow 中 weight decay 的设置: 在 Caffe 中, SolverParameter.weight_decay 可以作用于所有的可训练参数, ...
- dying relu 和weight decay
weight decay就是在原有loss后面,再加一个关于权重的正则化,类似与L2 正则,让权重变得稀疏: 参考:https://www.zhihu.com/question/24529483 dy ...
- 权重衰减(weight decay)与学习率衰减(learning rate decay)
本文链接:https://blog.csdn.net/program_developer/article/details/80867468“微信公众号” 1. 权重衰减(weight decay)L2 ...
- weight decay(权值衰减)、momentum(冲量)和normalization
一.weight decay(权值衰减)的使用既不是为了提高你所说的收敛精确度也不是为了提高收敛速度,其最终目的是防止过拟合.在损失函数中,weight decay是放在正则项(regularizat ...
- 在神经网络中weight decay
weight decay(权值衰减)的最终目的是防止过拟合.在损失函数中,weight decay是放在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度,所以weigh ...
- 【tf.keras】AdamW: Adam with Weight decay
论文 Decoupled Weight Decay Regularization 中提到,Adam 在使用时,L2 与 weight decay 并不等价,并提出了 AdamW,在神经网络需要正则项时 ...
- weight decay (权值衰减)
http://blog.sina.com.cn/s/blog_890c6aa30100z7su.html 在机器学习或者模式识别中,会出现overfitting,而当网络逐渐overfitting时网 ...
- [转载]理解weight decay
http://blog.sina.com.cn/s/blog_a89e19440102x1el.html
- 【撸码caffe四】 solver.cpp&&sgd_solver.cpp
caffe中solver的作用就是交替低啊用前向(forward)算法和后向(backward)算法来更新参数,从而最小化loss,实际上就是一种迭代的优化算法. solver.cpp中的Solver ...
随机推荐
- C实现shell管理的一个例子
通常情况下,一个进程(比如cat /tmp/tt.txt)的输出与输入是标准输入(stdin或者0).标准输出(stdout或者1) shell 获取tt.txt文件中包含aa的行记录,涉及两个进程, ...
- php 数据库查询order by 与查询返回的数据类型
<?php /** * Created by PhpStorm. * User: DY040 * Date: 2017/11/24 * Time: 9:40 * * 从结果集合中读取一行数据 * ...
- java——字典树 Trie
字典树是一种前缀树 package Trie; import java.util.TreeMap; public class Trie { private class Node{ public boo ...
- RequireJS -Javascript模块化(二、模块依赖)
上一篇文章中简单介绍了RequireJs的写法和使用,这节试着写下依赖关系 需求描述:我们经常写自己的js,在元素选择器这方面,我们可能会用jquery的$("#id")id选择器 ...
- 使用vue-router beforEach实现判断用户登录跳转路由筛选功能
在开发webApp的时候,考虑到用户体验,经常会把不需要调用个人数据的页面设置成游客可以访问,而当用户进入到一些需要个人数据的,例如购物车,个人中心,我的钱包等等,在进行登录的验证判断,如果判断已经登 ...
- 那些NPM文档中我看不懂地方
$cookies.set(keyName, value[, expireTimes[, path[, domain[, secure]]]]) //return this 中括号代表可选参数 上面一行 ...
- Jquery ValidationEngine 修改验证提示框的位置
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- S3C2440 中断相关寄存器小探
========================================== 转载时请注明出处和作者联系方式 文章出处:http://blog.csdn.net/longintchar 作者联 ...
- C语言中的重定向输入
所谓重定向输入,就是不用从键盘一组一组的输入数据,而是保存为一个文件,直接将该程序的测试数据进行输入即可:使用freopen()函数会将标准输入stdin重定向到文件input.txt(这个文件名自己 ...
- One special dictionary
由于项目一个功能需要,可以将关键字的值叠加加来,最终可以获取对这些关键字都做了些什么操作. Generic Programming is very powerful. /// <summary& ...